






1.Xpath下载
在chrome浏览器拓展商店可以直接下载
如果要用edge浏览器,可以去 GitHub - eliasdorneles/xpath_helper: XPath Helper Chrome extension modded![]() https://github.com/eliasdorneles/xpath_helper
https://github.com/eliasdorneles/xpath_helper
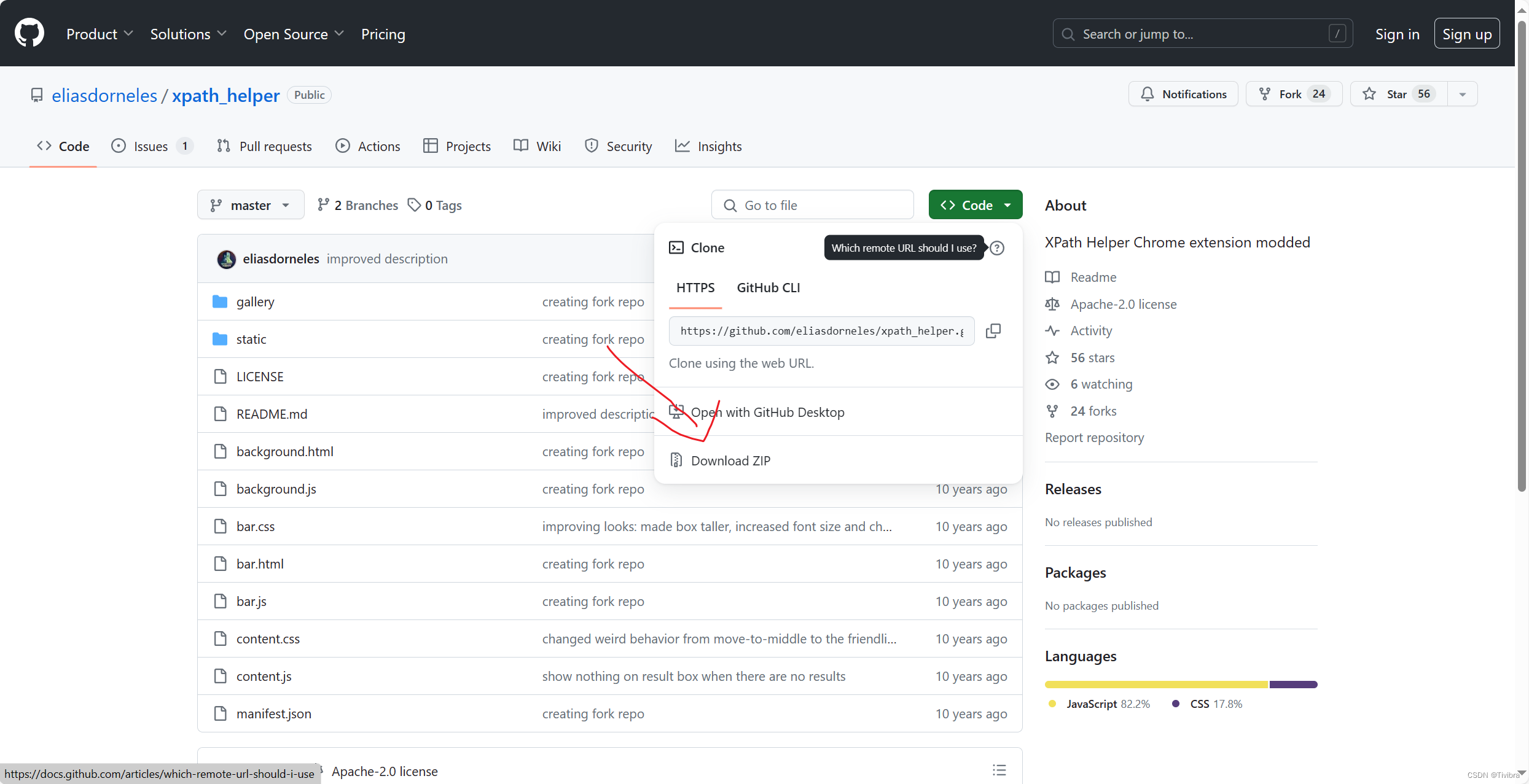
在这里下载并且导入edge拓展
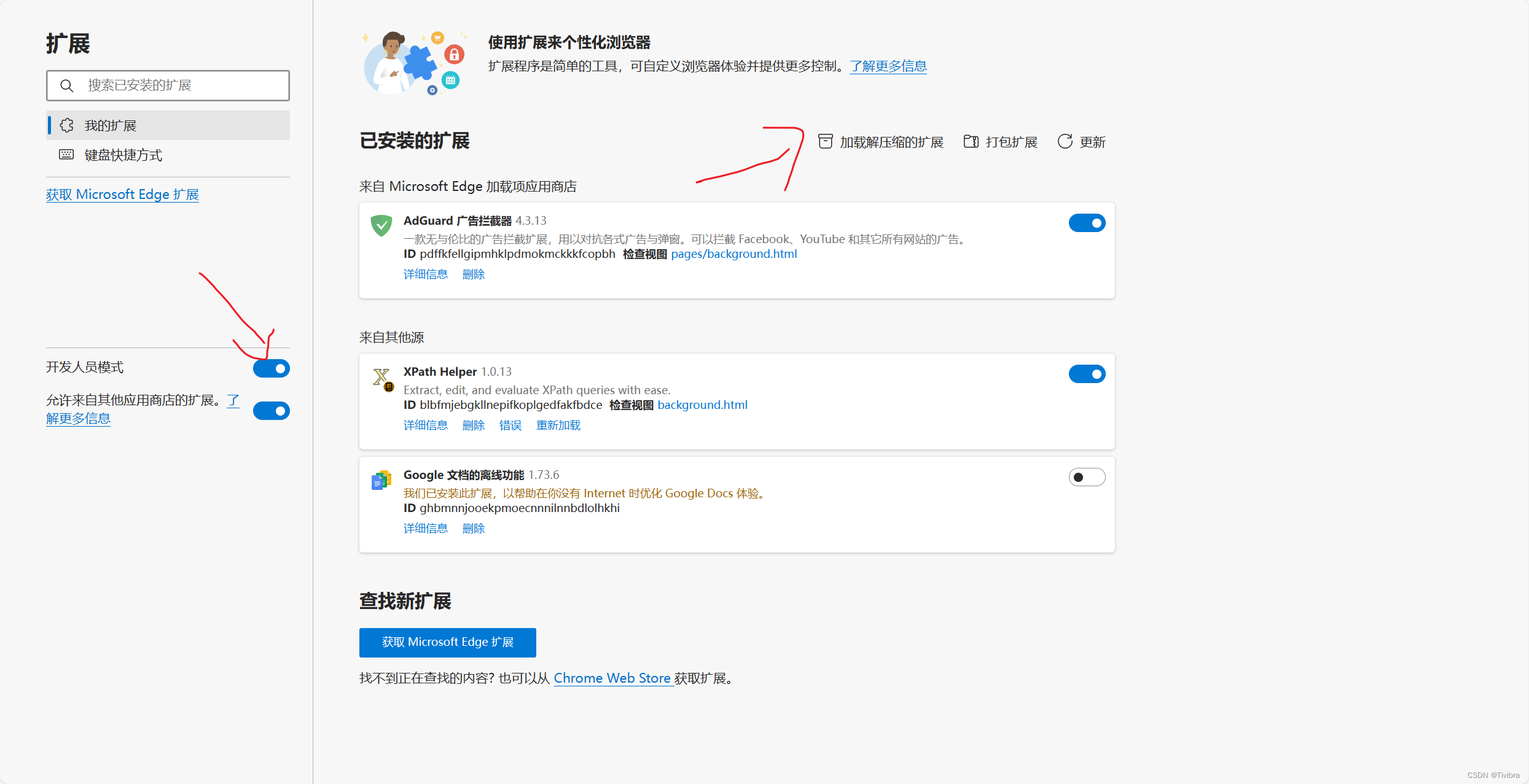
重启浏览器之后就可以使用了
记住浏览器初始界面不能使用 需要进入URL
Xpath快捷键是
ctrl + shift + X

出现黑框便是成功
2. 安装lxml
2.1 cmd安装
首先win+r打开cmd
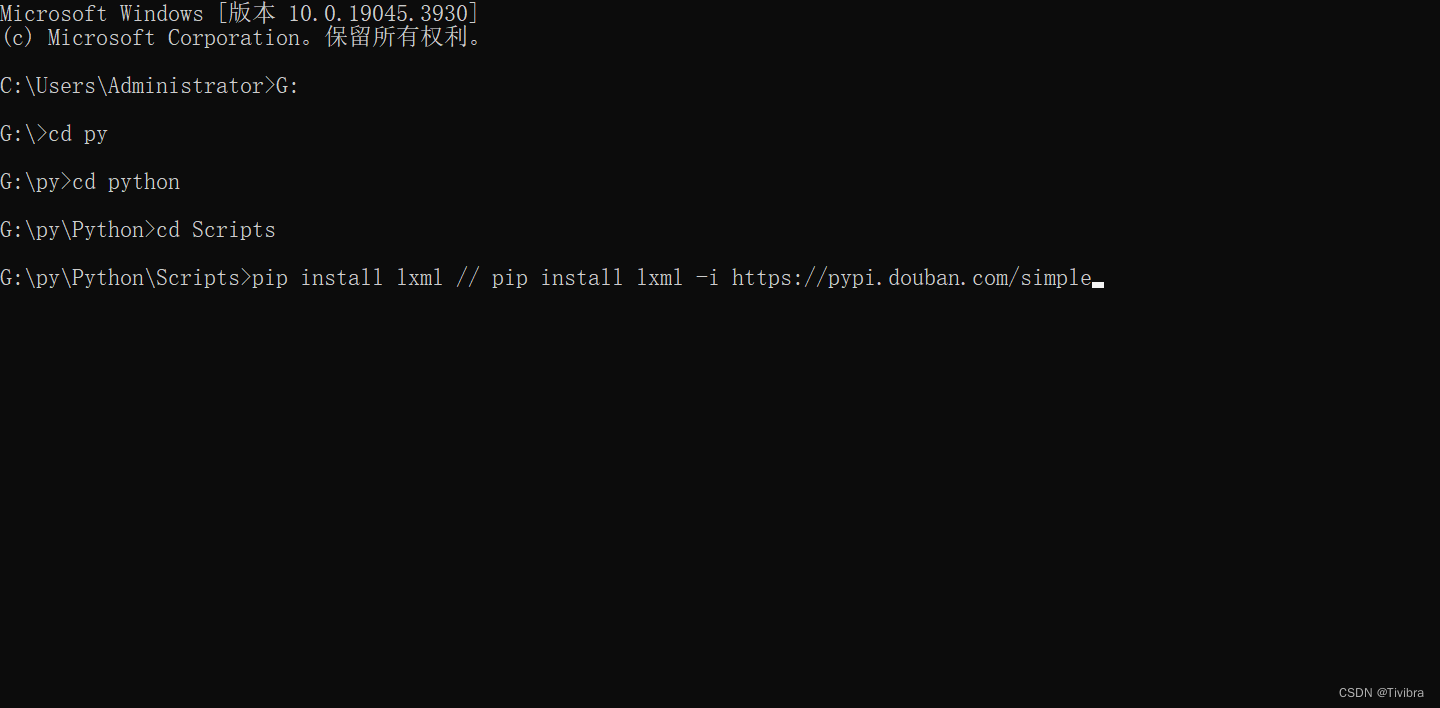
这里的路径寻找方法如下:
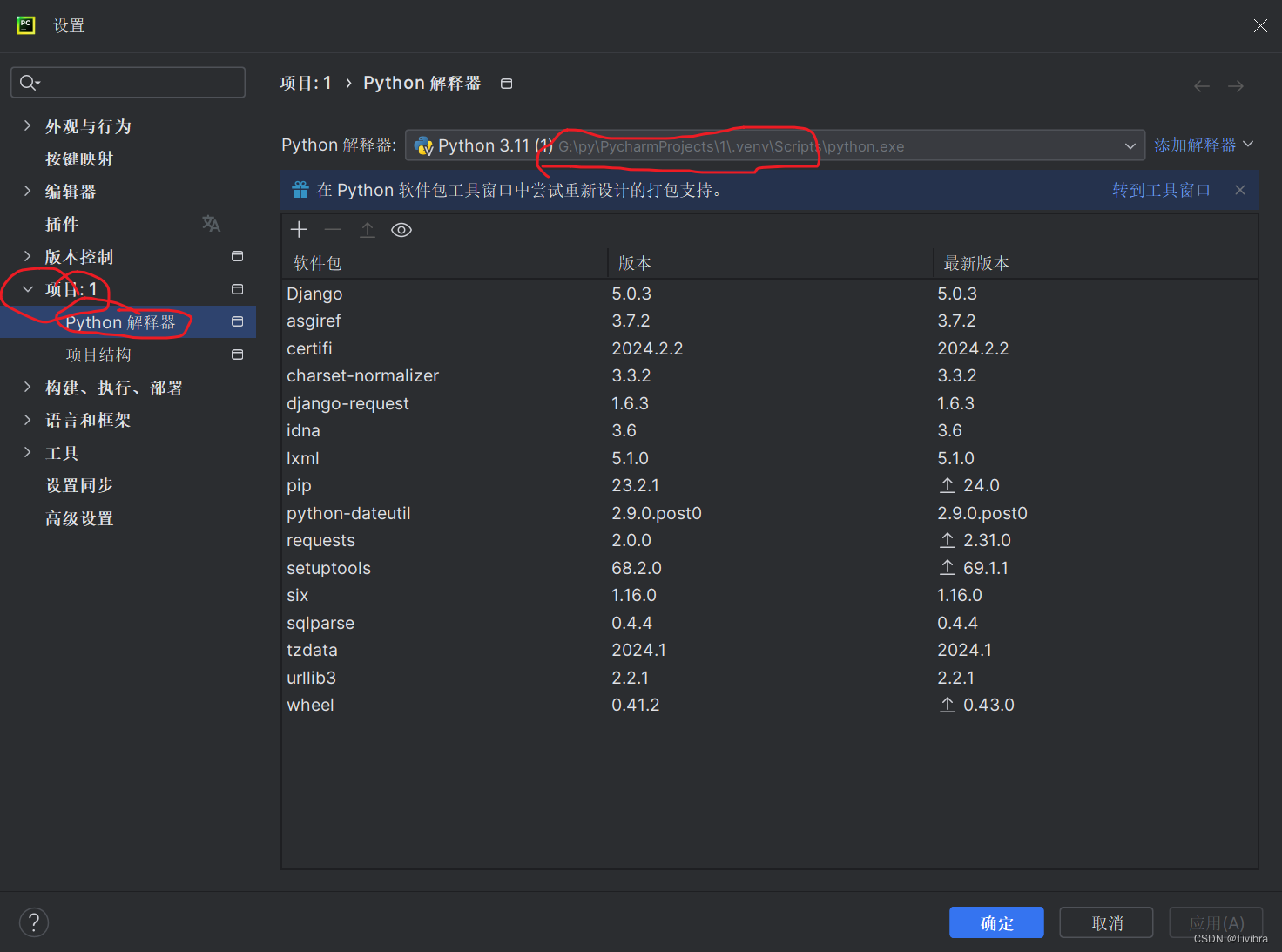
只需要在cmd中的命令按照流程找到路径下载就好了
这里下载有两个指令,第一种
pip install lxml
这是以国外路径下载的,获取比较慢,但第二种
pip install lxml -i http://pypi.douban.com/simple
这是国内路径下载,较快
2.2 pycharm直接安装
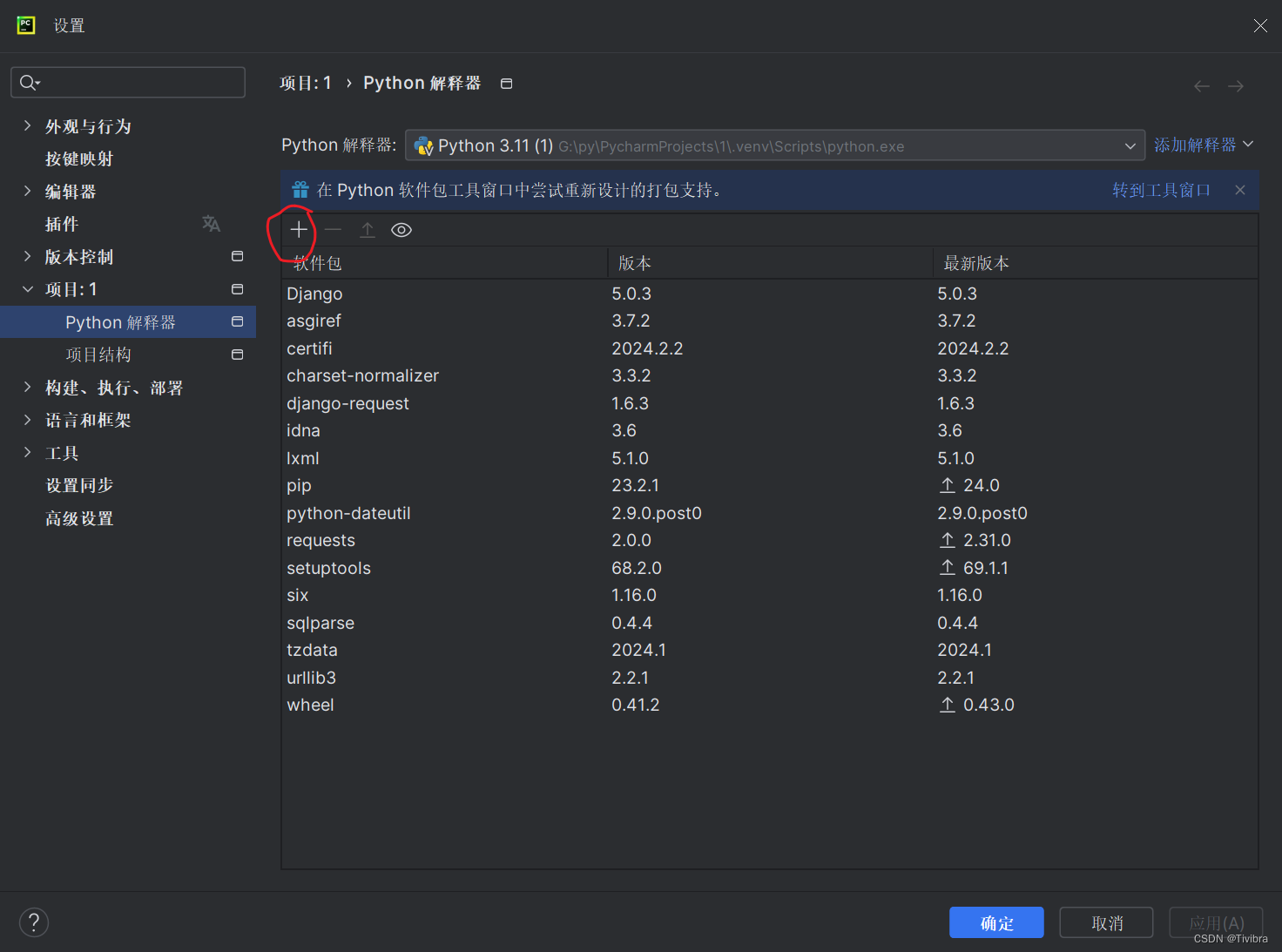
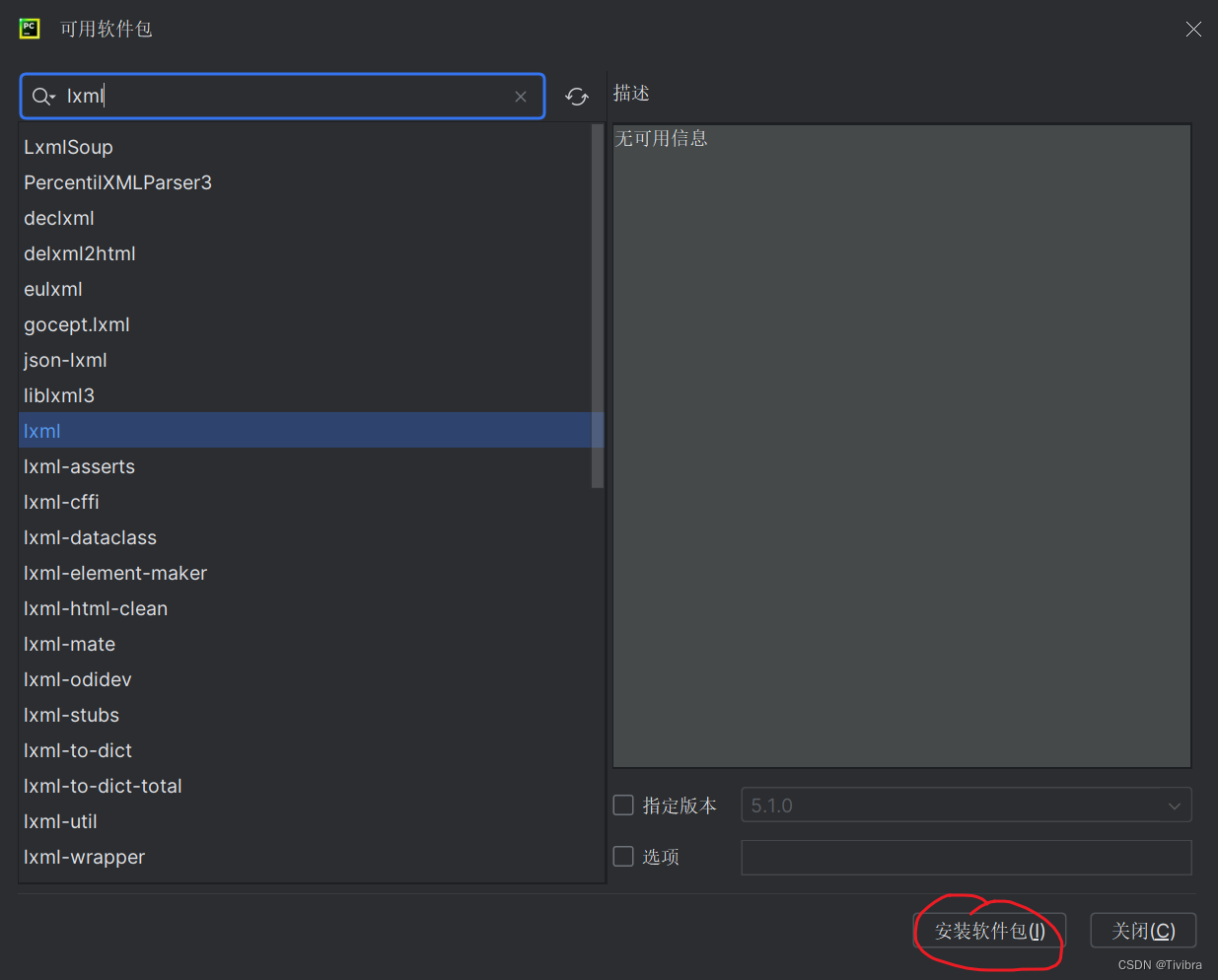
点击“+”,里面直接搜索lxml,找到并下载
安装完成后可以输出以下代码检查是否报错,不报错就是成功了
from lxml import etree如果报错了就去解释器里看看是否安装成功,或者重启尝试
3. xpath基本使用
3.1 解析本地文件
from lxml import etree
# xpath解析
# 1.本地文件 etree.parse
# 2.服务器响应的数据 response.read().decode('utf-8') *****常用 etree.HTML()
tree = etree.parse('解析-xpath的基本使用.html')
print(tree)在这之前我们新建一个html文件

随意输入一些数据
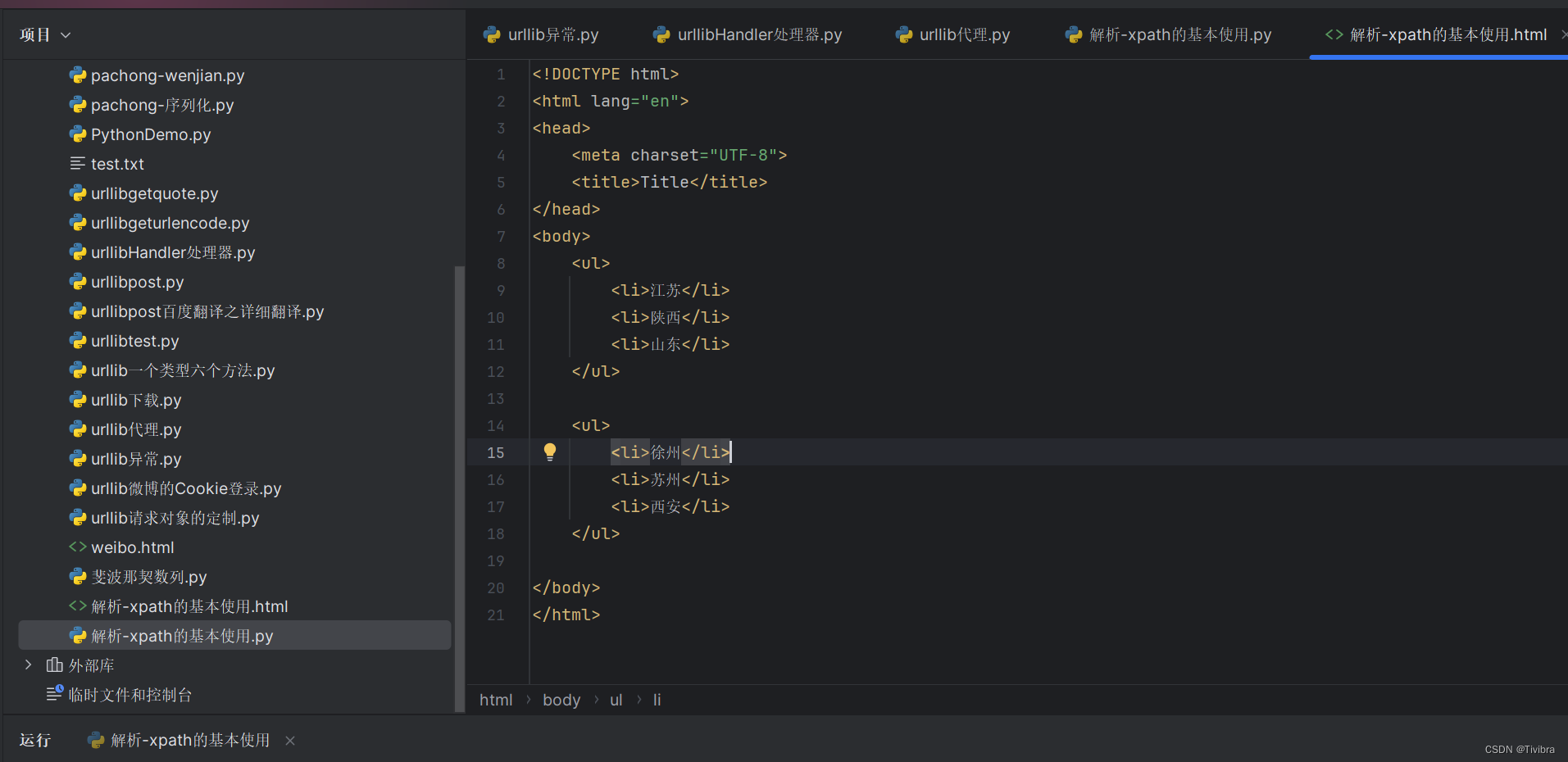
但是主代码运行之后会报错
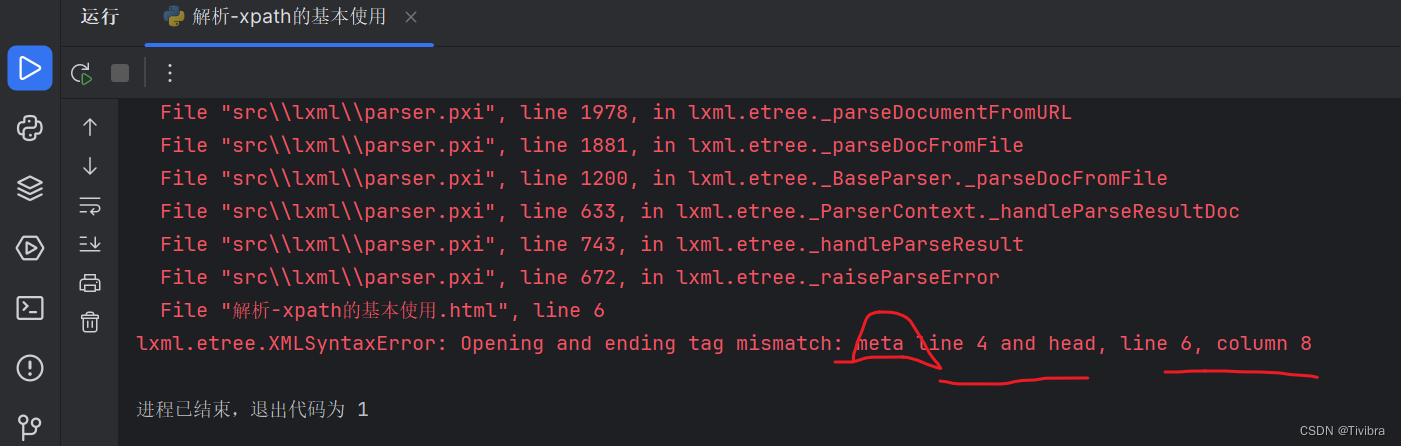
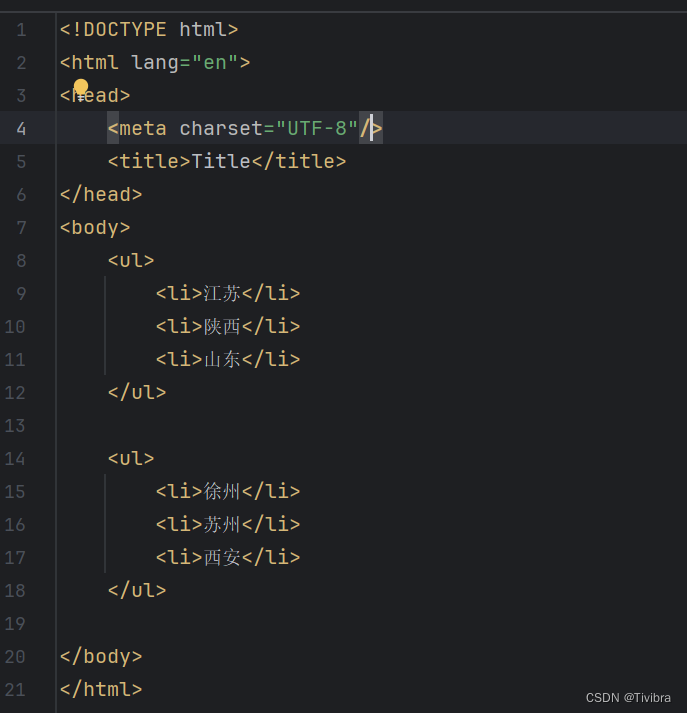
这里报错是因为xpath遵守html规范,但是我们的html中第四行缺少结束标签,于是我们给他结束
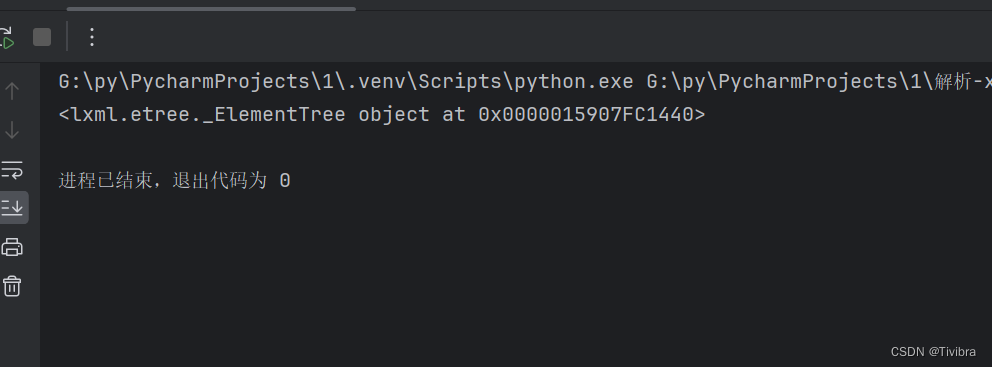
然后就可以得到我们 想要的东西了
3.2 xpath基本语法
3.2.1 路径查询
这里先注释掉第二个ul
from lxml import etree
tree = etree.parse('解析-xpath的基本使用.html')
# 查询信息
# 1.路径查询 tree.xpath('xpath路径')
# 查找ul下的li
# //是查找所有子孙节点,不考虑层次关系 /仅查找子节点
li_list = tree.xpath('//body/ul/li')# 或者是'//body//li'
print(li_list)
print(len(li_list))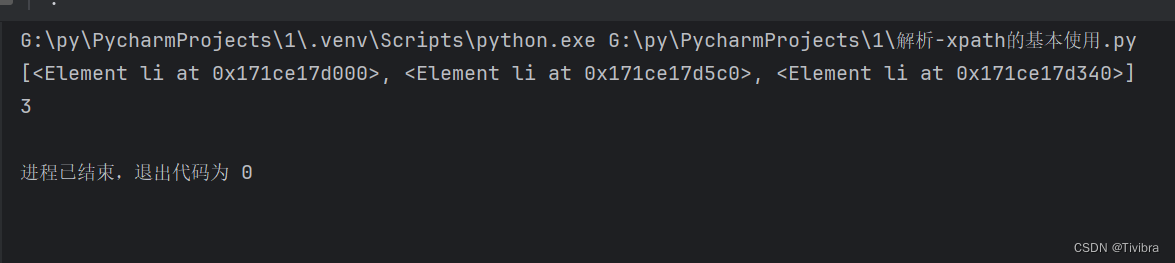
3.2.2谓词查询
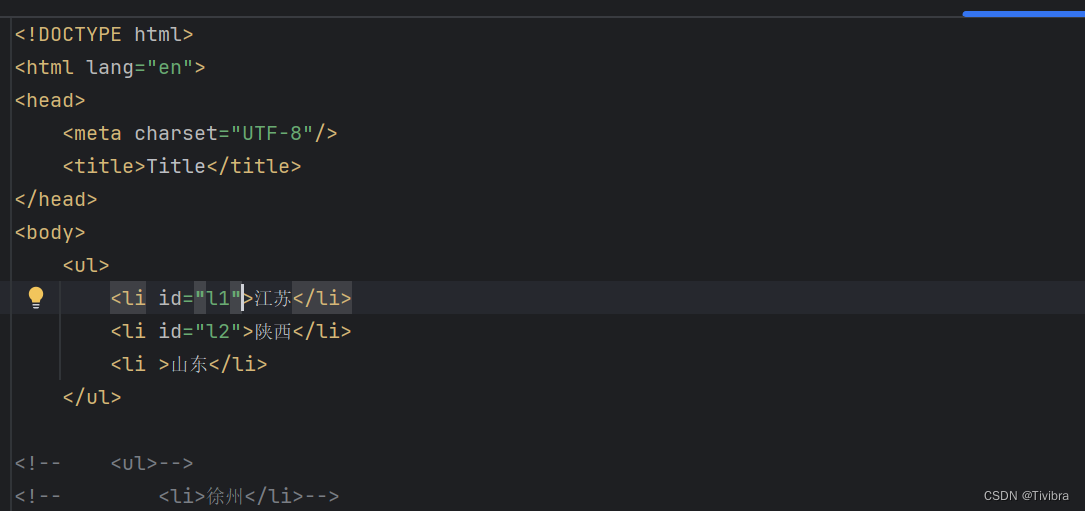
# 查找所有有id属性的li标签
# text()获取标签中的内容
li_list = tree.xpath('//ul/li[@id]text()')
print(li_list)
print(len(li_list))
# 找到id为l1的li标签
li_list = tree.xpath('//ul/li[@id="l1"]/text()')
print(li_list)
print(len(li_list))3.2.3 属性查询
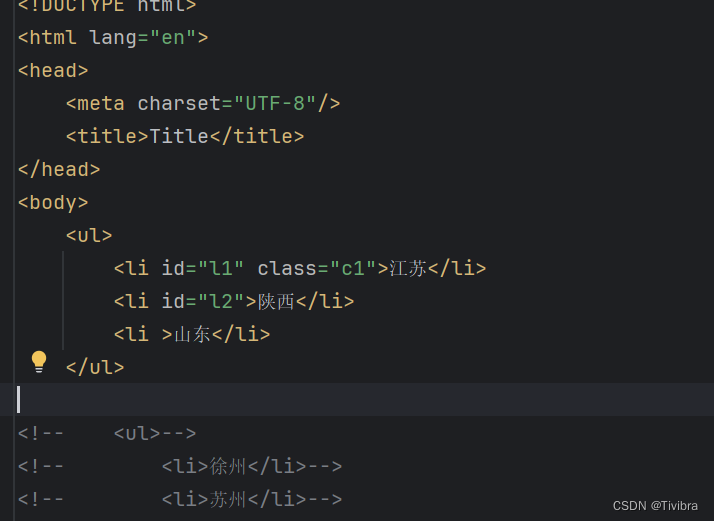
# 3.属性查询
# 查找到id为l1的li标签的class属性值
li_list = tree.xpath('//ul/li[@id="l1"]/@class')
print(li_list)
print(len(li_list))
3.2.4模糊查询
contains查询
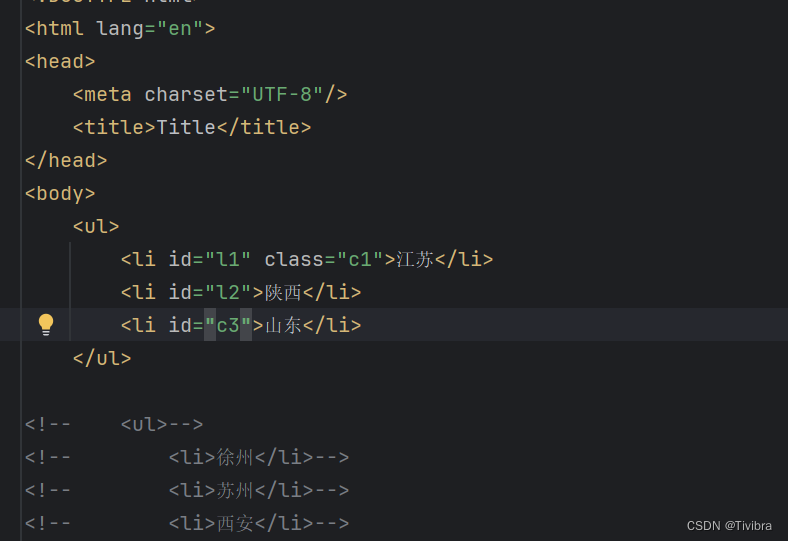
# 4.模糊查询
# 查询id中包含l的li标签
li_list = tree.xpath('//ul/li[contains(@id,"l")]/text()')
print(li_list)
print(len(li_list))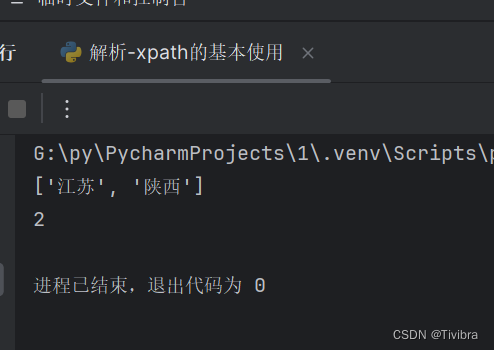
starts-with查询
# 查询id中包含c的li标签
li_list = tree.xpath('//ul/li[starts-with(@id,"c")]/text()')
print(li_list)
print(len(li_list))
3.2.5 逻辑查询
# 5.逻辑查询
# 查询id为l1和L2的li标签
li_list = tree.xpath('//ul/li[@id="l1"]/text() | //ul/li[@id="l2"]/text()')
print(li_list)
print(len(li_list))
# 5.逻辑查询
# 查询id为l1和class为c1的li标签
li_list = tree.xpath('//ul/li[@id="l1" and @class="c1"]/text()')
print(li_list)
print(len(li_list))
3.2.6 获取百度网站的‘百度一下’
首先找到‘百度一下’在那个标签处
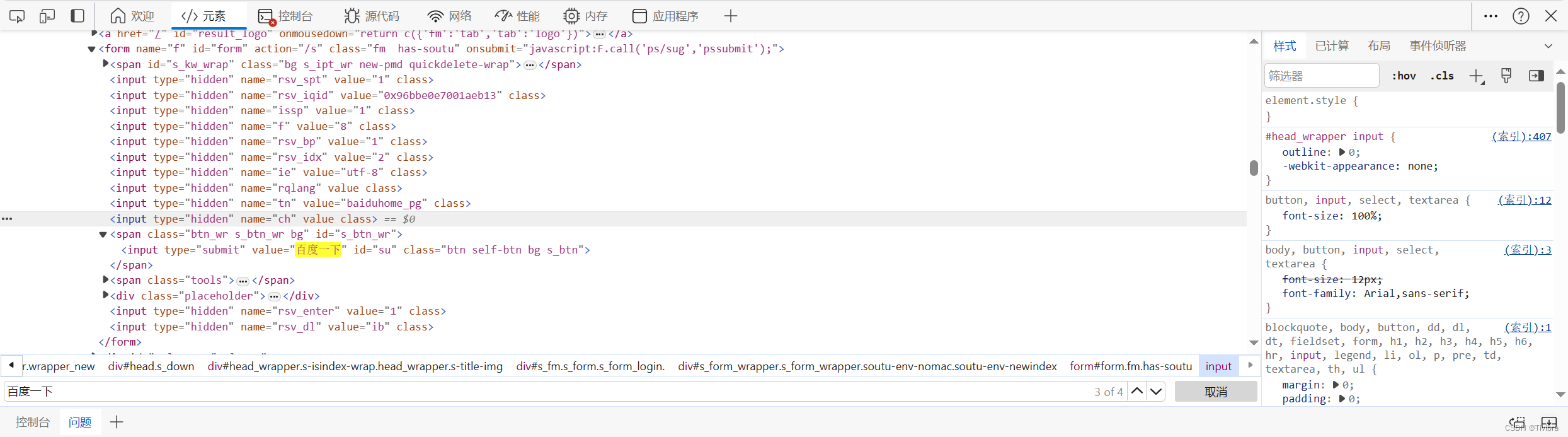
打开xpath,根据信息输入,对比结果
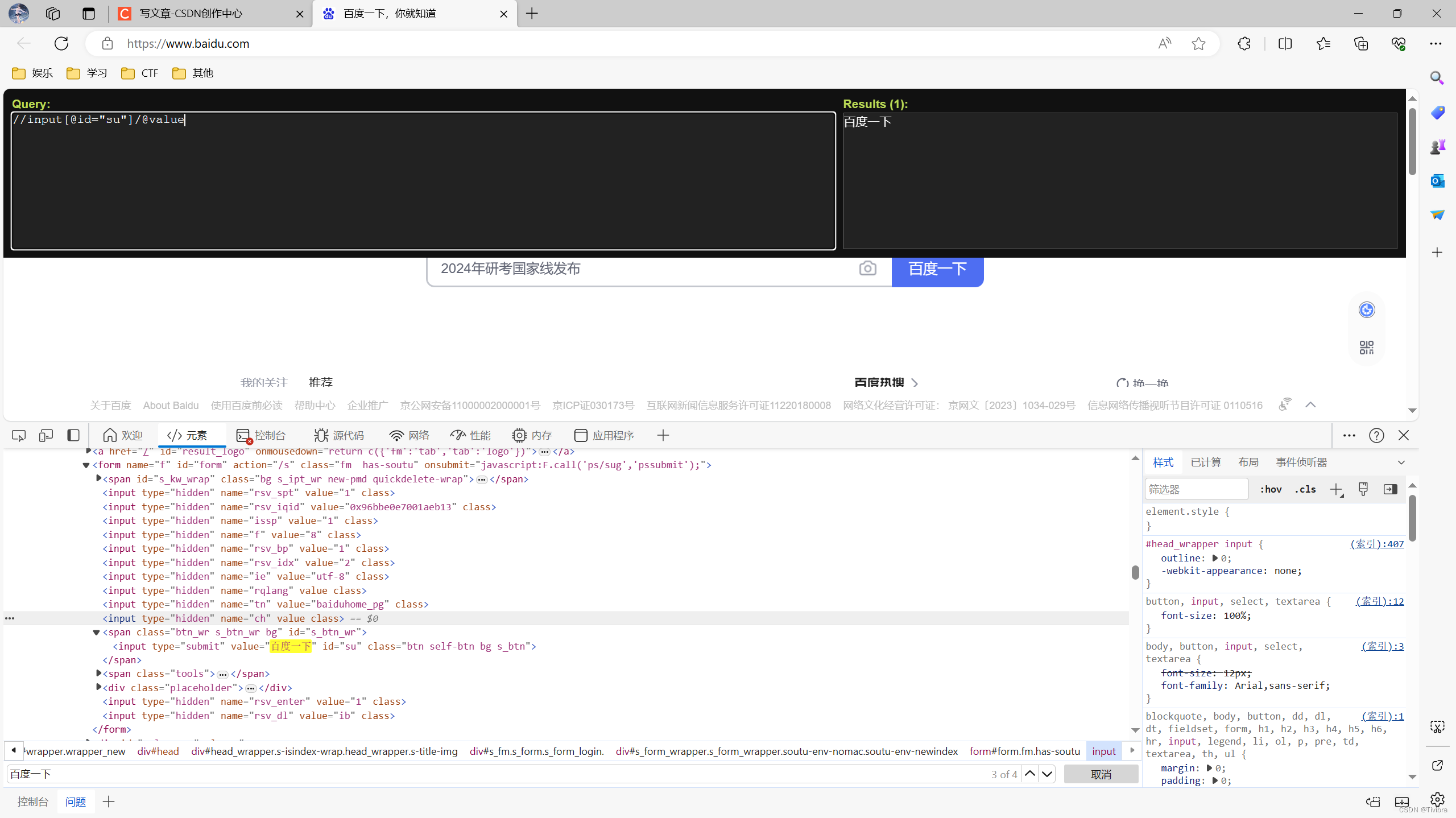
最终代码实现
import urllib.request
# 获取网页源码
url = 'https://www.baidu.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0',
}
request = urllib.request.Request(url = url,headers = headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# 解析网页源码,来获取我们想要的数据
from lxml import etree
# 解析服务器响应的文件
tree = etree.HTML(content)
# 获取想要的数据 xpath返回值是列表类型的数据 可以根据列表下标访问
result = tree.xpath('//input[@id="su"]/@value')[0]
print(result)


站长素材
一个找出正确url的小方法
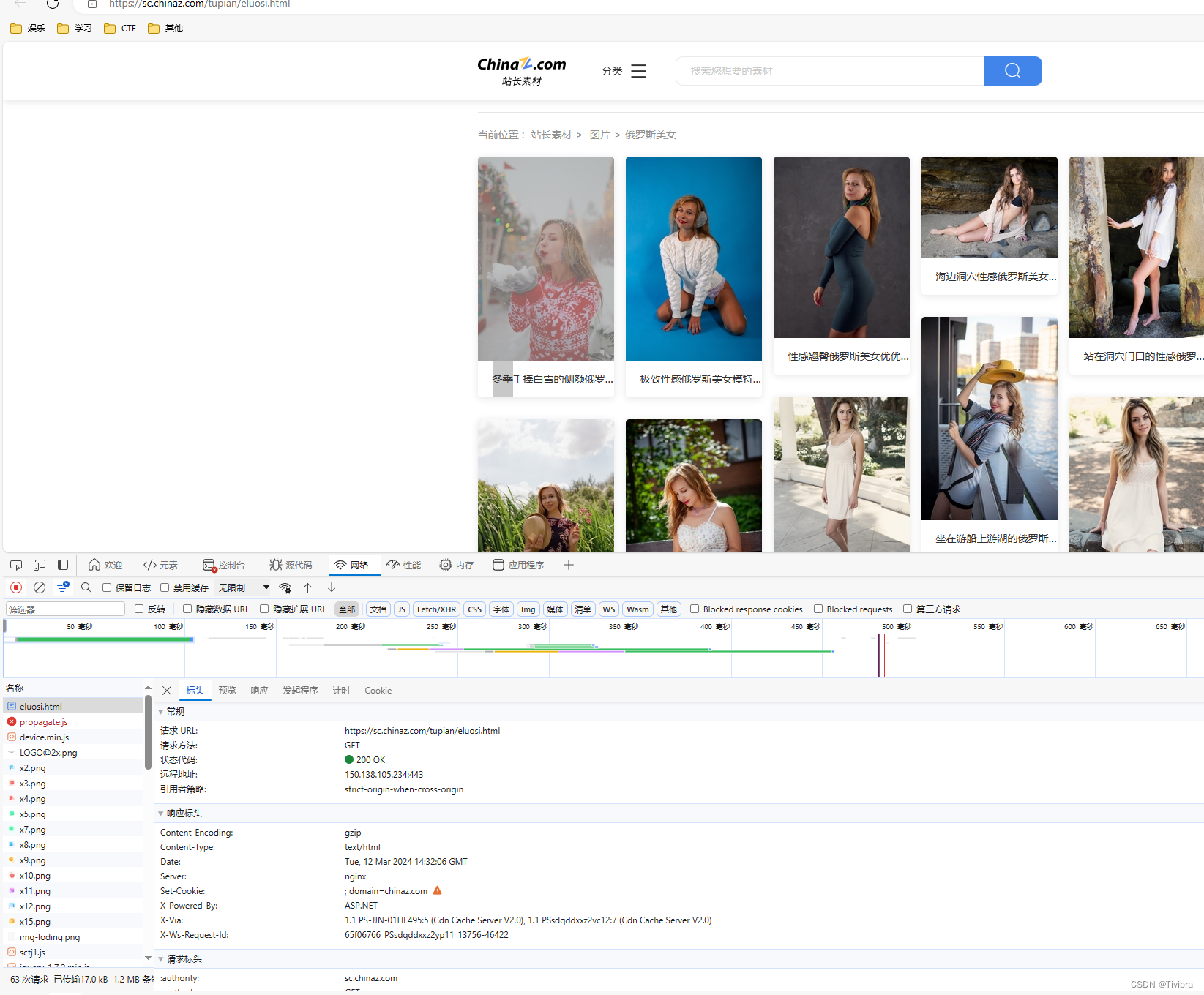
首先我们不能直接确定这个是不是正确的url,所以我们一般会去选择预览

但是这个蓝色字体我们点击之后却没有反应,这让我们开始疑惑这是不是正确的url
但是我们在这个url的响应栏去找寻答案时

我们把去这个地址检查后发现这是正确的图片
以此来看,我们可以确定这是我们所需要的url
下载站长素材的照片
进入图片的一种分类
首先我们在元素栏按 Ctrl+F 查找想要的图片信息

然后我们对准这一行点击右键


但是这样只能获得一张图片,我们总结规律,然后就可以得到系列图片,并且获得他的网址
所以我们应该使用的是‘/html/body/div[3]/div[2]/div/img/@data-original’
import urllib.request
from lxml import etree
def create_request(page):
if (page == 1):
url = 'https://sc.chinaz.com/tupian/eluosi.html'
else:
url = 'https://sc.chinaz.com/tupian/eluosi_' + str(page) + '.html'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0,'
}
request = urllib.request.Request(url = url,headers = headers)
return request
def get_content(request,page):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(content):
tree = etree.HTML(content)
name_list = tree.xpath('/html/body/div[3]/div[2]/div/img/@alt')
src_list = tree.xpath('/html/body/div[3]/div[2]/div/img/@data-original')
for i in range(len(name_list)):
name = name_list[i]
src = src_list[i]
url = 'https:' + src
urllib.request.urlretrieve(url = url,filename = './俄罗斯美女/' + name + '.jpg')
if __name__ == '__main__':
start_page = int(input('请输入开始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page,end_page+1):
request = create_request(page)
content = get_content(request,page)
down_load(content)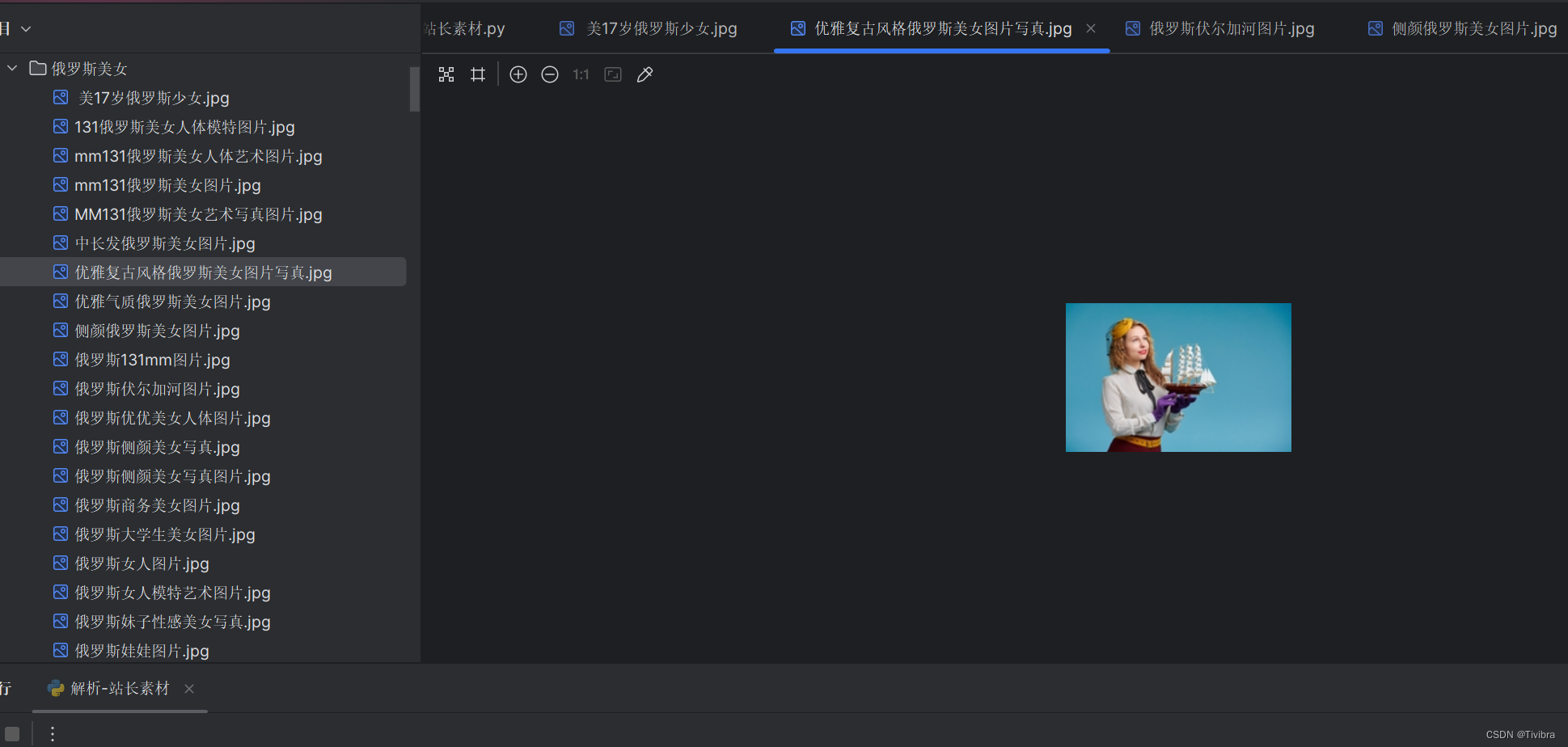
最后我们也是成功获得了这些图片















 706
706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









