







 RDD概论具体概念百度(以下总结):Spark中 RDD本身并不是数据,只是数据信息的集合。里面包含数据的分区信息;和获取数据的方式;Spark有很多类型的RDD;getPartitions只运行一次;compute每次有action算子的时候都会运行,一个partition一次。NewHadoopRDD根据id(rdd的id)生成一个Jobid 获取分区的方式,是根据inputFormatC
RDD概论具体概念百度(以下总结):Spark中 RDD本身并不是数据,只是数据信息的集合。里面包含数据的分区信息;和获取数据的方式;Spark有很多类型的RDD;getPartitions只运行一次;compute每次有action算子的时候都会运行,一个partition一次。NewHadoopRDD根据id(rdd的id)生成一个Jobid 获取分区的方式,是根据inputFormatC
个人GitHub地址 :https://github.com/LinMingQiang
RDD概论
具体概念百度(以下总结):
Spark中 RDD本身并不是数据,只是数据信息的集合。
getPartitions只运行一次;
compute每次有action算子的时候都会运行,一个partition一次。
NewHadoopRDD
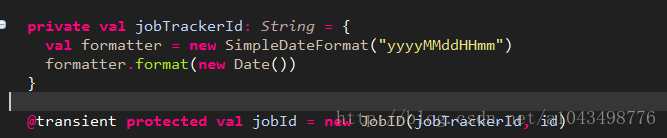
Jobid
Partition
获取分区的方式,是根据inputFormatClass的反射获取inputFormat类来获取分区,获取split信息,然后new几个NewHadoopPartition(个数等于分区数)。一般自定义的Partition都没什么东西,都是一些partition的信息(例如数据的开始结束offset,主要是在获取数据时提供信息)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 677
677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









