









目录
1.免费下载插件链接(若失效评论区留言发送最新链接)(2023.7亲测可用)
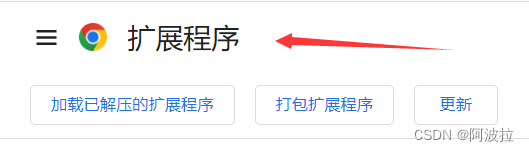
(1)打开chrome浏览器页面,点击:右上角三个点 > 扩展程序 > 管理拓展程序 (若没找到点更多工具)
(3)将刚刚下载好的插件直接拖到该页面中(注意:这里90%不成功!!!)
(8)快捷键ctrl+shift+X 开启 xpath-helper插件。或者点击右上角图标(关闭与开启操作一样)
1.免费下载插件链接(若失效评论区留言发送最新链接)(2023.7亲测可用)
baidu网盘链接:https://pan.baidu.com/s/14QDEOHUBO7t1Dfa1JnrkGA?pwd=syjh
提取码:syjh
若上一个链接下载失败,使用下面这个,下面这个直接是zip文件
链接:https://pan.baidu.com/s/1npkQhr28b3I28x2LrRQThQ?pwd=syjh
提取码:syjh
2.安装插件
(1)打开chrome浏览器页面,点击:右上角三个点 > 扩展程序 > 管理拓展程序 (若没找到点更多工具)

(2)打开右上角开发者模式

(3)将刚刚下载好的插件直接拖到该页面中(注意:这里90%不成功!!!)
由于浏览器的版本,大多数情况浏览器无法识别该插件,会在页面上方出现以下报错

(4) 此时我们将刚刚下载好的插件进行改名,并解压
将后缀 .crx 改为.zip,如图所示
然后将该文件解压到文件夹中,如图
![]()
(5)加载已解压的拓展程序
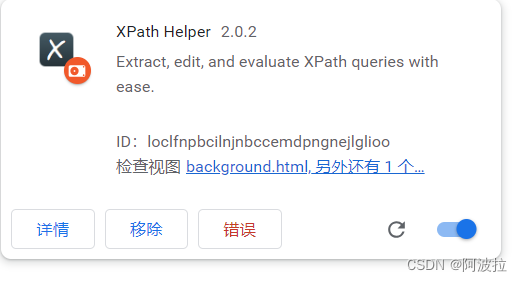
点击浏览器中的“加载已解压的拓展程序”按钮,选择刚刚解压的文件夹的路径

选择后会出现如下界面,将右下角按钮点开(默认可能已为打开)
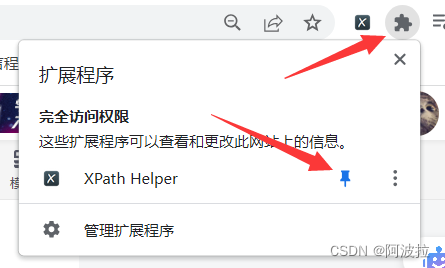
(6)将插件固定在右上角拓展程序中
如下图点击
(7)重启谷歌浏览器
(8)快捷键ctrl+shift+X 开启 xpath-helper插件。或者点击右上角图标(关闭与开启操作一样)
快捷键ctrl+shift+X
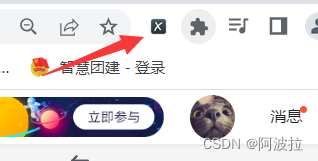
(9) 出现以下界面则xpath插件安装成功!!!
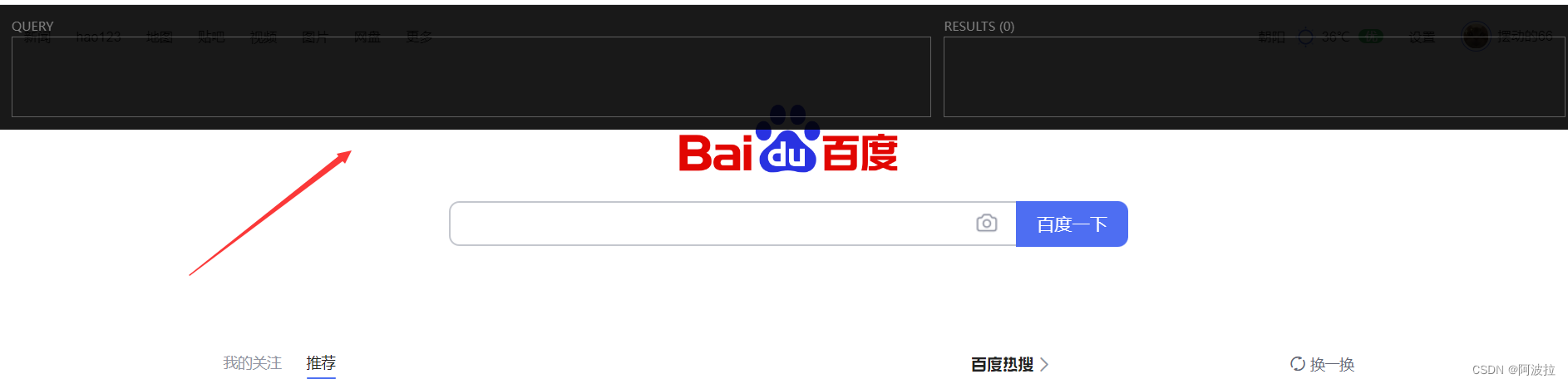
若有问题,欢迎评论区或私信讨论!!


















 113
113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









