







目录
精准分片算法 PreciseShardingAlgorithm
主要概念介绍
垂直分表
基于列字段进行的
拆分原则一般是表中的字段较多,将不常用的或者数据较大,长度较长的拆分到“扩展表 如text类型字段
访问频次低、字段大的商品描述信息单独存放在一张表中,访问频次较高的商品基本信息单独放在一张表中
垂直分库
- 垂直分库针对的是一个系统中的不同业务进行拆分, 数据库的连接资源比较宝贵且单机处理能力也有限
- 没拆分之前全部都是落到单一的库上的,单库处理能力成为瓶颈,还有磁盘空间,内存,tps等限制
- 拆分之后,避免不同库竞争同一个物理机的CPU、内存、网络IO、磁盘,所以在高并发场景下,垂直分库一定程度上能够突破IO、连接数及单机硬件资源的瓶颈
- 垂直分库可以更好解决业务层面的耦合,业务清晰,且方便管理和维护
- 单体项目升级改造为微服务项目,就是垂直分库
水平分表
- 把一个表的数据分到一个数据库的多张表中,每个表只有这个表的部分数据
- 核心是把一个大表,分割N个小表,每个表的结构是一样的,数据不一样,全部表的数据合起来就是全部数据
- 针对数据量巨大的单张表(比如订单表),按照某种规则(RANGE,HASH取模等),切分到多张表里面去
- 但是这些表还是在同一个库中,所以单数据库操作还是有IO瓶颈,主要是解决单表数据量过大的问题
- 减少锁表时间,没分表前,如果是DDL(create/alter/add等)语句,当需要添加一列的时候mysql会锁表,期间所有的读写操作只能等待
水平分库
- 把同个表的数据按照一定规则分到不同的数据库中,数据库在不同的服务器上
- 水平分库是把不同表拆到不同数据库中,它是对数据行的拆分,不影响表结构
- 每个库的结构都一样,但每个库的数据都不一样,没有交集,所有库的并集就是全量数据
- 水平分库的粒度,比水平分表更大
分表规则有哪些?
-
垂直分表
垂直分表是根据字段来的,有以下几种划分规则
- 把不常用的字段单独放在一张表;
- 把text,blob等大字段拆分出来放在附表中;
- 业务经常组合查询的列放在一张表中
-
水平分表
方式一:range
根据自增ID范围进行分表
1~1000000 是表一
1000001~2000000 是表二
2000001~3000000 是表三
......
自增id分表优点:
- id是自增长,可以无限增长(面试会问自增id用完的问题,注意数字是没有上限的,有上限的是你设计的字段长度)
- 扩容不用迁移数据,容易理解和维护
自增id分表缺点:
- 大部分读和写都访会问新的数据,有IO瓶颈,整体资源利用率低
- 数据倾斜严重,热点数据过于集中,部分节点有瓶颈
自增id是范围的一种,还有哪些访问?
- 时间
t_order_2022_01
t_order_2022_02
t_order_2022_03
......
- 地理
t_order_北京
t_order_广州
t_order_上海
t_order_华东、华南、华北等
......
方式二:Hash取模
为什么不直接取模?如果取模的字段不是整数型要先hash
取模规则:
要求:用户ID是整数型的,要分2库,每个库中的表数量4张,一共8张表
库ID = userId % 库数量 2
表ID = userId / 库数量 2 % 表数量4
优点:
保证数据较均匀的分散落在不同的库、表中,可以有效的避免热点数据集中问题
缺点:
扩容(如果不是2个库,改成4个库了呢)不是很方便,需要数据迁移
分库分表中间件介绍
- Cobar 阿里的已经被淘汰
- TDDL 淘宝的 TDDL (Taobao Distributed Data Layer),主要淘宝内部使用,开源功能较少
- Mycat
- 前身是Cobar,Java语言编写的MySQL数据库网络协议的开源中间件
- 遵守Mysql原生协议,跨语言,跨平台,跨数据库的通用中间件代理
- 是基于 Proxy,它复写了 MySQL 协议,将 Mycat Server 伪装成一个 MySQL 数据库
- Sharding-JDBC
- Apache 开源项目 ShardingSphere 下的组成部分,基于jdbc驱动,不用额外的proxy,支持任意实现 JDBC 规范的数据库
- 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖
- 可理解为加强版的 JDBC 驱动,兼容 JDBC 和各类 ORM 框架
Mycat和Sharding-JDBC的区别
- 两者设计理念相同,主流程都是SQL解析-->SQL路由-->SQL改写-->结果归并
- sharding-jdbc
- 基于jdbc驱动,不用额外的proxy,在本地应用层重写Jdbc原生的方法,实现数据库分片形式
- 是基于 JDBC 接口的扩展,是以 jar 包的形式提供轻量级服务的,性能高
- 代码有侵入性
- Mycat
- 是基于 Proxy,它复写了 MySQL 协议,将 Mycat Server 伪装成一个 MySQL 数据库
- 客户端所有的jdbc请求都必须要先交给MyCat,再有MyCat转发到具体的真实服务器
- 缺点是效率偏低,中间包装了一层
- 代码无侵入性
分库分表相关术语名词介绍
数据节点Node
数据分片的最小单元,由数据源名称和数据表组成
比如:ds_0.t_order_0
真实表
在分片的数据库中真实存在的物理表
比如订单表 t_order_0、t_order_1、t_order_2
逻辑表
水平拆分的数据库(表)的相同逻辑和数据结构表的总称
比如订单表 t_order_0、t_order_1、t_order_2,逻辑表就是t_order
绑定表
指分片规则一致的主表和子表
比如t_order表和t_order_info表,均按照t_order_id分表,则此两张表互为绑定表关系
绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升
广播表
指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致
适用于数据量不大且需要与海量数据的表进行关联查询的场景
例如:字典表、配置表
分片算法有哪些?
数据库表分片(水平库、表)
包含分片键和分片策略
分片键 (PartitionKey)
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段
比如t_order订单表,根据订单号 out_trade_no做哈希取模,则out_trade_no是分片键
除了对单分片字段的支持,ShardingSphere也支持根据多个字段进行分片
分片策略
- 行表达式分片策略 InlineShardingStrategy(必备)
- 只支持【单分片键】使用Groovy的表达式,提供对SQL语句中的 =和IN 的分片操作支持
- 可以通过简单的配置使用,无需自定义分片算法,从而避免繁琐的Java代码开发
- t_order_$->{user_id % 8}` 表示订单表根据user_id模8,而分成8张表,表名称为`t_order_0`到`t_order_7
- 标准分片策略StandardShardingStrategy
- 只支持【单分片键】,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法
- PreciseShardingAlgorithm 精准分片 是必选的,用于处理=和IN的分片
- RangeShardingAlgorithm 范围分配 是可选的,用于处理BETWEEN AND分片
- 如果不配置RangeShardingAlgorithm,如果SQL中用了BETWEEN AND语法,则将按照全库路由处理,性能下降
- 复合分片策略ComplexShardingStrategy
- 支持【多分片键(t_order_0_0)】,多分片键之间的关系复杂,由开发者自己实现,提供最大的灵活度
- 提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持
- Hint分片策略HintShardingStrategy
- 这种分片策略无需配置分片健,分片健值也不再从 SQL中解析,外部手动指定分片健或分片库,让 SQL在指定的分库、分表中执行
- 用于处理使用Hint行分片的场景,通过Hint而非SQL解析的方式分片的策略
- Hint策略会绕过SQL解析的,对于这些比较复杂的需要分片的查询,Hint分片策略性能可能会更好
- sql可以到指定的库指定的表执行
- 不分片策略 NoneShardingStrategy
- 不分片的策略。
SpringBoot整合Sharding-JDBC
pom.xml中导入springding-jdbc的jar包
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>分库分表需求:2库2表
- shop_order_0 // 第一个库
- t_order_0
- t_order_1
- shop_order_1 // 第二个库
- t_order_0
- t_order_1
逻辑表名就叫做 t_order,真实表名叫做 t_order_0/1
代码中把实体类创建好,这里就不贴代码了(使用逻辑表t_order创建实体类)
springboot 的 application.properties 中配置 (水平分表)
### 打印执行的数据库以及语句
spring.shardingsphere.props.sql.show=true
### 指定数据预源 db0,有多个数据源使用英式逗号分隔 db0,db1,db2
spring.shardingsphere.datasource.names=ds0,ds1
### 配置第一个数据库连接信息
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://192.168.189.71:3306/shop_order_0?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=123456
### 配置第二个数据库连接信息
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://192.168.189.71:3306/shop_order_1?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=123456
### 指定 order 表的数据分布情况,配置数据节点,行表达式标识符使用 ${...} 或 $->{...},
# 但前者与 Spring 本身的文件占位符冲突,所以在 Spring 环境中建议使用 $->{...}
# t_order:这里写逻辑表名 在ds0数据库,分成 t_order_0、t_order_1 两张表
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds0.t_order_$->{0..1}
# 指定t_order表的分片策略,分片策略包括【分片键和分片算法】
# t_order:这里写逻辑表名 sharding-column:分片键 (就是使用哪个字段进行分片)
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=user_id
# t_order:这里写逻辑表名 algorithm-expression:分片算法
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order_$->{user_id % 2}写个单元测试看下结果
@RunWith(SpringRunner.class)
@SpringBootTest(classes = DemoApplication.class)
@Slf4j
public class DBTest {
@Autowired
private OrderMapper orderMapper;
@Test
public void testSaveOrder() {
for (int i = 0; i < 10; i++) {
OrderDO orderDO = new OrderDO();
orderDO.setCreateTime(new Date());
orderDO.setUserId((long) i);
orderMapper.insert(orderDO);
}
}
}可以看到结果就按照 user_id % 2 的方式插入2张表中(注意主键生成策略不要使用自增长)
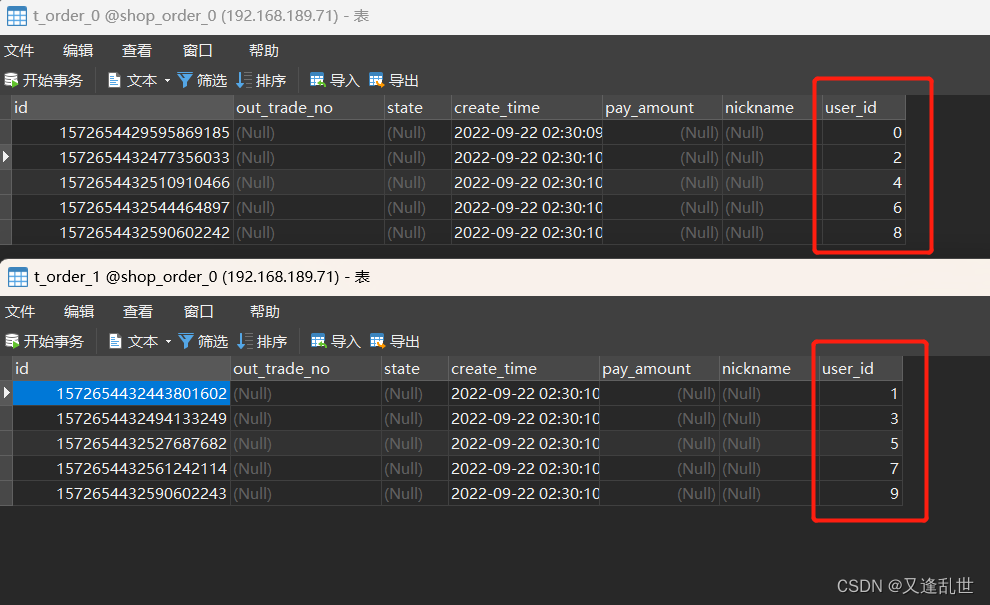
如何配置广播表?
application.properties 中配置
# 配置广播表, t_config 是表名,有多个广播表使用英式逗号分隔
spring.shardingsphere.sharding.broadcast-tables=t_config写个单元测试看下结果
@RunWith(SpringRunner.class)
@SpringBootTest(classes = DemoApplication.class)
@Slf4j
public class DBTest {
@Autowired
private ConfigMapper configMapper;
@Test
public void testSaveConfig() {
ConfigDO configDO = new ConfigDO();
configDO.setConfigKey("xxxKey");
configDO.setConfigValue("xxxVlue");
configDO.setType("xxxType");
configMapper.insert(configDO);
}
}可以看到多个库中的配置表插入了相同的数据
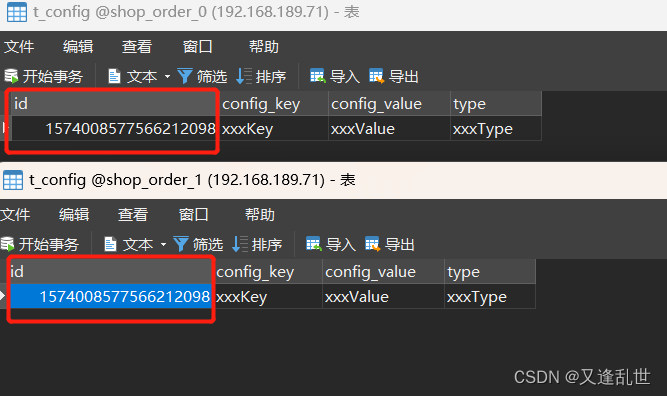
如何配置水平分库、水平分表?
分库规则:根据 user_id 进行分库 (user_id % 库数量)
分表规则:根据 t_order_id 订单号进行分表 (order_id / 库数量 % 表数量)
准备好表
- shop_order_0 // 第一个库
- t_order_0
- t_order_1
- shop_order_1 // 第二个库
- t_order_0
- t_order_1
application.properties 中配置
### 指定数据预源,有多个数据源使用英式逗号分隔 db0,db1,db2
spring.shardingsphere.datasource.names=ds0,ds1
### 配置第一个数据库连接信息
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://192.168.189.71:3306/shop_order_0?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=123456
### 配置第二个数据库连接信息
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://192.168.189.71:3306/shop_order_1?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=123456
### 指定 t_order 表的数据分布情况,配置数据节点,行表达式标识符使用 ${...} 或 $->{...},
# 但前者与 Spring 本身的文件占位符冲突,所以在 Spring 环境中建议使用 $->{...}
# t_order:这里写逻辑表名 在ds0数据库,分成 t_order_0、t_order_1 两张表
#spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds0.t_order_$->{0..1}
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order_$->{0..1}
### 配置默认分库规则,如果有很多表需要分库的话,就可以使用默认的
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{user_id % 2}
### 配置t_order表的分库规则
# t_order 是表名 sharding-column:指定分库使用t_order表的哪个字段,algorithm-expression:指定分片算法
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.algorithm-expression=ds$->{user_id % 2}
#### 配置t_order表的分表规则【分片键和分片算法】
# t_order:这里写逻辑表名 sharding-column:分片键 (就是使用t_order表的哪个字段进行分表)
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=id
# t_order:这里写逻辑表名 algorithm-expression:分片算法
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order_$->{id % 2}写个单元测试看下结果
@RunWith(SpringRunner.class)
@SpringBootTest(classes = DemoApplication.class)
public class DBTest {
@Autowired
private OrderMapper orderMapper;
@Test
public void testSaveOrder2() {
for (int i = 0; i < 10; i++) {
OrderDO orderDO = new OrderDO();
orderDO.setCreateTime(new Date());
orderDO.setUserId(IdWorker.getId());
orderMapper.insert(orderDO);
}
}
}可以看到2个库中的表中都插入了数据
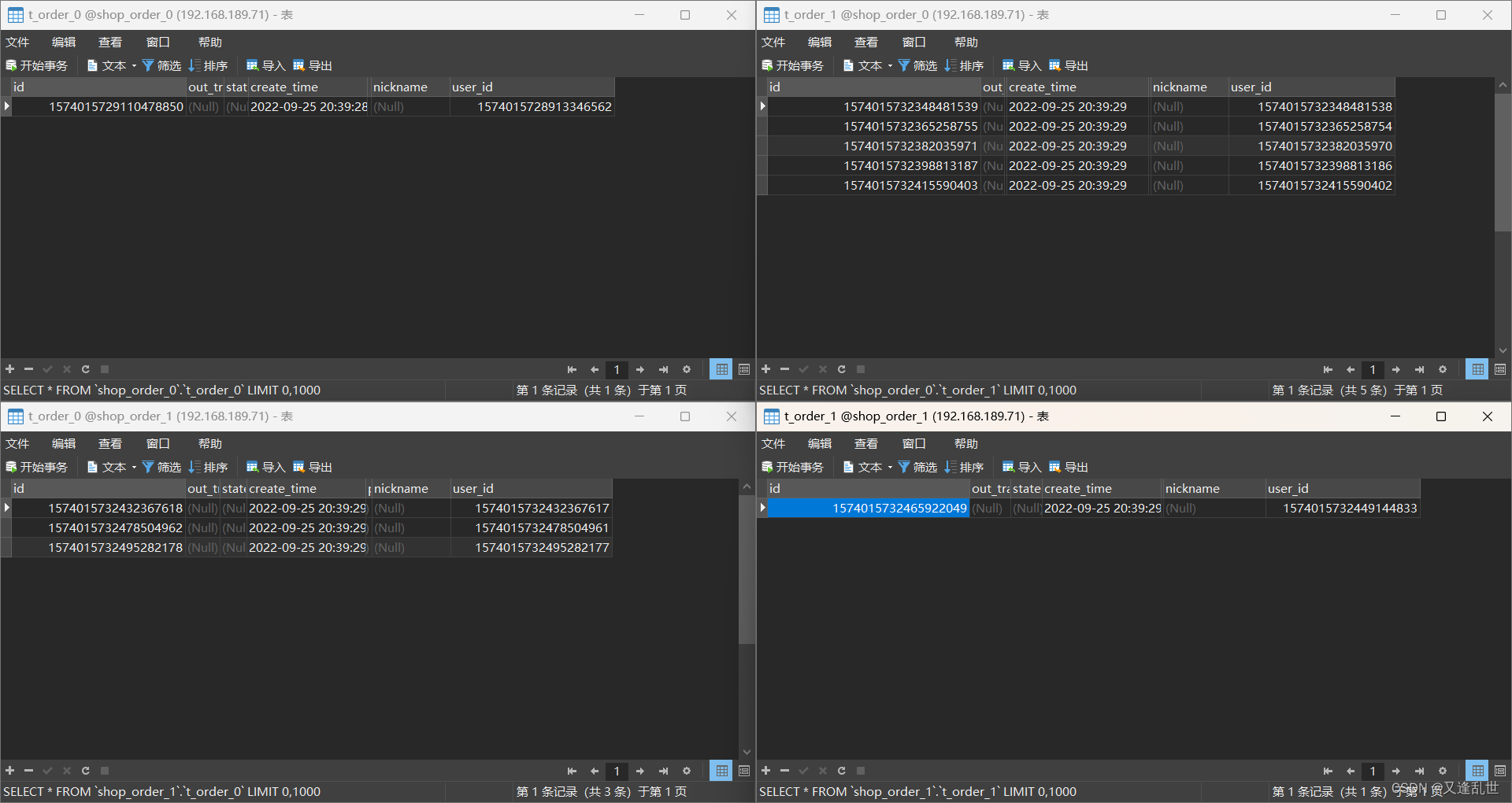
如何配置绑定表?
假如订单表 t_order 有订单详情表 t_order_info,外键关联字段是 order_id 字段。
如果要进行关联查询,未分表的情况下是这样的
select * from t_order o left join t_order_info i on o.id = i.order_id // 真实查询请勿使用 * 号
在分库分表的情况下,没有配置绑定表,会出现笛卡尔积查询
准备表
- shop_order_0 // 第一个库
- t_order_0
- t_order_1
- t_order_info_0
- t_order_info_1
- shop_order_1 // 第二个库
- t_order_0
- t_order_1
- t_order_info_0
- t_order_info_1
application.properties 中配置
### 配置 t_order_info 表的 分表规则
spring.shardingsphere.sharding.tables.t_order_info.actual-data-nodes=ds$->{0..1}.t_order_info_$->{0..1}
spring.shardingsphere.sharding.tables.t_order_info.table-strategy.inline.sharding-column=order_id
spring.shardingsphere.sharding.tables.t_order_info.table-strategy.inline.algorithm-expression=t_order_info_$->{order_id % 2}
### 配置绑定表
spring.shardingsphere.sharding.binding-tables[0]=t_order,t_order_info写个单元测试看下结果
@RunWith(SpringRunner.class)
@SpringBootTest(classes = DemoApplication.class)
public class DBTest {
@Autowired
private OrderMapper orderMapper;
@Test
public void testBinding () {
// sql 语句执行的是 @Select("select * from t_order o left join t_order_info i on o.id = i.order_id")
orderMapper.selectOrderInfoList();
}
}未配置绑定表之前的查询效果
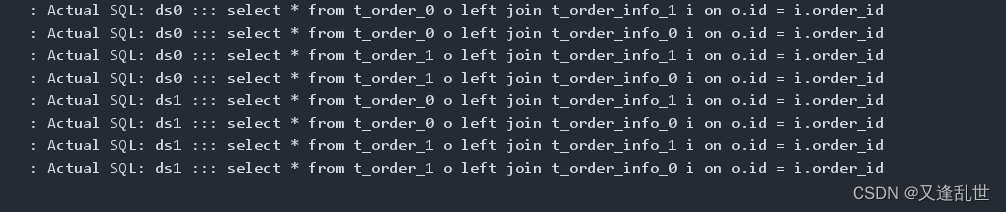
配置绑定表后的查询效果

精准分片算法 PreciseShardingAlgorithm
自定义类实现PreciseShardingAlgorithm重写doSharding方法
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.util.Collection;
public class CustomDBPreciseShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
/**
* @param dataSourceNames 数据源集合
* 在分库时值为所有分片库的集合 databaseNames
* 分表时为对应分片库中所有分片表的集合 tablesNames
* @param preciseShardingValue 分片属性,包括
* logicTableName 为逻辑表,
* columnName 分片健(字段),
* value 为从 SQL 中解析出的分片健的值
*/
@Override
public String doSharding(Collection<String> dataSourceNames, PreciseShardingValue<Long> preciseShardingValue) {
for (String datasourceName : dataSourceNames) {
String value = preciseShardingValue.getValue() % dataSourceNames.size() + "";
if (datasourceName.endsWith(value)) {
return datasourceName;
}
}
return null;
}
}public class CustomTablePreciseShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
/**
* @param dataSourceNames 数据源集合
* 在分库时值为所有分片库的集合 databaseNames
* 分表时为对应分片库中所有分片表的集合 tablesNames
* @param preciseShardingValue 分片属性,包括
* logicTableName 为逻辑表,
* columnName 分片健(字段),
* value 为从 SQL 中解析出的分片健的值
*/
@Override
public String doSharding(Collection<String> dataSourceNames, PreciseShardingValue<Long> preciseShardingValue) {
for (String datasourceName : dataSourceNames) {
String value = preciseShardingValue.getValue() % dataSourceNames.size() + "";
if (datasourceName.endsWith(value)) {
return datasourceName;
}
}
return null;
}
}application.properties 中配置
#精准分片
# 指定t_order表的数据分布情况,配置数据节点,在 Spring 环境中建议使用 $->{...}
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order_$->{0..1}
#指定精准分片算法-水平分库
spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.sharding-column=user_id
spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.precise-algorithm-class-name=com.demo.strategy.CustomDBPreciseShardingAlgorithm
#指定精准分片算法-水平分表
spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.sharding-column=id
spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.precise-algorithm-class-name=com.demo.strategy.CustomTablePreciseShardingAlgorithm写个单元测试看下结果
@RunWith(SpringRunner.class)
@SpringBootTest(classes = DemoApplication.class)
public class DBTest {
@Autowired
private OrderMapper orderMapper;
@Test
public void testSaveOrder2() {
for (int i = 0; i < 10; i++) {
OrderDO orderDO = new OrderDO();
orderDO.setCreateTime(new Date());
orderDO.setUserId(IdWorker.getId());
orderMapper.insert(orderDO);
}
}
}范围分片算法 RangeShardingAlgorithm
自定义类实现RangeShardingAlgorithm重写doSharding方法
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;
import java.util.Collection;
import java.util.LinkedHashSet;
import java.util.Set;
public class CustomRangeShardingAlgorithm implements RangeShardingAlgorithm<Long> {
/**
* @param dataSourceNames 数据源集合
* 在分库时值为所有分片库的集合 databaseNames
* 分表时为对应分片库中所有分片表的集合 tablesNames
* @param shardingValue 分片属性,包括
* logicTableName 为逻辑表,
* columnName 分片健(字段),
* value 为从 SQL 中解析出的分片健的值
*/
@Override
public Collection<String> doSharding(Collection<String> dataSourceNames, RangeShardingValue<Long> shardingValue) {
Set<String> result = new LinkedHashSet<>();
//between 开始值
Long lower = shardingValue.getValueRange().lowerEndpoint();
//between 结束值
Long upper = shardingValue.getValueRange().upperEndpoint();
for (long i = lower; i <= upper; i++) {
for (String datasource : dataSourceNames) {
String value = i % dataSourceNames.size() + "";
if (datasource.endsWith(value)) {
result.add(datasource);
}
}
}
return result;
}
}application.properties 中配置
#范围分片(水平分表)
spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.range-algorithm-class-name=com.demo.strategy.CustomRangeShardingAlgorithm写个单元测试
@RunWith(SpringRunner.class)
@SpringBootTest(classes = DemoApplication.class)
public class DBTest {
@Autowired
private OrderMapper orderMapper;
@Test
public void testBetween() {
orderMapper.selectList(new QueryWrapper<OrderDO>().between("id", 1L, 10L));
}
}Hint分片策略 HintShardingStrategy
自定义类实现接口HintShardingAlgorithm重写doSharding方法
import org.apache.shardingsphere.api.sharding.hint.HintShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.hint.HintShardingValue;
import java.util.ArrayList;
import java.util.Collection;
public class CustomDBHintShardingAlgorithm implements HintShardingAlgorithm<Long> {
/**
* @param dataSourceNames 数据源集合
* 在分库时值为所有分片库的集合 databaseNames
* 分表时为对应分片库中所有分片表的集合 tablesNames
* @param hintShardingValue 分片属性,包括
* logicTableName 为逻辑表,
* columnName 分片健(字段),hit策略此处为空 ""
* <p>
* value 【之前】都是 从 SQL 中解析出的分片健的值,用于取模判断
* HintShardingAlgorithm不再从SQL 解析中获取值,而是直接通过
* hintManager.addTableShardingValue("t_order", 1)参数进行指定
*/
@Override
public Collection<String> doSharding(Collection<String> dataSourceNames, HintShardingValue<Long> hintShardingValue) {
Collection<String> result = new ArrayList<>();
for (String datasourceName : dataSourceNames) {
for (Long shardingValue : hintShardingValue.getValues()) {
String value = shardingValue % dataSourceNames.size() + "";
if (datasourceName.endsWith(value)) {
result.add(datasourceName);
}
}
}
return result;
}
}import org.apache.shardingsphere.api.sharding.hint.HintShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.hint.HintShardingValue;
import java.util.ArrayList;
import java.util.Collection;
public class CustomTableHintShardingAlgorithm implements HintShardingAlgorithm<Long> {
/**
* @param dataSourceNames 数据源集合
* 在分库时值为所有分片库的集合 databaseNames
* 分表时为对应分片库中所有分片表的集合 tablesNames
* @param hintShardingValue 分片属性,包括
* logicTableName 为逻辑表,
* columnName 分片健(字段),hit策略此处为空 ""
* <p>
* value 【之前】都是 从 SQL 中解析出的分片健的值,用于取模判断
* HintShardingAlgorithm不再从SQL 解析中获取值,而是直接通过
* hintManager.addTableShardingValue("t_order", 1)参数进行指定
*/
@Override
public Collection<String> doSharding(Collection<String> dataSourceNames, HintShardingValue<Long> hintShardingValue) {
Collection<String> result = new ArrayList<>();
for (String datasourceName : dataSourceNames) {
for (Long shardingValue : hintShardingValue.getValues()) {
String value = shardingValue % dataSourceNames.size() + "";
if (datasourceName.endsWith(value)) {
result.add(datasourceName);
}
}
}
return result;
}
}application.properties 中配置
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order_$->{0..1}
spring.shardingsphere.sharding.tables.t_order.database-strategy.hint.algorithm-class-name=com.demo.strategy.CustomDBHintShardingAlgorithm
spring.shardingsphere.sharding.tables.t_order.table-strategy.hint.algorithm-class-name=com.demo.strategy.CustomTableHintShardingAlgorithm写个单元测试
@RunWith(SpringRunner.class)
@SpringBootTest(classes = DemoApplication.class)
public class DBTest {
@Autowired
private OrderMapper orderMapper;
@Test
public void testHit() {
//清除历史规则
HintManager.clear();
//获取对应的实例
HintManager hintManager = HintManager.getInstance();
//设置库的分片键值,value是用于库分片取模,参数一:指定逻辑表,参数二:指定的库
hintManager.addDatabaseShardingValue("t_order", 0L);
//设置表的分片键值,value是用于表分片取模,参数一:指定逻辑表,参数二:指定的表
hintManager.addTableShardingValue("t_order", 1L);
//如果在读写分离数据库中,Hint 可以强制读主库(主从复制存在一定延时,但在业务场景中,可能更需要保证数据的实时性)
//hintManager.setMasterRouteOnly();
//对应的value,只做查询,不做sql解析
orderMapper.selectList(new QueryWrapper<OrderDO>().eq("id", 1L));
}
}可以看到 单元测试指定的哪个库哪个表,执行的sql就找到指定的库指定表进行查询

分库分表带来的问题及解决办法
问题一
分库后,数据分布再不同的节点上,跨节点多库进行查询时,会出现limit分页、order by排序等问题。而且当排序字段非分片字段时,更加复杂了,要在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序(也会带来更多的CPU/IO资源损耗)
解决办法
业务上要设计合理,利用好分片键PartitionKey,查询的数据分布同个数据节点上,避免跨节点多库进行查询。sharding-jdbc在结果合并层自动帮我们解决很多问题(流式归并和内存归并)
问题二
数据库id主键重复问题
解决办法
UUID
redis发号器
雪花算法
问题三
跨节点数据库Join关联和多维度查询
- 数据库切分前,多表关联查询,可以通过sql join进行实现
- 分库分表后,数据可能分布在不同的节点上,sql join带来的问题就比较麻烦,不同维度查看数据,利用的partitionKey是不一样的
解决办法
- 冗余字段
- 比如订单显示的时候需要用户的基本信息,但是订单和用户分布在不同的库上,就可以在订单表中冗余用户昵称头像等字段
- 广播表
- NOSQL汇总
- 用户要查看自己的订单,库是根据用户id分的,那么查询在一个库上很方便
- 商家要查看店铺的订单,商家没有用户id,数据分布在不同的库上,这时查询就很麻烦。解决方法:可以使用nosql大表汇总,实操:使用canal-server监听数据库数据变更(相当于从库从主库中复制数据),监听的数据写到消息队列中,这里的消息队列用于数据缓冲流量削峰,ElasticSearch监听消息队列,把数据从队列中写到ElasticSearch中,商户查询就从ElasticSearch中查询(平常我们使用淘宝京东购物的时候,搜索商品信息,就是从ElasticSearch中搜索出的数据)
问题四
分布式事务问题
解决办法
常见分布式事务解决方案
- 2PC 和 3PC
- 两阶段提交, 基于XA协议
- TCC
- Try、Confirm、Cancel
- 事务消息
- 最大努力通知型
分布式事务框架
- TX-LCN:支持2PC、TCC等多种模式(停止维护了)。https://github.com/codingapi/tx-lcn
- Seata:阿里的。支持 AT、TCC、SAGA 和 XA 多种模式。https://github.com/seata/seata
- RocketMq:自带事务消息解决分布式事务。https://github.com/apache/rocketmq
- 最终一致性:Mq延迟任务+数据信息状态表
问题五
数据库二次扩容问题
业务发展快,初次分库分表后,满足不了数据存储,导致需要多次扩容,数据迁移问题
解决办法
- 时间规则分库分表的,没有二次扩容问题
- 区域规则分库分表的,全量迁移数据
- hash取模:
- 成倍扩容,例如2、4、6、8。扩容后需要迁移部分数据。例如2个库的时候,1%2=1,2%2=0,3%2=1,4%2=0,可以看到1、3数据在1库,2、4数据在0库,扩容成4个库的时候,1%4=1,2%4=2,3%4=3,4%4=0,那么数据2就要迁移到第二库,数据3就要迁移到第三个库。1、4数据不用迁移,这样就迁移了部分数据,关于数据迁移解决方案,可以网上搜索其他的博客 数据迁移方案
- 虚拟节点,从设计分库分表之初,多设计些库表,不要只使用2库2表,减少扩容的数据迁移
Sharding-jdbc 读写分离配置
准备2台配置好主从复制的数据库,主从复制配置教程 请查看
pom.xml中导入springding-jdbc的jar包
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>application.yml中配置
spring:
shardingsphere:
props:
# 展示修改以后的sql语句
sql-show: true
datasource:
names: m1,s1
m1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://主库ip:3306/test_db?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: root
password: 123456
s1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://从库ip:3306/test_db?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: root
password: 123456
sharding:
master-slave-rules:
ds0:
master-data-source-name: m1
slave-data-source-names: s1写个 测试类,看下效果
@RunWith(SpringRunner.class)
@SpringBootTest(classes = ShardingDemoApplication.class)
public class UserTest {
@Autowired
private UserMapper userMapper;
/**
* 更新语句(insert、update、delete),走主库
*/
@Test
public void testSave() {
UserDB userDB = new UserDB();
userDB.setUsername("张三");
userMapper.insert(userDB);
}
/**
* 查询语句(select),走从库
*/
@Test
public void testSelect() {
// 在主从复制有延迟的情况下,业务又需要里面查询到数据,可以使用 setMasterRouteOnly() 方法,让查询语句走主库
/*HintManager hintManager = HintManager.getInstance();
hintManager.setMasterRouteOnly();*/
userMapper.selectById(1L);
}
}集成sharding-jdbc过程中遇到的坑
1:如果使用了druid数据源,要使用druid,不要使用druid-spring-boot-starter,不然会报错Property 'sqlSessionFactory' or 'sqlSessionTemplate' are required
<!-- druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
</dependency>
<!-- shardingsphere -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
</dependency>
2:使用 mybatis 和 sharding-jdbc 在子查询的时候,有sharding-jdbc在解析不到数据的时候,会报NullPointerException,或者 java.lang.IllegalStateException: Can not find owner from table
这个问题将在sharding-jdbc的5.x版本中解决,请参考:
Abount Exception [Can not find owner from table.] · Issue #4810 · apache/shardingsphere · GitHub

















 2452
2452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











