









D5
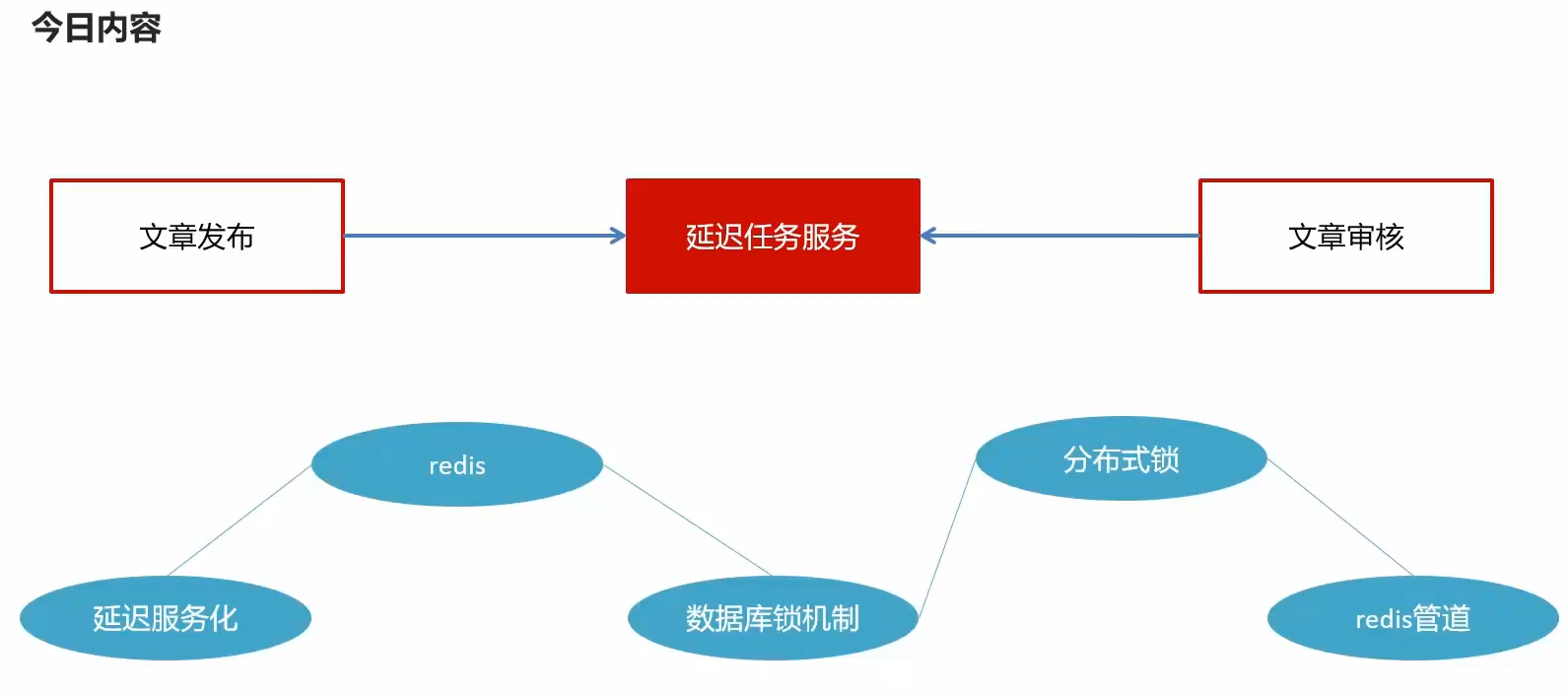
1.今日内容介绍
1.1延时任务
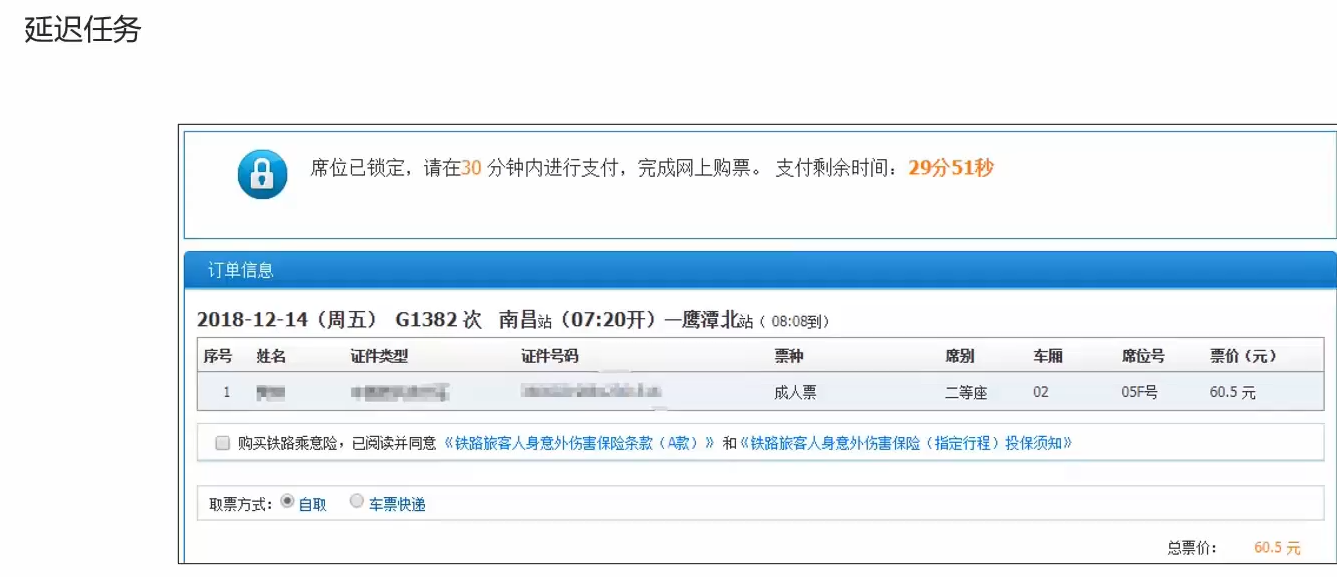
买票的时候,30分钟内必须支付,该结束订单任务延时了30分钟,如果30分钟内没有支付,到点取消订单
-
延迟服务化,多个模块可以使用
-
redis存储
-
锁机制防止并发提交定时任务
-
多redis线程结合成一个
2.延迟任务概述
2.1什么是延迟任务

- 订单取消
- 网络故障重试终止
2.2技术对比
DelayQueue
JDK自带的
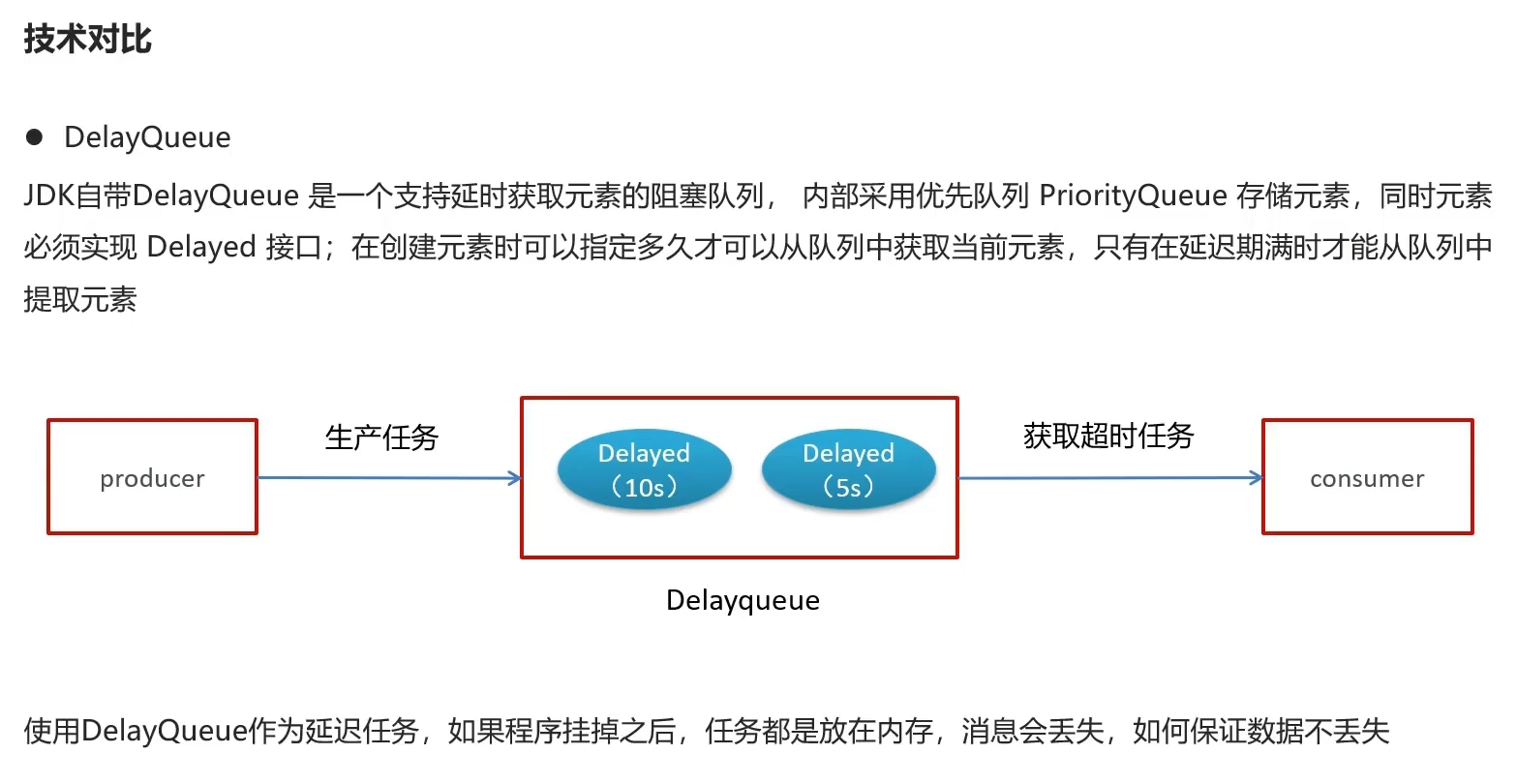
- 延迟队列,相当于冷却时间,冷却时间一到则从队列拿出来任务执行
不过内存一蹦就没了
RabbitMQ
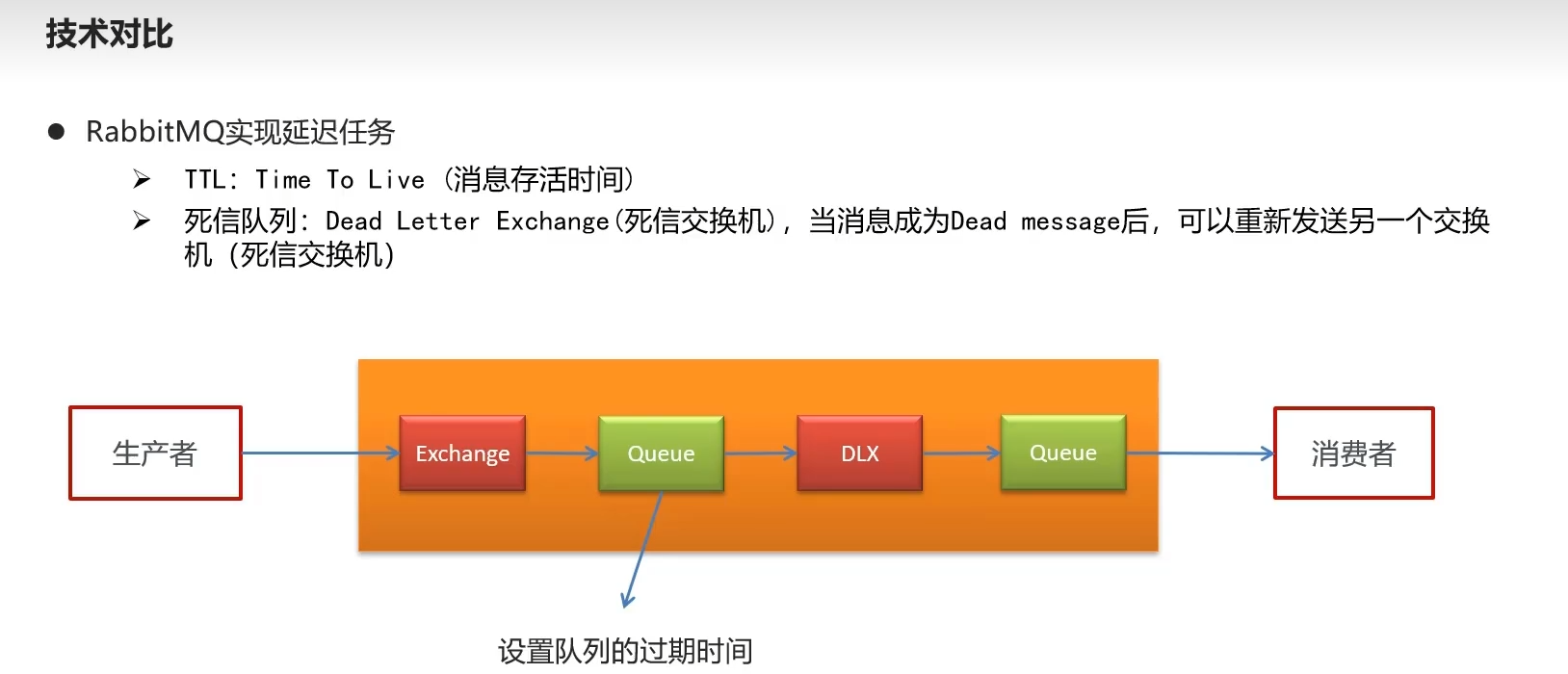
- TTL 消息存活时间
- 死信队列(DLX dead letter exchange)死信交换机,从交换机入列之后设置过期时间,过期后通过DLX进入下一个队列
入队列,排队时间,时间到了下一个排队,直到队列前没有其他消息则传达给消费者
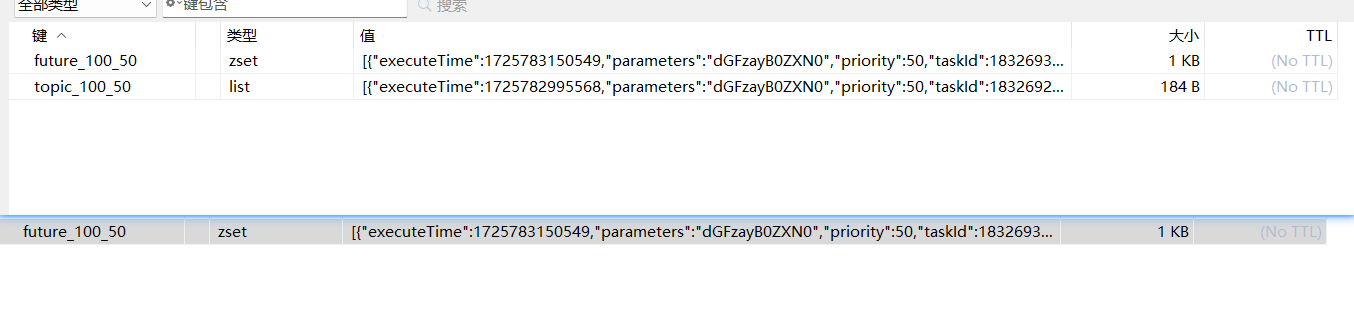
Redis实现
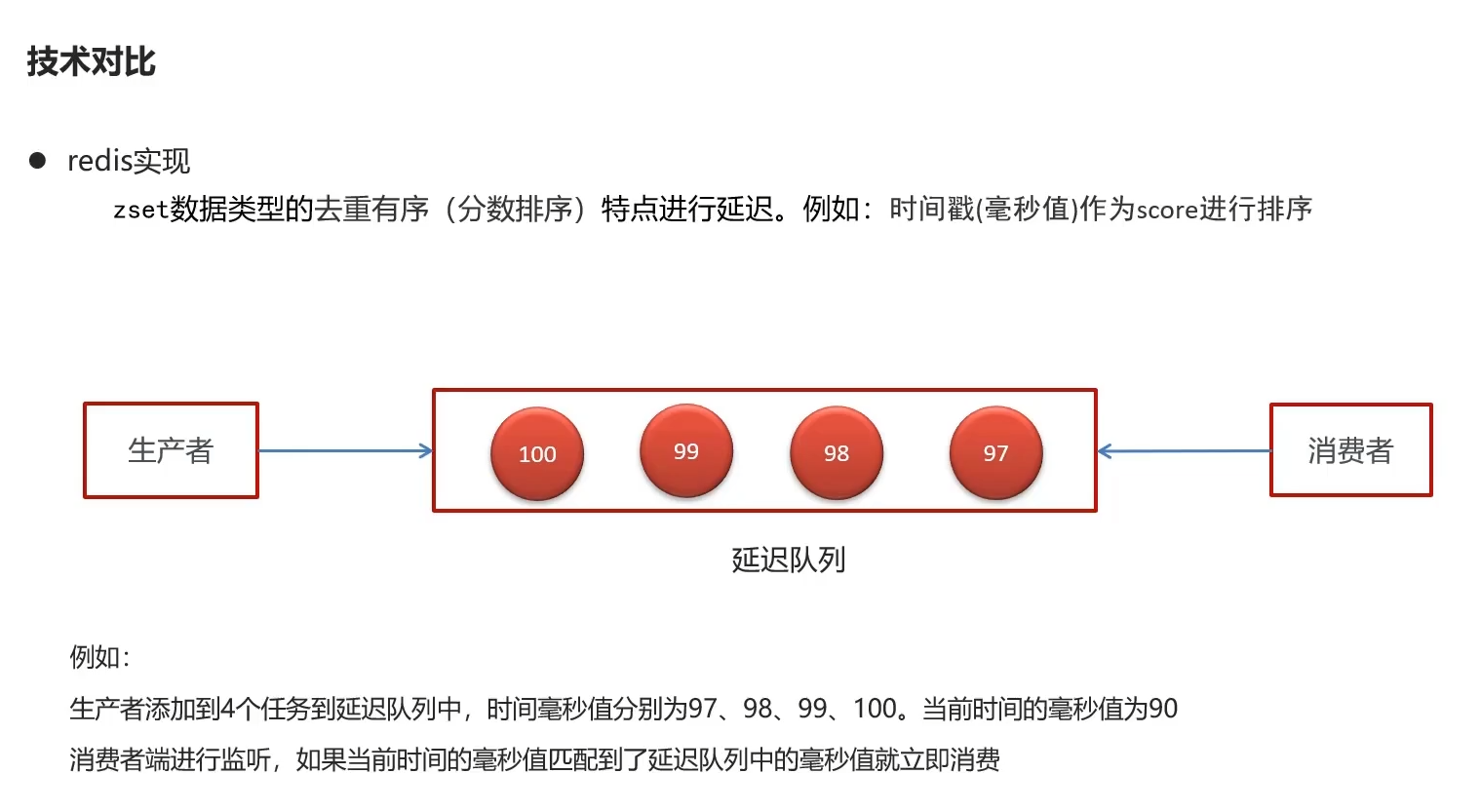
- 4个队列,以时间戳排队,后入列的时间戳大,当当前时间毫秒级到了哪一个范围,则消费哪个,后来后消费原则
- 将时间戳作为作为z-set存入redis,以此来分辨谁先执行
2.3流程说明
使用list和zset的好处原因
list:双向链表结构,增加和删除速度快,不影响整个列表的索引
zset:为不同定时任务设置不同的score 区分执行顺序
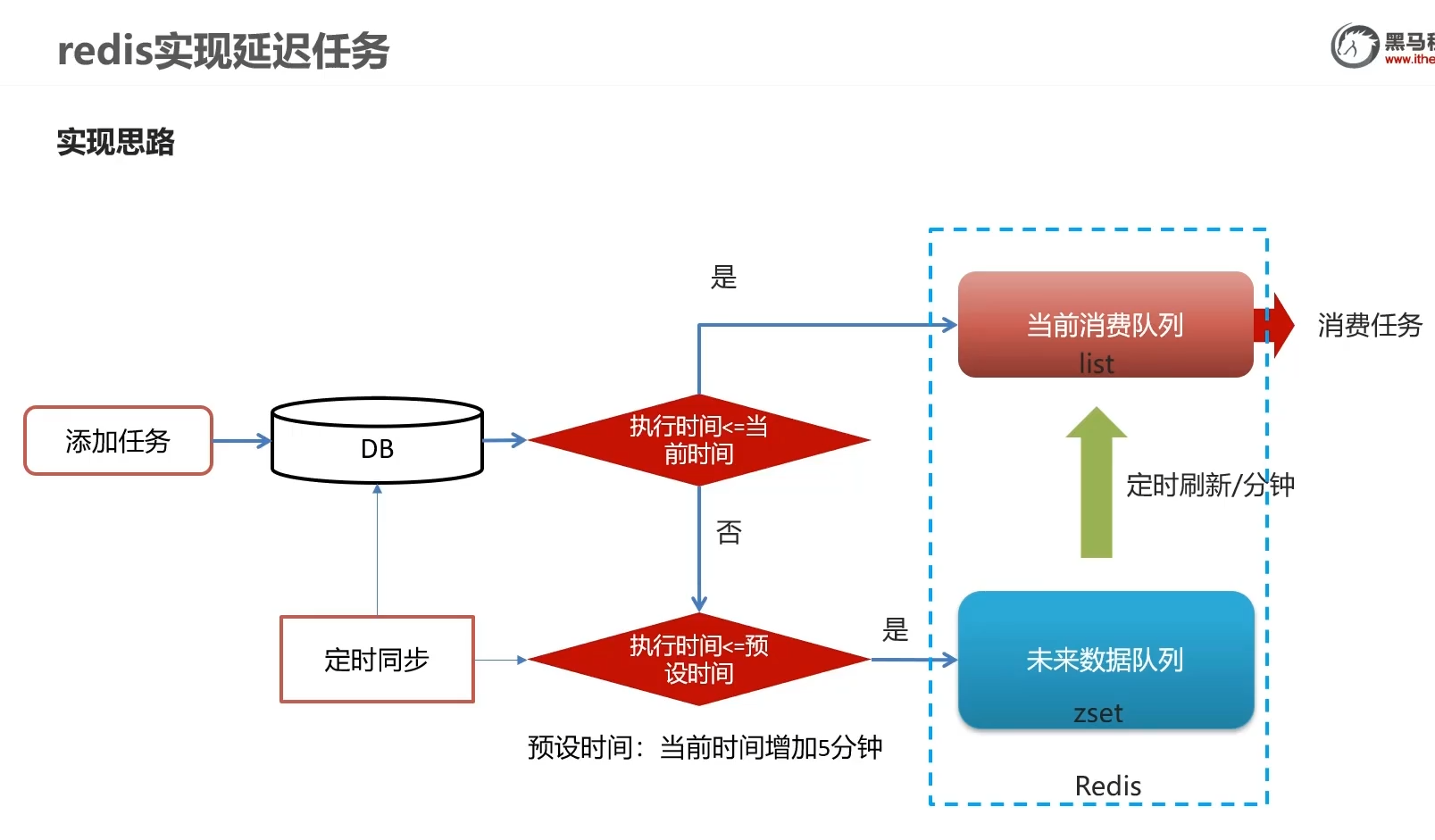
- 由于redis内存有限,不一上来就往里整
- 先存储到数据库里,判断当前时间大于执行时间,也就是过了12点要碎觉觉了,我们就把它存到消费队列一个一个给消费者吃
- 如果当前时间小于执行时间,说明执行时间的时间戳大于当前时间,也就是说在未来才执行,并且为了防止一口气存到redis产生压力
我们应该提前五分钟也就是 在执行时间的前五分钟将数据同步到redis - zset定时同步到list
- DB定时判断同步数据到redis
人话:到点消费, 预定的前五分钟可以消费
面试问题
2.3.1存数据库的原因
- 通用服务,有需求的任务可以调用
- 内存有限,持久化mysql更加的安全
2.3.2使用redis中的两种数据类型原因

- list存储立即执行(增删快),zset存储未来(方便区分)
- 任务量大zset 性能下降
时间复杂度
执行时间随数据变大的变化趋势,类似于高中数学函数图,他的那个斜率好比是
list的LPUSH复杂度 O(1)
redis的zset的zadd O(M*log(n))
O(1):常量级复杂度,次数与规模没关系
O(M*log(n))对象级复杂度,数据一大,执行次数时间曲线上涨
2.3.3为什么要预加载?
数据大,阻塞,提前五分钟预存,是一种优化形式
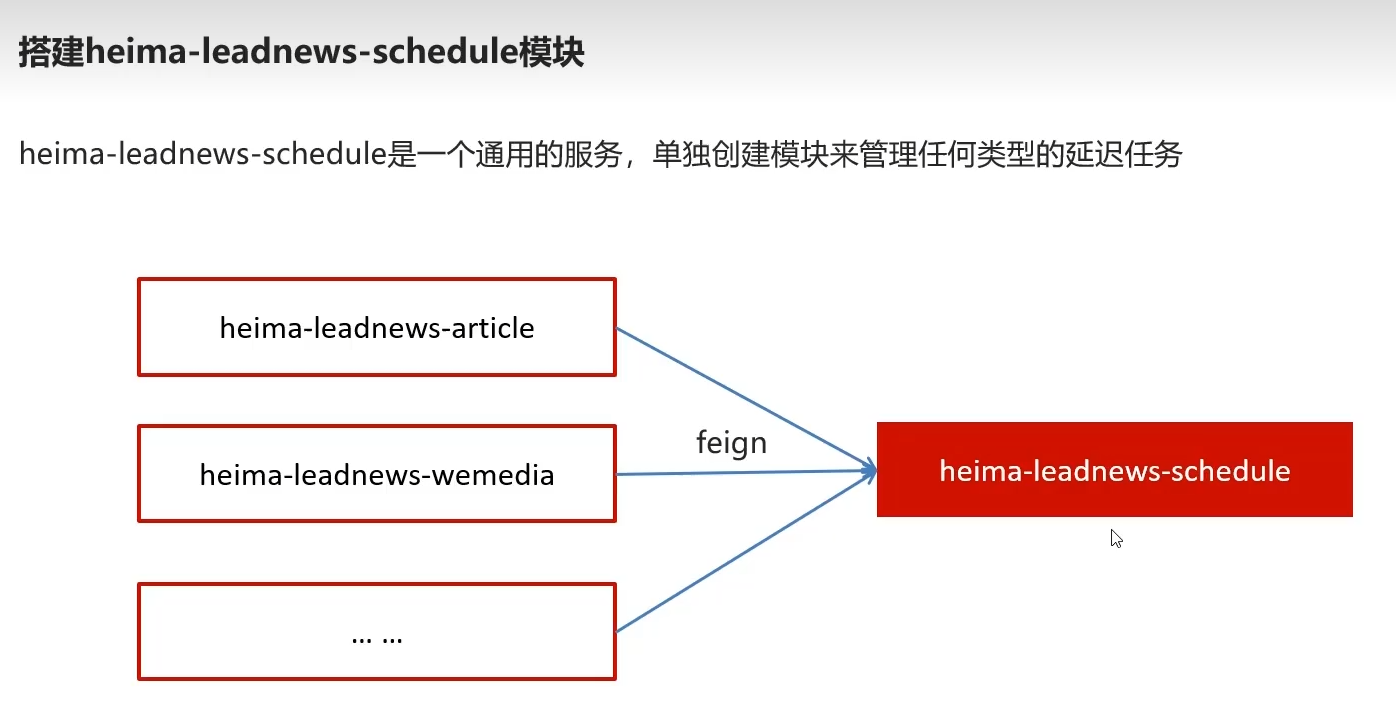
3.延迟任务实现
3.1环境搭建步骤
导入模块到service服务下
bootstrap.yml
server:
port: 51701
spring:
application:
name: leadnews-schedule
cloud:
nacos:
discovery:
server-addr: 192.168.200.130:8848
config:
server-addr: 192.168.200.130:8848
file-extension: yml
nacos配置中心
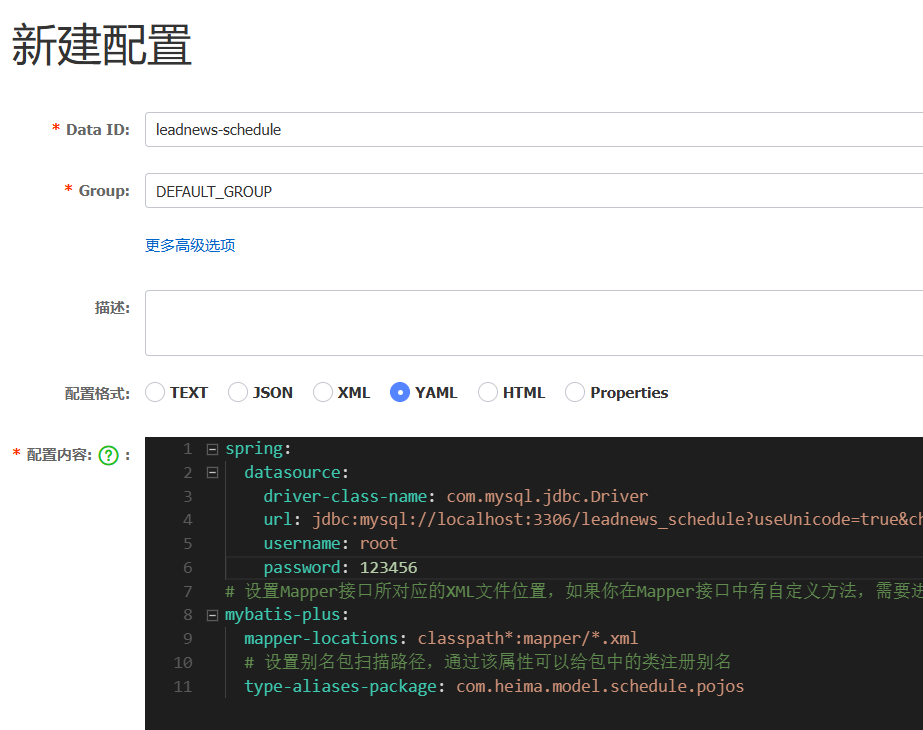
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/leadnews_schedule?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
username: root
password: root
# 设置Mapper接口所对应的XML文件位置,如果你在Mapper接口中有自定义方法,需要进行该配置
mybatis-plus:
mapper-locations: classpath*:mapper/*.xml
# 设置别名包扫描路径,通过该属性可以给包中的类注册别名
type-aliases-package: com.heima.model.schedule.pojos
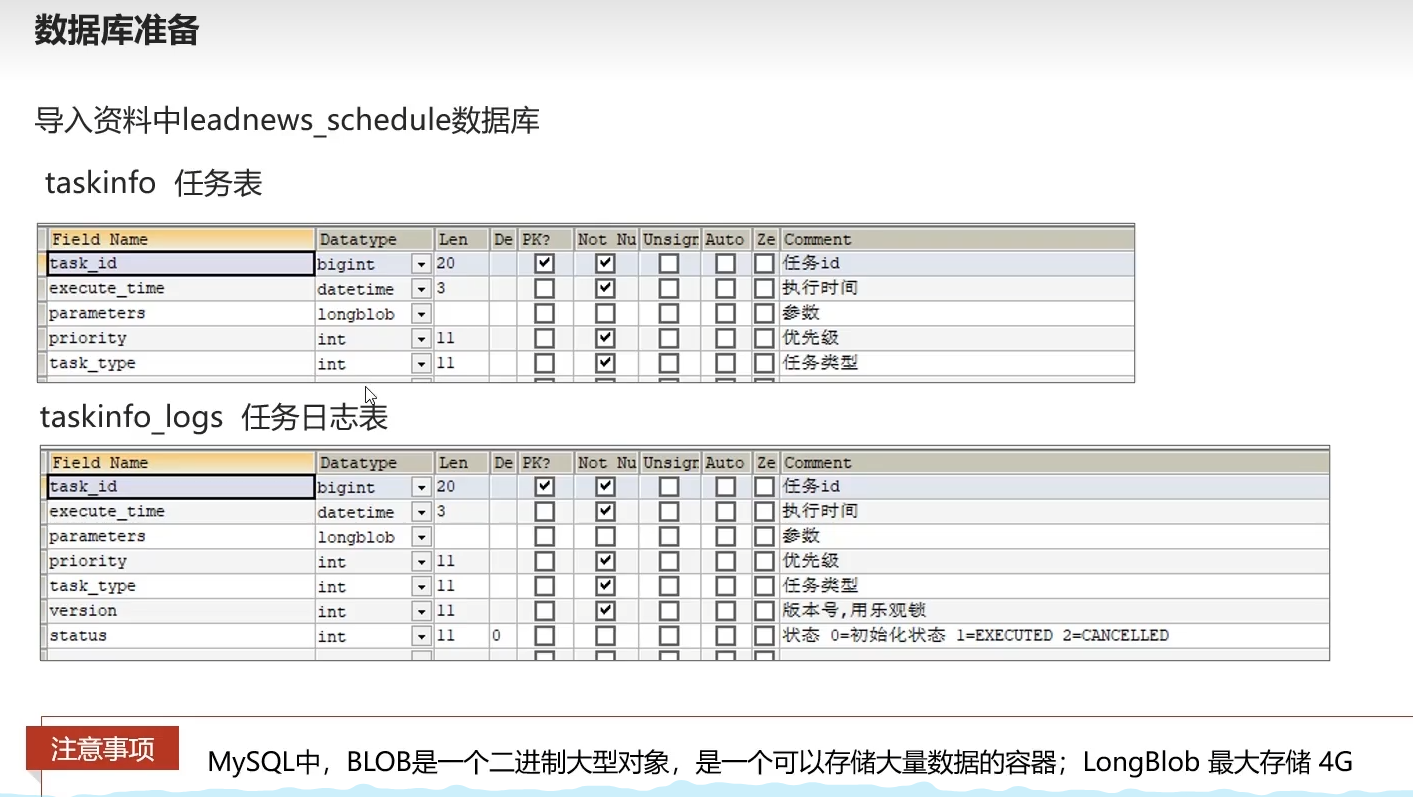
数据库
实体类
model模块下
package com.heima.model.schedule.pojos;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import java.io.Serializable;
import java.util.Date;
/**
* <p>
*
* </p>
*
* @author itheima
*/
@Data
@TableName("taskinfo")
public class Taskinfo implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 任务id
*/
@TableId(type = IdType.ID_WORKER)
private Long taskId;
/**
* 执行时间
*/
@TableField("execute_time")
private Date executeTime;
/**
* 参数
*/
@TableField("parameters")
private byte[] parameters;
/**
* 优先级
*/
@TableField("priority")
private Integer priority;
/**
* 任务类型
*/
@TableField("task_type")
private Integer taskType;
}
package com.heima.model.schedule.pojos;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import java.io.Serializable;
import java.util.Date;
/**
* <p>
*
* </p>
*
* @author itheima
*/
@Data
@TableName("taskinfo")
public class Taskinfo implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 任务id
*/
@TableId(type = IdType.ID_WORKER)
private Long taskId;
/**
* 执行时间
*/
@TableField("execute_time")
private Date executeTime;
/**
* 参数
*/
@TableField("parameters")
private byte[] parameters;
/**
* 优先级
*/
@TableField("priority")
private Integer priority;
/**
* 任务类型
*/
@TableField("task_type")
private Integer taskType;
}
乐观锁集成
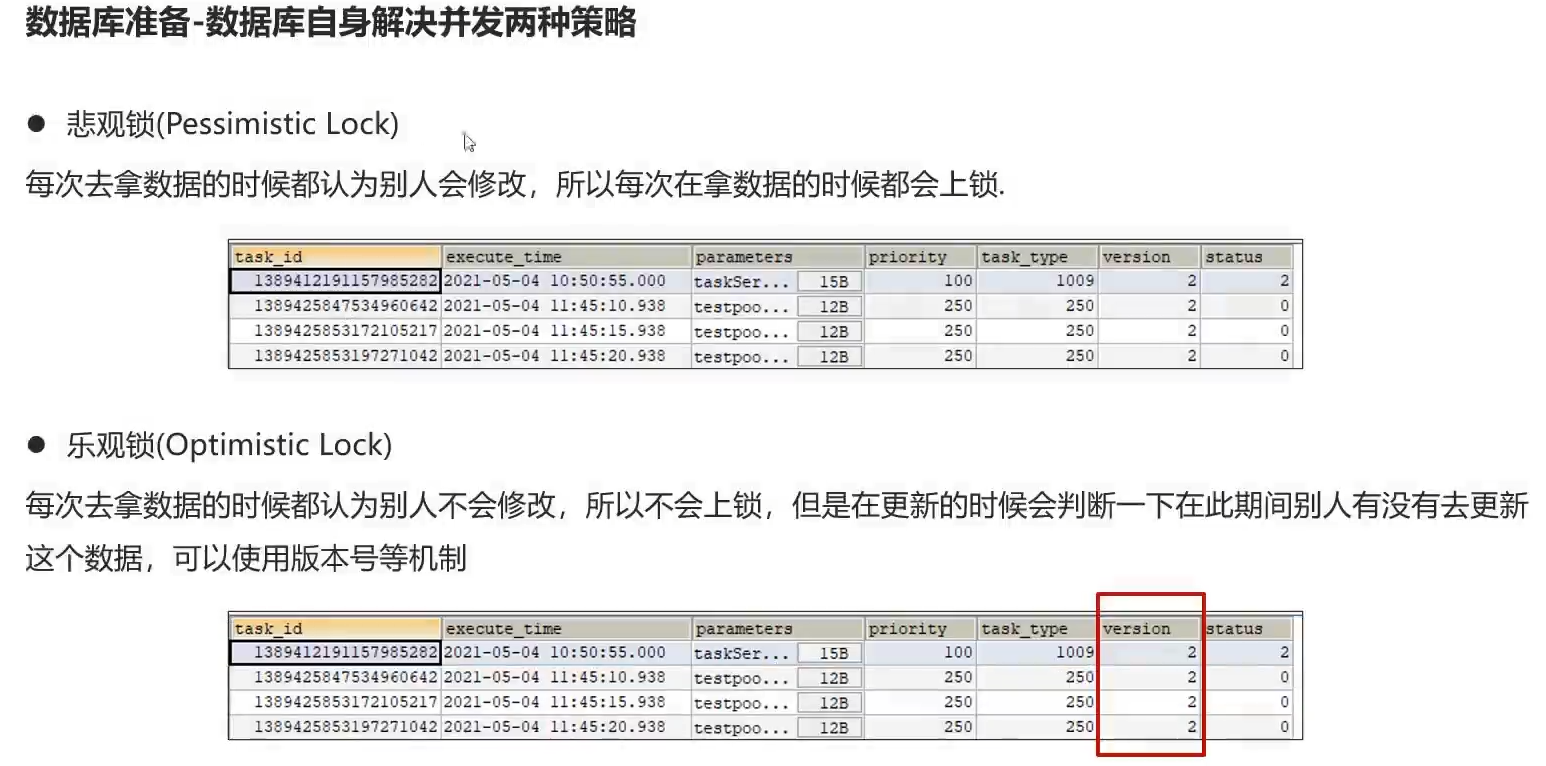
悲观锁,修改数据的过程 改变状态,其他用户不得修改
乐观锁,修改数据的过程 不改变状态,提交修改的结果时改变数据
乐观锁效率高于悲观锁,日志操作,加了version字段
开启乐观锁支持
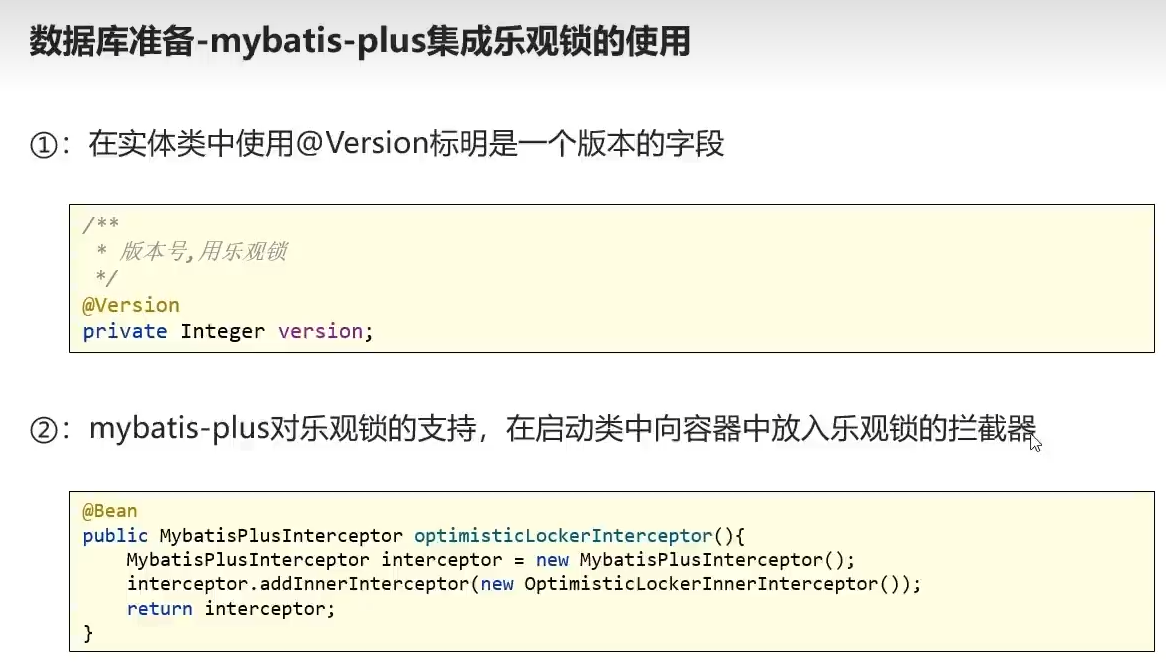
- 实体类字段加version,上面加注解
- 启动类加乐观锁拦截器 注册到bean里
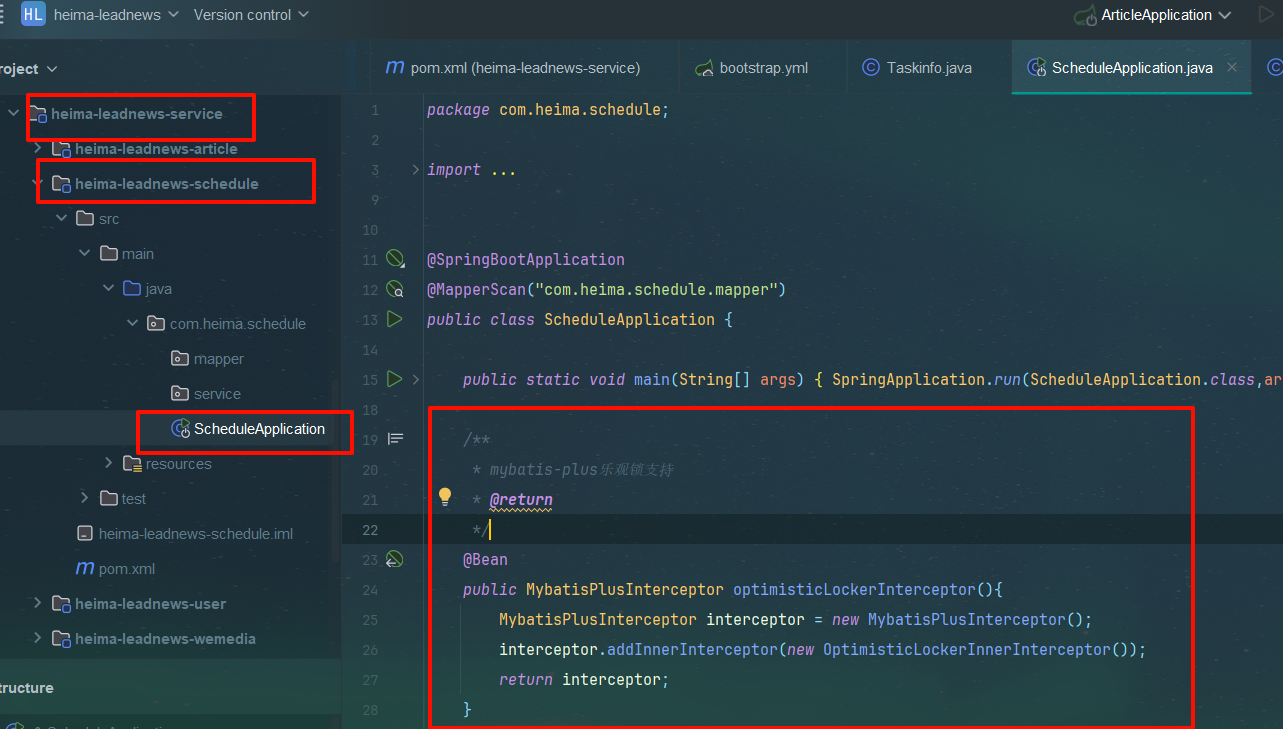
/**
* mybatis-plus乐观锁支持
* @return
*/
@Bean
public MybatisPlusInterceptor optimisticLockerInterceptor(){
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
return interceptor;
}
安装docker
①拉取镜像
docker pull redis
②创建容器
密码:leadnews 端口6379 ,总是开机启动
docker run -d --name redis --restart=always -p 6379:6379 redis --requirepass "leadnews"
③链接测试
wc
项目集成redis
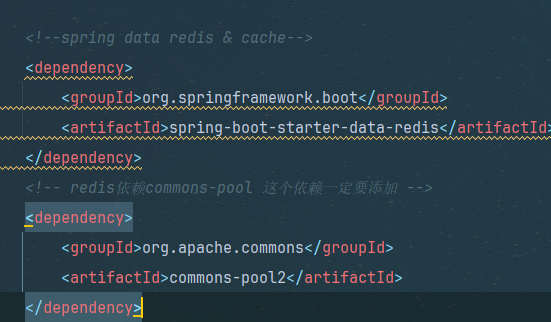
这一步一开始就有了,不用搞了
添加nacos配置
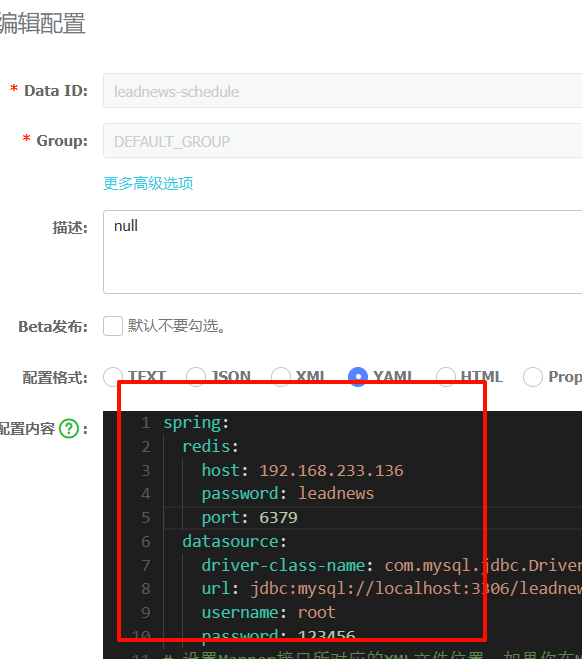
spring:
redis:
host: 192.168.233.136
password: leadnews
port: 6379
redis工具类
太大了,自己下载去
添加自动配置bean
com.heima.common.redis.CacheService
测试
就是一个redisTemplate嘛,由于之前用过,直接cv测试类不跟着敲了
package com.heima.schedule.test;
import com.heima.common.redis.CacheService;
import com.heima.schedule.ScheduleApplication;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.Set;
@SpringBootTest(classes = ScheduleApplication.class)
@RunWith(SpringRunner.class)
public class RedisTest {
@Autowired
private CacheService cacheService;
@Test
public void testList(){
//在list的左边添加元素
// cacheService.lLeftPush("list_001","hello,redis");
//在list的右边获取元素,并删除
String list_001 = cacheService.lRightPop("list_001");
System.out.println(list_001);
}
@Test
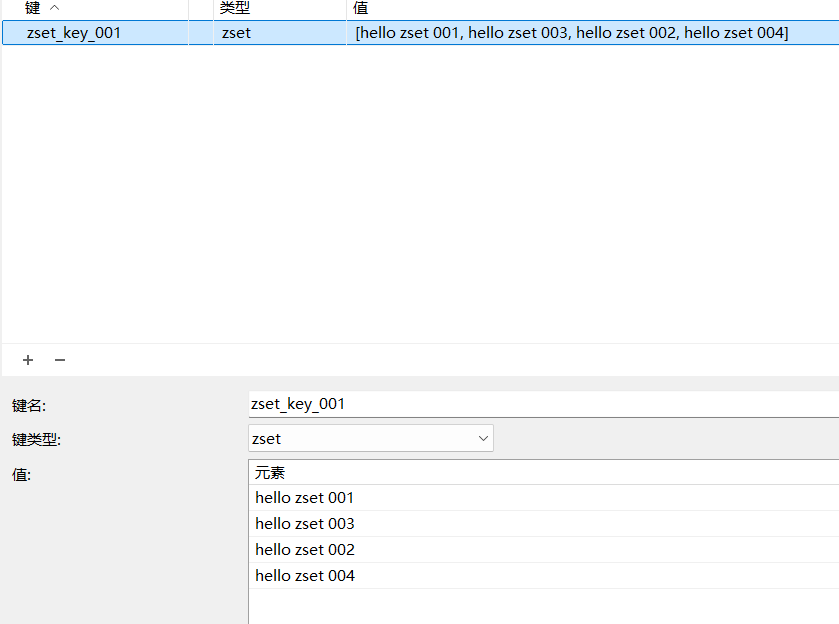
public void testZset(){
//添加数据到zset中 分值
/*cacheService.zAdd("zset_key_001","hello zset 001",1000);
cacheService.zAdd("zset_key_001","hello zset 002",8888);
cacheService.zAdd("zset_key_001","hello zset 003",7777);
cacheService.zAdd("zset_key_001","hello zset 004",999999);*/
//按照分值获取数据
Set<String> zset_key_001 = cacheService.zRangeByScore("zset_key_001", 0, 8888);
System.out.println(zset_key_001);
}
}

3.2添加任务
3.2.1步骤

- 自己拷贝资料代码
3.2.1.1task类
package com.heima.model.schedule.dtos;
import lombok.Data;
import java.io.Serializable;
@Data
public class Task implements Serializable {
/**
* 任务id
*/
private Long taskId;
/**
* 类型
*/
private Integer taskType;
/**
* 优先级
*/
private Integer priority;
/**
* 执行id
*/
private long executeTime;
/**
* task参数
*/
private byte[] parameters;
}
3.2.1.2任务信息和任务日志添加到数据库和redis
service和impl
package com.heima.schedule.service;
import com.heima.model.schedule.dtos.Task;
public interface TaskService {
/**
* 添加延迟任务
* @param task
* @return
*/
public long addTask(Task task);
}
package com.heima.schedule.service.impl;
import com.alibaba.fastjson.JSON;
import com.heima.common.constants.ScheduleConstants;
import com.heima.common.redis.CacheService;
import com.heima.model.schedule.dtos.Task;
import com.heima.model.schedule.pojos.Taskinfo;
import com.heima.model.schedule.pojos.TaskinfoLogs;
import com.heima.schedule.mapper.TaskinfoLogsMapper;
import com.heima.schedule.mapper.TaskinfoMapper;
import com.heima.schedule.service.TaskService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.Calendar;
import java.util.Date;
@Service
@Transactional
@Slf4j
public class TaskServiceImpl implements TaskService {
/**
* 添加延迟任务
*
* @param task
* @return
*/
@Override
public long addTask(Task task) {
//1.添加任务到数据库中
boolean success = addTaskToDb(task);
if (success) {
//2.添加任务到redis
addTaskToCache(task);
}
return task.getTaskId();
}
@Autowired
private CacheService cacheService;
/**
* 把任务添加到redis中
*
* @param task
*/
private void addTaskToCache(Task task) {
String key = task.getTaskType() + "_" + task.getPriority();
//获取5分钟之后的时间 毫秒值
Calendar calendar = Calendar.getInstance();
calendar.add(Calendar.MINUTE, 5);
long nextScheduleTime = calendar.getTimeInMillis();
//2.1 如果任务的执行时间小于等于当前时间,存入list
if (task.getExecuteTime() <= System.currentTimeMillis()) {
cacheService.lLeftPush(ScheduleConstants.TOPIC + key, JSON.toJSONString(task));
} else if (task.getExecuteTime() <= nextScheduleTime) {
//2.2 如果任务的执行时间大于当前时间 && 小于等于预设时间(未来5分钟) 存入zset中
cacheService.zAdd(ScheduleConstants.FUTURE + key, JSON.toJSONString(task), task.getExecuteTime());
}
}
@Autowired
private TaskinfoMapper taskinfoMapper;
@Autowired
private TaskinfoLogsMapper taskinfoLogsMapper;
/**
* 添加任务到数据库中
*
* @param task
* @return
*/
private boolean addTaskToDb(Task task) {
boolean flag = false;
try {
//保存任务表
Taskinfo taskinfo = new Taskinfo();
BeanUtils.copyProperties(task, taskinfo);
taskinfo.setExecuteTime(new Date(task.getExecuteTime()));
taskinfoMapper.insert(taskinfo);
//设置taskID
task.setTaskId(taskinfo.getTaskId());
//保存任务日志数据
TaskinfoLogs taskinfoLogs = new TaskinfoLogs();
BeanUtils.copyProperties(taskinfo, taskinfoLogs);
taskinfoLogs.setVersion(1);
taskinfoLogs.setStatus(ScheduleConstants.SCHEDULED);
taskinfoLogsMapper.insert(taskinfoLogs);
flag = true;
} catch (Exception e) {
e.printStackTrace();
}
return flag;
}
}
大致思路
存任务信息,和日志信息到数据库
- 定时类调用传来task(类似dto)
- 由于接收的是时间戳格式的也就是long类型的,但是要存到数据库里的是date类型,做个转换,然后将dto考到实际对应数据库表的实体类上进行插入
- 日志初始化乐观锁版本设置为1,状态为初始化状态
调用添加数据库成功之后存redis
- key值加工,当前/预处理+类型+优先级
- 设置预处理的时间大小,(类似于赶高铁要提前多久出发,9点高铁如果提前半小时那就8:30出发),calendar获取当前时间+5分钟转毫秒值存入预处理
- 执行时间小于当前时间(谁小谁时间戳小,谁被谁超过,这里当前时间超过了执行时间,就是现在!旋风三连踢,也就是12点该进食堂吃饭了)
就进入list队列 - 执行时间小于预处理时间(假设预处理5分钟,那么在执行的前5分钟就得进入食堂,也就是当前时间大于11:55时就可以进入Z队列排队然后再等到12:00时进入list队列)
- 由于一开始没有taskId,在taskInfo添加到数据库之后会自动生成一个id,而task作用域大于taskInfo,我们降值赋值给taskid然后最后 添加完任务之后返回该id即可
3.2.1.3测试

这个报错了哥几个,如果数据库连不上的看看这个是不是自己虚拟机地址,而非localhost
package schedule.service.impl;
import com.heima.model.schedule.dtos.Task;
import com.heima.schedule.ScheduleApplication;
import com.heima.schedule.service.TaskService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.Date;
@SpringBootTest(classes = ScheduleApplication.class)
@RunWith(SpringRunner.class)
public class TaskServiceImplTest {
@Autowired
private TaskService taskService;
@Test
public void addTask() {
Task task = new Task();
task.setTaskType(100);
task.setPriority(50);
task.setParameters("task test".getBytes());
task.setExecuteTime(new Date().getTime());
long taskId = taskService.addTask(task);
System.out.println(taskId);
}
}
分别插入一条setExecuteTime(new Date().getTime()); 为现在的和让他加个1000的,结果会出现list和zset

perfect,下一关各位
3.3取消任务
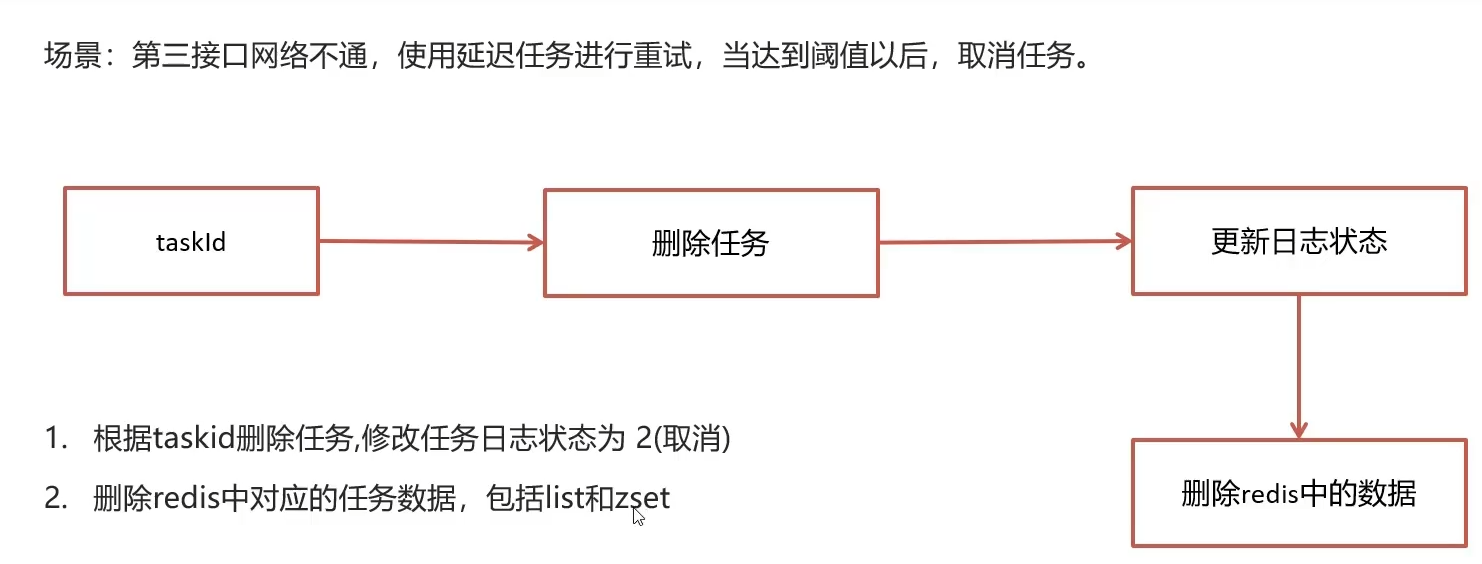
定时器到点执行不了重试3次,不行就说明服务器崩了,用户重新定时吧,之前那个任务给你清了哦,去找客服投诉我吧~
实现类+service+test
service
/**
* 取消任务
* @param taskId
* @return
*/
public boolean cancelTask(long taskId);
impl
/**
* 取消任务
*
* @param taskId
* @return
*/
@Override
public boolean cancelTask(long taskId) {
boolean flag = false;
//删除任务,更新任务日志
Task task = updateDb(taskId, ScheduleConstants.CANCELLED);
//删除redis的数据
if (task != null) {
removeTaskFromCache(task);
flag = true;
}
return flag;
}
/**
* 删除redis中的数据
*
* @param task
*/
private void removeTaskFromCache(Task task) {
String key = task.getTaskType() + "_" + task.getPriority();
if (task.getExecuteTime() <= System.currentTimeMillis()) {
cacheService.lRemove(ScheduleConstants.TOPIC + key, 0, JSON.toJSONString(task));
} else {
cacheService.zRemove(ScheduleConstants.FUTURE + key, JSON.toJSONString(task));
}
}
/**
* 删除任务,更新任务日志
*
* @param taskId
* @param status
* @return
*/
private Task updateDb(long taskId, int status) {
Task task = null;
try {
//删除任务
taskinfoMapper.deleteById(taskId);
//更新任务日志
TaskinfoLogs taskinfoLogs = taskinfoLogsMapper.selectById(taskId);
taskinfoLogs.setStatus(status);
taskinfoLogsMapper.updateById(taskinfoLogs);
task = new Task();
BeanUtils.copyProperties(taskinfoLogs, task);
task.setExecuteTime(taskinfoLogs.getExecuteTime().getTime());
} catch (Exception e) {
log.error("task cancel exception taskId={}", taskId);
}
return task;
}
思路
-
更新日志状态逻辑删除,删除taskInfo数据(如果任务数据表里没有该id的数据那么直接log输出,且后续判断task为null则返回一开始设置的flag为false,task不为空就有机会设置flag为true表示删除成功)
-
后续使用task来删除redis(key值用到了权重和类型和还有值)因此在更新日志要返回task,且该task由info的bean拷贝过去的,同时设置执行时间比对当下时间进行删除
为什么删除还是要当前时间大于执行时间才删呢? 因为这里的前提条件本来就是定时到点了服务器睡着了没能成功删除,所以这里的当前时间必然大于执行时间 -
lRemove 第二个参数0解释如下
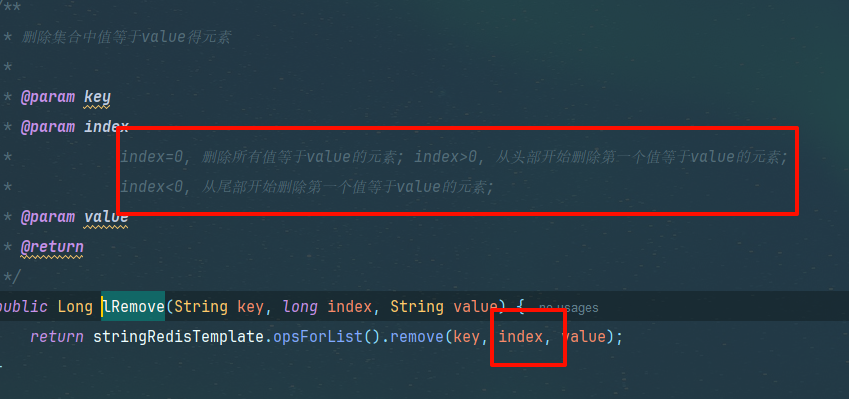
为0时值一样全删掉,大于0从头开始删除第一个匹配到value的元素,小于0则从尾部匹配第一个进行删除 -
如果当前时间还没超过执行时间,说明作者定时了半小时后悔了,想定时两小时(要么是服务器睡着了删list,要么是作者后悔了删定时的)
@Test
public void cancelTesk(){
taskService.cancelTask(1393402270461292545L);
}
测试
@Test
public void cancelTesk(){
taskService.cancelTask(1832692832851324930L);
}

3.4任务执行/消费
service
/**
* 按照类型和优先级拉取任务
* @param type
* @param priority
* @return
*/
public Task poll(int type,int priority);
实现
/**
* 按照类型和优先级拉取任务
*
* @param type
* @param priority
* @return
*/
@Override
public Task poll(int type, int priority) {
Task task = null;
try {
String key = type + "_" + priority;
//从redis中拉取数据 pop
String task_json = cacheService.lRightPop(ScheduleConstants.TOPIC + key);
if (StringUtils.isNotBlank(task_json)) {
task = JSON.parseObject(task_json, Task.class);
//修改数据库信息
updateDb(task.getTaskId(), ScheduleConstants.EXECUTED);
}
} catch (Exception e) {
e.printStackTrace();
log.error("poll task exception");
}
return task;
}
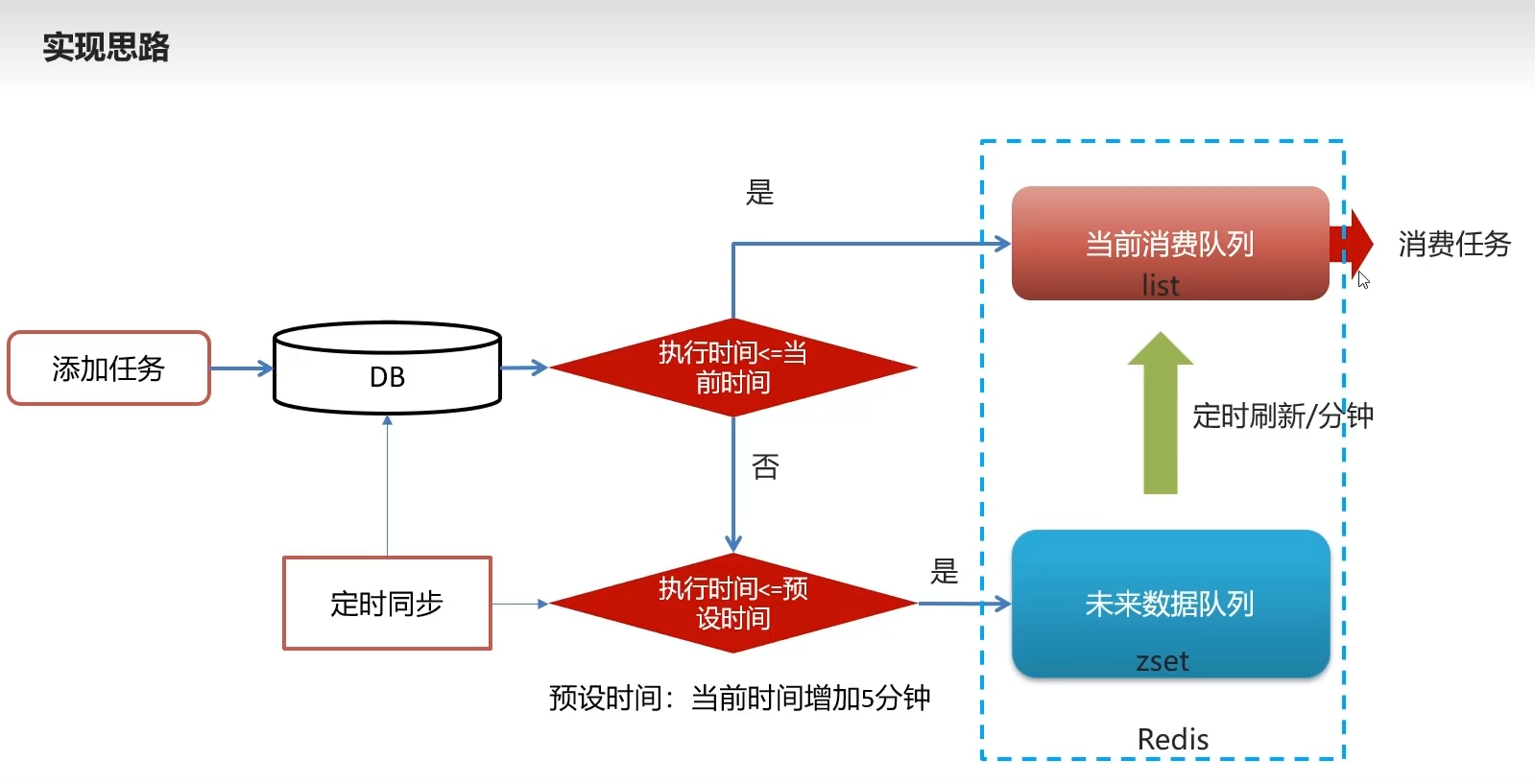
思路
- 根据 类型和优先级拼串 从redis查询拉取任务信息,判断是否为空
- 不为空 则更新taskInfo为已执行,
测试
@Test
public void testPoll(){
Task task = taskService.poll(100, 50);
System.out.println(task);
}
调用成功返回信息
日志状态修改
任务删除
redis pop 取出并删除
3.5未来数据刷新到list
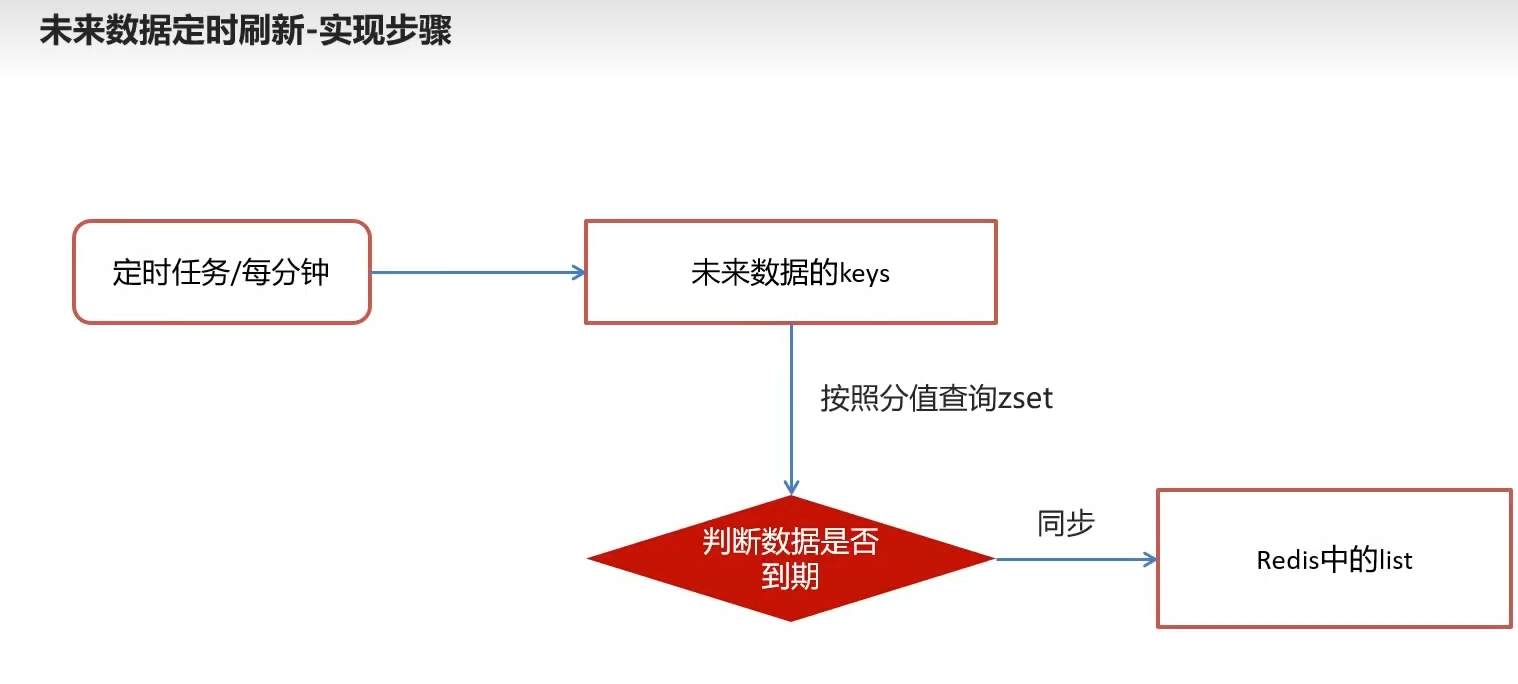
每分钟检查 当前时间+预留时间是否到期,到期后同步zset到list去
方案1
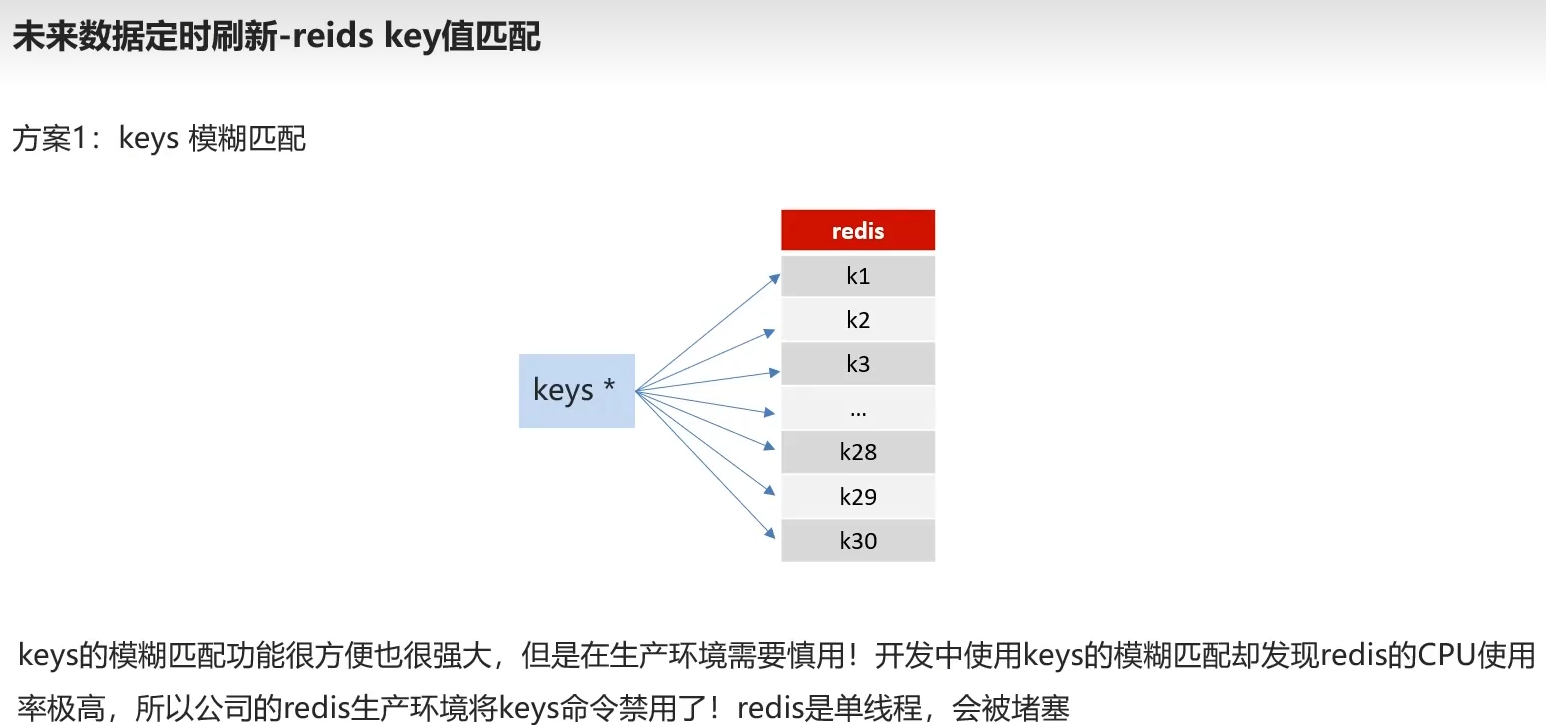
模糊查询cpu占用高,res单线程会堵塞 大多公司弃用了
方案2
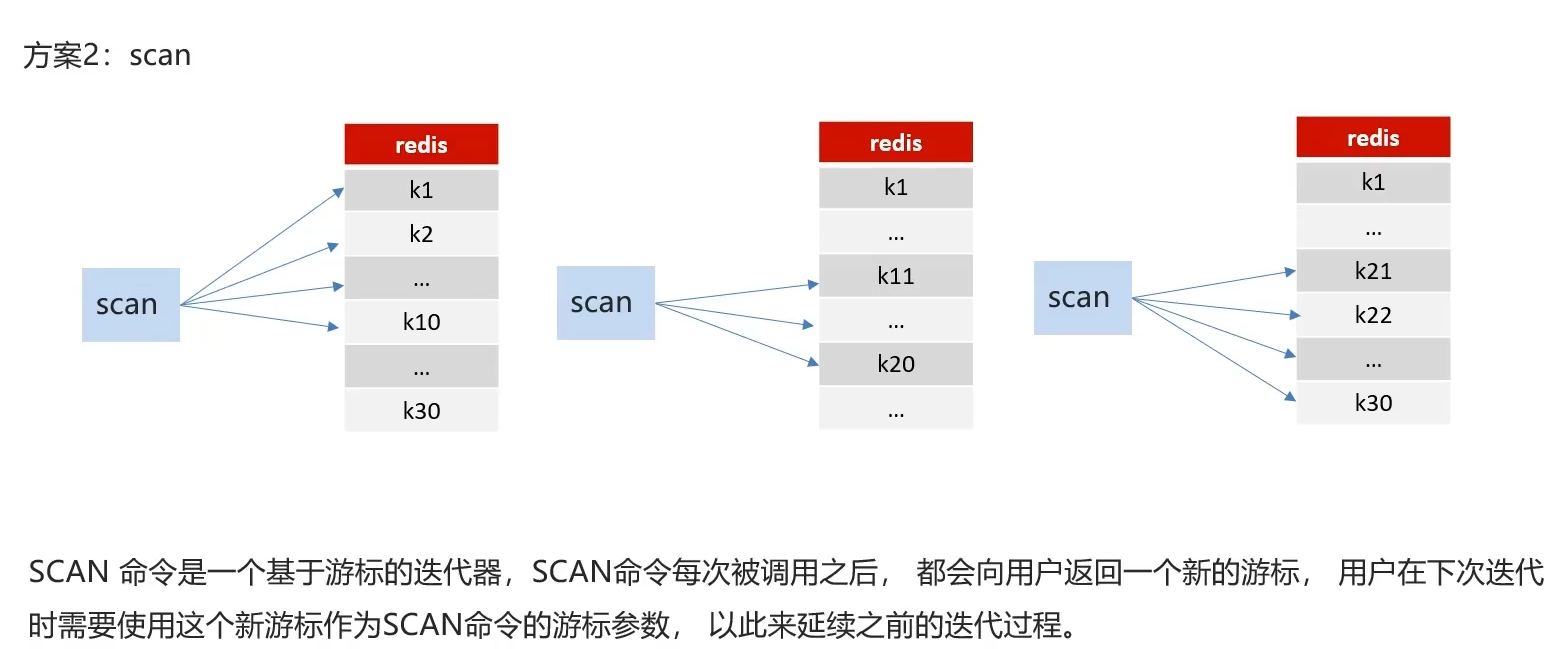
分批查询,相比之前查30条,这里查出了10条每批,一批结束类似游标会记录这一批的最后一个,以此延续迭代过程
测试获取所有的key
@Test
public void testKeys(){
Set<String> keys = cacheService.keys("future_*");
System.out.println(keys);
Set<String> scan = cacheService.scan("future_*");
System.out.println(scan);
}
- 一般不用keys*,会产生堵塞的现象

如何同步?

- 查数据,存,删除
redis管道
普通方式

查一次,返回一次,创建链接,关闭连接频繁
pipeline请求模型
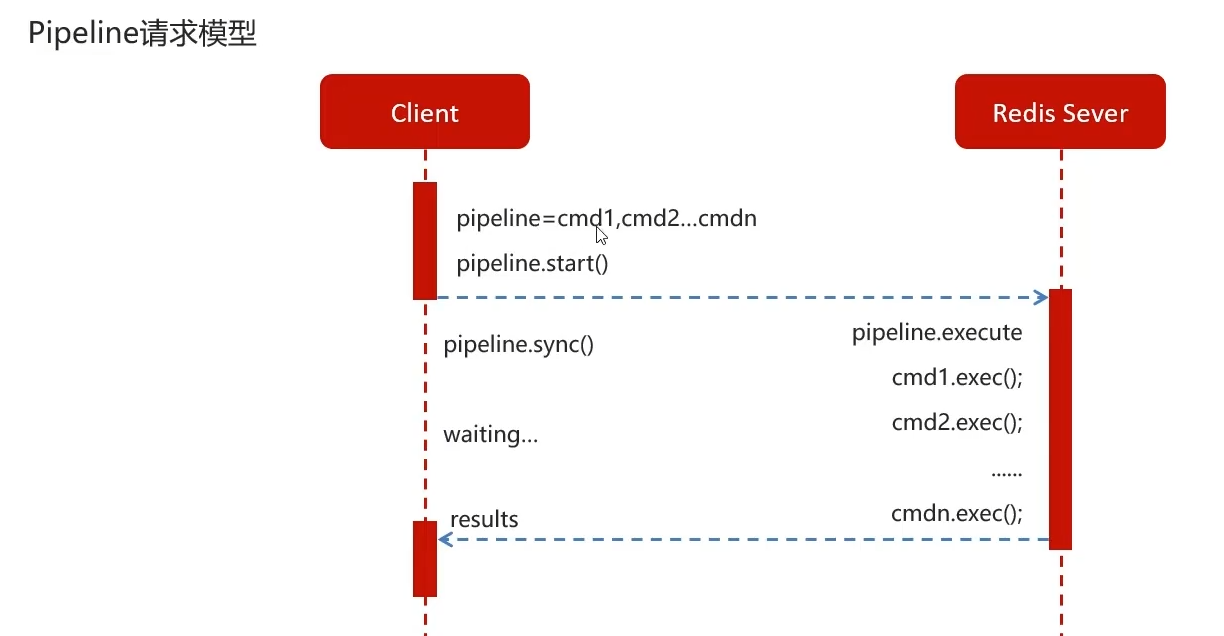
将多条命令打包一次发送,redis一次性执行完返回结果
对比图
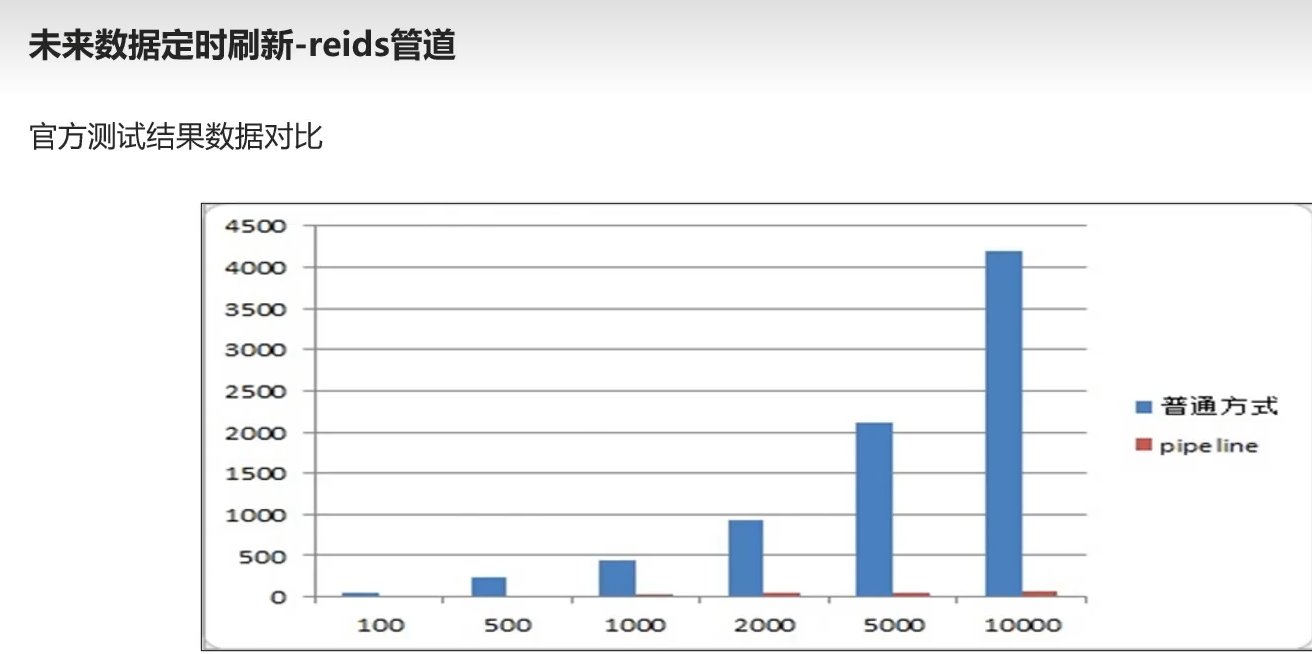
测试对比
// 耗时5505
@Test
public void testPiple1() {
long start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
Task task = new Task();
task.setTaskType(1001);
task.setPriority(1);
task.setExecuteTime(new Date().getTime());
cacheService.lLeftPush("1001_1", JSON.toJSONString(task));
}
System.out.println("耗时" + (System.currentTimeMillis() - start));
}
// 673毫秒
@Test
public void testPiple2() {
long start = System.currentTimeMillis();
// 使用管道技术
List<Object> objectList = cacheService.getstringRedisTemplate().executePipelined(new RedisCallback<Object>() {
@Nullable
@Override
public Object doInRedis(RedisConnection redisConnection) throws DataAccessException {
for (int i = 0; i < 10000; i++) {
Task task = new Task();
task.setTaskType(1001);
task.setPriority(1);
task.setExecuteTime(new Date().getTime());
redisConnection.lPush("1001_1".getBytes(), JSON.toJSONString(task).getBytes());
}
return null;
}
});
System.out.println("使用管道技术执行10000次自增操作共耗时:" + (System.currentTimeMillis() - start) + "毫秒");
}
实现步骤
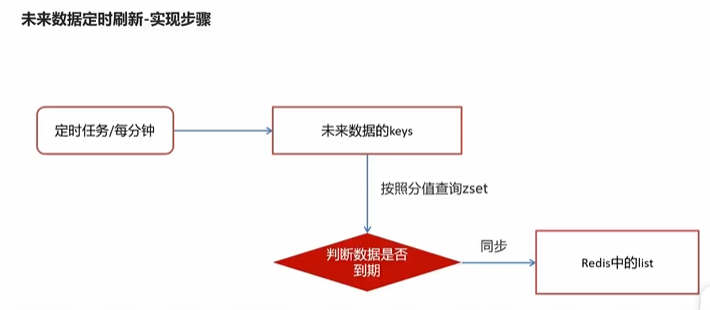
分值查key,判断时间,取出存list
impl
@Scheduled(cron = "0 */1 * * * ?")
public void refresh() {
log.info("未来任务zset定时刷新到list,开始同步数据...");
// 1. 获取所有未来数据的key (scan)
Set<String> futureKeys = cacheService.scan(ScheduleConstants.FUTURE + "*");
for (String futureKey : futureKeys) {
// 2. 获取当前数据的key,利用原先的futurekey future_100_50将future替换为TOPIC
String topKey = futureKey.replace(ScheduleConstants.FUTURE, ScheduleConstants.TOPIC);
// 3. 根据未来的key 查询数据, 0到当前时间范围内的所有task,set去重
Set<String> tasks = cacheService.zRangeByScore(futureKey, 0, System.currentTimeMillis());
// 4. 管道同步(list则push,zset则remove)
if (tasks != null && tasks.size() > 0) {
//此步骤会批量刷新到list,和删除rset
cacheService.refreshWithPipeline(futureKey,topKey,tasks);
log.info("成功将"+futureKey+"刷新到了"+topKey);
}
}
}
@Scheduled定时注解 秒分时,日月周, */1表示每一分钟
引导类开启定时功能注解
思路
- 获取所有未来数据的key (scan)
- 获取当前数据的key,利用原先的futurekey future_100_50将future替换为TOPIC
- 根据未来的key 查询数据, 0到当前时间范围内的所有task,set去重
- 管道同步(list则push,zset则remove)
debug启动测试
先增加几条未来数据
@Test
public void addTaskForRefresh() {
for (int i = 0; i < 5; i++) {
Task task = new Task();
task.setTaskType(100 + i);
task.setPriority(50);
task.setParameters("task test".getBytes());
task.setExecuteTime(new Date().getTime() + 100 * i);
long taskId = taskService.addTask(task);
System.out.println(taskId);
}
}

同步完成,这里图没截好,就是由future -> topic
3.6分布式下方法抢占执行——分布式锁
我们先开启两个服务
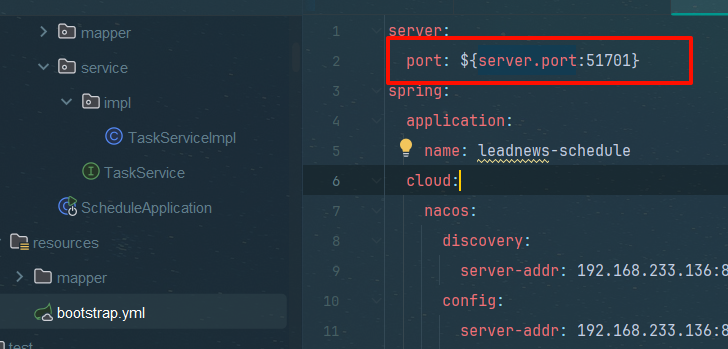
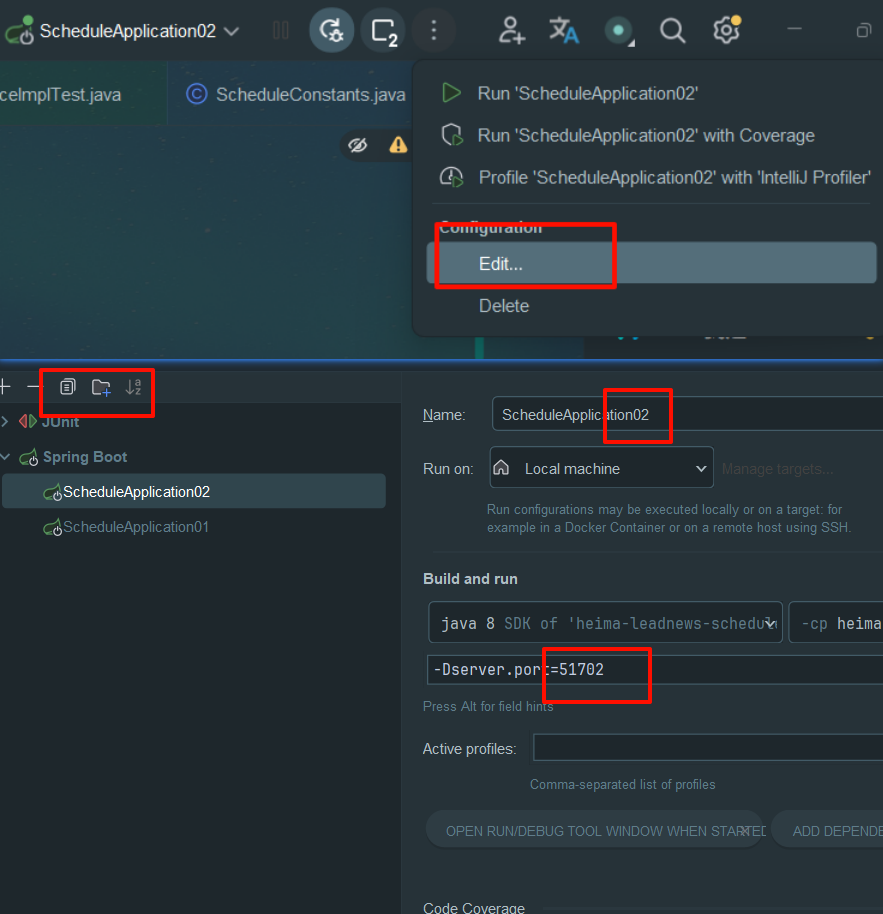
变量替换写死的端口号,同时默认值51701,后续添加虚拟机参数时替换
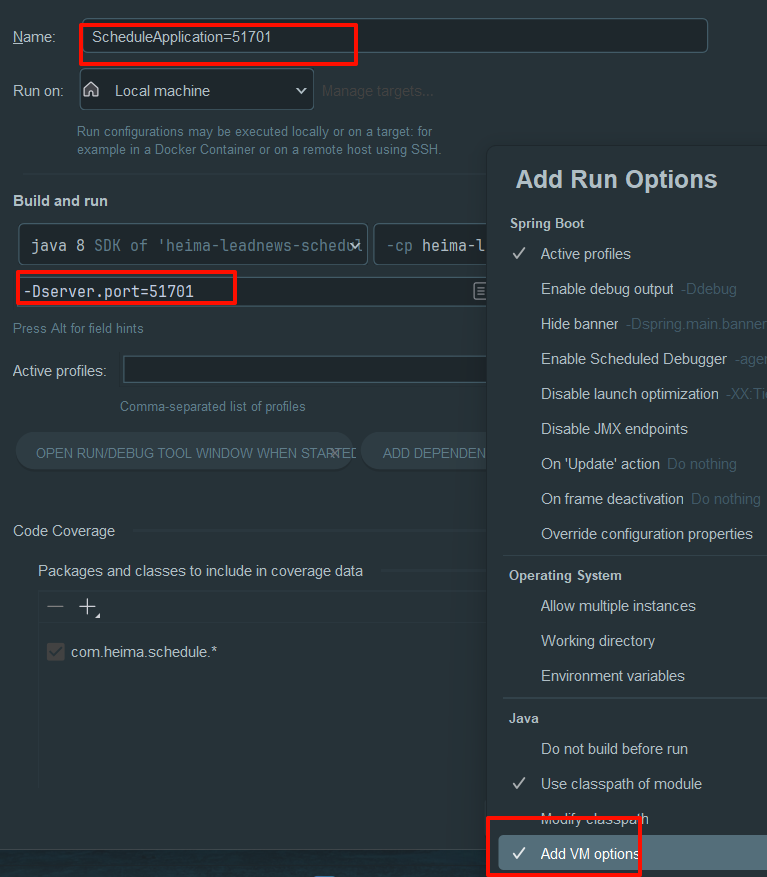
指定服务name和端口号参数
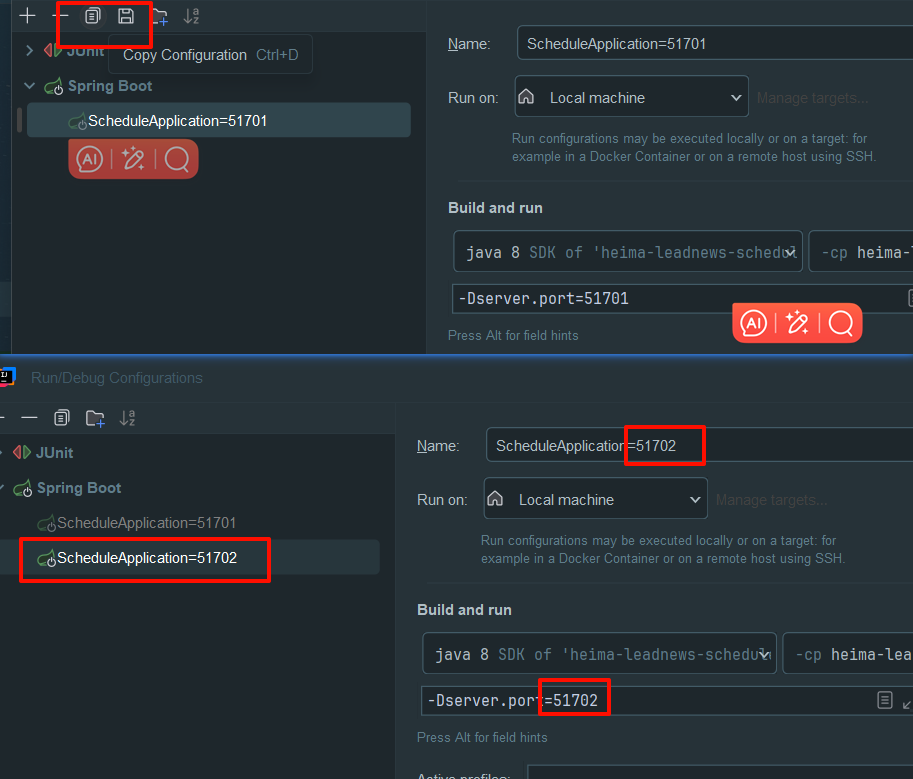
拷贝一份,修改为51702
启动51701 和51702类
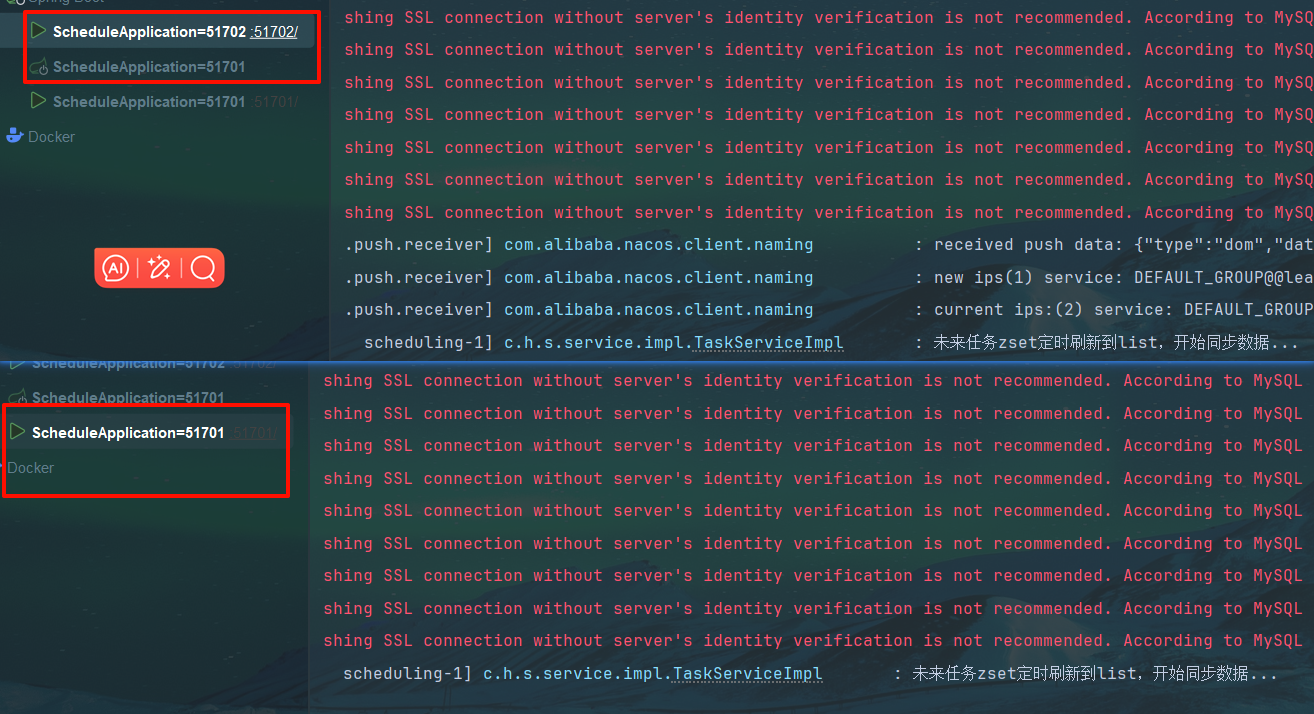
都会执行定时方法,此时需要使用分布式锁的方法
思路
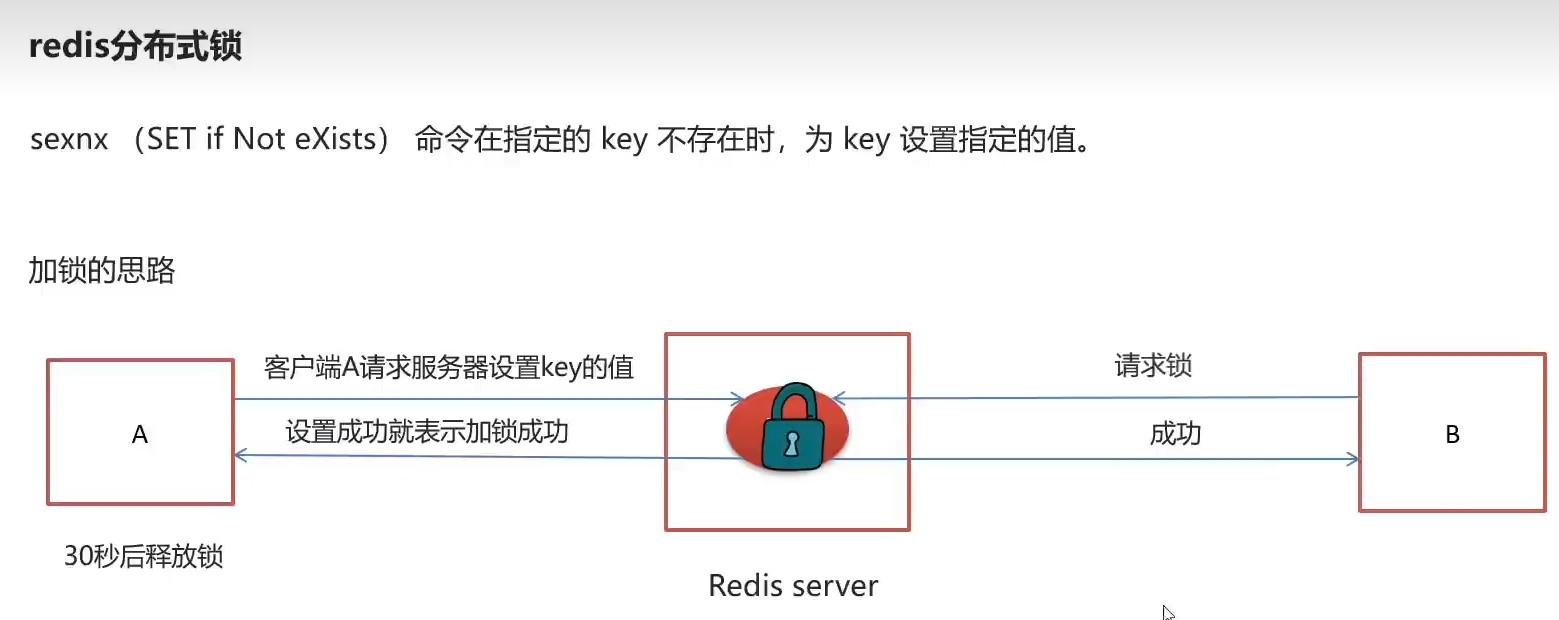
设置future为list时加锁,其他客户端想要修改得等设置好后的30秒冷却时间
步骤
调用tryLock,传锁名
public String tryLock(String name, long expire) {
name = name + "_lock";
String token = UUID.randomUUID().toString();
RedisConnectionFactory factory = stringRedisTemplate.getConnectionFactory();
RedisConnection conn = factory.getConnection();
try {
//参考redis命令:
//set key value [EX seconds] [PX milliseconds] [NX|XX]
Boolean result = conn.set(
name.getBytes(),
token.getBytes(),
Expiration.from(expire, TimeUnit.MILLISECONDS),
RedisStringCommands.SetOption.SET_IF_ABSENT //NX
);
if (result != null && result)
return token;
} finally {
RedisConnectionUtils.releaseConnection(conn, factory,false);
}
return null;
}
讲解
- 生成锁名作为key,唯一的锁uuid作为value
- 获取连接,设置k 和 v,和过期时间,还有 设置选项为NX, 全称为IF NOT EXIST 只有不存在才设置
- 设置成功有result了返回token表示 你生成了一把锁, 如果下一个人想要再次设置此时key值存在,result为空,加锁失败,不执行定时任务
方法impl改进
@Scheduled(cron = "0 */1 * * * ?")
public void refresh() {
String lockToken = cacheService.tryLock("FUTRUE_TASK_SYNC", 1000 * 30);
if (org.apache.commons.lang3.StringUtils.isNotBlank(lockToken)) {
log.info("未来任务zset定时刷新到list,开始同步数据...");
// 1. 获取所有未来数据的key (scan)
Set<String> futureKeys = cacheService.scan(ScheduleConstants.FUTURE + "*");
for (String futureKey : futureKeys) {
// 2. 获取当前数据的key,利用原先的futurekey future_100_50将future替换为TOPIC
String topKey = futureKey.replace(ScheduleConstants.FUTURE, ScheduleConstants.TOPIC);
// 3. 根据未来的key 查询数据, 0到当前时间范围内的所有task,set去重
Set<String> tasks = cacheService.zRangeByScore(futureKey, 0, System.currentTimeMillis());
// 4. 管道同步(list则push,zset则remove)
if (tasks != null && tasks.size() > 0) {
// 此步骤会批量刷新到list,和删除rset
cacheService.refreshWithPipeline(futureKey, topKey, tasks);
log.info("成功将" + futureKey + "刷新到了" + topKey);
}
}
}
}
重启测试方法有无同时执行
复制一份启动实例
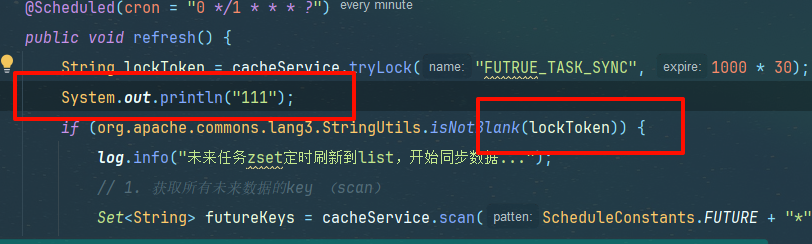

51701在获取锁时 发现被人抢先一步了 所以只输出了111
为什么不使用主动释放锁
当服务器出现故障时,主动释放锁步骤 没执行到,此时锁会一直存在,交给redis的expiration由他过时间来释放
3.7数据库同步到redis
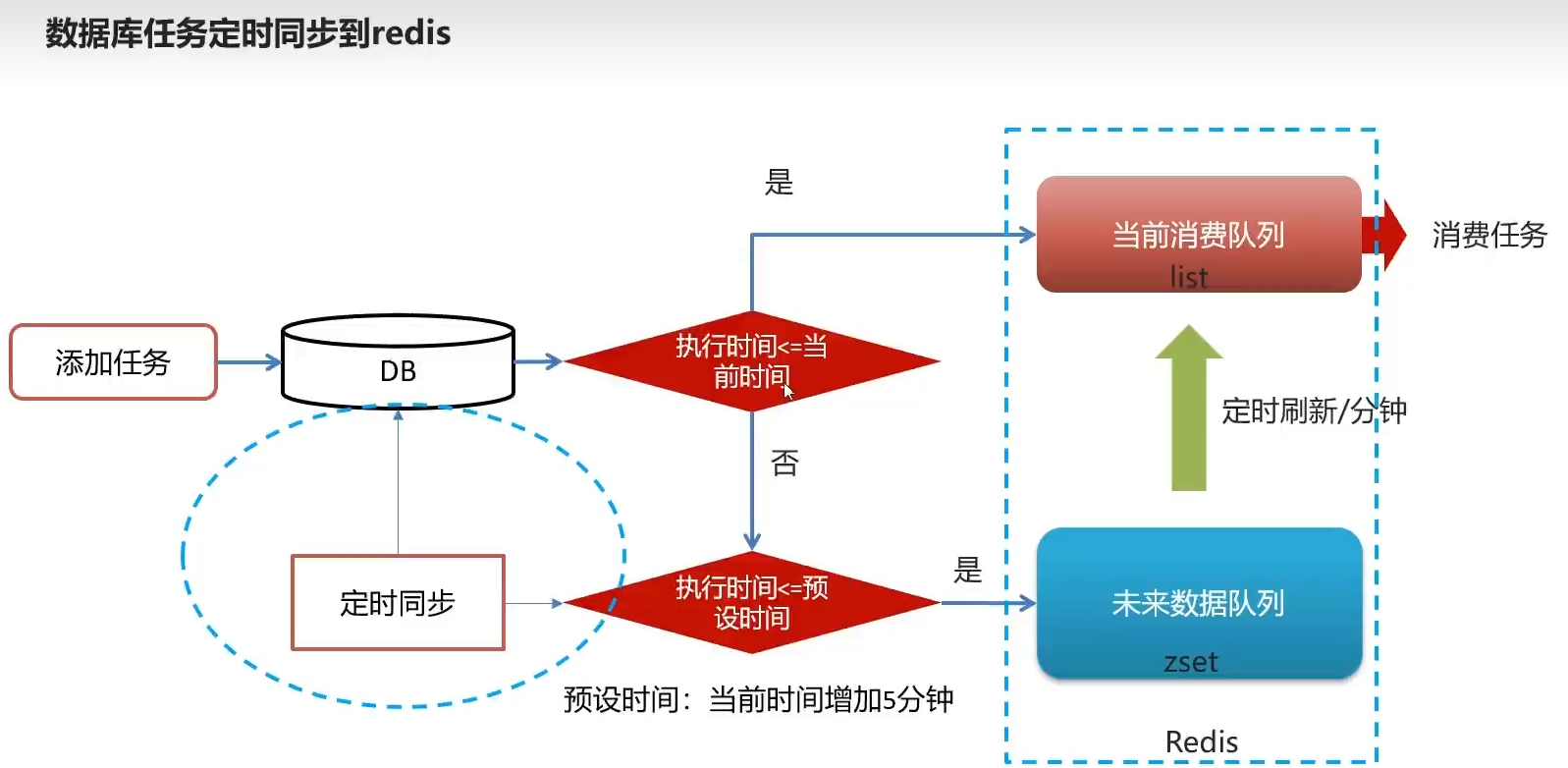
当预设时间还未大于执行时间,也就是提前半小时出门的那个出门时间点还没到,
步骤
-
清理数据,类似于瑞吉外卖的缓存更新,当有新的task进入时,将原来的缓存全部清除,然后再设置到redis同步,不清除如果当前缓存里的task未全部执行执行完毕会造成重复
就是说第一批的玩家如果还没通关 一起先踢掉,随着第二批的玩家再一起进入服务器,
为什么要这么做,不能不影响第一批玩家的位置,有第二批也就是新任务再同步吗,由于是定时同步,同步内容为一个整体,而不是实时的检测新的task进入就判断设置到redis,减少实时资源消耗?而是一段时间一批一段时间一批,而不是就每分每秒的监视?
思路
-
清所有缓存
-
根据条件查任务,提前执行时间五分钟的任务
-
添加到redis
-
防止服务器崩溃重新计时,启动该微服务时时立即执行该方法
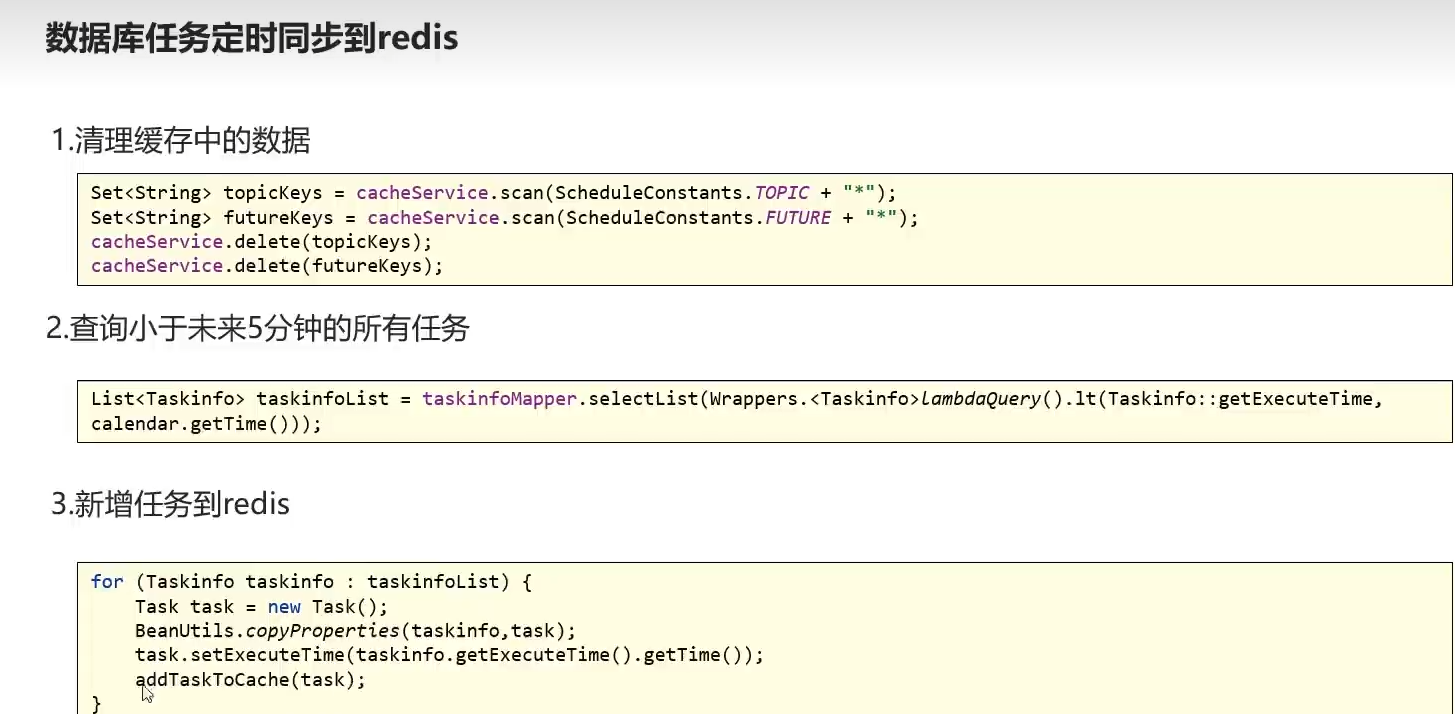
// 数据库任务同步到redis,每五分钟,且当服务器挂掉后,微服务启动时执行该方法
@PostConstruct
@Scheduled(cron = "0 */5 * * * ?")
public void reloadData() {
// 1.清除所有缓存
clearCache();
// 2.查询大于执行时间前五分钟的那个时间点的数据
// 也可以获取五分钟之后的时间,然后挑选出比这个时间小的
Calendar instance = Calendar.getInstance();
instance.add(Calendar.MINUTE, 5);
List<Taskinfo> taskInfoList = taskinfoMapper.selectList(Wrappers.<Taskinfo>lambdaQuery().lt(Taskinfo::getExecuteTime, instance.getTime()));
if (taskInfoList != null && taskInfoList.size() > 0) {
for (Taskinfo taskinfo : taskInfoList) {
// 将任务拷贝到task然后添加到redis, task相当于一个匹配数据库字段的类
Task task = new Task();
BeanUtils.copyProperties(taskinfo, task);
task.setExecuteTime(taskinfo.getExecuteTime().getTime());
addTaskToCache(task);
}
}
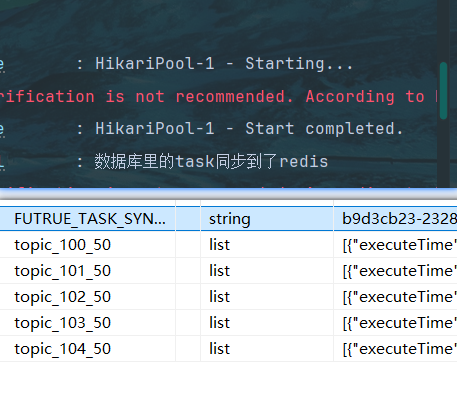
log.info("数据库里的task同步到了redis");
}
测试
将数据库和redis的信息全删,执行test类里的方法生成新的
启动定时任务引导类
3.8延时任务接口定义
接口
package com.heima.apis.schedule;
import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.schedule.dtos.Task;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
@FeignClient("leadnews-schedule")
public interface IScheduleClient {
/**
* 添加延迟任务
* @param task
* @return
*/
@PostMapping("/api/v1/task/add")
public ResponseResult addTask(@RequestBody Task task);
/**
* 取消任务
* @param taskId
* @return
*/
@GetMapping("/api/v1/task/{taskId}")
public ResponseResult cancelTask(@PathVariable("taskId") long taskId);
/**
* 按照类型和优先级拉取任务
* @param type
* @param priority
* @return
*/
@GetMapping("/api/v1/task/{type}/{priority}")
public ResponseResult poll(@PathVariable("type") int type,@PathVariable("priority") int priority);
}
服务实现接口
服务下创建feign包
package com.heima.schedule.feign;
import com.heima.apis.schedule.IScheduleClient;
import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.schedule.dtos.Task;
import com.heima.schedule.service.TaskService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
@RestController
public class ScheduleClient implements IScheduleClient {
@Autowired
private TaskService taskService;
/**
* 添加延迟任务
*
* @param task
* @return
*/
@PostMapping("/api/v1/task/add")
public ResponseResult addTask(@RequestBody Task task) {
return ResponseResult.okResult(taskService.addTask(task));
}
/**
* 取消任务
*
* @param taskId
* @return
*/
@GetMapping("/api/v1/task/{taskId}")
public ResponseResult cancelTask(@PathVariable("taskId") long taskId){
return ResponseResult.okResult(taskService.cancelTask(taskId));
}
/**
* 按照类型和优先级拉取任务
*
* @param type
* @param priority
* @return
*/
@GetMapping("/api/v1/task/{type}/{priority}")
public ResponseResult poll(@PathVariable("type") int type,@PathVariable("priority") int priority) {
return ResponseResult.okResult(taskService.poll(type,priority));
}
}
3.9发布文章添加延迟任务
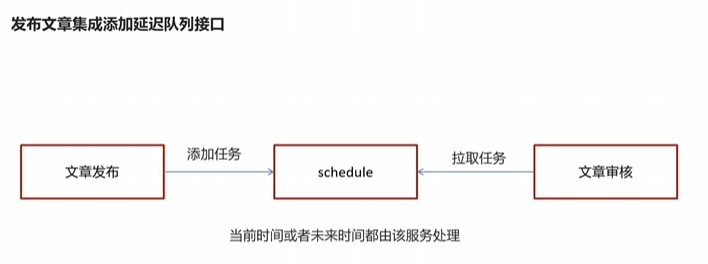
序列化方法
网络传输实体类将该实体类序列化, jdk序列化器没有谷歌提供的protostuff好用
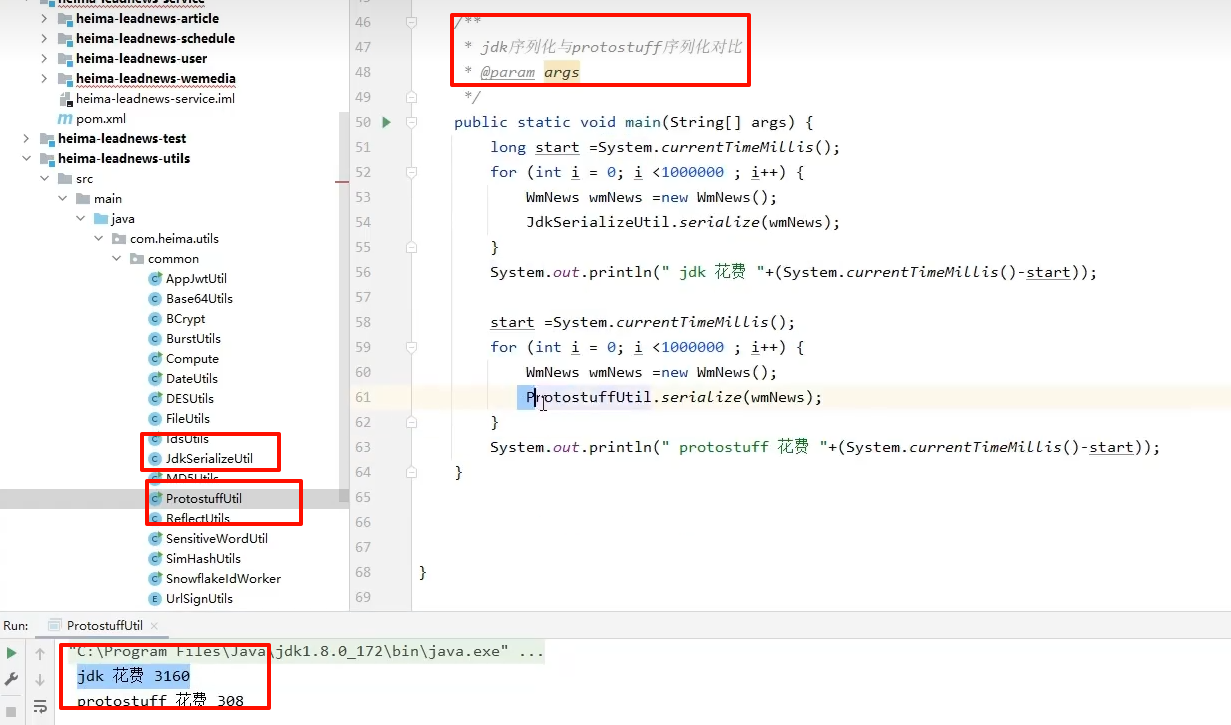
序列化依赖
<dependency>
<groupId>io.protostuff</groupId>
<artifactId>protostuff-core</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>io.protostuff</groupId>
<artifactId>protostuff-runtime</artifactId>
<version>1.6.0</version>
</dependency>
思路
- 初始化一个task,包含定时扫描状态,执行时间
- 指定审核发布的文章id,添加文章到任务队列中去,服务之间传输类,网络传输类,序列化文章类(序列化工具类已添加,)
常量类
model的enum包下
package com.heima.model.common.enums;
import lombok.AllArgsConstructor;
import lombok.Getter;
@Getter
@AllArgsConstructor
public enum TaskTypeEnum {
NEWS_SCAN_TIME(1001, 1,"文章定时审核"),
REMOTEERROR(1002, 2,"第三方接口调用失败,重试");
private final int taskType; //对应具体业务
private final int priority; //业务不同级别
private final String desc; //描述信息
}
设置任务的状态,
文章任务service
在自媒体的service包下
package com.heima.wemedia.service;
import java.util.Date;
public interface WmNewsTaskService {
/**
* 添加任务到延迟队列中
* @param id 文章的id
* @param publishTime 发布的时间 可以做为任务的执行时间
*/
public void addNewsToTask(Integer id, Date publishTime);
}
impl
package com.heima.wemedia.service.impl;
import com.alibaba.fastjson.JSON;
import com.heima.apis.schedule.IScheduleClient;
import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.common.enums.TaskTypeEnum;
import com.heima.model.schedule.dtos.Task;
import com.heima.model.wemedia.pojos.WmNews;
import com.heima.utils.common.ProtostuffUtil;
import com.heima.wemedia.service.WmNewsAutoScanService;
import com.heima.wemedia.service.WmNewsTaskService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Async;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Service;
import java.util.Date;
@Service
@Slf4j
public class WmNewsTaskServiceImpl implements WmNewsTaskService {
@Autowired
private IScheduleClient scheduleClient;
/**
* 添加任务到延迟队列中
* @param id 文章的id
* @param publishTime 发布的时间 可以做为任务的执行时间
*/
@Override
@Async
public void addNewsToTask(Integer id, Date publishTime) {
log.info("添加任务到延迟服务中----begin");
Task task = new Task();
task.setExecuteTime(publishTime.getTime());
task.setTaskType(TaskTypeEnum.NEWS_SCAN_TIME.getTaskType());
task.setPriority(TaskTypeEnum.NEWS_SCAN_TIME.getPriority());
WmNews wmNews = new WmNews();
wmNews.setId(id);
task.setParameters(ProtostuffUtil.serialize(wmNews));
scheduleClient.addTask(task);
log.info("添加任务到延迟服务中----end");
}
}
addNewsToTask需要异步调用,让用户更好的体验感
修改新增文章impl类

不直接审核了,而是添加到任务队列里去,这里我们启动wemedia和wemedia的网关和任务队列服务 增加文章进行测试
测试立即审核任务此刻的
清空表,后续添加文字查看有无加到该队列里去,redis也清空
这里报了一个错,说是publishTime找不到了,因此我在submit文章那里加了一处,或者直接修改为new Date



锁超30秒了没截到图
测试定时审核测试一天后的
定时一个一天后的
但是刚才添加任务设置的发布时间这里导致变成了 立即执行任务了,这下得来看看为什么publishTime是空了

前端请求没问题,看后端
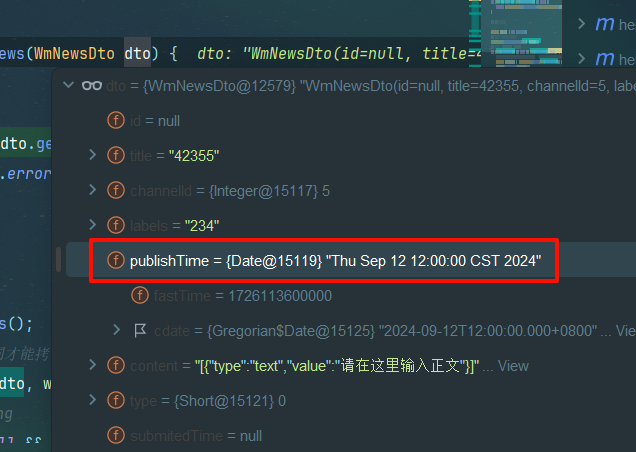
也没问题啊byd
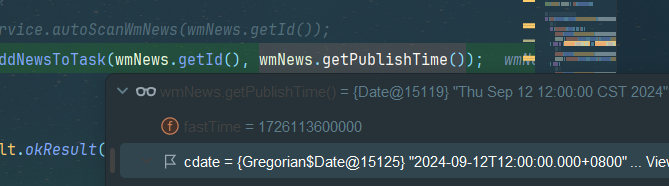
好吧是正常的,且redis里没有该数据

添加未来五分钟内的

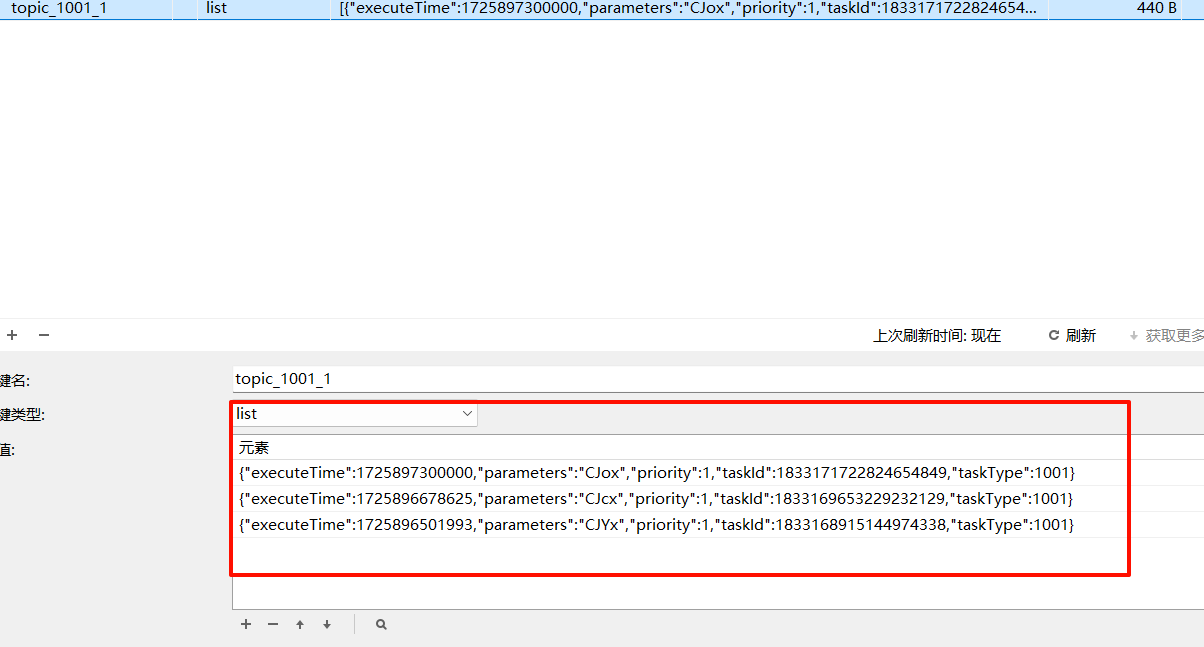
到点变topic,如我所料奥里给
4.消费任务
此时我们已经把添加的文章(包含了文章id的wmnews)传到定时任务去了
接下来就是要从redis拉取当前要执行的审核文章也就是topic文章进行审核
调用远程接口,获取responseResult,内部包含task,从中获取wmnews,根据wmnews获取id。根据id进行审核WmautoScan,不过由于是网络传输,内容是序列化后的字节文件,需要进行反序列化 由于data里的params是T,泛型对象,可能不是task对象,先json串在java对象,然后强转为task,(这一步不太清楚,详情自行查询文章)这里给出gpt回答
- 确保数据一致性:
responseResult.getData()可能返回一个对象,这个对象可能不是Task类型。通过先转换为 JSON 字符串,然后再转换回Task对象,可以确保数据的一致性,并且确保转换过程中不会丢失任何信息。- 避免循环引用:如果
Task对象中包含对其他对象的引用,直接转换可能会遇到循环引用的问题。通过先转换为 JSON 字符串,然后再转换回对象,可以避免这些循环引用问题。- 处理复杂对象:如果
responseResult.getData()返回的是一个复杂对象,直接转换可能会遇到类型不匹配的问题。通过先转换为 JSON 字符串,然后再转换回对象,可以确保类型匹配。- 序列化和反序列化:在某些情况下,直接转换可能会遇到序列化和反序列化的问题。通过先转换为 JSON 字符串,然后再转换回对象,可以确保序列化和反序列化的正确性。
总结来说,这一步的目的是为了确保数据的一致性、避免循环引用、处理复杂对象,以及确保序列化和反序列化的正确性。直接获取
task可能会导致类型不匹配、循环引用等问题,因此需要先转换为 JSON 字符串,然后再转换回对象。
再总结,数据一致性,避免循环引用,出现序列,反序列化问题
添加注解,每秒钟执行一次审核,和开启定时任务注解
步骤
- 远程客户端pull下来task (判断code为200,data不为空)
- 获取task的参数
- 反序列化
- 注入autoscanServiceImpl调用自动审核方法
@Autowired
private WmNewsAutoScanService wmNewsAutoScanService;
@Autowired
private IScheduleClient scheduleClient;
@Override
public void scanNewsByTask() {
// 1. 远程客户端pull下来task (判断code为200,data不为空)
ResponseResult responseResult = scheduleClient.poll(TaskTypeEnum.NEWS_SCAN_TIME.getTaskType(), TaskTypeEnum.NEWS_SCAN_TIME.getPriority());
if (responseResult.getCode() == 200 && responseResult.getData() != null) {
// 2. 获取task的参数
Task task = JSON.parseObject(JSON.toJSONString(responseResult.getData()), Task.class);
// 3. 反序列化
WmNews wmNews = ProtostuffUtil.deserialize(task.getParameters(), WmNews.class);
// 4. 注入autoscanServiceImpl调用自动审核方法
wmNewsAutoScanService.autoScanWmNews(wmNews.getId());
}
}
我们启动自媒体,自媒体网关,文章(审核通过后自媒体到时候通过远程调用发布文章),延迟队列服务
发布一个即时的文章测试
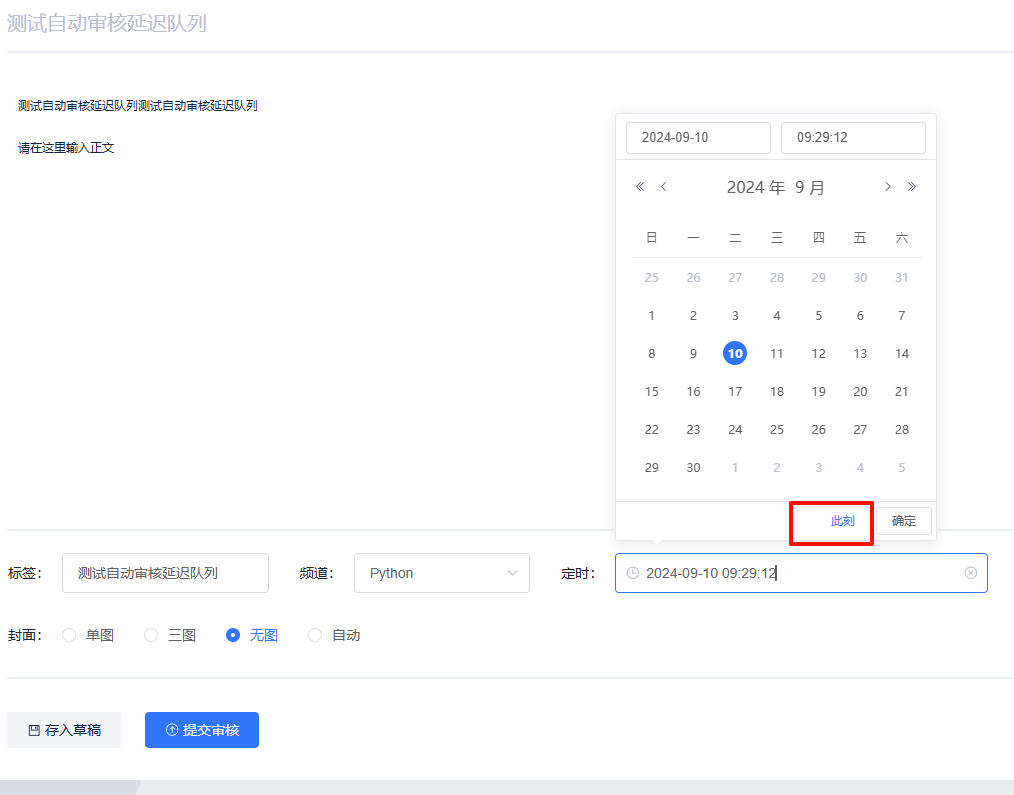

发布一个一分钟后的进行测试
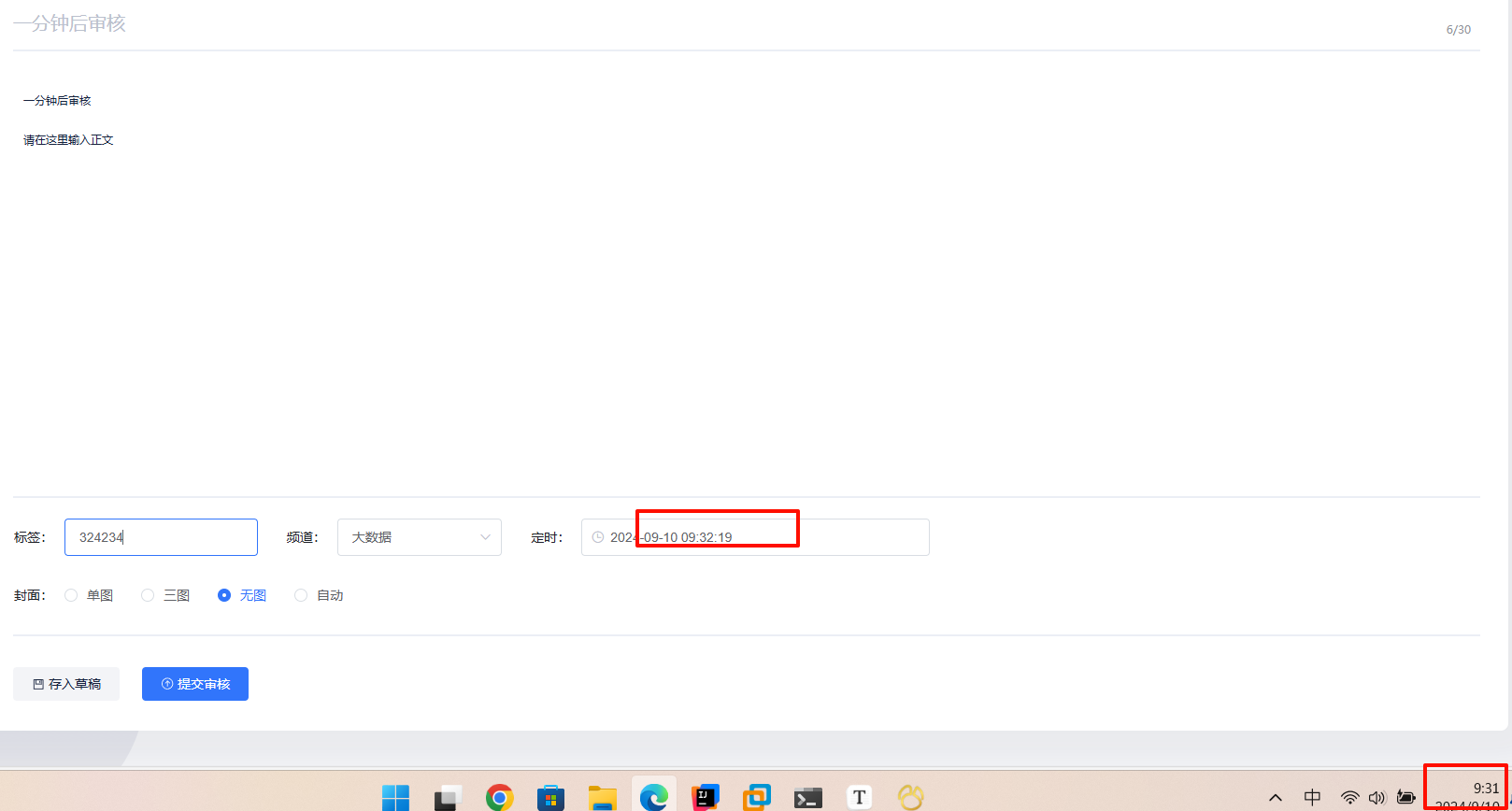
先到了redis的zset,再list,最后审核,不过这里偏差了半分钟左右,估计是同步到list这一块设置的每一分钟同步一次导致的,所以这种细粒度只能精确到分钟
















 172
172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









