







 该文详细介绍了如何使用Python的PyTorch库处理和训练MNIST手写数字识别数据集。首先,文章导入必要的模块,然后下载MNIST数据集,接着读取并解析数据集,包括训练集和验证集。之后,定义了一个简单的卷积神经网络模型,并进行了训练,记录了训练和验证过程中的损失和准确率。
该文详细介绍了如何使用Python的PyTorch库处理和训练MNIST手写数字识别数据集。首先,文章导入必要的模块,然后下载MNIST数据集,接着读取并解析数据集,包括训练集和验证集。之后,定义了一个简单的卷积神经网络模型,并进行了训练,记录了训练和验证过程中的损失和准确率。
MNIST 网络 测试用
1. 导入所需要的模块
import sys
#sys.path.append('../../')
#from zfdplearn import fdutils, fdtorch_net, fddata
import os.path as path
import gzip
from typing import Dict, List, Tuple, AnyStr, KeysView, Any
import torch
from torch.utils.data import DataLoader, Dataset
from torch import nn
from torchvision import transforms
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
2. 下载 MNIST 数据集
2.1 下载地址: http://yann.lecun.com/exdb/mnist/
2.1.1 下载的文件有 4 个,分别是:
train-images-idx3-ubyte.gz ==> 训练集的图片
train-label-idx1-ubyte.gz ==> 训练集的标签
t10k-images-idx3-ubyte.gz ==> 测试集的图片
t10k-label-idx1-ubyte.gz ==> 测试集的标签
下载的数据集格式为 .gz,因此需要使用到 python 的 gzip 包
# 下载地址: http://yann.lecun.com/exdb/mnist/
dataset_folder = '../datasets/mnist'
files_name = {
'train_img': 'train-images-idx3-ubyte.gz',
'train_label': 'train-labels-idx1-ubyte.gz',
'vali_img': 't10k-images-idx3-ubyte.gz',
'vali_label': 't10k-labels-idx1-ubyte.gz'
}
3. 读取 MNIST 数据集
3.1 下载的数据集格式为 .gz,因此需要使用 gzip 中的 open 函数打开。
3.2 打开模式设置为 mode=‘rb’,以字节流的方式打开。因为下载的数据集的格式为字节方式封装
3.3 由于使用字节流打开,因此需要使用 torch.frombuffer() 或者 np.frombuffer() 函数打开。
3.3 根据 MNIST 数据集官网可知,读取数据集需要 offset,因为,在数据头部的数据存储了数据集的一些信息
3.4.1 training set label file: 前 4 个字节为 魔术数,第 4-7 字节为数据的条数(number of items),因此需要 offset 8

3.4.2 training set images file: 前 4 个字节为 魔术数,第 4-7 字节为数据的条数(number of items),第 8-11 是每张图片的行数,第 12-15 是每张图片的列数, 因此需要 offset 16
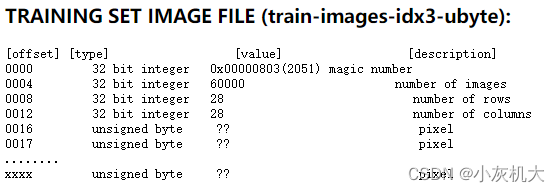
3.4.2 test set label file: 前 4 个字节为 魔术数,第 4-7 字节为数据的条数(number of items),因此需要 offset 8

3.4.3 test set images file: 前 4 个字节为 魔术数,第 4-7 字节为数据的条数(number of items),第 8-11 是每张图片的行数,第 12-15 是每张图片的列数,因此需要 offset 16

PS: torch/np. frombuffer()
# 加载训练集 图片
def load_mnist_data(files_name) -> Tuple:
with gzip.open(path.join(dataset_folder, files_name['train_img']), mode='rb') as data:
train_img = torch.frombuffer(data.read(), dtype=torch.uint8, offset=16).reshape(-1, 1, 28, 28)
# 加载训练集 标签
with gzip.open(path.join(dataset_folder, files_name['train_label']), mode='rb') as label:
train_label = torch.frombuffer(label.read(), dtype=torch.uint8, offset=8)
# 加载验证集 图片
with gzip.open(path.join(dataset_folder, files_name['vali_img']), mode='rb') as data:
vali_img = torch.frombuffer(data.read(), dtype=torch.uint8, offset=16).reshape(-1, 1, 28, 28)
# 加载验证集 label
with gzip.open(path.join(dataset_folder, files_name['vali_label']), mode='rb') as label:
vali_label = torch.frombuffer(label.read(), dtype=torch.uint8, offset=8)
return (train_img, train_label),(vali_img, vali_label)
# save -- fdutils.Accumulator
class Accumulator():
"""
collecting metrics in experiment
"""
def __init__(self, names: List[Any]):
self.accumulator = {}
if not isinstance(names, list):
raise Exception(f'type error, expected list but got {type(names)}')
for name in names:
self.accumulator[name] = list()
def __getitem__(self, item) -> List[Any]:
if item not in self.accumulator.keys():
raise Exception(f'key error, {item} is not in accumulator')
return self.accumulator[item]
def add(self, name: AnyStr, val: Any):
self.accumulator[name].append(val)
def add_name(self, name: AnyStr):
if name in self.accumulator.keys():
raise Exception(f'{name} is already in accumulator.keys')
self.accumulator[name] = list()
def gets(self) -> Dict[AnyStr, Any]:
return self.accumulator
def get_item(self, name: AnyStr) -> List[Any]:
if name not in self.accumulator.keys():
raise Exception(f'key error, {name} is not in accumulator')
return self.accumulator[name]
def clear(self):
self.accumulator.clear()
def get_names(self) -> KeysView:
return self.accumulator.keys()
class MNIST_dataset(Dataset):
def __init__(self, data: List, label: List):
self.__data = data
self.__label = label
def __getitem__(self, item):
if not item < self.__len__():
return f'Error, index {item} is out of range'
return self.__data[item], self.__label[item]
def __len__(self):
return len(self.__data)
# 读取数据
train_data, vali_data = load_mnist_data(files_name)
# 将数据封装为 MNIST 类
train_dataset = MNIST_dataset(*train_data)
vali_dataset = MNIST_dataset(*vali_data)
len(train_dataset), len(vali_dataset)
(60000, 10000)
class YLMnistNet(nn.Module):
def __init__(self):
super(YLMnistNet, self).__init__()
self.conv0 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=(5, 5))
self.conv1 = nn.Conv2d(6, 16, kernel_size=(5, 5))
self.pool0 = nn.AvgPool2d(kernel_size=(2, 2))
self.pool1 = nn.AvgPool2d(kernel_size=(2, 2))
self.linear0 = nn.Linear(16*4*4, 120)
self.linear1 = nn.Linear(120, 84)
self.linear2 = nn.Linear(84, 10)
self.relu = nn.ReLU()
self.flatten = nn.Flatten()
self.layers = [self.conv0, self.pool0, self.conv1, self.pool1, self.flatten, self.linear0, self.relu, self.linear1, self.relu, self.linear2, self.relu]
def forward(self, x):
output = self.conv0(x)
output = self.pool0(output)
output = self.conv1(output)
output = self.pool1(output)
output = self.flatten(output)
output = self.linear0(output)
output = self.relu(output)
output = self.linear1(output)
output = self.relu(output)
output = self.linear2(output)
output = self.relu(output)
return output
# get depth of MNIST Net
def __len__(self):
return len(self.layers)
# get specified layer
def __getitem__(self, item):
return self.layers[item]
def __name__(self):
return 'YNMNISTNET'
net = YLMnistNet()
def train(net, loss, train_iter, vali_iter, optimizer, epochs, device) -> Accumulator:
net = net.to(device)
one_hot_f = nn.functional.one_hot
accumulator = Accumulator(['train_loss', 'vali_loss', 'train_acc', 'vali_acc'])
epoch_loss = []
for epoch in range(epochs):
len_train = 0
len_vali = 0
net.train()
epoch_loss.clear()
correct_num = 0
for img, label in train_iter:
img, label = img.to(device, dtype=torch.float), label.to(device)
oh_label = one_hot_f(label.long(), num_classes=10)
optimizer.zero_grad()
y_hat = net(img)
l = loss(y_hat, oh_label.to(dtype=float))
l.backward()
optimizer.step()
epoch_loss.append(l.item())
correct_num += (y_hat.argmax(dim=1, keepdim=True) == label.reshape(-1, 1)).sum().item()
len_train += len(label)
accumulator['train_loss'].append(sum(epoch_loss)/len(epoch_loss))
accumulator['train_acc'].append(correct_num/len_train)
print(f'-----------epoch: {epoch+1} start --------------')
print(f'epoch: {epoch+1} train loss: {accumulator["train_loss"][-1]}')
print(f'epoch: {epoch+1} train acc: {accumulator["train_acc"][-1]}')
# validation
epoch_loss.clear()
correct_num = 0
with torch.no_grad():
net.eval()
for img, label in vali_iter:
img, label = img.to(device, dtype=torch.float), label.to(device)
# print(img.dtype)
oh_label = one_hot_f(label.long(), num_classes=10)
vali_y_hat = net(img)
l = loss(vali_y_hat, oh_label.to(dtype=float))
epoch_loss.append(l.item())
correct_num += (vali_y_hat.argmax(dim=1, keepdim=True) == label.reshape(-1, 1)).sum().item()
len_vali += len(label)
accumulator['vali_loss'].append(sum(epoch_loss)/len(epoch_loss))
accumulator['vali_acc'].append(correct_num / len_vali)
print(f'epoch: {epoch+1} vali loss: {accumulator["vali_loss"][-1]}')
print(f'epoch: {epoch+1} vali acc: {accumulator["vali_acc"][-1]}')
print(f'-----------epoch: {epoch+1} end --------------')
return accumulator
# from torch.utils.data import DataLoader
net = YLMnistNet()
batch_size = 32
train_iter = DataLoader(train_dataset, batch_size=batch_size)
vali_iter = DataLoader(vali_dataset, batch_size=batch_size)
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
num_epoch = 1
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.01)
accumulator = train(net, loss, train_iter, vali_iter, optimizer, num_epoch, device)
--------------epoch: 1 start ----------------------
epoch: 1 train loss: 0.4480924960145155
epoch: 1 train acc: 0.85015
epoch: 1 vali loss: 0.14723741338332405
epoch: 1 vali acc: 0.9559
--------------epoch: 1 end ----------------------
…
…
--------------epoch: 20 start ----------------------
epoch: 20 train loss: 0.01722543535107635
epoch: 20 train acc: 0.9943166666666666
epoch: 20 vali loss: 0.12874228838498014
epoch: 20 vali acc: 0.9754
--------------epoch: 20 end ----------------------

















 4696
4696

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









