







二、搜索相关性
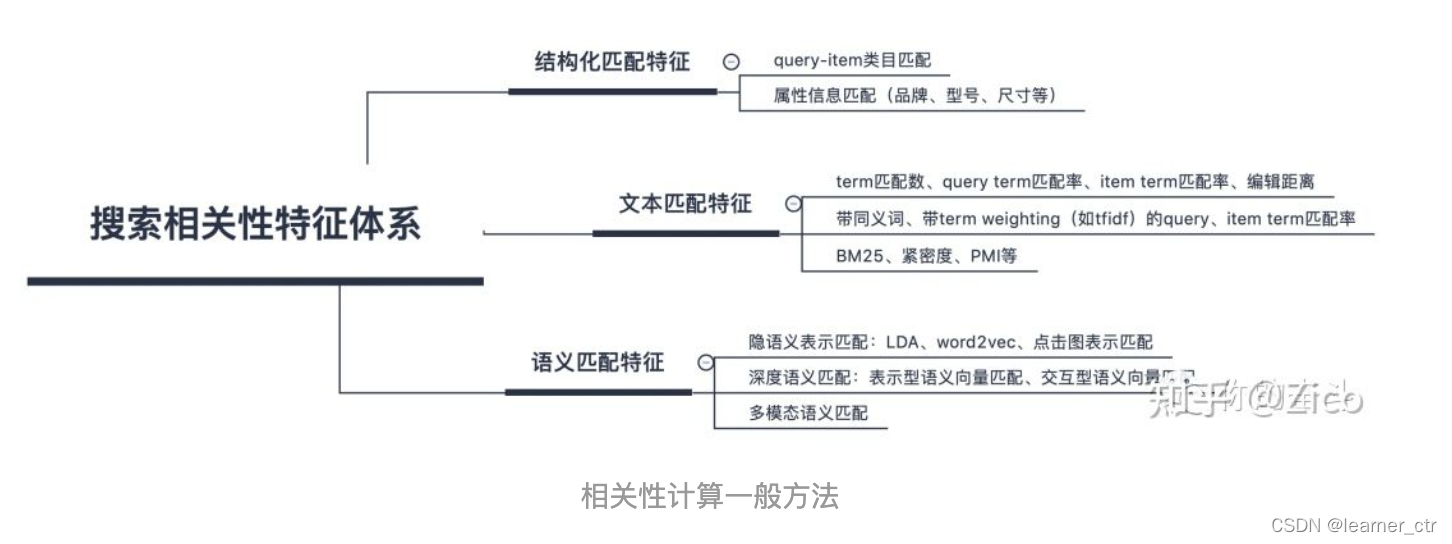
上面这篇文章中说的很好,把相关性从简到易分到3种(结构化匹配、文本匹配、语义匹配)
I:召回、粗排中用到结构化匹配的方式来控制相关性(query的类目是分类模型,有论文针对长尾query来优化类目,这说明query类目预测这里也很重要;item的类目依靠直播间、运营团队的标签)
II:文本匹配特征,这个层次中,有些比较复杂,有些比较简单,可以根据复杂程度动态决定是放在召回、粗排层,还是放在精排、重排层
1:query和item的各个term往往重要程度不同,在得到各个term的weighting之后,可以计算带weighting的query term匹配率和item term匹配率,比如tf-idf得到query和item的向量,然后求余弦相似度
2:考虑了term权重和文档长度的BM25、考虑了term共现信息的紧密度和点互信息(PMI)特征。

III:语义匹配,这个一般用在精排、重排会多一些,因为计算的是query和item在语义上的相关性,而不是前面那种文字层面,更符合直播场景的个性化搜索要求,提供给用户真正有相关性的item
1:dssm做相关性,dssm一般有3种,还有两种变形cnn-dssm,lstm-dssm DSSM、CNN-DSSM、LSTM-DSSM等深度学习模型在计算语义相似度上的应用+距离运算_古月哲亭-CSDN博客_lstm语义相似度
(1) dssm
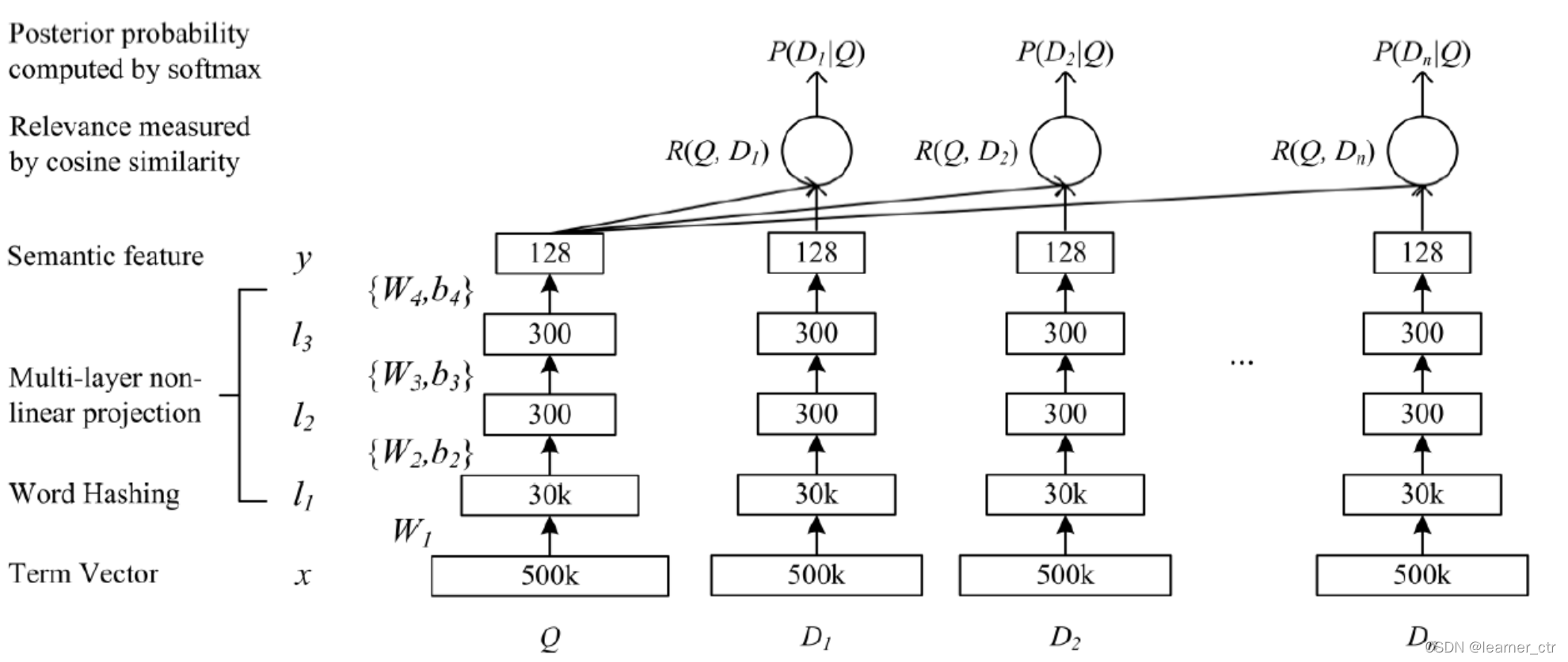
有几个重要的点 - 优缺点
1) 优点:英文的输入层处理方式是通过word hashing。举个例子,假设用 letter-trigams 来切分单词(3 个字母为一组,#表示开始和结束符),boy 这个单词会被切为 #-b-o, b-o-y, o-y-#。这样将编码空间从50万->3万,而且冲突也不是很大。这样还可以增加泛化能力
Word2Vec 和 LDA 都是无监督的训练,dssm相比这些精度更高
2) tanh 作为隐层和输出层的激活函数;cos相似度作为相关性标准,极大似然估计优化损失函数,随机梯度下降收敛模型
3) 缺点:上文提到 DSSM 采用词袋模型(BOW),因此丧失了语序信息和上下文信息。另一方面,DSSM 采用弱监督、端到端的模型,预测结果不可控
(2) cnn-dssm
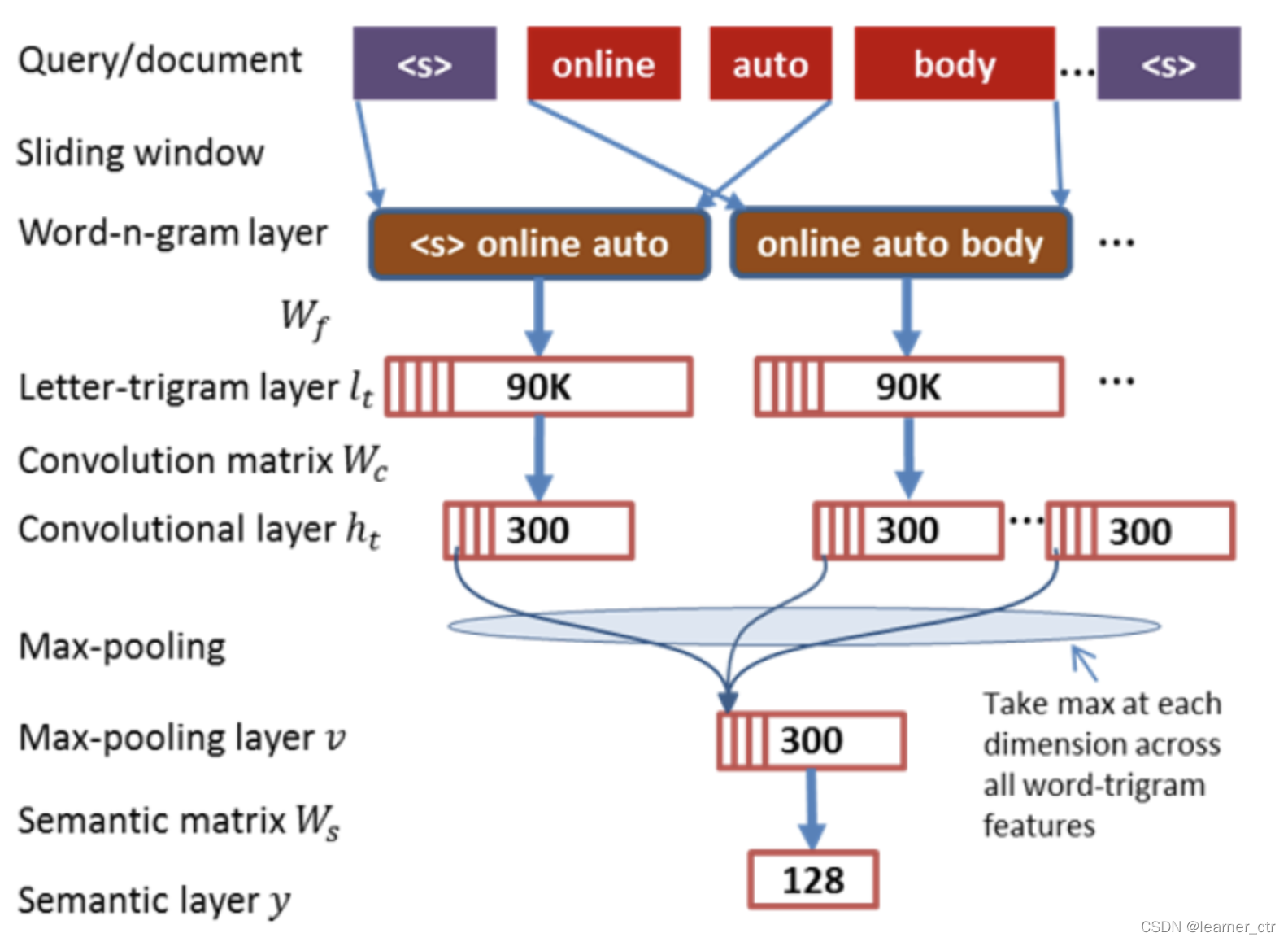 对于一个N个单词的query/doc,滑动窗口方式每次提取3个单词,每个单词都像dssm那样映射到3万维的向量,然后concat,形成9万维的向量。再然后是cnn特征提取到300的长度
对于一个N个单词的query/doc,滑动窗口方式每次提取3个单词,每个单词都像dssm那样映射到3万维的向量,然后concat,形成9万维的向量。再然后是cnn特征提取到300的长度
 然后池化层的输出为各个 Feature Map 的最大值(max_pooling layer),即一个 300
然后池化层的输出为各个 Feature Map 的最大值(max_pooling layer),即一个 300*1 的向量
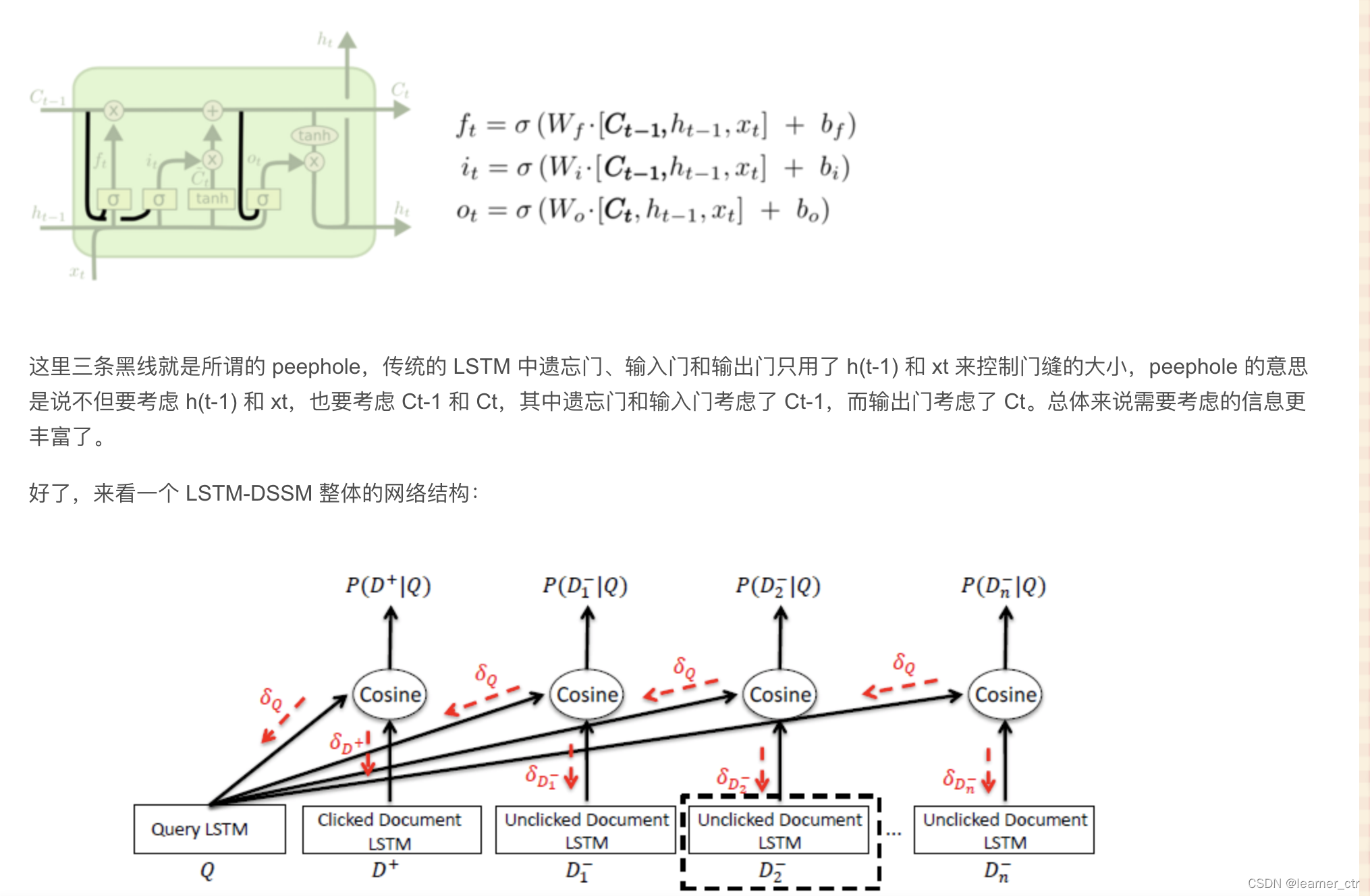
 (3) lstm-dssm
(3) lstm-dssm
2:bert做相关性,基本思路和前一篇召回文章里面的相似(直播推荐、搜索中的召回、相关性、多目标精排 - 召回篇_1066196847的博客-CSDN博客)这篇文章里面的想法(比如用交互式进行蒸馏、半交互式PolyEncoder)也在最上面“电商搜索”上得到了体现


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









