








ArXiv 2023.2的文章
文章地址:https://arxiv.org/abs/2301.12652
目录
0、背景
(1)近年来的LLMs是不公开且不可微调的,只提供API接口
(2)很多大语言模型就算公开但微调他们也需要花费大量开销
(3)LLMs容易产生幻觉
1、摘要
REPLUG只是将检索到的文档添加到冻结的黑盒LM的输入中,就相较于目前流行的大语言模型及检索增强的语言模型有了很强的提升,并且这种简单的设计可以很容易地应用于任何现有的检索和语言模型。论文还提出了REPLUG的升级版 REPLUG LSR, 获得了更好的效果。
2、结论
(1)提出了一种新范式:将语言模型视为一个黑盒,并让检索模型去适配语言模型
(2)REPLUG可以与任何现有的语言模型集成,以提高它们在语言建模或下游任务上的性能
(3)缺乏可解释性,因为不清楚模型的输出是依赖于检索到的知识还是参数化知识
3、模型
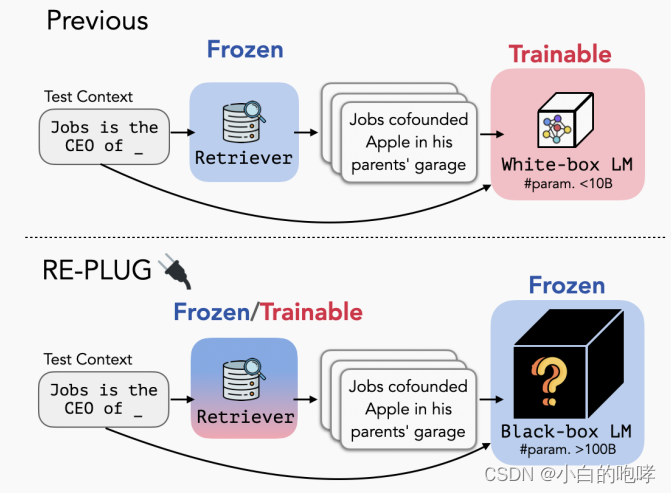
以往的研究:
·冻结检索器,微调语言模型来适配检索器
·缺点:LLMs是黑盒,无法再进行微调
REPLUG:
·把语言模型视为一个黑盒
·被设计为一个可调的即插即用模块,灵活高效,适用于各种LLMs
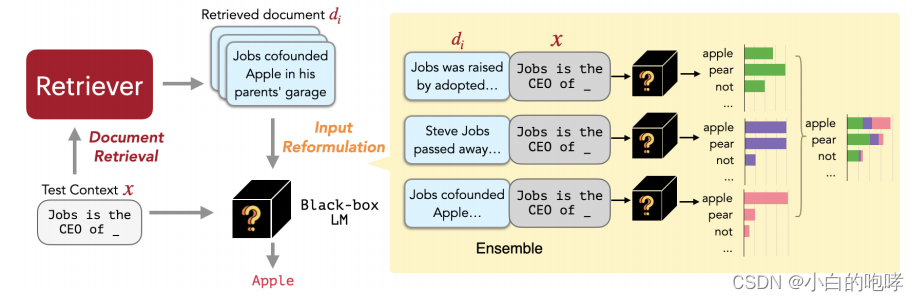
上图为REPLUG的流程图
(1)给定一个上下文x
(2)REPLUG会从外部知识库中检索出一些相关文档di
- 使用dual-encoder(共享参数)检索文档
- 文档与输入的embedding都是对其中每个token最后一个隐藏层表达的平均值
- 使用余弦相似度计算x与d的相关性:
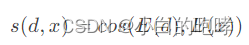
- 预先计算文档的embedding,并利用
FAISS来快速找到top-k文档
(3)将每个检索到的文档和x拼接之后,并行输入到LM中
-
由于LM上下文长度限制了可以添加的文档的数量,因此我们还引入了一个新的集成方案。
-
集成方案:将每个检索到的top-k文档分别拼在x前面,并将拼接结果分别输入到LLM中。最后聚合每个并行输入z得到的预测概率
(4)最后聚合每个并行输入得到的预测概率
对于给定上下文x和top-k文档集合D,下一个y的生成概率由加权平均决定。
![]()
其中λ(d, x)是d与x相似度s(d, x)进行softmax的结果
REPLUG LSR:
可以理解为REPLUG的升级版
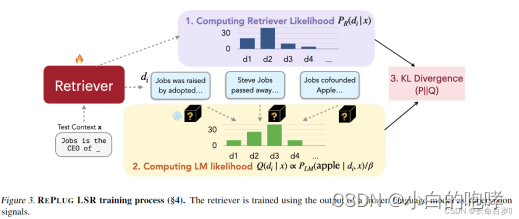
主要步骤:
(1)检索文档并计算检索似然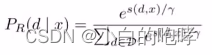
(2)计算语言模型概率分布(原文用的是likelihood,认为译成概率分布比较合适)
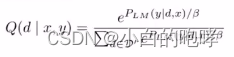
其中的PLM是计算给定d和x的情况下,可以输出正确的标签的概率。之前再做一个softmax输出结果
(3)计算检索结果似然和语言模型概率分布,二者之间的KL散度, 进而更新检索模型参数
(KL散度:KL散度越小,说明概率Q与概率P之间越接近,那么估计的概率分布与真实的概率分布也就越接近)
(4)异步更新知识库索引
·因为检索模型的参数在训练阶段会更新,进而导致embedding过时
·每隔T步,对文档重新进行embedding
使用的损失函数为检索文档的似然和LM的概率分布,二者的KL散度
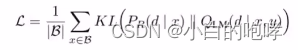 使KL散度变小
使KL散度变小
4、实验
作者一共做了三组实验,检索模型使用的是Contriever。
(1)语言建模阶段:研究目的是评估在语言建模任务上,将检索模块(REPLUG和REPLUG LSR)添加到传统的语言模型(GPT-3和GPT-2)中是否能够提高性能
数据集:The pile(一个语言建模基准,来自不同领域的文本源组成,如网页、代码和学术论文)
Baseline:GPT-3,GPT-2家族
其中GPT-3中的四个模型(Davinci, Curie, Baddage and Ada)都是黑盒模型
检索语料库:随机抽取Pile训练数据(随机抽取Pile训练数据(367M文档,128个令牌)作为所有模型的检索语料库)
实验结果
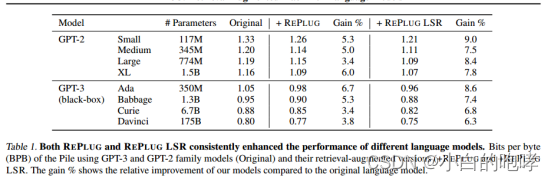
(2)下游任务测试
数据集:MMLU(Measuring massive multitask language understanding):一个多选题QA数据集,涵盖了57个任务的考试问题,包括数学、计算机科学、法律、美国历史等。
Baseline分成两组:
一组是目前最先进的大语言模型(Codex1 PaLM FlanPaLM)【有论文证明这三个模型是MMLU榜单的前三】
另一组是由检索增强语言模型组成:Atlas(只有一个,因为没有其他检索增强的lm在MMLU数据集上进行评估)
检索语料库:维基百科
实验结果
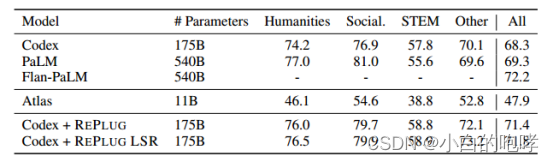
(3)开放域问答领域
数据集:NQ 和 TriviaQA
Baseline:
第一组由LLMs组成:Chinchilla (64-shot ) 、PaLM (64-shot )、Codex(16-shot)
第二组由检索增强LLMs组成:RETRO、R2-D2、Atlas(64-shot)
以上这些模型都是在训练数据上进行了微调
使用的外部知识库:维基百科
实验结果
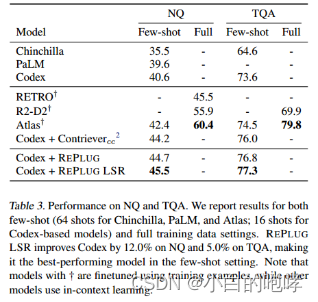
Ps:这个结果仍落后于在完整训练上微调的检索增强语言模型的性能(Atlas)
这可能是由于训练集中存在近似重复的测试问题,Lewis[1]等人发现32.5%的测试问题与NQ中的训练集重叠
参考文献
[1] Question and answer test-train overlap in open-domain question answering datasets


















 1751
1751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











