






已经有许多关于商业微处理器从单内核过度到多内核的文章,这个趋势表现的最明显的是CPU处理器上面。现在的商业PC机通常包含2至8个核心,当然,将来可能会更多。用这么多内核的目的是通过利用适当的并行工作负载来执行多个独立的程序或者执行由多个并行任务组成的程序,从而实现更高的性能,然而单核芯片要维持相同性能只能靠顺序的工作负载(译者注:明显力不从心嘛!)
与此相关的一个架构趋势是日益突出的面向吞吐量微处理器架构体系。有一些处理器,比如SUN的Niagara,NVIDIA的图形处理单元或GPU,都跟随着早先的面向吞吐量处理器的设计,但是更广泛地被使用了在商品机上面。笼统的说,他们更专注于执行并行工作负载,同时试图提高总吞吐量,即使牺牲 一个任务中可能需要的串行方面的性能。虽然提高总吞吐量在单个任务上面增加时延并不是一个好的权衡,但是这确实是一个无可非议的、正确的设计决策在许多 依赖并行计算的问题领域,包括实时计算机图形、视频处理、医学图像分析、分子动力学、天体物理模拟和基因序列调整。现在的GPU是完全可编程的,设计来满足问题领域——实时计算机图形,有极大的固有的并行性。此外,实时图像在工作的总量上放置了一个可以完成一个帧的额外时间(通常持续1/30秒)。由于他们历史的发展,GPU已经发展成了面向吞吐量处理器架构的典范。他们强调吞吐量的优化、期望丰富和可用的并行性要比其他面向吞吐量的架构更好。他们也可以广泛的使用和易于编程。NVIDIA在2006年发布了其首款支持CUDA并行计算架构的GPU,目前正在发售的代号为“Fermi”24的第三代CUDA架构,是NVIDIA在2010年发布的Tesla C2050和其他处理器。
图1所示的为一个包含25095个原子的核小体结构,该结构可以用来评测用于分子动力学模拟程序工具包的AMBER的性能。分子动力学领域中的多核计算具有其内在的并行性,因此,近期AMBER增加了加速CUDA计算功能。目前溶剂方面的计算依赖的是由2台4核的Intel Xeon E5462处理器组成的8核计算系统,在采用了加速CUDA计算功能后,计算速率可达到每天中平均0.06纳秒一次,而同样的情况若采用NVIDIA Tesla C2050则是每天中平均1.04纳秒一次,该速率大概仅是单核顺序运算的144倍,也仅是八核运算的17倍之多。
以GPU为例,本篇文章将分析吞吐量优化处理器和比较传统的时延优化处理器间的基础架构设计方案的不同。这些不同同时也导致了并行编程方法,从性质上来说,就与现在流行的CPU并行线程模型不同。
吞吐量优化的处理器
任务延迟(任务发起到完成所花费的时间)和吞吐量(单位时间完成的工作总量)作为两种基本的处理器性能衡量指标。为了避免顾此失彼,处理器设计在时延和吞吐量两者间优化方面做了许多精心的权衡。根据可能承受的工作负载,现实世界中的处理器倾向于打破两者优化间的平衡。
传统的标量微处理器基本上是采用时延优化类型的架构,旨在任何时候通过避免任务级别延迟来减少单个串行程序的运行时间。很多架构技术包括无序执行、推断执行,复杂内存缓存都可以避免任务级别延迟。这种传统的设计方法是基于认为工作负载中提供给处理器的可用并行执行数是非常稀缺的保守判断。典型的英特尔奔腾4单核标量处理器在时延优化上可谓下足了功夫。最近很多多核处理器(比如英特尔酷睿2双核和酷睿i7)反映着一种趋势,即在时延优化上做了让步并且支持适量的并行执行。
相反地,基于工作负载中可以支持高并行这种认识,吞吐量优化处理器产生了。这种不同导致了区别于传统时序机的架构产生。一般来说,吞吐量优化处理器架构有三个重要特征:强调采用多个单核处理器,广泛的硬件多线程,使用单指令多数据(或者称为SMID)执行。以GPU为例,积极地提高吞吐量类型的处理器愿意牺牲单线程执行效率去扩大整个线程中总体计算吞吐量。(译者注:翻完时浏览器挂掉又得重翻的说,吃力ing....)
成功的处理器不可能只优化总体任务吞吐量然而完全忽略单一任务延迟,反之亦然。不同处理器在时延或吞吐量优化方面着重点不同。例如,单一吞吐量优化架构也许不都采用上述3个特点。同样值得注意的是,不同架构策略包含流水线、复用、无序执行,通过提高指令级吞吐量来避免任务级别延迟。
硬件多线程。很多并行的计算能被分解一系列并发的时序任务,在所有线程中这些任务潜在地可能并行执行或同步执行。我们把每个线程都看做一个虚拟标量处理器,很显然表示每个线程都有程序计数器、寄存器文件和相应地处理器状态。因此单一线程可以执行单一时序任务对应的指令流。值得注意的是这种线程模型是不管并发线程是如何调动的,比如说,线程间是否调度合理(任何等待的线程是否最终得到执行)就是另外一回事。
众所周知,多线程,不管是软件级的还是硬件级的,提供了一种容许延迟的方案。如果指定线程因为等待某个指令(比如等待流水线指令单元完成、等待外部DRAM数据到达、或者其他事件)完成而被阻塞,那么支持多线程的系统允许另一个阻塞的线程执行。也就是说,单线程中长延时的操作可以被另一个位于就绪状态的线程隐藏或者覆盖。这里说的容许延迟,其中的处理器利用率并不会应为部分活动线程被阻塞而出现下降,这也是面向吞吐量处理器的一个标志。
硬件多线程作为一种提高并行工作负载上的集群性能的设计策略已经有很长的的一段历史。20世纪六十年代开发的数据控制公司CDC 6600 的外围处理器和 七十年代末开发异构元素处理器系统 28 都是著名的早期硬件多线程运用(实例)。这些年来已经有许多更加多线程化的处理器被设计出来 31;比如,Tera,Sun Niagara,以及 NVIDIA GPU22 架构都使用了集成多线程来实现并行工作负载的高吞吐性能,通过交错多线程。每一个线程都能够在每一个(线程)周期中的进行线程间切换。所以线程的的执行都交错在非常小的粒度上,通常是指令级别的。阻塞多线程是一种粗粒度的(允许)线程不中断地运行直到遇到一个长延迟的操作,即有另外的线程被选择执行的 策略。流处理器Imagine,Merrimac和SPI Storm 是有名的采用这种策略的面向吞吐架构的例子。这些机器明确地将程序分成整个数据块上的批量加载/存储操作和内存访问仅限于(代表相应任务)被加载的芯片(存储)块的 “内核”任务。当内核完成了对它的芯片上数据的处理的时候,另外的一个请求(那些)已经被加载到芯片上的内存块的任务就会被执行。对一个或多个任务进行重叠的批量数据传输隐藏了内存访问的延迟。内容交换发生的地方(即)内核边界 的战略地位也能大幅的减少 那些在任务执行期间必须被保留的状态数量。第三个策略称作同步多线程。它允许不同的线程同时注重于一个主题中各互相独立的功能单元的指令要求,以及在单线程情况下,不查找并行指令集的方式,达到提升超标量顺序处理器的工作效率。NVIDIA的Fermi架构明智地在内核线程技术上广泛采用了这种策略。
HEP,Tera以及NVIDIA G80处理器的设计显示了一个在一些面向吞吐量处理器上的重要特性:没有一款这样的处理器提供传统的缓存用来加载和存储在额外记忆体上的一系列操作,除非这些面向延迟的处理器(典型的如CPU)为传统的缓存子系统额外分配一个处理内核。这些机器之所以能够在缓存存在的情况下,达到高吞吐量的原因在于他们在假想存在大量的平行作业隐藏了片外存储器访问的延迟。与原来的NVIDIA处理器不同,虽然Fermi架构提供了缓存机制来应对超出内存容量的请求访问,然而它依旧依赖于针对延迟的上限而设立的额外的多线程。
大量简单处理单元。 当今半导体技术下晶体管比较高的集成密度使得一个单个的芯片就可以包含多个处理单元,因此就出现了为了达到最优的性能应该如何利用芯片上可用面积的问题:应该做成一个非常大的处理器、若干比较大处理器还是大量比较小的处理器?
设计越来越大的单处理器芯片缺乏吸引力。6 用于获得越来越高的标量性能(scalar performance, 比如乱序执行(out-of-order execution)以及激进型预测(aggressive speculation))的策略是以越来越高的功耗为代价的。15因此,尽管从物理上讲增加一个单线程核心的功耗是可行的,通过对比会发现更加激进型的预测在性能提升方面的潜力微不足道。这样分析下来,使得业界广泛转向了对多核芯片的研发,但他们的设计基本上仍然为面向时延的(latency-oriented)。同早期那一代单核芯片相比,每个核心基本上保持了大致相同的标量性能。
通过使用大量简单,也即比较小型的,处理核心,面向吞吐量的处理器(Throughput-oriented processor)甚至取得了更高水平的性能。10面向吞吐量的芯片中每个处理单元一般都是按照程序中指令的自然顺序进行执行,而不会尝试动态的重新调整执行的顺序进行乱序执行(out-of-order execution)。它们一般也避免进行预测型执行,不对程序的分支进行预测。这些在架构方面所作的简化往往会减慢单线程的执行速度。然而,简化所节约出来的芯片面积可用于集成更多的并行处理单元,所以在并行负载下却等获得更高的吞吐量。
SIMD执行 并行处理器经常利用某种形式的单指令流多数据流执行技术,也即SIMD执行技术,12来提高它们的吞吐总量。在一个SIMD机器中,发出一条指令就可以将运算施加于潜在的多个操作数;例如,一条SIMD加法指令就可以完成对两个具有64个元素的数据序列进行成对的相加运算。和单线程的情况一样,SIMD执行的很早就出现了,至少追溯到20世纪60年代。
强劲的吞吐量处理器,比如GPU,在所有线程中,他 会使用一个独立的线程来增加总吞吐量。大部分的SIMD机器都能分为两个基本类别。第一类是SIMD处理器阵列,典型是在伊利诺伊大学开发的ILLIAC IV ,Thinking Machines CM-229 ,以及 MasPar Computer Corp. MP-15 。一系列巨大的处理元素(成百上千)和一个单一的控制单元的所有组成都会消耗一个单一的指令流。控制单元会把每一个指令广播到所有的在随后会并行执行指令的处理元素。
第二个类型是向量处理器。Cray-125是其典型代表, 另外还包括许多其它的机器11。它们扩大了传统型的标量指令集,额外添加了一些对固定宽度的向量进行运算的向量指令。Cray-1的向量宽度为64,也即一个向量可以包含64个元素;而绝大多数当代的向量扩充单元(比如X86流式SIMD扩充单元,也即SSE)的向量宽度是4。向量指令,比如向量的加法,可以以管道式的风格来执行(比如Cray-1),也可以并行执行(比如当前的SSE实现)。 包括来自Intel和AMD的x86处理器以及ARM的Cortex-A系列处理器在内,现代的处理器几大家族提供的向量SIMD指令可以对128位(比如4个32位的整数)的值进行并行运算。可编程GPU长期以来一直都广泛应用了SIMD技术;NVIDIA现在的GPU的SIMD向量宽度为32。近来很多研究中的设计,包括19 SCALE、20、Imagine以及Merrimac流式处理器9,16也都采用了SIMD架构来提高效率。
SIMD执行技术很吸引人,其中有一个原因在于,这种技术增加了专用于功能单元可用的资源,而不是将大量资源用于控制逻辑。例如,32个浮点数运算单元同一个单个控制单元结合在芯片上所占的面积要比32个运算单元分别同32个控制单元所占的面积小。即使在最早期,追求将控制逻辑的代价分摊给无数个功能单元也是研发SIMD机器背后的一个关键动因。7
然而,让控制逻辑占用更少的地方也是有代价的。SIMD执行技术在并行任务都遵循相同的执行轨迹时能够获得最大的性能,但在不同性质的并行任务执行轨迹完全不同的情况下性能会有所下降。SIMD架构的效率有赖于具有一致性的任务总数是否能达到一定的值。实际上,在具有大量并行负载的情况下往往都会存在足够一致性的任务。因为10,000个并发任务中的任务类型数量比较小的可能性要远大于这10,000个任务的计算类型完全各不相同的可能性。
GPU(Graphics Processing Unit 图形处理单元)
可编程的GPU是强劲的以吞吐量为导向的处理器中的杰出典范,它对吞吐量的重视超出了其他绝大多数处理器,因此可编程GPU为大规模并发难题提供了巨大的潜在性能。13
从历史的角度来看,当今的GPU是根据实时计算机图形处理的需要而演变过来的。其中有两点是特别重要的,因为通过它们我们可以更好的了解GPU的设计发展:1.实时计算机图形处理是高度并发的问题;2.吞吐量是衡量GPU性能的最重要参数。
可视化应用程序通过一组几何基元来塑造它们的显示环境,其中三角形是最常见的基元。使用范围最广的用来生成图片的技术就是通过多个阶段处理这些基元,对这些基元的处理作用在每一个三角形,三角形角落(triangle corner )和被三角形覆盖的像素上。在每一个处理阶段,单独的三角形/顶点/像素可以被单独的处理而不影响其他个体。一个单独的场景可以很容易地在一个时间点内绘制出数以万计的像素点,从而产生大量的完全并发工作。此外,对一个元素的处理一般包含开启一个线程来执行开发者写的程序(该程序通常被成为 shader)。因此,GPU被特定地设计成可以在一秒内逐句执行数以亿计的用户写的小程序。大多数实时可视化程序被设计可以运行在一个每秒30-60帧的比率上。所以 在复杂的可视化世界中,人们希望一个图形系统可以在33毫秒的时间内完成图片的生成,渲染和显示。既然图形系统必须在这段时间间隔内完成许多数以万计的独立任务,那么完成其中 任何一个任务的时间就显得相对不那么重要了。但是,在33毫秒内处理完所有的工作量还是非常关键的,因为这个通常决定了要显示的环境视觉丰富度。它们在实时图形处理加速中所起的重要角色,使得GPU成为一种大量销售的设备。此外,和先前许多以吞吐量为导向的机器不同,它们的可获得性也更加宽广。自从2006年末以来,英伟达( NVIDIA)公司已经销售了几乎2亿2千万个支持CUDA(Compute Unified Device Architecture 计算统一设备架构)的GPU,比过去的那些大规模并行架构(如CM-2和MasPar机)多出了几个数量级。【*译者注:CM是Connection Machine的缩写,防止部分人上不了维基百科】英伟达(NVIDIA)GPU架构 从2006年末发布的G80处理器开始,所有新式的英伟达(NVIDIA)GPU都支持CUDA架构来进行并行计算。它们建立在多处理器阵列周围,简称流式多处理器( streaming multiprocessors)或者SM。22,24

图2. 包含了支持多线程的多处理器阵列的英伟达(NVIDIA)GPU
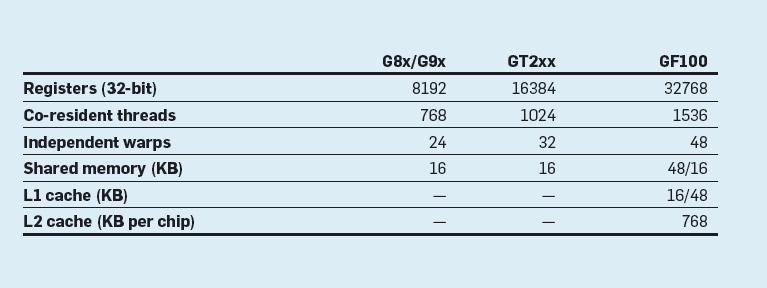
图2展示了一个具有代表性的费米(费米Fermi:长度单位,等于一毫微微米)技术的GPU,如Tesla C2050中的GF100处理器。每一个多处理器支持处理以千为数量级的共驻主存的线程,而且多处理器还被配备了一个很大的寄存器文件,这样就给了每个线程分配了专有的寄存器集合。所以一个有着多个SM的高端GPU可以同时支持数以万计的线程。多处理器包含许多标量处理部件,这些部件用来执行活动线程发出的指令。每个多处理器还包含高带宽,低延迟的芯片内部共享的内存,同时它还提供线程对芯片外部存储器的直接读写通道。费米架构可以将它每个SM的64K内存转化为16KB的L1缓存加48KB的RAM,或者48KB的L1缓存加16KB的RAM。它还提供了一个可以被所有SM共享的全局768KB的L2缓存。下表概括了三代英伟达(NVINDIA)支持CUDA的GPU中单个SM的容量。
SM多处理器负责处理所有线程的创建,资源的分配和在硬件中的调度,线程在指令级上近乎零开销的交叉执行。为所有活动线程分配专有的寄存器意味着在切换线程的时候没有状态来存储或恢复。将所有的线程管理操作放在硬件中,这样对多个线程的开销可以达到最低。比如,图3中Tesla C2050执行内核的increment()方法将在大约每秒130亿线程处理的速率上进行线程的创建,执行和退出。

图3. 普通的CUDA C内核中对每个数组元素的增加处理
为了有效管理大量的线程群,GPU采用单指令多线程或者叫做SIMT,在这种架构里,线程驻留在一个每组32个的单一的SM处理器里面执行,称之为wraps,每次在其所有线程执行一条指令。wraps是线程调度的基本单位,在任何给定的周期中,SM从任意可运行的wraps中自由的发布命令。一个warp块的线程可以自由按照自己的路径执行,所有这些执行差异由硬件程序自动处理。然而,对大多数计算,线程遵循相同的执行路径显然更高效。在没有惩罚措施的情况下,不同的wraps可以遵循不同的执行路径。SIMT架构与SIMD向量机有许多共同的性能特点,从程序员的角度来看,他们在性质上有所差异。向量机是典型的,以内部函数显式的对一些固定宽度的向量进行操作或编译器自动化量化的循环变量进行编程。相比之下,SIMT机编程时通过对单一线程行为编写一个标量程序描述。一个SIMT机 以SIMD方式隐式执行独立的标量线程组,而一个向量机显式地编码SIMD在执行过程中, 它被赋予在矢量操作中的 指令流。CUDA 编程模型。CUDA 编程模型23,26 提供了一种针对像 NVIDIA 的 GPU 一类的大量多线程架构的最简抽象。CUDA 程序由运行在宿主机处理器一个或多个线程,以及这些宿主机线程在并行设备上执行的一个或多个并行核组成。
单个内核通过一组并行线程执行一个标量顺序程序。编程人员安排内核线程到线程块,为每一个内核载入一定数量的块和为每个块的一定数目的线程被创建。CUDA内核与所熟悉的单个程序块具有相似的风格,多数据,或者SPMD,图表。然而,CUDA在某些方面比大多数SPMD系统更灵活, 因为主程序是可以自由定制一定数目的线程和特定内核每次调用装载的块。一个线程块是一组并行线程,该线程可以与在一个分块壁垒进行同步,同时每块通过互相通信进行共享内存。不同块的线程可以与通过对在对所有线程可见的全局内存空间的变量进行配合。有一个隐式的壁垒在由主机程序启动的连续依赖内核。NVIDIA CUDA Toolkit ( http://www.nvidia.com/cuda ) 包含了一个编写CUDA程序的语言扩展集合的C编译器。图3描述了一个简单的CUDA程序片段用图来解说这些扩展。_global_修饰符表明了increament()函数是一个内核的入口同时可以只能在运行内核的时候才被调用。那些没有修饰的或者由_host_显式修饰的是常见的C函数。主程序要运行内核则使用像syntax increment<<<B,T>>>(...)的函数调用,表明函数increment()会被在每个T线程的B块上并行运行。这些内核的块使用像特殊变量blockIdx.x和blockIdx.y这样的对内核可见的二维索引来数字化,范围分别是从0到gridDim.x-1和gridDim.y-1。同样的,块的线程使用三围的索引threadIdx.x,threadIdx.y,threadIx.z来数字化;每维度的块范围有blockDim.x,blockDim.y和blockDim.z来给定。并行函数_increment()接受一个有n个元素的数组,同时运行一个至少有每个元素有一个线程组织到256个线程的块里的并行内核。因为在例子里的数据是一维的,在图3的代码使用了一维索引。同样,因为在这个计算的每个线程是完全独立的,所以决定在我们的实现里每个块使用256个线程是很随意的。内核每个线程从它的本地threadIdx和它的块的blockIdx上计算一个全局的唯一索引i。如果i<n它为xi 的值加1——条件检查是需要的,因为n需要不需要是256的倍数。
面向吞吐量编程
可扩展性是编程人员在为以吞吐量为导向的机器设计有效算法时,重点关注的问题。如今的架构发展趋势明显有利于增大并行度,有效的算法技术必须对于硬件的并行度具有扩展性。某些技术适用于四个并行线程但并不适用于4000个并行线程。同时运行成千上万个线程,GPU是一个开发可扩展算法的强大平台,同时作为未来面向吞吐量架构算法设计方面的引领指标。
丰富的并行机制。以吞吐量为导向的课程必须公开大量的细粒度并行机制,亦满足体系架构的预期。开发多核CPU显然同样要求公开并行机制,但一个在面向吞吐量处理器并行机制方面的编程人员的心智模式与多核有本质上的区别。四核CPU能被4到8个线程充分利用。线程创建和调度是一种重量级运算,因为他们涉及到保存和恢复处理器状态,调用操作系统内核(的开销)是相当昂贵的。GPU通常会要求数以千计的线程以掩盖存储延迟并达到充分利用,而线程调度本质上是没有成本的。想想计算乘积 y=Ax;A是一个nxn的矩阵,x是一个n元向量。
对于稀疏问题,因为大部分矩阵元素为0,A是使用一个存储只有非0元素的数据结构的最好表示。为解决稀疏向量乘法(SpMV)如下所示:
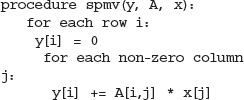
GPU(图形处理器)是专门设计用来执行每秒数十亿的小用户编写的程序。图4给出了三种不同并行粒度性能的实验测量:一个线程/行,32个线程/行,还有一个一个线程/非零 【3】。这些测试使用了一个固定数目的,通过一个可变行数的从左边一行4百万项到右边一项4百万行的合成矩阵。最大的并行性能出自于, 当行数不多的时候 , 每一个非零元素分配一个线程会产生最有效的实现 但有较低的绝对性能,因为它需要对线程间进行同步。对于中间的行数,每行分配32个线程是最好的解决方案,而当行数足够大的时候,每行分配一个线程是最佳的解决方案。 计算是廉价的。通常计算比转储所需开销少许多。尤其是外部转储,常常都需要好几百个周期才能完成。转储开销持续增加。和计算开销相比,这种开销又特别大。这一事实常被称作“内存墙”。芯片和外部DRAM间数据迁移比1个芯片功能组件执行所需的能量多许多。在45nm时代,1个64位整型加法单元消耗大约1pJ(微微焦耳),1个64位浮点混合乘加单元或者FMA单元消耗大约100pJ。相比之下,从外部DRAM读取一个64位的值,就要消耗2000 pJ。 8
延迟和吞吐量为导向的处理器访问存储器的相对成本较高,因为成本是半导体技术的物理属性的结果。然而,参考以吞吐量为导向的处理器的外部存储器的性能影响更为显著;这些存储器被设计成能达到更高的峰值计算吞吐量和可能比以延迟为导向的处理器有更高的峰值吞吐量带宽比。更重要的是,他们企图容忍而不是避免延迟。为了隐藏从主存频繁的数据输入输出的移动带来的延迟,亦或者是更多的线程或每个线程做更多的工作,通常要求采用大数据集。最佳性能的典型表现是当计算多于数据访问的时候。从内存中加载数据的每个字,执行大约10-20次操作是比较理想的,它可能最好是在本地重新计算的值,而不是存储在外部存储器中经常需要的值。举一个像计算sin θ中θ从0到256个不同的值,这样成本中等功能的简单例子。将256个可能的值列成表格,只需要很小的空间,但要从外存中访问他们则组要数以百计的循环周期。在相同的计数时间内,一个线程大概能执行50到100条指令就能得到结果,并为其他用途留下存储器带宽。
分而治之。即使是明显的串行问题,各个击破的方法往往产生有效的并行算法。考虑到合并两个排序序列A和B,对于大部分计算机科学专业的学生学习一类序列化的解决方案,会遇到像下面这样共同的问题:

与此相关的分而治之的算法,从A或者B中选取一个元素s,并分区到两个序列 A1,B1 和A2,B2, A1,B1小于s,A2,B2不小于s。将输入序列分隔开,合并后的序列再构建双递归就仅仅是Ai 与Bi合并的问题。实现该操作的代码如下:

由于A和B都被有条件的排序,此方法让人想起了快速排序算法。如果s取自A,"分区"A变得微不足道,因为元素小于的s仅仅是之前的s,通过二进制搜索,可以找到s分割B的对应的点。
这种分而治之的方法,通过从k分割成的元素序列s1, ..., sk中选取一组已排序的序列,将产生一种固定的并行算法。这些分隔器分区A和B都将独立的合并到k+1的子序列中,像下面的代码所示:

虽然每一个递归合并时独立的,这是一个固有的并行算法。这种形式的合并算法在并行编程文献中已经使用了数十年【14】,同时该算法还可以用于建立高效的支持CUDA技术的合并排序程序【27】。
Hierarchical synchronization(分层同步)。通常,在不同时间段,并行线程需要彼此同步,但是过度同步会降低并行程序的效率。对于那些面向吞吐量的,大规模并行的,存在成千上万个线程可能同时争夺同一把锁的处理器,同步必须要小心对待。
为了避免不必要的同步,尽可能久地保持并行计算独立性,线程应该分层同步。并行程序按层次分解,就像分治方法一样,线程同步也能够按层次管理。比如,当计算merge3(A,B)时,每个递归的并行合并步骤能够相互独立执行。这些子任务间的任何同步能够分发到它们当中。只有在最后,当所有这一连串的操作都合并了,并行的子任务才需要相互同步。分层管理同步也能很好地平衡遍布某个给定系统的不同部分间线程同步带来的物理成本。很自然地想到,执行在单核中的线程比那些遍布整个处理器中的线程同步更便宜,好比单个机器中的线程比集群中遍布多个节点间的线程同步更便宜。
结论
从单核到多核处理的转变以及越来越多的采用面向吞吐量的架构意味着要更加将并行着重作为追求更改的计算性能的驱动力。然而,这两种处理器在典型载荷下人们对它们的并行度的期待有所不同,面向吞吐量的处理器假设有大量而不是少量的的并行处理,它们最终的设计目标是将所有并行认为的总吞吐量最大化,而不是将单个连续任务的延迟将到最小。
强调总吞吐量而不是单个任务的运行实际会产生大量的价格设计决策。对于典型面向吞吐量的处理器,其中三种主要的架构趋势是硬件多线程化、多个简单处理元素以及SIMD执行。硬件多线程化使得把预期中的大量并行处理管理起来的价格低廉。简单的按次序执行的核心(in-order core)摒弃了无序执行与预测(out-of-order execution and spectulation),SIMD执行提高了功能单元同控制逻辑之比。简单的核心设计和SIMD执行减少了面积以及控制逻辑的能耗,从而可留给为并行功能单元更多的资源
这些设计决策都是在假定处理器预期要处理的载荷中存在大量的并发行为。因此,没有足够并发行为的程序执行起来效率就要打折扣了。完全通用型的芯片(如CPU)做不到积极地以损失单线程的性能减低的代价换取总性能的提升。呈现给这类芯片载荷的范围非常宽泛,而且也不是所有的计算都是并行的。对于大体上是按顺序进行的计算来讲,面向延迟的处理器( latency-oriented processor)的性能要优于面向吞吐量的处理器。反过来讲,专为并行计算设计的处理器能够接受这种折中方式,从而可以最终在并行问题处理方法获得巨大的总吞吐量。
因为这些架构之间的差异并非是一种临时性的表现而是永久性的,所以理想的系统是混合型的,在这种混合型系统里,面向延迟的处理器(比如CPU)和面向吞吐量的处理器(如GPU)是串联起来一起工作的,这样就能够处理呈现给它们的混合型载荷了。
参考文献
1. Alverson, G., Alverson, R., Callahan, D., Koblenz, B., Porterfield, A., and Smith, B. Exploiting heterogeneous parallelism on a multithreaded multiprocessor. In Proceedings of the Sixth international Conference on Supercomputing (Washington, D.C., July 19–24). ACM Press, New York, 1992, 188–197.
2. Alverson, R., Callahan, D., Cummings, D., Koblenz, B., Porterfield, A., and Smith, B. The Tera computer system. In Proceedings of the Fourth international Conference on Supercomputing (Amsterdam, The Netherlands, June 11–15). ACM Press, New York, 1990, 1–6
3. Bell, N. and Garland, M. Implementing sparse matrix-vector multiplication on throughput-oriented processors. In Proceedings of the Conference on High Performance Computing Networking, Storage and Analysis (Portland, OR, Nov. 14–20). ACM Press, New York, 2009, 1–11.
4. Birrell, A.D. An Introduction to Programming with Threads. Research Report 35. Digital Equipment Corp. Systems Research, Palo Alto, CA, 1989.
5. Blank, T. The MasPar MP-1 architecture. In Proceedings of Compcon (San Francisco, CA, Feb. 26–Mar. 2). IEEE Press, 1990, 20–24.
6. Borkar, S., Jouppi, N.P., and Stenstrom, P. Microprocessors in the era of terascale integration. In Proceedings of the Conference on Design, Automation and Test in Europe (Nice, France, Apr. 16–20). EDA Consortium, San Jose, CA, 2007, 237–242.
7. Bouknight, W.J., Denenberg, S.A., McIntyre, D.E., Randall, J.M., Sameh, A.H., and Slotnick, D.L. The Illiac IV system. Proceedings of the IEEE 60, 4 (Apr. 1972), 369–388.
8. Dally, W. Power efficient supercomputing. Presented at the Accelerator-based Computing and Manycore Workshop (Lawrence Berkeley National Laboratory, Berkeley, CA, Nov. 30–Dec. 2, 2009); http://www.lbl.gov/cs/html/Manycore_Workshop09/GPUMulticoreSLAC2009/dallyppt.pdf
9. Dally, W.J., Labonte, F., Das, A., Hanrahan, P., Ahn, J., Gummaraju, J., Erez, M., Jayasena, N., Buck, I., Knight, T. J., and Kapasi, U.J. Merrimac: Supercomputing with streams. In Proceedings of the 2003 ACM/IEEE Conference on Supercomputing (Nov. 15–21). IEEE Computer Society, Washington, D.C., 2003.
10. Davis, J.D., Laudon, J., and Olukotun, K. Maximizing CMP throughput with mediocre cores. In Proceedings of the 14th international Conference on Parallel Architectures and Compilation Techniques (Sept. 17–21). IEEE Computer Society, Washington, D.C., 2005, 51–62.
11. Espasa, R., Valero, M., and Smith, J.E. Vector architectures: Past, present and future. In Proceedings of the 12th international Conference on Supercomputing (Melbourne, Australia). ACM Press, New York, 1998, 425–432.
12. Flynn, M.J. Very high-speed computing systems. Proceedings of the IEEE 54, 12 (Dec. 1966), 1901–1909.
13. Garland, M., Grand, S.L., Nickolls, J., Anderson, J., Hardwick, J., Morton, S., Phillips, E., Zhang, Y., and Volkov, V. Parallel computing experiences with CUDA. IEEE Micro 28, 4 (July 2008), 13–27.
14. Gavril, F. Merging with parallel processors. Commun. ACM 18, 10 (Oct. 1975), 588–591.
15. Grochowski, E., Ronen, R., Shen, J., and Wang, H. Best of both latency and throughput. In Proceedings of the IEEE international Conference on Computer Design (Oct. 11–13). IEEE Computer Society, Washington, D.C., 2004, 236–243.
16. Kapasi, U., Dally, W.J., Rixner, S., Owens, J.D., and Khailany, B. The Imagine stream processor. In Proceedings of the 2002 IEEE International Conference on Computer Design (Sept. 16–18). IEEE Computer Society, Washington, D.C., 2002, 282–288.
17. Khailany, B.K., Williams, T., Lin, J., Long, E.P., Rygh, M., Tovey, D.W., and Dally, W.J. A programmable 512 GOPS stream processor for signal, image, and video processing. IEEE Journal of Solid-State Circuits 43, 1 (Jan. 2008), 202–213.
18. Kongetira, P., Aingaran, K., and Olukotun, K. Niagara: A 32-way multithreaded Sparc processor. IEEE Micro 25, 2 (Mar./Apr. 2005), 21–29.
19. Kozyrakis, C. and Patterson, D. Vector vs. superscalar and VLIW architectures for embedded multimedia benchmarks. In Proceedings of the 35th Annual ACM/IEEE International Symposium on Microarchitecture (Istanbul, Turkey, Nov. 18–22). IEEE Computer Society Press, Los Alamitos, CA, 2002, 283–293.
20. Krashinsky, R., Batten, C., Hampton, M., Gerding, S., Pharris, B., Casper, J., and Asanovic, K. The vector-thread architecture. SIGARCH Computer Architecture News 32, 2 (Mar. 2004), 52–63.
21. Laudon, J., Gupta, A., and Horowitz, M. Interleaving: A multithreading technique targeting multiprocessors and workstations. In Proceedings of the Sixth International Conference on Architectural Support For Programming Languages and Operating Systems (San Jose, CA, Oct. 5–7). ACM Press, New York, 1994, 308–318.
22. Lindholm, E., Nickolls, J., Oberman, S., and Montrym, J. NVIDIA Tesla: A unified graphics and computing architecture. IEEE Micro 28, 2 (Mar./Apr. 2008), 39–55.
23. Nickolls, J., Buck, I., Garland, M., and Skadron, K. Scalable parallel programming with CUDA. Queue 6, 2 (Mar./Apr. 2008), 40–53.
24. NVIDIA. NVIDIA's Next-Generation CUDA Compute Architecture: Fermi, Oct. 2009; http://www.nvidia.com/fermi
25. Russell, R.M. The Cray-1 computer system. Commun. ACM, 21, 1 (Jan. 1978), 63–72.
26. Sanders, J. and Kandrot, E. CUDA By Example: An Introduction to General-Purpose GPU Programming. Addison-Wesley, July 2010.
27. Satish, N., Harris, M., and Garland, M. Designing efficient sorting algorithms for manycore GPUs. In Proceedings of the 2009 IEEE international Symposium on Parallel & Distributed Processing (May 23–29). IEEE Computer Society, Washington, D.C., 2009, 1–10.
28. Smith, B.J. Architecture and applications of the HEP multiprocessor computer system. Proceedings of the International Society for Optical Engineering 298 (Aug. 1981), 241–248.
29. Tucker, L.W. and Robertson, G.G. Architecture and applications of the Connection Machine. Computer 21, 8 (Aug. 1988), 26–38.
30. Tullsen, D.M., Eggers, S.J., and Levy, H.M. Simultaneous multithreading: maximizing on-chip parallelism. In Proceedings of the 22nd Annual international Symposium on Computer Architecture (S. Margherita Ligure, Italy, June 22–24). ACM Press, New York, 1995, 392–403.
31. Ungerer, T., Robic, B., and Šilc, J. A survey of processors with explicit multithreading. ACM Computing Surveys 35, 1 (Mar. 2003), 29–63.
返回顶部
作者
Michael Garland (mgarland@nvidia.com) 一个在加利福尼亚州圣克拉拉的NVIDIA研究院的高级研究科学家。
David B. Kirk (dk@nvidia.com) 一个在加利福尼亚州圣克拉拉的NVIDIA研究院的研究员和前首席科学家















 149
149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









