






前言
【DataWhale LLM】系列是本人参与DataWhale的开源学习项目的笔记,该开源项目链接:
动手学大模型应用开发 (datawhalechina.github.io)
本系列的内容都是本人基于以上链接学习之后按自己见解写的,如有问题还请指出(本人小白)。
1.LLM简介
1.1.LLM概念(省流:大模型)
LLM,全称:Large Language Model,中文名:大语言模型,也称大型语言模型,是一种旨在理解和生成人类语言的人工智能模型。
LLM 通常指包含数百亿(或更多)参数的语言模型,它们在海量的文本数据上进行训练,从而获得对语言深层次的理解。
1.2.常见LLM
- GPT 系列:由 OpenAI 提出,特点是通过语言建模压缩世界知识。
- Claude 系列:由 Anthropic 公司开发,致力于提升模型的理解和生成能力。
- PaLM/Gemini 系列:由 Google 开发,PaLM 是早期模型,Gemini 是后续升级版本。
- 文心一言:基于百度文心大模型,中文能力强。
- 星火大模型:科大讯飞发布,支持多种自然语言处理任务。
- LLaMA 系列:Meta 开源的基础语言模型,强调使用公开数据集训练。
- 通义千问:阿里巴巴基于“通义”大模型研发的开源模型。
1.3.LLM的能力与特点
LLM的能力与特点如下图所示:
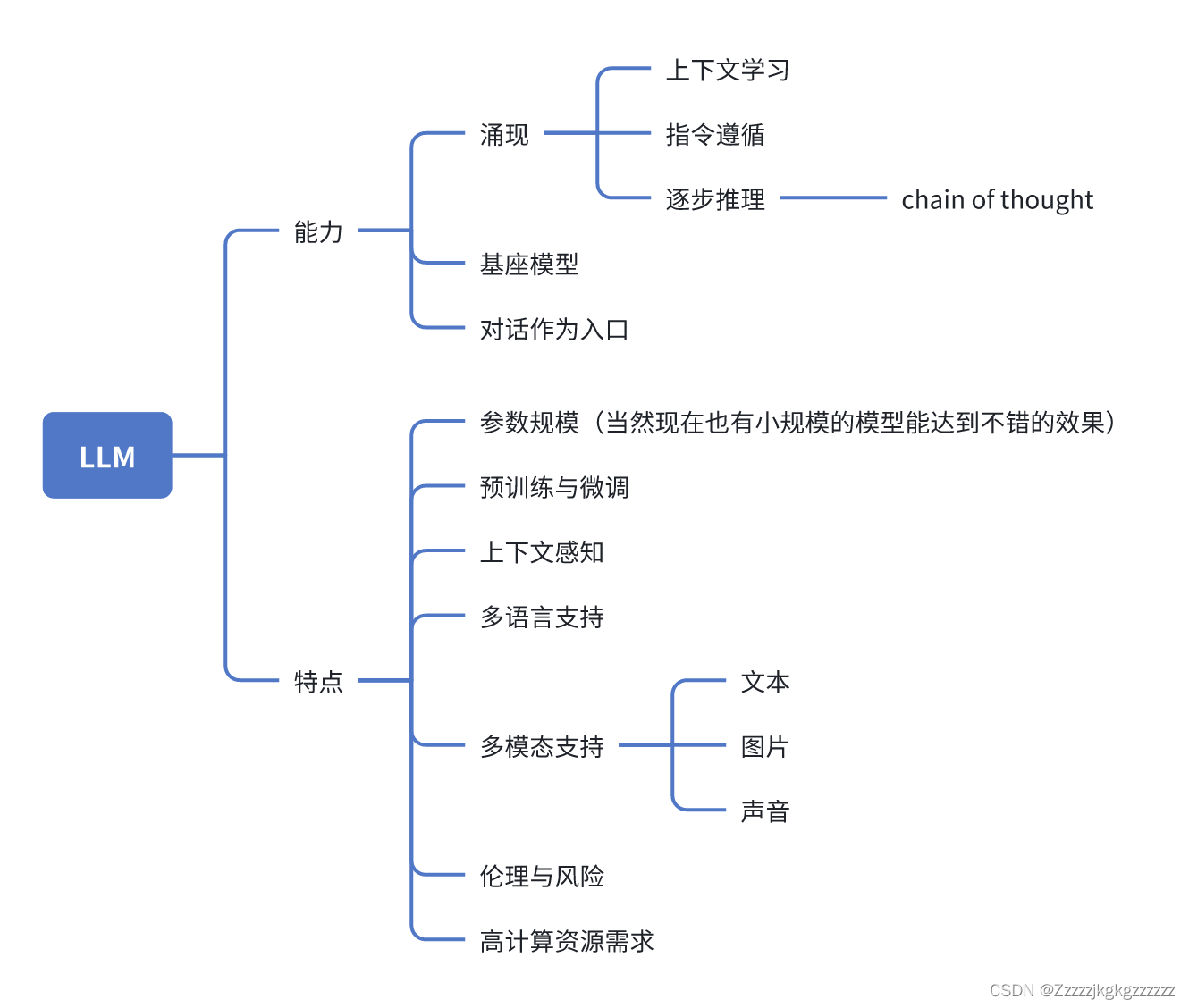
- 涌现能力:模型规模增大引起性能迅速提升而具备的能力。如:上下文学习、指令遵循、逐步推理。
- 基座模型:LLM可作为应用建设的基础。
- 对话作为入口:可以跟LLM聊天。
本节参考链接:
LLM Universe动手学大模型应用开发 - 飞书云文档 (feishu.cn)
2.RAG
2.1.RAG概念&作用
概念:RAG,全称:Retrieval-Augmented Generation,中文名:检索增强生成。RAG是一种为了提高LLM的性能与输出质量的架构。
作用:要了解RAG的作用,首先得看LLM目前的问题(毕竟RAG是用来优化LLM的)。
LLM目前面临的问题:
信息偏差/幻觉
知识更新滞后性(LLM 基于静态的数据集训练,无法及时反映最新的信息动态。)
内容不可追溯
领域专业知识能力欠缺
推理能力限制
应用场景适应性受限
长文本处理能力较弱
RAG架构巧妙地整合了从庞大知识库中检索到的相关信息,并以此为基础,指导大型语言模型生成更为精准的答案,从而显著提升了回答的准确性与深度。RAG可以使LLM不用进行Fine-tuning来接受新信息。(用Fine-tuning更费时费力,更慢)
说人话就是:LLM只会背书不会自主学习新东西,你问它背过的东西它就回答得好,一旦超纲它就乱答。RAG可以根据提出的问题,在一个知识库里检索相关信息告诉LLM,帮LLM在不用背新书的情况下更好地答题。
2.2.RAG的工作流程
以下是RAG的工作流程图: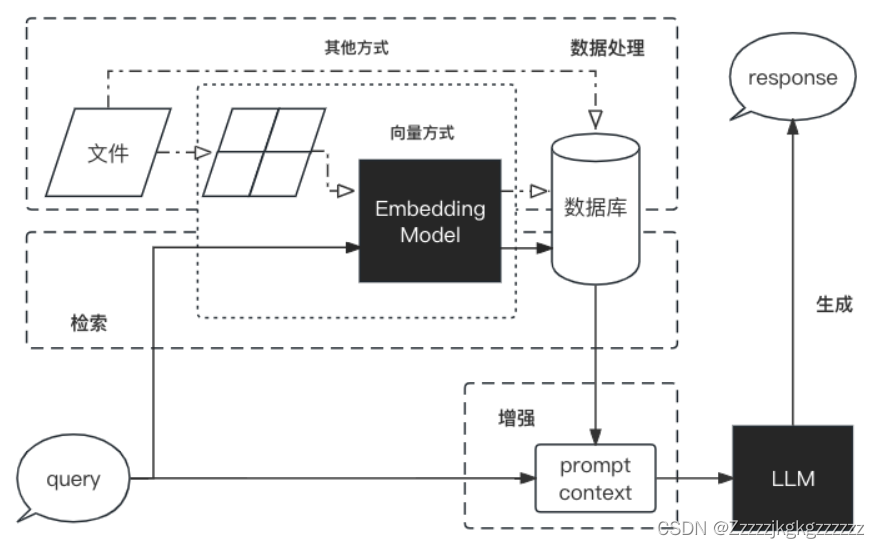
数据处理阶段:
对原始数据进行清洗和处理。
将处理后的数据转化为检索模型可以使用的格式。
将处理后的数据存储在对应的数据库中。
检索阶段:
将用户的问题输入到检索系统中,从数据库中检索相关信息。
增强阶段:
对检索到的信息进行处理和增强,以便生成模型可以更好地理解和使用。
生成阶段:
将增强后的信息输入到生成模型中,生成模型根据这些信息生成答案。
2.3.RAG VS Fine-tuning(微调)
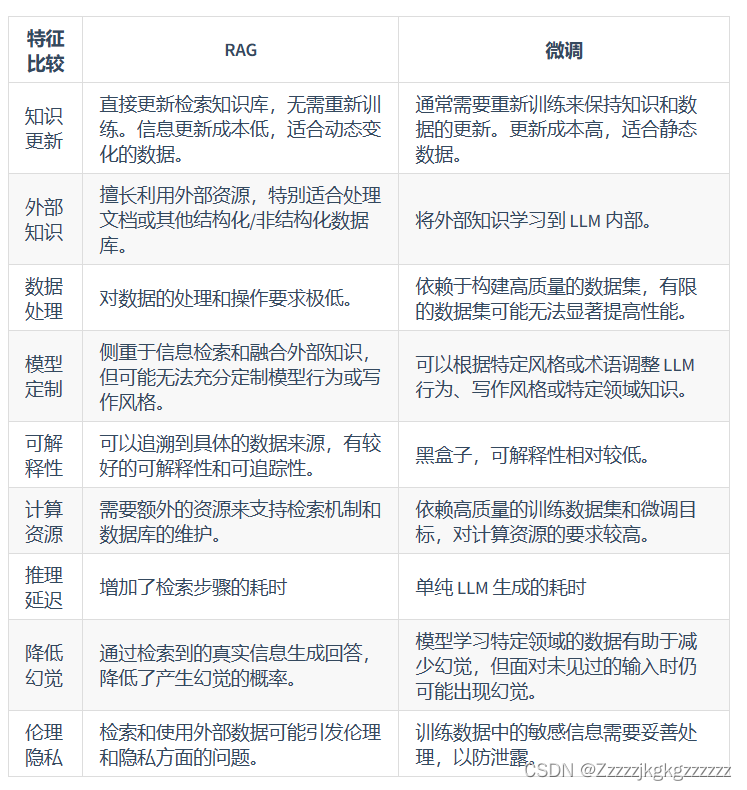
RAG更多知识可参考链接:
Class3 茴香豆 RAG智能助理 (notion.site)
3.Langchain
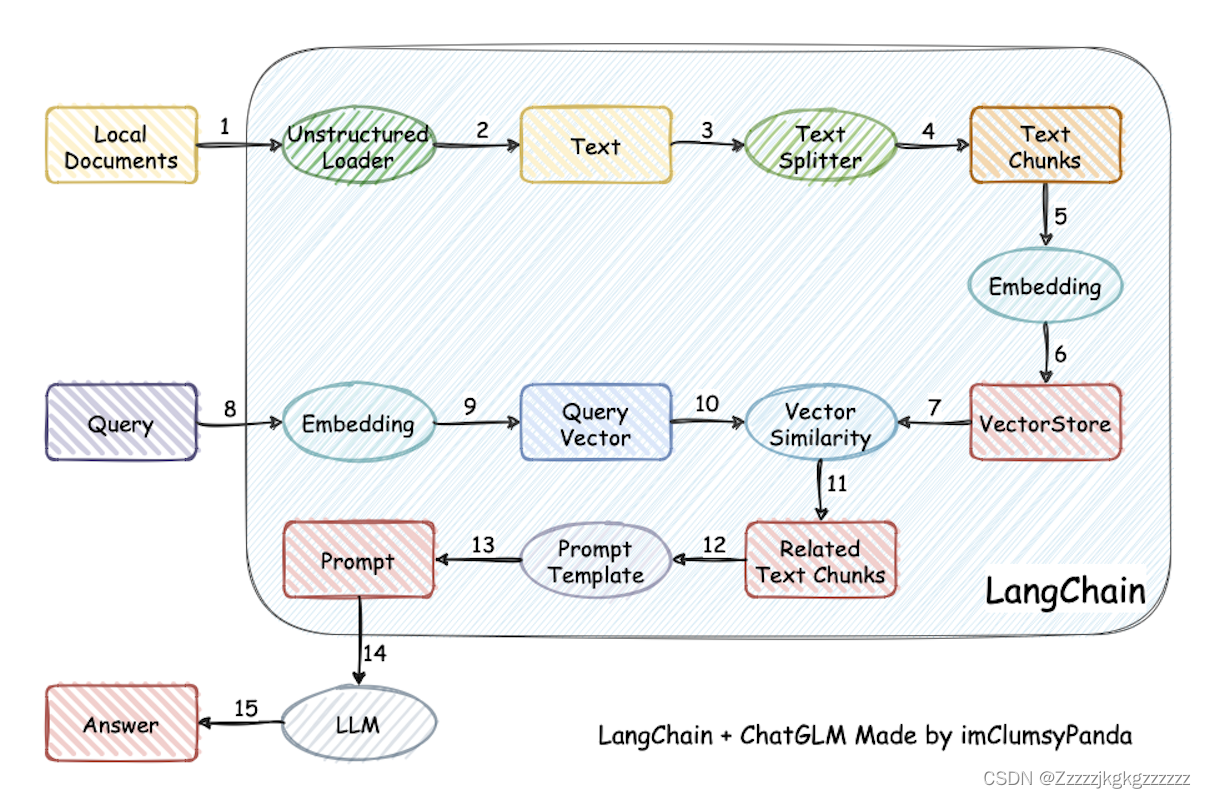
LangChain 框架是一个开源工具,充分利用了大型语言模型的强大能力,以便开发各种下游应用。它的目标是为各种大型语言模型应用提供通用接口,从而简化应用程序的开发流程。具体来说,LangChain 框架可以实现数据感知和环境互动,也就是说,它能够让语言模型与其他数据来源连接,并且允许语言模型与其所处的环境进行互动。
利用 LangChain 框架,我们可以轻松地构建如下所示的 RAG 应用。在下图中,每个椭圆形代表了 LangChain 的一个模块,例如数据收集模块或预处理模块。每个矩形代表了一个数据状态,例如原始数据或预处理后的数据。箭头表示数据流的方向,从一个模块流向另一个模块。在每一步中,LangChain 都可以提供对应的解决方案,帮助我们处理各种任务。
4.开发LLM应用的整体流程
4.1.大模型开发
大模型开发:开发以大语言模型为功能核心、通过大语言模型的强大理解能力和生成能力、结合特殊的数据或业务逻辑来提供独特功能的应用。
在大模型开发中,我们一般不会去大幅度改动模型,而是将大模型作为一个调用工具,通过 Prompt Engineering、数据工程、业务逻辑分解等手段来充分发挥大模型能力,适配应用任务,而不会将精力聚焦在优化模型本身上。因此,作为大模型开发的初学者,我们并不需要深研大模型内部原理,而更需要掌握使用大模型的实践技巧。
4.2.大模型开发的一般流程
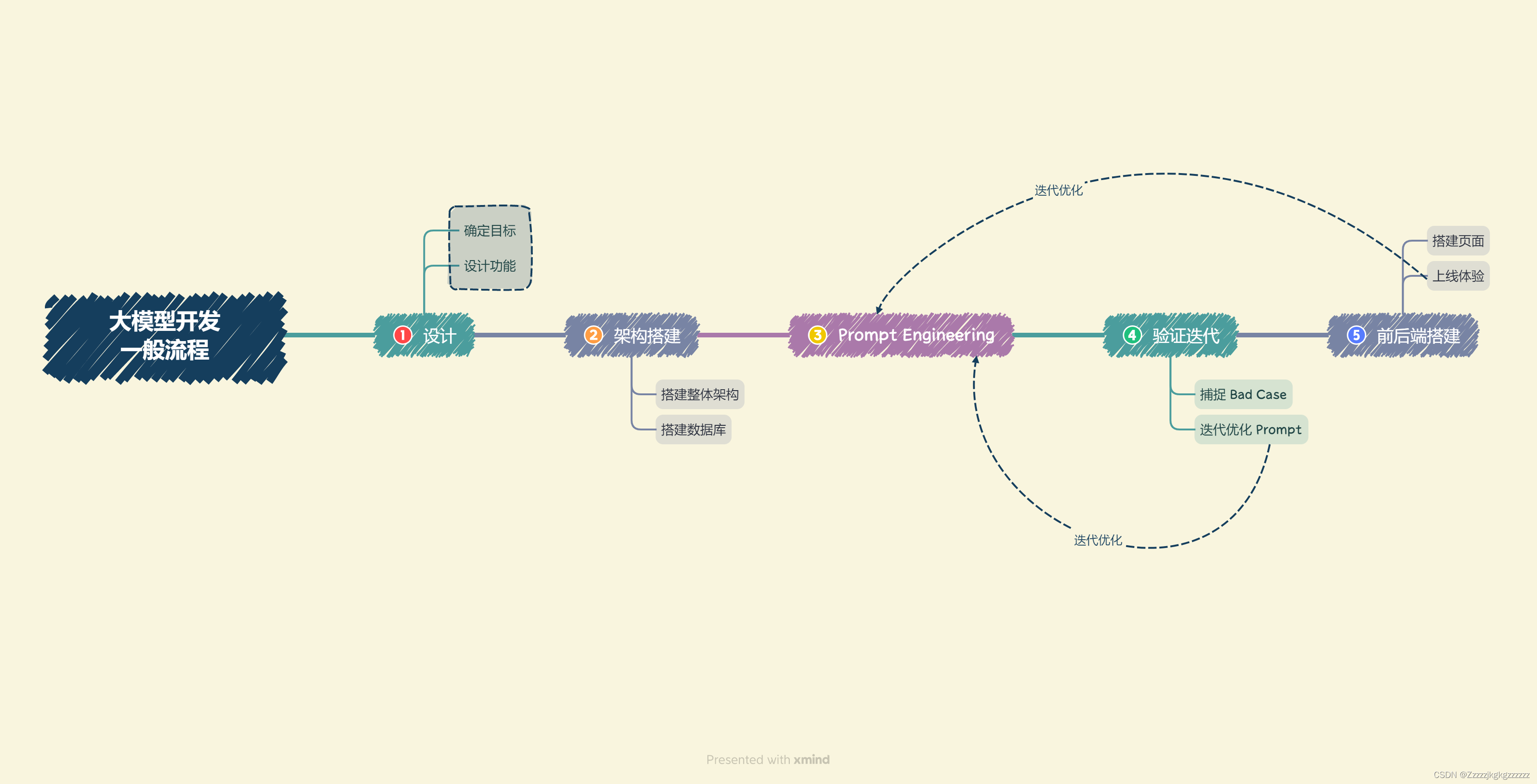
(本节比较难懂,学完后面再看会好点)(具体内容可以看前言里的那个原链接)
5.阿里云服务器使用攻略&Jupyter使用
可参考DateWhale的教程:
5. 阿里云服务器使用攻略 (datawhalechina.github.io)
6.环境配置
通过上节可以实现用VScode连接阿里云服务器了,DataWhale的这个教程就是让代码在服务器上跑,VScode就是用来控制服务器的。服务器按教程来的话,系统就是Linux的,配置环境就选Linux的运行。
在哪运行那些代码?VScode!!!
在完成上一节之后,打开VScode,应该会弹出这个窗口:

输入密码,登进去之后,Ctrl+` 打开终端(`就是字母上面那排数字,1的左边那个)
打开终端之后就可以在终端里输入教程中的代码一步步配置就行。
教程链接:7. 环境配置 (datawhalechina.github.io) (注意选择Linux的代码复制!!!)
安装miniconda可以看这个:安装miniconda(linux,xshell)_linux 命令行 minconda-CSDN博客
下好miniconda之后可以看看这个链接,配置镜像源加速,熟悉以下conda的指令(miniconda和anaconda用起来是一样的):还是搞不懂Anaconda是什么?读这一篇文章就够了-CSDN博客
(在环境配置这节直接看教程,我直接就懵了当时,根本就不知道在哪运行代码,希望能够帮助到大家)
访问GitHub国内网太慢,可以试试fastgithub(github加速器)这个软件,下载地址:
https://pan.xunlei.com/s/VNkZDuBtf34LBe1QqSdEShWuA1?pwd=f3dm















 174
174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









