







摘要
TCP/IP协议,或称为TCP/IP协议栈,或互联网协议系列。TCP/IP协议栈(按TCP/IP参考模型划分),TCP/IP分为4层,不同于OSI,他将OSI中的会话层、表示层规划到应用层。
TCP/IP是互联网的核心协议,也是大多数网络应用的核心协议。
TCP由RFC793、RFC1122、RFC1323、RFC2001、RFC2018以及RFC2581定义。

(1) TCP概述
a. TCP提供的是面向连接的全双工服务。
TCP所有的数据会匹配到由源地址,目的地址,源端口,目的端口构成的一个TCP连接之上。TCP连接是一种需要建立的资源,可以通过之后会讲到的握手机制来完成。UDP是一种基于尽力而为机制的协议,不存在UDP连接资源的建立,资源的处理往往由应用层协议代劳了。
b. TCP是提供的可靠服务。
TCP有确认机制来保证数据包的可靠到达,
TCP有CRC校验机制来保证数据包的无差错性,UDP的CRC是可选的,
TCP会重新排序乱序的数据包和丢弃重复的数据,
TCP能够提供流量控制机制,使用滑动窗口算法,
TCP能提供拥塞控制与恢复机制,存在多种TCP拥塞控制模型,
TCP能协商发送的数据报文长度。
TCP报头:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Source Port | Destination Port |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Sequence Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Acknowledgment Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Data | |U|A|P|R|S|F| |
| Offset| Reserved |R|C|S|S|Y|I| Window |
| | |G|K|H|T|N|N| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Checksum | Urgent Pointer |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Options | Padding |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| data |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ TCP Header Format
对于TCP头的标记位,SYN标记只在三次握手(或四次握手)的时候的被置位,ACK标记会在握手之后所有的TCP报文中被置位。当然也有一些特殊情况,比如有些情况下RST报文不会置位ACK。
这些规则也许在配置复杂的ACL中有用。
(2) TCP协议栈的状态机
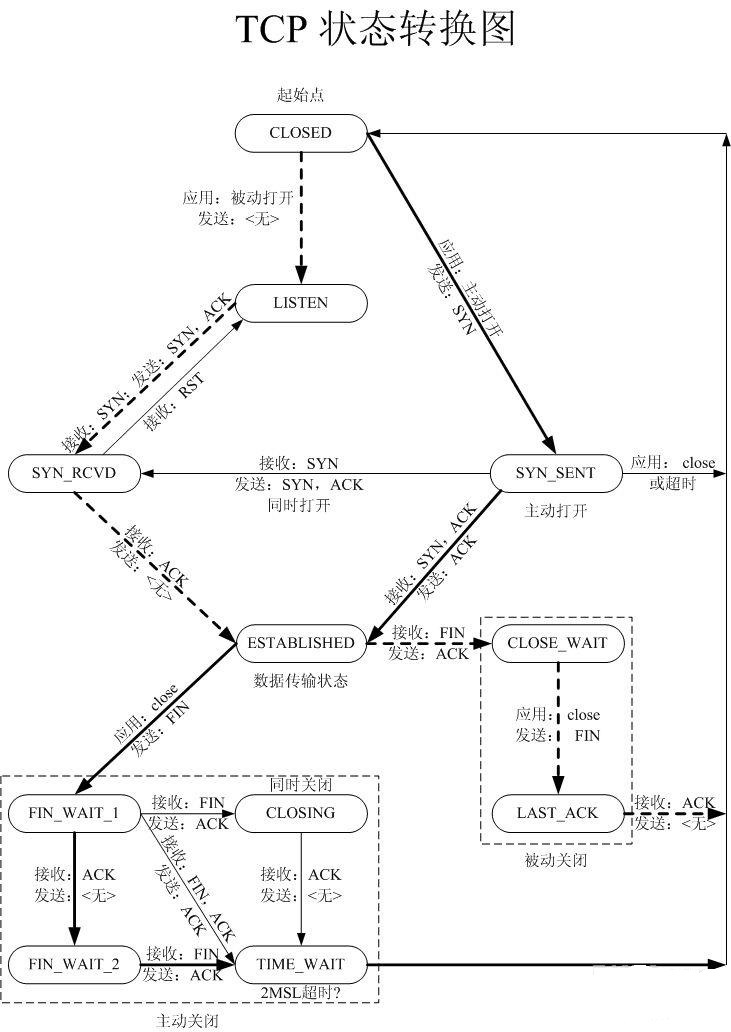
TCP1
a. TCP连接的建立。TCP连接的建立有主动打开,被动打开以及同时打开三种情况。
三次握手比较清楚,要强调的是ISN,就是初始序列号的选择问题,序列号是32位的,针对不同的OS,初始序列号的选择往往也是有规律的。
TCP传输的最大报文长度也是在三次握手中协商的。具体说是在也仅在SYN报文中协商的。MSS = MTU - ip_header_len - tcp_header_len。MSS这里也是为了防止分片,提高网络带宽利用率。
TCP三次握手中,最后一个报文ACK,不需要再有额外的确认机制,如果这个ACK在网络中丢弃了,TCP协议栈也有其他的机制来处理。
除了三次握手,还有一种很特殊的应用情况,就是TCP两端同时打开的情况(发送syn),这种情况没有描述在上面的状态机中。
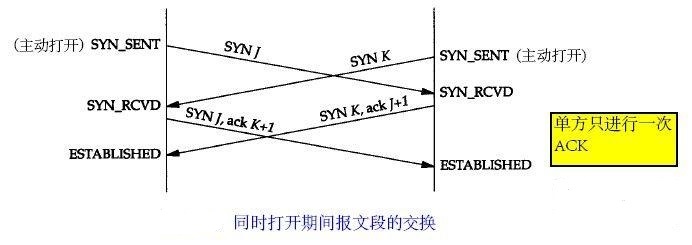
SYN1
举例子来说,A通过源端口7777发起到B的目的端口8888的连接的同时,B也通过源端口8888发起对A的目的端口7777的TCP连接。
b. TCP连接的关闭
TCP连接的关闭也有主动关闭,被动关闭和同时关闭三种情况,这三种情况在上面的TCP状态机中都有描述。
TCP连接的关闭需要报文四次交互,因为TCP是一个全双工的服务,所以每个方向的连接都关闭后,TCP的连接才是完整的拆除。
状态机中,主动关闭和同时关闭最后都会进入到一个TIME_WAITE状态。针对TCP主动关闭的最后一个报文应该是ACK,确认对端的FIN报文。这个状态的概念是该TCP连接的资源并没有完全释放,因为还要确保最后一个ACK报文能够无误的到达对端,确认对端的FIN,否则就仍然要重传ACK。
这个等待的过程(或者资源没有完全释放的过程)需要等待2MSL时间(考虑报文一次往返)。MSL是最大报文生存时间,RFC793中为2分钟,根据不同的TCP实现,一般是30s或者1分钟。
所以在TIME_WAITE状态内,该TCP连接所使用的端口和连接资源,不能被继续使用。但是很多TCP实现并没有这个限制,只要新的TCP连接所使用的ISN大于TIME_WAITE状态TCP连接所使用的最后序号即可。实现中往往使用
new ISN = latest ISN in time_waite + 128000
IP报文的最大生存时间是TTL值,TCP报文的最大生存时间是MSL,二层上没有报文最大生存时间的概念,存在风暴的可能。
(3) TCP的滑动窗和定时器
a. TCP的报文确认机制。
TCP使用的是滑动窗口机制来发送数据流,所以TCP协议允许连续发送多个TCP分组而不等待对端的确认。所以发送的分组数据和确认不是一对一的关系。
TCP中,对数据的确认往往是延迟的,一般情况是两个TCP数据对应一个确认,在时延定时器没有溢出的情况下。如果时延定时器溢出了,那么自然也会发送确认报文。
但是,针对存在交互大量微小报文的TCP应用,过于频繁的确认会导致网络利用率的低效,所以TCP支持一种Nagle算法。
b. 延时定时器
当TCP收到报文时候,启动延时定时器,比如200ms。
c. Nagle算法
TCP连接上只能存在一个未被确认的微小报文(41字节的TCP报文),在该确认到达前,TCP仅仅收集微小报文,当确认到达后,以一个分组的形式发出去。
当然,某些应用需要关闭Nagle算法。
d. 滑动窗口机制
窗口合拢(左移):在收到对端数据后,自己确认了数据的正确性,这些数据会被存储到缓冲区,等待应用程序获取。但这时候因为已经确认了数据的正确性,需要向对方发送确认响应ACK,又因为这些数据还没有被应用进程取走,这时候便需要进行窗口合拢,缓冲区的窗口左边缘向右滑动。注意响应的ACK序号是对方发送数据包的序号,一个对方发送的序号,可能因为窗口张开会被响应(ACK)多次。
窗口张开(右移):窗口收缩后,应用进程一旦从缓冲区中取出数据,TCP的滑动窗口需要进行扩张,这时候窗口的右边缘向右扩张,实际上窗口这是一个环形缓冲区,窗口的右边缘扩张会使用原来被应用进程取走内容的缓冲区。在窗口进行扩张后,需要使用ACK通知对端,这时候ACK的序号依然是上次确认收到包的序号。
窗口收缩,窗口的右边缘向左滑动,称为窗口收缩,Host Requirement RFC强烈建议不要这样做,但TCP必须能够在某一端产生这种情况时进行处理。
e. 重传定时器
目的是为了获得对端的确认报文。如果多次重传仍然没有获得确认,则会发送复位报文RST。
这里我们再来看一下TCP的三次握手。
A(发起端) ---> syn ---> B(服务器)
A(发起端) <--- syn/ack <--- B(服务器)
A(发起端) ---> ack ? B(服务器)如果TCP客户端A的最后一个ACK丢失了,TCP服务器B没有收到,会是一种什么情况?
这个时候A已经进入到了Establish状态,然而B还只是Syn_Recev状态,所以服务器会重传syn/ack报文,只到连接的最终建立。但是客户端A已经到建立状态了,所以A是有可能发送TCP数据给服务器B的。
所以TCP的两端,最终状态机是有可能不一致的。[后面会详细讲述重传和拥塞控制机制]
f. 坚持定时器
由于TCP没有对ACK的确认机制,所以当接收端窗口从0恢复到一定值的时候,如果接收端发给发送端的ACK报文(标识窗口大小)丢失了,发送端就永远不知道接收端的窗口恢复情况了。
所以发送端会定时发送带一个字节的ACK给接收端,查看接收端的确认报文中的窗口信息。
g. 保活定时器
由于物理原因,处于IDLE状态的TCP连接一端崩溃的时候,TCP有保活机制来判断对端是否仍然工作。这个设计存在争议,也许应用层应该实现该功能。RFC1122中有描述,保活定时器默认是关闭的。下面截取了一些RFC描述。
Implementors MAY include “keep-alives” in their TCP implementations,
although this practice is not universally accepted. If keep-alives
are included, the application MUST be able to turn them on or off for
each TCP connection, and they MUST default to off.
(4) TCP拥塞控制算法
慢启动、拥塞避免、快速重传和快速恢复
针对拥塞控制,主要有四种模型,即TCP TAHOE,TCP RENO,TCP NEWRENO和TCP SACK。TCP TAHOE模型是最早的TCP协议之一,它由Jacobson提出。
Jacobson观察到,TCP报文段(TCP Segment)丢失有两种原因,其一是报文段损坏,其二是网络阻塞,而当时的网络主要是有线网络,不易出现报文段损坏的情况,网络阻塞为报文段丢失的主要原因。针对这种情况,TCP TAHOE对原有协议进行了性能优化,其特点是,在正常情况下,通过重传计时器是否超时和是否收到重复确认信息(dupack)这两种丢包监测机制来判断是否发生丢包,以启动拥塞控制策略;在拥塞控制的情况下,采用慢速启动(Slow Start)算法和“拥塞避免”(Congestion Avoidance)算法来控制传输速率。 1990年出现的TCP Reno版本增加了“快速重传 ”(Fast Retransmit)、“快速恢复”(Fast Recovery)算法,避免了网络拥塞不严重时采用“慢启动”算法而造成过度减小发送窗口尺寸的现象,这样TCP的拥塞控制就主要由这4个核心算法组成。
a. 超时与重传
RTT的计算与RTO的计算
b. 慢启动和拥塞避免算法
慢启动算法的目的是为了保证TCP发送方发送分组的速率应该匹配收到该分组确认报文的速率,这样的设计能够应用于低速链路的广域网应用。为了实现慢启动机制,为TCP连接增加了一个新的窗口,拥塞窗口cwnd,该窗口初始化为一个报文段(非一个字节,而是一个TCP最大传输报文段大小,MSS)。这样一个方向上的TCP连接有两个窗口,一个是接收窗口用于接收方的流量控制,一个是拥塞窗口用于发送方的流量控制。发送方以这两个窗口中的小值作为方式上限。
慢启动算法:指数算法,cwnd默认为1,当收到一个ack确认时候,cwnd增加为2,当收到两个ack确认时候,cwnd增加为4,接着8,…
拥塞避免算法的目的,是为了防止中间路由器由于网络拥塞引起的数据包超时或者丢包。拥塞避免算法需要用到两个变量,一个是cwnd窗口大小,一个是ssthresh慢启动阈值,对于一个给定的初始连接,cwnd为1,ssthresh为65535。
当拥塞发生(超时或者重复确认),当拥塞发生时候,ssthresh被设置为cwnd和接收窗口中小值的一半,如果是超时引起的拥塞,则cwnd设置为1。
拥塞避免算法:如果cwnd大于ssthresh,每收到一个数据报文的确认,cwnd=cwnd+1/cwnd,cwnd窗口大小单位仍然是mss。
拥塞避免算法其实是和慢启动配合使用的。cwnd和ssthresh都是动态的值,虽然初始值为1和65535。
当真正拥塞发生的时候,如果是超时或重复ack引起的拥塞,ssthreash会置为cwnd和接收窗口大小的一半,cwnd会降为1,然后执行慢启动算法,直到cwnd大于ssthresh的时候,执行拥塞避免算法;
在慢启动算法期间和拥塞避免算法期间,TCP的发送速率都是在增长的,只是一个是指数增长方式,一个是线性增长方式。
c . 快速重传和快速恢复算法
TCP连接中有两种情况会引起重复的ack,一种是乱序报文,一种是丢包。
快速重传:当发送方收到三个重复的ack后,不会进入慢启动状态,而是立刻重传丢失的报文。因为只有接收方收到新的报文段的时候,才会发送重复的ack,这表明TCP连接上仍然有数据流动,所以应该避免使用慢启动降速。
快速恢复:
第一步,当收到第三个重复的ack的时候,ssthresh设置为当前cwnd的一半,重传丢失的报文。设置cwnd为ssthresh加上3倍的报文段大小(cwnd=cwnd/2 + 3)。
第二步,每收到一个重复的ack,cwnd增加1并发送一个分组。
第三步,当下一个确认新数据的ack到达的时候,设置cwnd为上面第一步中ssthresh值,这个ack应该是对重传报文的确认,同时也是对丢包后面的中间报文的确认。
最后,在收到三个重复ack的情况下,速度减半。
快速重传算法首次出现在4.3BSD的Tahoe版本,快速恢复首次出现在4.3BSD的Reno版本,也称之为Reno版的TCP拥塞控制算法。
可以看出Reno的快速重传算法是针对一个包的重传情况的,然而在实际中,一个重传超时可能导致许多的数据包的重传,因此当多个数据包从一个数据窗口中丢失时并且触发快速重传和快速恢复算法时,问题就产生了。因此NewReno出现了,它在Reno快速恢复的基础上稍加了修改,可以恢复一个窗口内多个包丢失的情况。具体来讲就是:Reno在收到一个新的数据的ACK时就退出了快速恢复状态了,而NewReno需要收到该窗口内所有数据包的确认后才会退出快速恢复状态,从而更一步提高吞吐量。
SACK就是改变TCP的确认机制,最初的TCP只确认当前已连续收到的数据,SACK则把乱序等信息会全部告诉对方,从而减少数据发送方重传的盲目性。比如说序号1,2,3,5,7的数据收到了,那么普通的ACK只会确认序列号4,而SACK会把当前的5,7已经收到的信息在SACK选项里面告知对端,从而提高性能,当使用SACK的时候,NewReno算法可以不使用,因为SACK本身携带的信息就可以使得发送方有足够的信息来知道需要重传哪些包,而不需要重传哪些包。
(5) TCP的应用
前几天和公司做防火墙限速的同事聊天, 我们公司新的防火墙限速实现方案就用到了TCP窗口机制. 众所周知, QoS除了分类,测速,队列还有调度一类的借助硬件的算法以外,在基于缓存或者丢包的限速基础上,最好还要降低TCP端到端的真正发送的速率,否则容易引起TCP的一系列拥塞控制动作。我们软件新的设计,就是通过修改ACK方向的通告窗口大小,来控制发送发的速率,能够在限速的基础上,同时降低发送方的发送速率。
转载申明
本文出自 “jasonccie” 博客















 1283
1283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









