










1. 镜像
1.1 镜像是什么
镜像(images)是一种轻量级、可执行的独立软件包,它包含运行某个软件所需的所有内容
-
我们把应用程序和配置依赖打包好形成一个可交付的运行环境(包括代码、运行时需要的库、环境变量和配置文件等),
这个打包好的运行环境就是image镜像文件
只有通过这个镜像文件才能生成Docker容器实例(类似Java中new出来一个对象)。
1.2 分层拉取
以我们的pull为例,在下载的过程中我们可以看到docker的镜像好像是在一层一层的在下载
1.3 UnionFS(联合文件系统)
Union文件系统(UnionFS)是一种**分层、轻量级并且高性能的文件系统**,它支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下(unite several directories into a single virtual filesystem)
Union 文件系统是 Docker 镜像的基础。
镜像可以通过分层来进行继承,基于基础镜像(没有父镜像),可以制作各种具体的应用镜像。
**特性:**一次同时加载多个文件系统,但从外面看起来,只能看到一个文件系统,联合加载会把各层文件系统叠加起来,这样最终的文件系统会包含所有底层的文件和目录
1.4 Docker镜像加载原理
docker的镜像实际上由一层一层的文件系统组成,这种层级的文件系统UnionFS。
bootfs(boot file system)主要包含bootloader和kernel, bootloader主要是引导加载kernel
-
Linux刚启动时会加载bootfs文件系统
在Docker镜像的最底层是引导文件系统bootfs。
这一层与我们典型的Linux/Unix系统是一样的,包含boot加载器和内核。
-
当boot加载完成之后整个内核就都在内存中了,此时内存的使用权已由bootfs转交给内核,此时系统也会卸载bootfs。
rootfs (root file system),在bootfs之上。
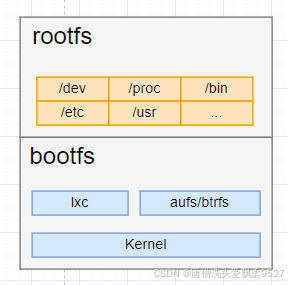
包含的就是典型 Linux 系统中
- /dev
- /proc
- /bin
- /etc
- 等标准目录和文件
rootfs就是各种不同的操作系统发行版,比如Ubuntu,Centos等等。
1.4.1 镜像的大小
平时我们安装进虚拟机的CentOS都是好几个G,为什么docker的镜像才200M??

对于一个精简的OS,rootfs可以很小,只需要包括最基本的命令、工具和程序库就可以了,因为底层直接用Host的kernel,自己只需要提供 rootfs 就行了。
由此可见对于不同的linux发行版, bootfs基本是一致的, rootfs会有差别, 因此不同的发行版可以公用bootfs。
1.5 为什么采取分层架构
镜像分层有这么些好处
-
共享资源
-
方便复制迁移
-
可以复用
比如说有多个镜像都从相同的 base 镜像构建而来,那么 Docker Host 只需在磁盘上保存一份 base 镜像;
同时内存中也只需加载一份 base 镜像,就可以为所有容器服务了。
而且镜像的每一层都可以被共享。
1.6 要点
Docker镜像层都是只读的,容器层是可写的
当容器启动时,一个新的可写层被加载到镜像的顶部
这一层通常被称作容器层,“容器层”之下的都叫作:镜像层
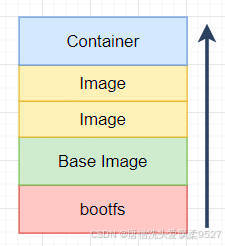
当容器层启动时,一个新的可写层被加载到镜像的顶部
所有对容器的改动(添加、删除、修改)都只会发生再容器层中
只有容器层是可写的,容器层下面的所有镜像层都是只读的
1.7 commit
docker commit 容器ID
commit提交容器副本使之成为一个新的镜像
具体参数:
docker commit -m="提交的描述信息" -a="作者" 容器ID 要创建的目标镜像名:[标签名]
Docker中的镜像分层,支持通过扩展现有镜像,创建新的镜像
类似Java继承于一个Base基础类,自己再按需扩展。
新镜像是从 base 镜像一层一层叠加生成的。每安装一个软件,就在现有镜像的基础上增加一层
2. 容器数据卷
容器数据卷,亦可以说是数据映射,将容器内部的目标文件或目录映射到本机的文件或目录中,这样就可以通过本机的文件来操控容器内的文件了
这样方便我们对于容器的配置
使用命令:
docker run -it --privileged=true -v /宿主机绝对路径目录:/容器内目录 镜像名
2.1 宿主vs容器之间映射添加容器卷
直接命令添加
公式:
docker run -it -v /宿主机目录:/容器内目录 ubuntu /bin/bash
# 例如
docker run -it --name myu3 --privileged=true -v /tmp/myHostData:/tmp/myDockerData ubuntu /bin/bash
docker run -it --privileged=true -v /宿主机绝对路径目录:/容器内目录 镜像名
查看数据卷是否挂载成功
docker inspect 容器ID

容器和宿主机之间数据共享
- docker修改,主机同步获得
- 主机修改,docker同步获得
- docker容器stop,主机修改,docker容器重启看数据是否同步
2.2 读写规则映射添加说明
2.2.1 读写(默认)
docker run -it -v /宿主机绝对路径目录:/容器内目录:rw 镜像名
2.2.2 只读
容器示例内部被限制,只能读取不能写
docker run -it -v /宿主机绝对路径目录:/容器内目录:ro 镜像名
ro :read only
此时如果宿主机写入内容,可以同步给容器内,容器可以读取到
2.3 卷的继承和共享
docker run -it --volumes-from 父类容器别名 --name 别名 镜像名
3. Mysql主从同步
3.1 新建主服务容器示例 3307
docker run -p 3307:3306 --name mysql-master \
-v /mydata/mysql-master/log:/var/log/mysql \
-v /mydata/mysql-master/data:/var/lib/mysql \
-v /mydata/mysql-master/conf:/etc/mysql/conf.d \
-e MYSQL_ROOT_PASSWORD=root \
--name mysql-master \
-d mysql:8.0.39
创建一个端口3307的 mysql:8.0.39 容器
日志目录映射在:/mydata/mysql-master/log
数据目录映射在:/mydata/mysql-master/data
配置目录映射在:/mydata/mysql-master/conf
3.2 创建配置文件
进入 /mydata/mysql-master/conf 目录下新建my.cnf 文件
[mysqld]
## 设置server_id,同一局域网中需要唯一
server_id=101
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能
log-bin=mall-mysql-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
当创建完毕后,需要重启master实例
docker restart mysql-master
3.3 创建数据同步用户
进入master3307容器,并登入mysql
docker exec -it mysql-master /bin/bash
mysql -u root -p root
在master3307容器内部,创建数据同步用户
CREATE USER 'slave'@'%' IDENTIFIED BY '123456';
GRANT REPLICATION SLAVE,REPLICATION CLIENT ON *.* To 'slave'@'%';
3.4 创建从容器实例3308
docker run -p 3308:3306 --name mysql-master \
-v /mydata/mysql-slave/log:/var/log/mysql \
-v /mydata/mysql-slave/data:/var/lib/mysql \
-v /mydata/mysql-slave/conf:/etc/mysql/conf.d \
-e MYSQL_ROOT_PASSWORD=root \
--name mysql-slave \
-d mysql:8.0.39
当创建完毕后,也需要重启slave实例
docker restart mysql-slave
3.5 配置主从同步
change master to master_host='192.168.81.102', master_user='slave', master_password='123456', master_port=3307, master_log_file='mall-mysql-bin.000001', master_log_pos=617, master_connect_retry=30 get_master_public_key=1;
参数说明:
| 参数 | 说明 |
|---|---|
| master_host | 主数据库的IP地址 |
| master_port | 主数据库的运行端口 |
| master_user | 在主数据库创建的用于同步数据的用户账号 |
| master_password | 在主数据库创建的用于同步数据的用户密码 |
| master_log_file | 指定从数据库要复制数据的日志文件,通过查看主数据的状态,获取File参数 |
| master_log_pos | 指定从数据库从哪个位置开始复制数据,通过查看主数据的状态,获取Position参数 |
| master_connect_retry | 连接失败重试的时间间隔,单位为秒 |
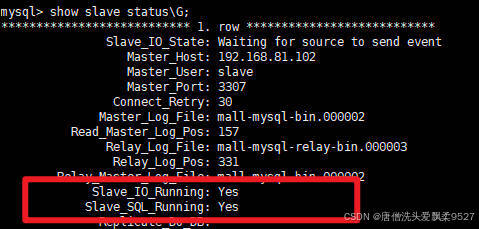
当 从库,IO和SQL都处于Yes状态,就代表主从同步成功
3.6 可能出现的报错:
3.6.1 日志不一致
Got fatal error 1236 from source when reading data from binary log: 'binlog truncated in the middle of event; consider out of disk space on source; the first event 'mall-mysql-bin.000001' at 617, the last event read from './mall-mysql-bin.000001' at 126, the last byte read from './mall-mysql-bin.000001' at 712.'
出现这种报错,可能代表你的主从日志不一致,这时候需要更改一下从库针对主库的日志版本即可
3.6.1.1 刷新主库日志
刷新binlog日志
flush logs;
刷新后的日志会+1
例如上面的 File: mysql-bin.000001 会变成 File: mysql-bin.000002
再次查看master状态
mysql> flush logs;
Query OK, 0 rows affected (0.02 sec)
mysql> show master status\G;
*************************** 1. row ***************************
File: mall-mysql-bin.000002
Position: 157
Binlog_Do_DB:
Binlog_Ignore_DB: mysql
Executed_Gtid_Set:
1 row in set (0.00 sec)
ERROR:
No query specified
3.6.1.2 修改从库
直接在原来的基本配置上进行修改
CHANGE MASTER TO MASTER_LOG_FILE='mall-mysql-bin.000002',MASTER_LOG_POS=157;
MASTER_LOG_FILE=主库日志版本(即是 File: mall-mysql-bin.000002)
MASTER_LOG_POS=主库位置(即是 Position: 157)
然后进行重启
start slave;
然后再进行查看从库状态
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for source to send event
Master_Host: 192.168.81.102
Master_User: slave
Master_Port: 3307
Connect_Retry: 30
Master_Log_File: mall-mysql-bin.000002
Read_Master_Log_Pos: 157
Relay_Log_File: mall-mysql-relay-bin.000003
Relay_Log_Pos: 331
Relay_Master_Log_File: mall-mysql-bin.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 157
Relay_Log_Space: 720
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 101
Master_UUID: aac84732-b850-11ef-a9a7-0242ac110003
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Replica has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
Master_public_key_path:
Get_master_public_key: 1
Network_Namespace:
1 row in set, 1 warning (0.00 sec)
ERROR:
No query specified
4. Redis集群
在处理非常多条数据缓存的场景,如何设计存储案例?
- redis进行分布式存储
4.1 三种分区
好比要缓存2~3亿数据
4.1.1 哈希取余分区
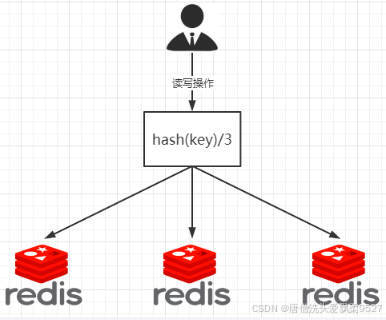
2亿条记录就是2亿个v,v,我们单机不行必须要分布式多机
假设有3台机器构成一个集群,用户每次读写操作都是根据公式
hash(key)%N
计算出哈希值,用来决定数据映射到哪一个节点上。
优点:
- 简单粗暴,直接有效只需要预估好数据规划好节点,例如3台、8台、10台,就能保证一段时间的数据支撑。
- 使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡+分而治之的作用。
缺点:
-
原来规划好的节点,进行扩容或者缩容就比较麻烦了,
不管扩缩,每次数据变动导致节点有变动,映射关系需要重新进行计算,在服务器个数固定不变时没有问题
如果需要弹性扩容或故障停机的情况下,原来的取模公式就会发生变化:
Hash(key)/3会变成Hash(key) /?此时地址经过取余运算的结果将发生很大变化,根据公式获取的服务器也会变得不可控。某个redis机器宕机了,由于台数数量变化,会导致hash取余全部数据重新洗牌。
4.1.2 一致性哈希算法分区
4.1.2.1 是什么?
一致性哈希算法在1997年由麻省理工学院中提出的,设计目标是为了解决:
- 分布式缓存数据变动和映射问题
- 例如:某个机器宕机了,分母数量改变了,自然取余数不OK了。
4.1.2.2 能干嘛?
提出一致性Hash解决方案
目的是当服务器个数发生变动时,尽量减少影响客户端到服务器的映射关系
4.1.2.3 三大步骤
4.1.2.3.1 算法构建一致性哈希环
一致性哈希算法必然有个hash函数并按照算法产生hash值,这个算法的所有可能哈希值会构成一个全量集,这个集合可以成为一个hash空间[0,2^32-1]
这个是一个线性空间,但是在算法中,我们通过适当的逻辑控制将它首尾相连(0 = 2^32),这样让它逻辑上形成了一个环形空间。
它也是按照使用取模的方法,前面笔记介绍的节点取模法是对节点(服务器)的数量进行取模
而一致性Hash算法是对2^32 取模,简单来说:
-
一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,
如假设某哈希函数H的值空间为0-2^32-1 (即哈希值是一个32位无符号整形),整个哈希环如下图:

整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、……直到2^32-1 ,也就是说0点左侧的第一个点代表2^32-1, 0和2^32-1 在零点中方向重合,我们把这个由2^32 个点组成的圆环称为Hash环。
4.1.2.3.2 节点映射
将集群中各个IP节点映射到环上的某一个位置。
将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置。
假如4个节点NodeA、B、C、D,经过IP地址的哈希函数计算(hash(ip)),使用IP地址哈希后在环空间的位置如下:
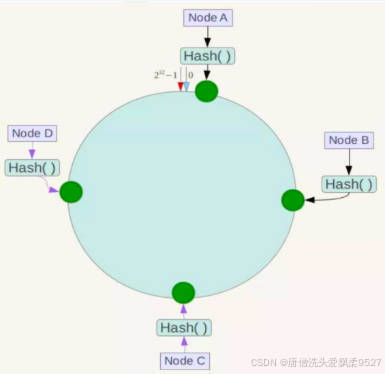
4.1.2.3.3 key落到服务器的落键规则
当我们需要存储一个kv键值对时,首先计算key的hash值,hash(key),将这个key使用相同的函数Hash计算出哈希值并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器,并将该键值对存储在该节点上。
如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:
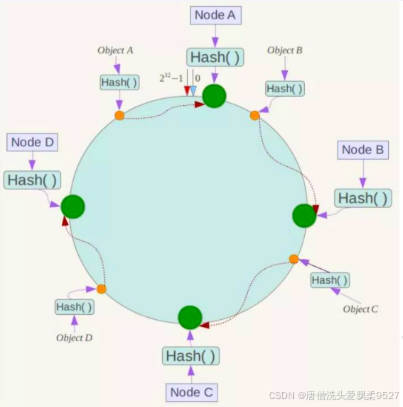
根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。
4.1.2.3 优点
4.1.2.3.1 容错性:
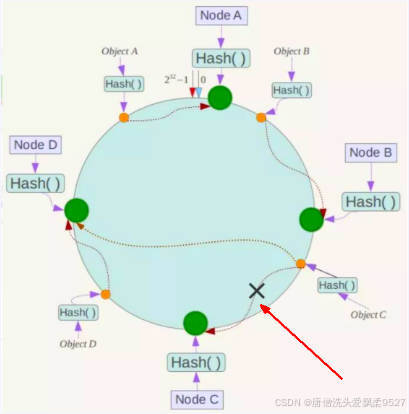
假设Node C宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
简单说,就是C挂了,受到影响的只是B、C之间的数据,并且这些数据会转移到D进行存储。
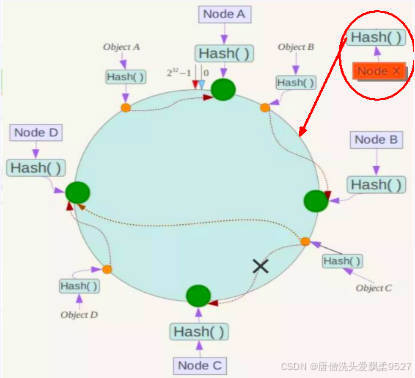
4.1.2.3.2 扩展性:
数据量增加了,需要增加一台节点NodeX,X的位置在A和B之间,那收到影响的也就是A到X之间的数据,重新把A到X的数据录入到X上即可,不会导致hash取余全部数据重新洗牌。
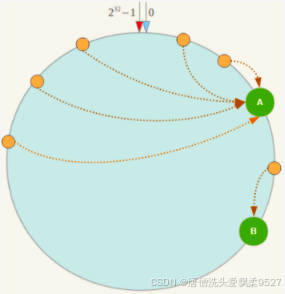
4.1.2.4 缺点:Hash换的数据倾斜问题
一致性Hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,
例如系统中只有两台服务器:
4.1.2.5 一致性Hash分区小结
为了在节点数目发生改变时尽可能少的迁移数据
将所有的存储节点排列在收尾相接的Hash环上,每个key在计算Hash后会顺时针找到临近的存储节点存放。
而当有节点加入或退出时仅影响该节点在Hash环上顺时针相邻的后续节点。
- 优点
加入和删除节点只影响哈希环中顺时针方向的相邻的节点,对其他节点无影响。
- 缺点
数据的分布和节点的位置有关,因为这些节点不是均匀的分布在哈希环上的,所以数据在进行存储时达不到均匀分布的效果。
4.1.3 哈希槽分区
4.1.3.1 是什么?
- 为什么出现
哈希槽实质就是一个数组,数组[0,2^14 -1]形成hash slot空间。
- 能干什么
解决均匀分配的问题,在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系,现在就相当于节点上放的是槽,槽里放的是数据。
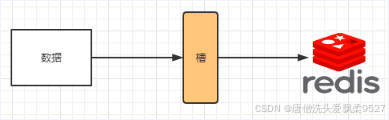
槽解决的是粒度问题,相当于把粒度变大了,这样便于数据移动。
哈希解决的是映射问题,使用key的哈希值来计算所在的槽,便于数据分配。
- 多少个hash槽
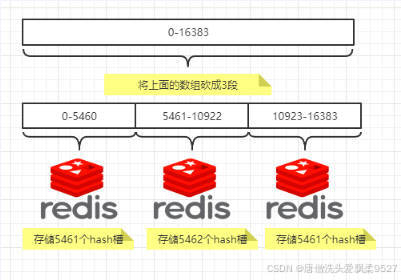
一个集群只能有16384个槽,编号 0-16383(0-2^14-1)。
这些槽会分配给集群中的所有主节点,分配策略没有要求。可以指定哪些编号的槽分配给哪个主节点。集群会记录节点和槽的对应关系。
解决了节点和槽的关系后,接下来就需要对key求哈希值,然后对16384取余,余数是几key就落入对应的槽里。
slot = CRC16(key) % 16384。以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容易,这样数据移动问题就解决了。
4.1.3.2 哈希槽计算
Redis 集群中内置了 16384 个哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。
当需要在 Redis 集群中放置一个 key-value时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,也就是映射到某个节点上。
如下代码,key之A 、B在Node2, key之C落在Node3上
@Test
public void test(){
System.out.println(SlotHash.getSlot("A"));
System.out.println(SlotHash.getSlot("B"));
System.out.println(SlotHash.getSlot("C"));
System.out.println(SlotHash.getSlot("Hello"));
}
4.2 开始部署
- 关闭防火墙,开启docker服务
- 确保存在一个redis镜像(我这里使用redis6.0.9版本)
docker images如果没有redis镜像
可以
docker pull redis:6.0.9redis镜像
4.2.1 创建6个docker容器redis实例
docker run -d --name redis-node-1 --net host --privileged=true -v /mydata/redis/redis-node-1:/data redis:6.0.9 --cluster-enabled yes --appendonly yes --port 6381
docker run -d --name redis-node-2 --net host --privileged=true -v /mydata/redis/redis-node-2:/data redis:6.0.9 --cluster-enabled yes --appendonly yes --port 6382
docker run -d --name redis-node-3 --net host --privileged=true -v /mydata/redis/redis-node-3:/data redis:6.0.9 --cluster-enabled yes --appendonly yes --port 6383
docker run -d --name redis-node-4 --net host --privileged=true -v /mydata/redis/redis-node-4:/data redis:6.0.9 --cluster-enabled yes --appendonly yes --port 6384
docker run -d --name redis-node-5 --net host --privileged=true -v /mydata/redis/redis-node-5:/data redis:6.0.9 --cluster-enabled yes --appendonly yes --port 6385
docker run -d --name redis-node-6 --net host --privileged=true -v /mydata/redis/redis-node-6:/data redis:6.0.9 --cluster-enabled yes --appendonly yes --port 6386
最后启动成功后,docker ps 可以看到启动了6个实例
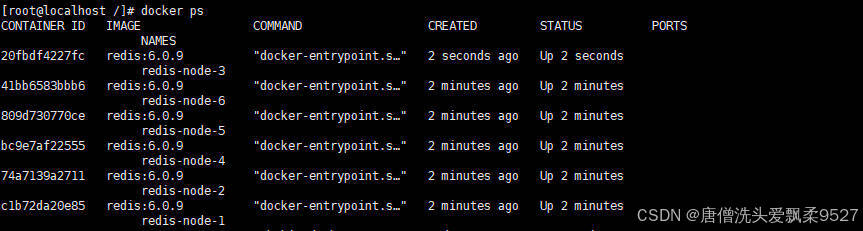
命令解析:
- docker run:创建并运行docker容器实例
- –name redis-node-# :容器名称
- –net host :使用宿主机的IP和端口(默认)
- –privileged=true :获取宿主机root用户权限
- -v /mydata/redis/redis-node-#:/data :容器卷,宿主机地址:docker内部地址
- reds:6.0.9 :redis镜像和版本号
- –cluster-enabled yes :开启redis集群
- –appendonly yes :开启持久化
- –port 638# :redis端口号
4.2.2 构建主从关系
进入各个redis容器内部确立主从关系
docker exec -it redis-node-1 /bin/bash
这里代码只是做个示范,请根据自己的部署自行修改进入的容器
redis-cli --cluster create 192.168.81.102:6381 192.168.81.102:6382 192.168.81.102:6383 192.168.81.102:6384 192.168.81.102:6385 192.168.81.102:6386 --cluster-replicas 1
这里一样需要根据你自己的IP地址来更改
要求:每一个
IP:端口地址都必须能通信!
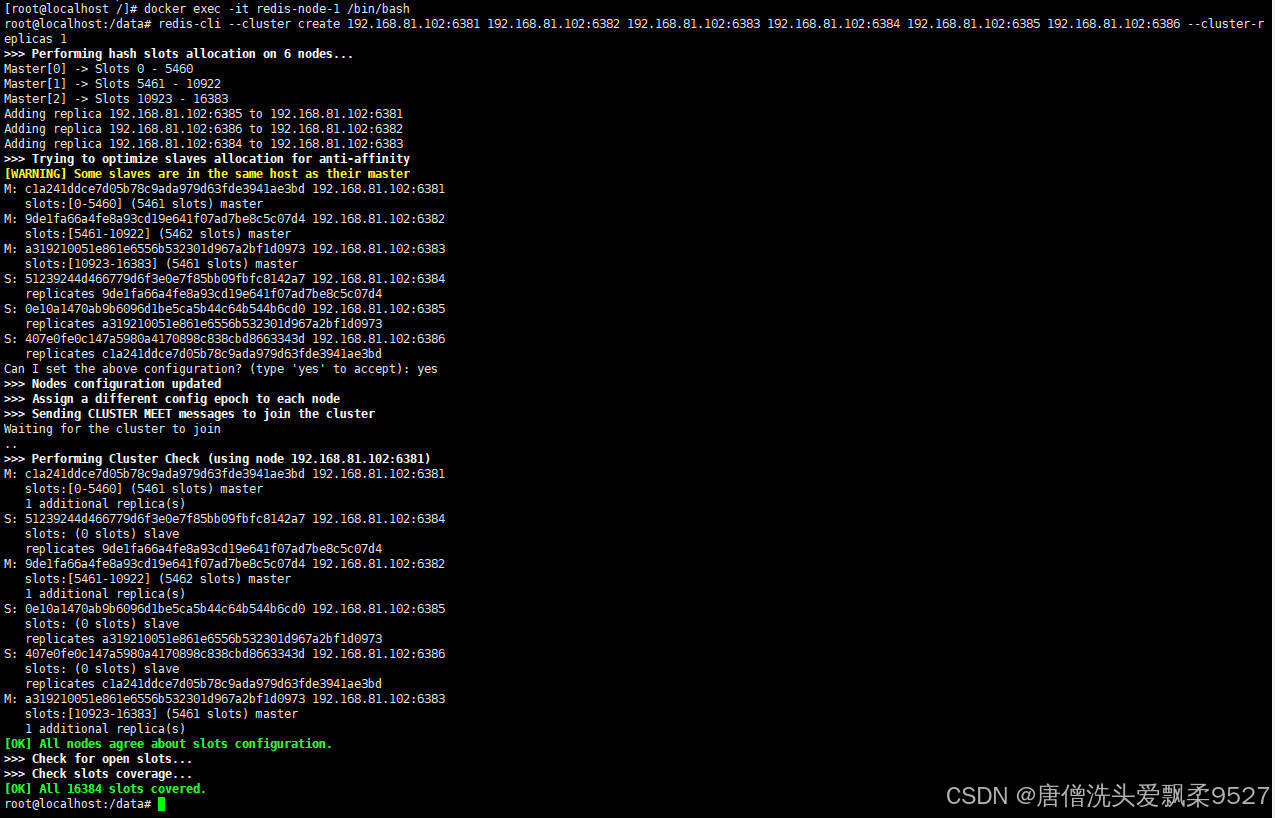
当出现OK选项时,就代表集群配置完毕
4.2.3 查看阶段状态
进入Redis:6381容器,查看节点状态
cluster info
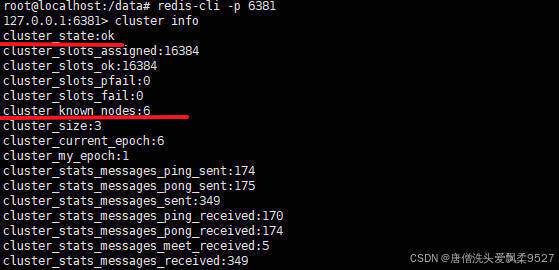
cluster nodes

4.3 主从容错切换迁移案例
4.3.1 数据读写存储
对redis:6381新增两个key
redis-cli -p 6381 -c
这里防止路由失效,最好加上
-c参数
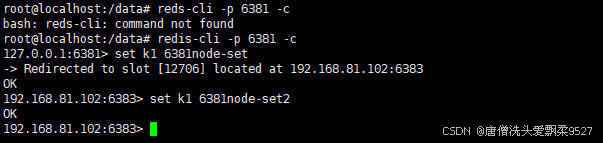
set k1 6381node-set1
set k2 6381node-set2
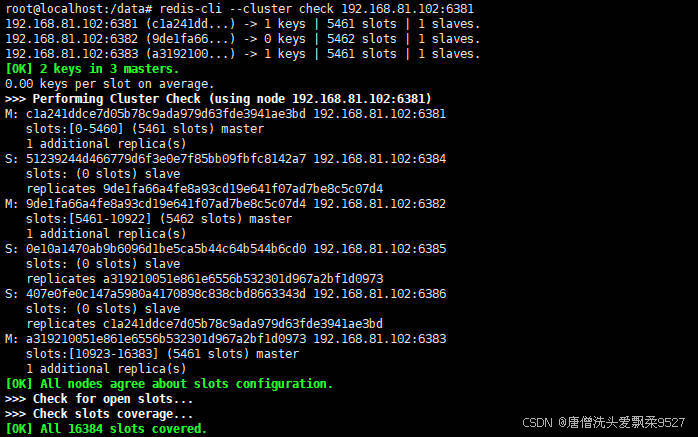
查看集群信息
redis-cli --cluster check 192.168.81.102:6381
4.3.2 容错切换迁移
名字高大上,其实操作很简单
我们只需要将master节点停掉,然后redis会自动将某一台slave节点上位,这台上位的slave节点就会变成master节点
我这里先将redis:6381容器停掉(因为redis:6381容器在集群中所代表的就是master节点),这里就模拟redis集群中某一节点宕机
docker stop redis-node-1
此时我们可以进入节点2去看看集群节点的状态
docker exec -it redis-node-2 /bin/bash
redis-cli -p 6382 -c
cluster nodes

这里可以看到
- 6381节点 master 处于fail的状态
- 6382节点 myself,master 处于connected
- 6386节点 master 处于connected
可以看到6386节点上位为了master
4.3.3 还原三主三从状态
重新启动 redis:6381 节点即可
docker start redis-node-1
再次查看集群信息

可以看到
- 6381 节点从原来的master,变成了slave
- 而6386节点依旧时master
这就完成了一次主从切换
4.4主从扩容
目标:
- 集群内新增6387、6388两个节点
4.4.1 加入集群
首先docker启动两个redis实例
docker run -d --name redis-node-7 --net host --privileged=true -v /mydata/redis/redis-node-7:/data redis:6.0.9 --cluster-enabled yes --appendonly yes --port 6387
docker run -d --name redis-node-8 --net host --privileged=true -v /mydata/redis/redis-node-8:/data redis:6.0.9 --cluster-enabled yes --appendonly yes --port 6388
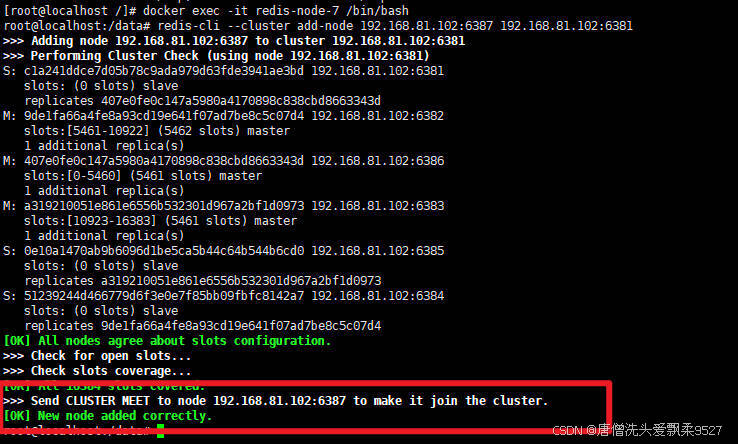
进入redis:6387容器
docker exec -it redis-node-7 /bin/bsah
将新增的6387节点作为master节点加入原集群
redis-cli --cluster add-node 192.168.81.102:6387 192.168.81.102:6381
为什么后面要跟上集群内的一个master节点呢?
其实就是将 节点 加入到 目标节点所在的集群中
4.4.2 分配槽号
我们刚加入集群的节点,都是没有槽号的,没有槽号redis就无法进行操作
检查一次集群即可看到
redis-cli --cluster check 192.168.81.102:6381
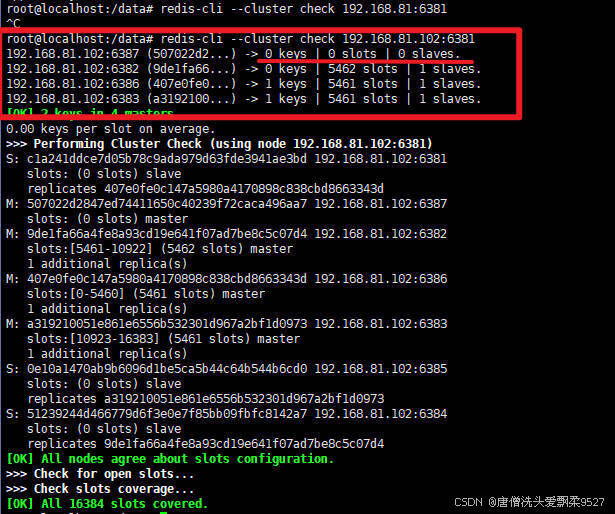
看到6387节点没有槽号,所以我们还需要为新加的节点分配槽号
redis-cli --cluster reshard 192.168.81.102:6381
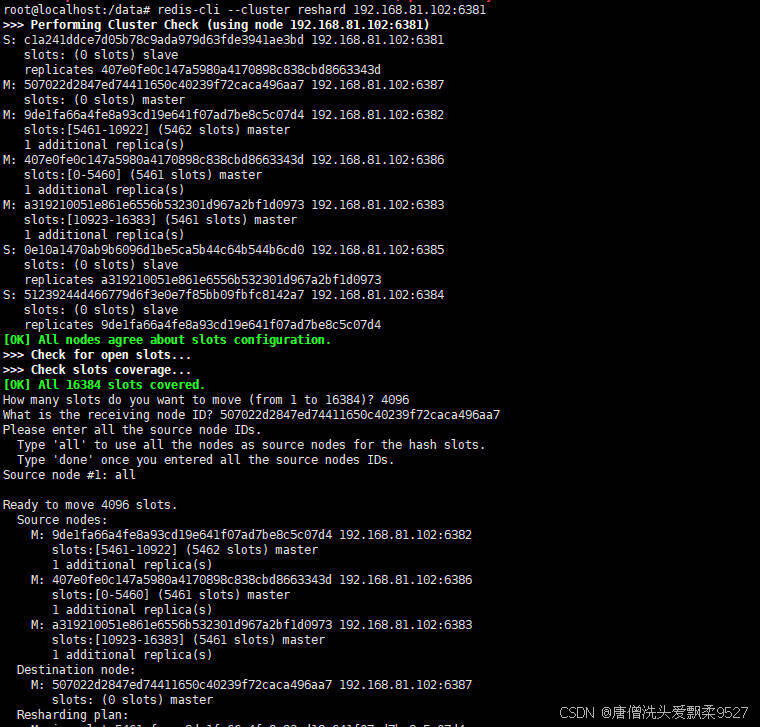
这里作几个解释,在分配槽号时,redis还会询问你几个事项
-
How many slots do you want to move (from 1 to 16384)?
- 这里我们一般是根据槽号总数也就是(from 1 to 16384) 中的16384这个数除以集群中master节点的个数,最后填这个计算出来的值
- 16384/master节点个数;我这里是4台,所以是 16384/4=4096
- 结果我填写的值就是
4096
-
What is the receiving node ID?
-
这个就是问你给哪个master节点重新分配,我们只需要填写对应节点的ID即可
-
ID就是
S: c1a241ddce7d05b78c9ada979d63fde3941ae3bd 192.168.81.102:6381
slots: (0 slots) slave
replicates 407e0fe0c147a5980a4170898c838cbd8663343d
M: 507022d2847ed74411650c40239f72caca496aa7 192.168.81.102:6387
slots: (0 slots) master
M: 9de1fa66a4fe8a93cd19e641f07ad7be8c5c07d4 192.168.81.102:6382
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
M: 407e0fe0c147a5980a4170898c838cbd8663343d 192.168.81.102:6386
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: a319210051e861e6556b532301d967a2bf1d0973 192.168.81.102:6383
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 0e10a1470ab9b6096d1be5ca5b44c64b544b6cd0 192.168.81.102:6385
slots: (0 slots) slave
replicates a319210051e861e6556b532301d967a2bf1d0973
S: 51239244d466779d6f3e0e7f85bb09fbfc8142a7 192.168.81.102:6384
slots: (0 slots) slave
replicates 9de1fa66a4fe8a93cd19e641f07ad7be8c5c07d4这串信息中的前面一段字符,例如
M: 507022d2847ed74411650c40239f72caca496aa7 192.168.81.102:6387 slots: (0 slots) master那么就是
507022d2847ed74411650c40239f72caca496aa7这一串ID
-
-
Source node #1:
- 一般填写
all
- 一般填写
分配完成后,我们再检查一次集群状态
redis-cli --cluster check 192.168.81.102:6381
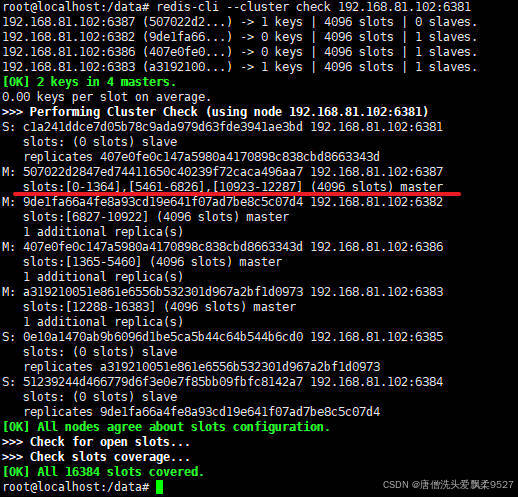
能够看到6387节点已有槽号
为什么6387是3个新的区间,以前的还是连续?
重新分配成本太高,所以前3家各自匀出来一部分,从6381/6382/6383三个旧节点分别匀出1364个坑位给新节点6387
4.4.3 为主节点6387分配从节点6388
命令:
redis-cli --cluster add-node ip:新slave端口 ip:新master端口 --cluster-slave --cluster-master-id 新主机节点ID
自己根据实际情况来更改
我这里就是这样子的
redis-cli --cluster add-node 192.168.81.102:6388 192.168.81.102:6387 --cluster-slave --cluster-master-id 507022d2847ed74411650c40239f72caca496aa7
再次检查集群
redis-cli --cluster check 192.168.81.102:6381
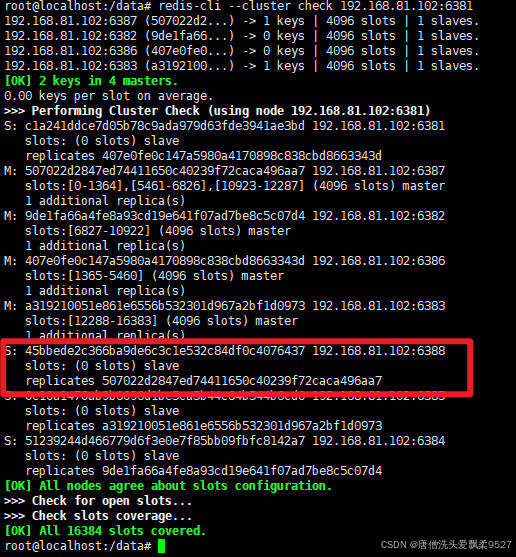
4.5 主从缩容
主从缩容就不演示了
目的就是将6387和6388下线
缩容的整体思路和扩容思路就是完全相反的
- 先删除从节点6388
- 然后将6387主节点的槽号清空
- 重新分配集群槽号
- 再分配槽号时,多出来的槽号可以分配其他主节点
- 最后将6387主节点删除
5. ❤️Docker专栏 - 前篇回顾
- 1. Docker的概述与架构,手把手带你安装Docker,云原生路上不可缺少的一门技术!
- 2. 还在浏览网页寻找Docker命令?本文全面列举与使用Docker里的各个命令!想要什么命令直接从本文拿!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









