






图片中的文字怎么提取出来?图片中的文字需要手动输入或复制粘贴到其他文档中,而通过提取文字,可以节省用户的时间和劳动力。用户可以使用提取文字功能,快速地将图片中的文字提取出来,并且避免手动输入或复制粘贴的繁琐步骤,获得更好的用户体验和更高效的工作流程。那么怎么提取图片中的文字呢?给大家分享几种简单方法,一起来学习吧。

方法一:迅捷拼图助手
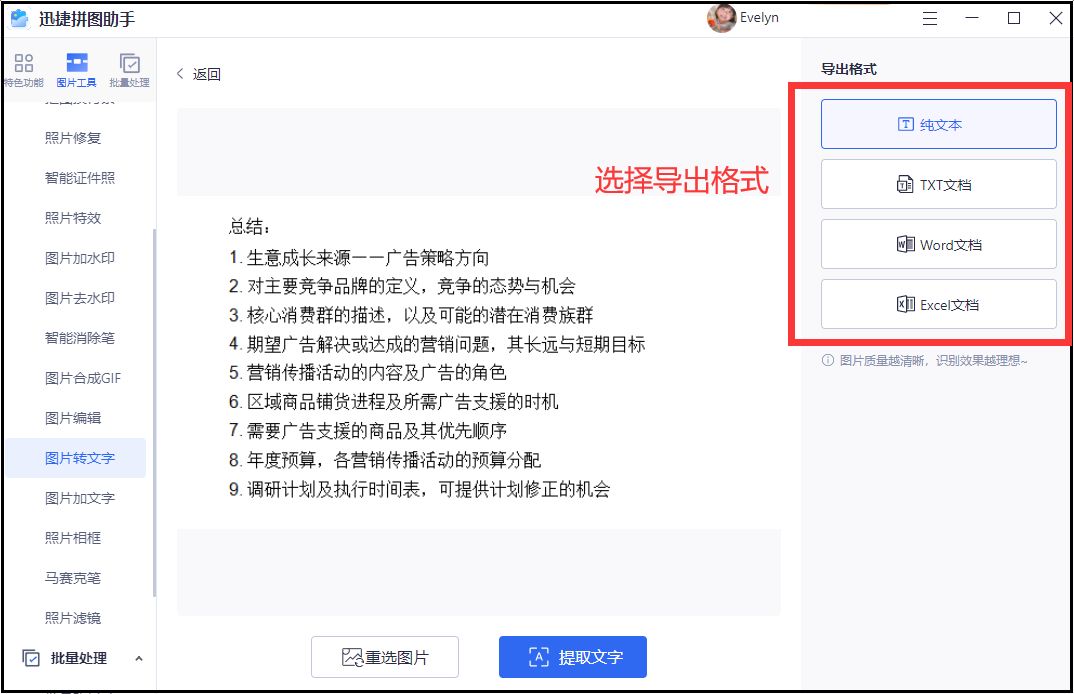
这是一款功能强大的图片处理工具,其中包括了图片转文字的功能。用户可以通过简单的操作,将图片中的文字提取出来,以便进行搜索、翻译和编辑等操作。操作起来很简单,只需要打开需要转换的图片,然后点击转文字按钮即可,就会自动识别图片中的文字,可以选择导出的格式,也能随时复制和粘贴这些文本内容到其他文档中。
方法二:图片编辑助手
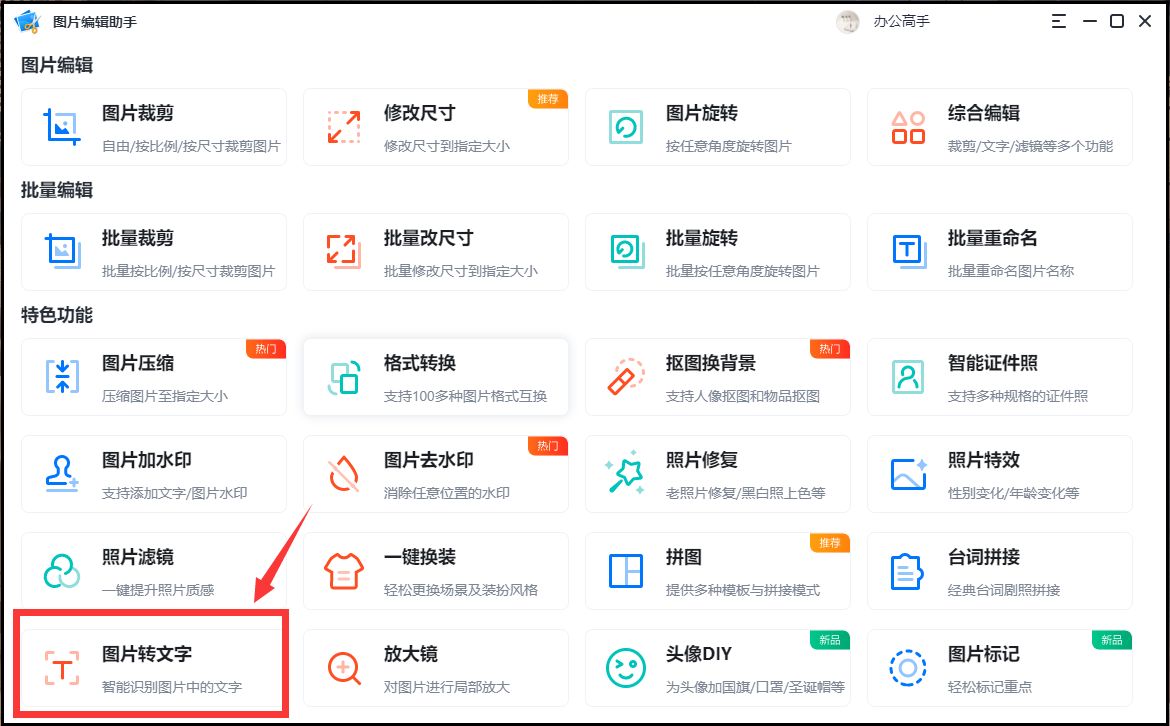
这也是一个专业的图片编辑工具,可以裁剪图片、图片编辑、图片格式转换、拼图、压缩等操作,非常全面。我们在左下角点击“图片转文字”,将需要识别文字的图片给添加进来,就可以提取出图片中的文字啦,非常简单,它的诸多其他功能大家也可以了解下。
方法三:Easy Screen OCR
这是一款简单易用的OCR软件,可以将屏幕截图、网页截图等图片转换为可编辑的文本。支持多种语言,包括中文、英文、日文等。该软件还支持截图后自动识别文字,节省了手动上传图片的时间,非常方便。

方法四:改图鸭
这是一款功能强大的图片处理工具,它提供了多种实用的图片处理功能,其中图片转文字功能是其中之一。可以将图片中的文字内容快速转换为可编辑的文本格式,便于进一步编辑和使用。该功能支持多种文字识别语言,包括中文、英文、日文等,并且具有较高的识别准确率。只需上传图片并选择识别语言,即可轻松获取图片中的文字内容,方便快捷。

好了,如何提取图片中的文字方法分享给大家啦,简单高效,能够帮助我们节约不少时间,有需要的小伙伴就去尝试下吧,希望可以帮助到大家。














 5384
5384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









