







总述:首先冷启动分为3种,用户冷启动、item冷启动、query冷启动(在搜索中常常称为长尾query)。这里有一个专业名词 Exploration and Exploitation 探索和开发。推荐中的长尾指长尾用户、长尾item,搜索中的长尾指长尾用户、长尾item、长尾query
在淘宝一篇文章(商品序列建模在新用户承接上的应用实践)中看到过对冷启动的解决办法分成了3类
1:充分利用跨域的信息,把新用户或冷启物品其他领域内的信息充分挖掘迁移打通到待推荐的内容领域
2:探索方法,新用户或新物品到来的时候,先给他一定的流量进行探索,然后逐步感知真实的分布
3:建模的思路
(1) 通过DropoutNet来缓解对冷启ID embedding的依赖,更多通过其内容属性来进行推荐,如Meta Warm Up Framework(MWUF)通过拉伸函数将冷启ID embedding与非冷启动ID embedding空间打通,实现了“冷热转换”,用热的带动冷的学习
(2) Meta learning的思想对冷启ID结合其他信息生成一个embedding,模拟冷启动的过程
(3) 强化学习思路
====================item冷启动======================================
这里面 item冷启动是最常见的,先聊聊这种的常见做法。item冷启动在召回、粗排、精排三个阶段的作用、做法都是不一样的,下面针对这3个阶段来说下
对item冷启动来说,一般要面临3个问题,每个item保量多少、保量时间区间、保量给谁,item冷启是一个双向行为,做的不好就会对系统有损(收入、创作者),做的好就能使用新item给用户带来更好的体验。难点在于:有限的冷启动流量,难以满足,新发内容的快速透出和潜在优质内容的快速成长诉求
这里有小红书的一些关于item冷启的基础知识:ShusenWang的个人空间_哔哩哔哩_Bilibili
冷启动的目标:用户侧~精准推荐、作者侧~激励发布、内容侧~挖掘高潜
冷启动的评价(AB测试):
用户侧~新item的ctr 交互率等,大盘的消费时长等(用户不能方案)
作者侧~人均发布量(当天新item/日活人数) 发布渗透率(当日发布人数/日活人数)
内容侧~高热笔记占比
一、召回(有可能连同粗排一起的方法)
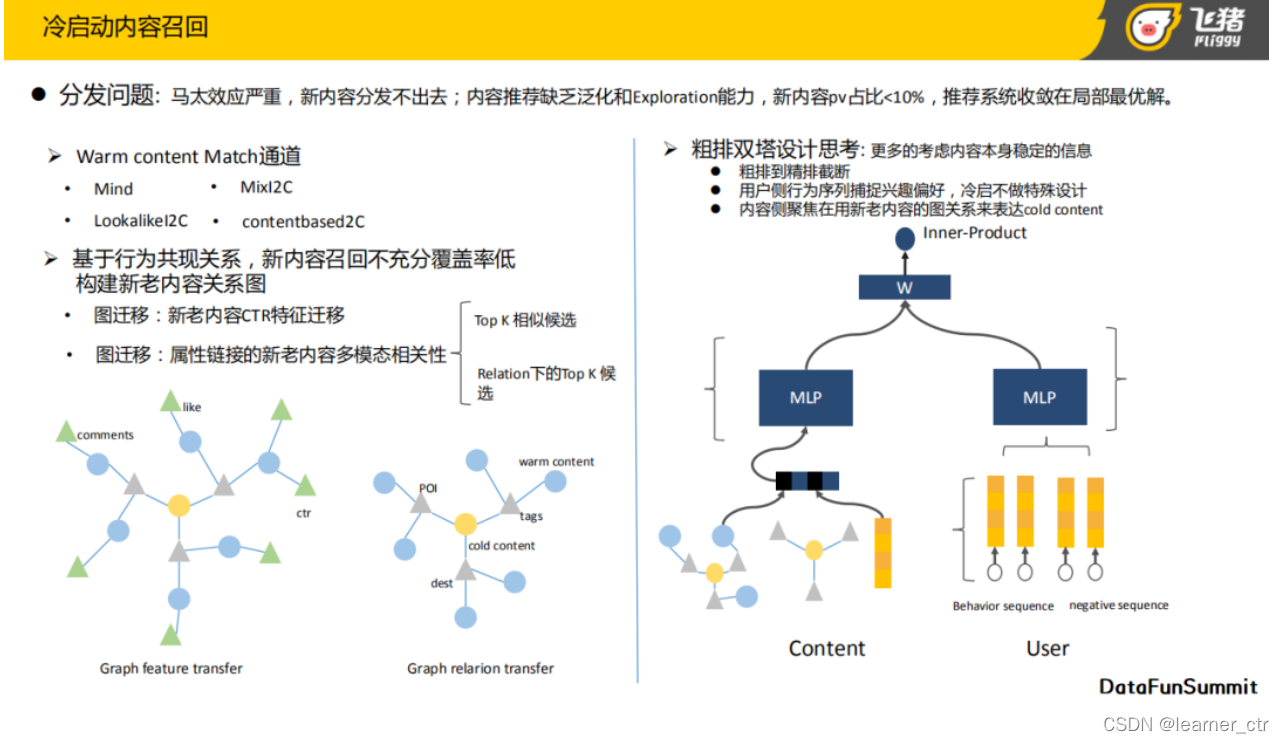
1:飞猪单独从召回、粗排两个阶段,解决了不能很好为用户召回“内容item”侧的冷启动item
https://appukvkryx45804.pc.xiaoe-tech.com/detail/i_61e181dce4b01e3d14020b72/1?fromH5=true
召回方面:设计了两路冷启动item召回
2:均匀保量+助推放大(阿里巴巴 - 每平每屋的冷启动策略),详见精排
文章中只提到为什么单独为召回、排序搞一套链路:由于新内容缺少线上的反馈数据,但是没有讲到具体的细节,所以我猜测应该只是在主链路的基础上将item相关的统计特征(就是需要时间反馈的一系列特征)给删除掉了!
3:小红书的冷启动召回
召回方式:itemcf依赖user和item的交互,所以冷启动用不了;id embedding也没有(没法直接用双塔召回,需要改造);自带图片、文字内容;自带算法/人工标签/类目/关键词;聚类召回;Look-Alike召回
改进的双塔模型:模型最开始的input_feature,新item都使用default embedding;利用相似的高曝光的item的embedding的平均值。(一般会是多个向量召回池,1小时item池、6小时、24小时、30天item,而且共享一个双塔model,不会增加训练代价)
基于类目的召回:维护类目->item的索引,按时间倒排。用户进入系统后,拿到这个user喜欢的类目,再拿到top-k的item(缺点:发布几小时后,就没有机会再被召回;个性化很差。优点:能让新发布的item尽快曝光,对作者/用户挺好)
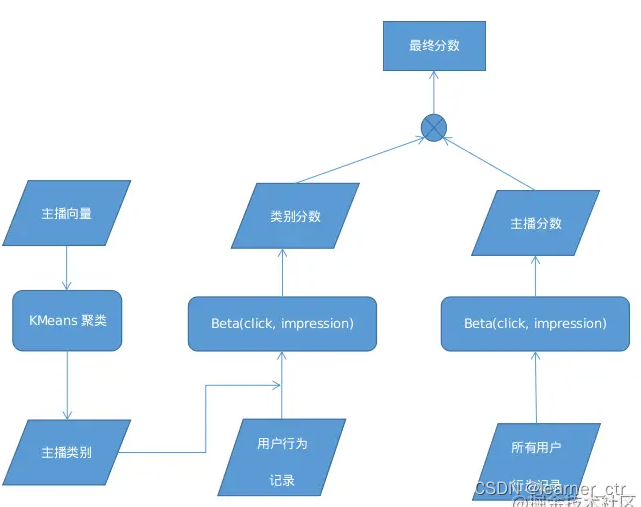
聚类召回:如果用户喜欢一篇item,那么他会喜欢内容相似的item。事先训练一个神经网络(下有结构),基于item的类目、内容,把item映射到向量,利用kmeans余弦相似度划分成1000个类别。新的item产生后,先拿到embedding,再计算和1000个类别的距离,按照时间加聚类索引的在最前面。缺点和上面一样,一篇item发布几小时后,就召回不了了
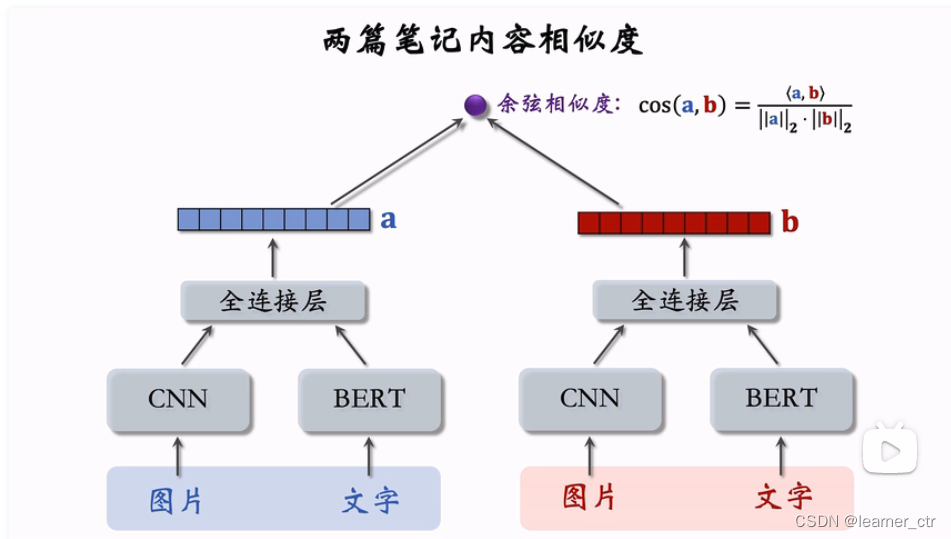
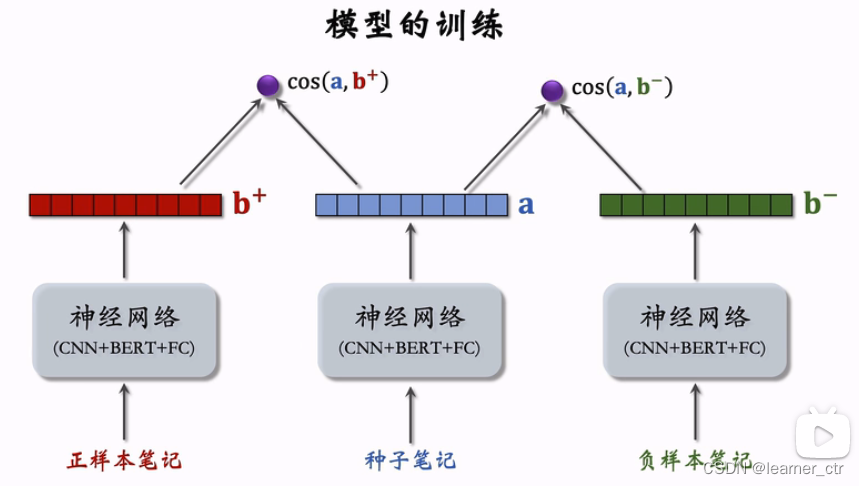
种子笔记、正样本的选择办法:高曝光、两篇笔记有相同二级类目,再用itemcf选择正样本
负样本:全库随机选
LookLike召回
如何计算两个用户的相似度:usercf userembedding的cos余弦相似度
用户对笔记感兴趣的操作:点赞、点击、收藏、转发,把这些作为种子用户,查找相似的用户进行推荐
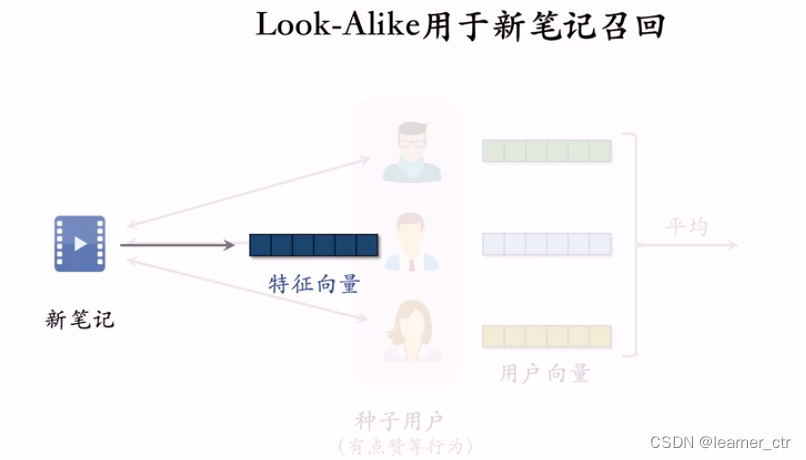
新笔记的交互较少,所以有交互的用户一定要利用起来,先拿到种子用户,再复用双塔模型得到的用户的embedding取平均(有交互就分钟级更新),然后把这些新笔记的特征向量放在faiss数据库中。有新用户过来,取回几十篇新笔记
二、粗排
1:利用图网络思想,给一些冷启item泛化出一些可统计的特征
2:均匀保量+助推放大(阿里巴巴 - 每平每屋的冷启动策略),详见精排
3:小红书 物品冷启05:流量调控_哔哩哔哩_bilibili
3.1 新笔记提权(粗排、重排,两个漏斗环节),小投入大产出,缺点:人工系数敏感
3.2 新笔记保量。缺点,线上环境变化很快,成功率远低于100%
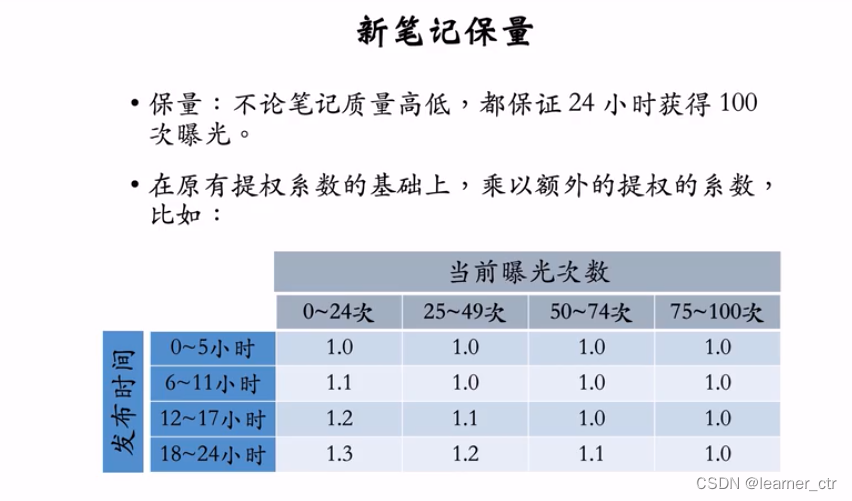

3.3 差异化保量
基础保量:100次
内容质量:用模型判断内容质量,额外保量,最多200次
作者质量:同上
保量结束后,就停止新笔记的扶持,和老笔记一起进行竞争
三、精排
1:常见的一种做法是精排阶段两轮冷启动boost(pid+ucb),这是因为pid可控性强,方便业务可以按照自己的需要来进行放量。ucb波动更小,更接近真实值。这两种做法博主研究的不是很多
2:均匀保量+助推放大(阿里巴巴 - 每平每屋的冷启动策略)、潜力预估模型冷启动系统优化与内容潜力预估实践_阿里巴巴淘系技术团队官网博客的博客-CSDN博客
2.1 由于新内容缺少线上的反馈数据,直接复用主链路的召回排序算法会导致对新内容的预估结果偏差较大,所以我们为冷启动链路设计了一套独立的召回排序链路(所以不止是精排,召回、粗排也是一套独立的链路)。均匀保量是每个新item都会有同等的保底曝光pv,助推放大是在均匀保量截断根据item的实时ctr动态调高保量值
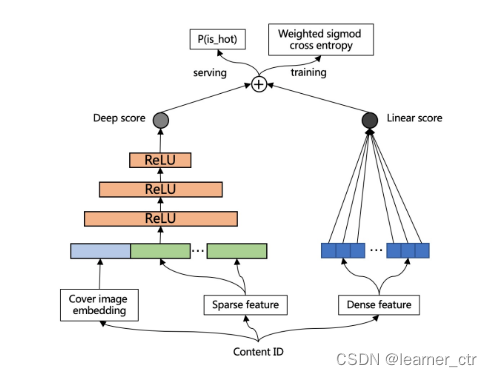
2.2 潜力预估分主要被应用于干预线上冷启链路内容的召回和排序算法。期望对于P(is_hot)高的内容,给予更高的冷启PV;同时,对于P(is_hot)低的内容,减少其冷启PV,以节省一部分冷启流量。在具体实现上,我们分别将潜力预估分作为冷启链路排序模型的一个特征和召回链路的截断分。
样本:发布7天内迅速获得高曝光高点击的内容为正样本,其余为负样本。设定曝光PV和点击率阈值,高于阈值的为正样本,否则为负样本
模型:
3:meta-learning中的maml
meta-learning推荐大家去看看“李宏毅”讲师的视频课程:https://www.bilibili.com/video/BV1Wv411h7kN?p=92
重点我们看看maml是怎么应用在冷启动中的,之前看过一篇论文讲解的是maml用来快速用少量样本训练得到冷启动item较好的向量,然后用在召回侧,我们重点看看这种做法
论文地址:https://arxiv.org/abs/1904.11547
单独为这篇论文写出来一篇文章来讲解:maml - Warm Up Cold-start Advertisements - 论文研读_1066196847的博客-CSDN博客3:
====================二、用户冷启动====================
1:如果用户什么信息都没有,那么肯定是推荐一些热门item给他。但是这样如果更新不及时,用户很快就是失去兴趣(毕竟热门不会对每个用户都喜欢,还是需要很快从用户反馈中进行个性化推荐)
2:类似于召回阶段的协同过滤方案
很多app对于用户刚进来时,都要求用户必须选择至少3个喜欢的类型,然后可以针对选择的类型做群体推荐(item协同过滤,比如单纯的计算、矩阵分解等办法)
3:multi-armed bandit算法


4:深度学习方案
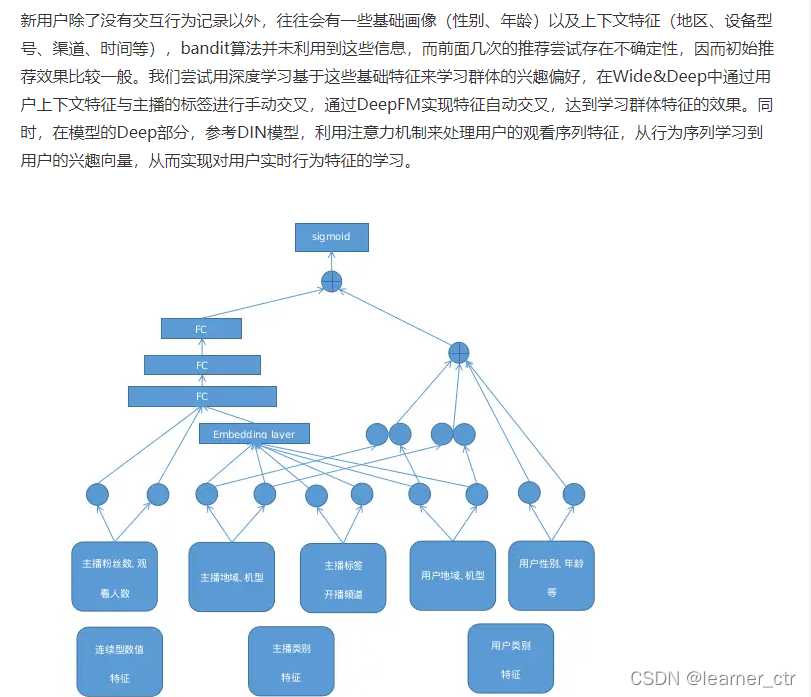
如果已经有了一些用户注册时候的基础属性(很多app在第一次使用的时候都会让用户选这些),那么就可以设计规则、单单用这些基础属性训练base model的思路来进行刚开始的冷启推荐;同时模型中要加入用户的短期实时反馈特征,处理思路是下面截图中的DIN思路,这种实时反馈特征对推荐效果来说很重要
5:淘宝 - 逛逛团队,在淘宝这个商品item+内容item独有的app中,为内容侧的冷启user设计了很好的方案,这个方案还可以泛化到其他app中,比如京东的“逛”、抖音的小程序、点淘的直播-短视频等
首先有几个基础知识:self attention && vanilla attention
self attention是出自论文“attention is all you need”,讲解好的文章有:Transformer模型中重点结构详解_Jeremy-CSDN博客_transformer主要结构
详解Transformer (Attention Is All You Need) - 知乎
vanilla attention是来自下面这篇论文(不太确定)
Attention(一)——Vanilla Attention, Neural Turing Machines
两个区别应该是


上面这段讲的是attention is all you need里面的encoder 和 decoder部分,也就是说encoder用的是self-attention,decoder用的是vanilla-attention
逛逛团队的这篇文章可以详看:多序列融合召回在新用户冷启动上的应用
里面有几个难点讲解详看:淘宝逛逛,融合淘宝商品序列 - 逛逛场景内容序列的办法_1066196847的博客-CSDN博客
6:迁移学习方案
https://arxiv.org/pdf/2010.15982.pdf
7:特征、样本
特征
(1):提取一些长尾用户也能覆盖到的特征,比如用户最近n个item,但是这种特征很可能让模型学偏,因为对中部和头部、尾部用户来说,n个item代表的是不同的意义。不一定会有效果
(2):长序列建模,这个方法提出来不是专门为这种问题,而且想把用户长期行为能够用到,而且是在淘宝电商场景用到,在电商场景用户对一种类目的item往往不会只有一个item的喜好,所以把同类目/计算item相似度的top拿出来作为特征可能有用,但是在一些本身用户可能偶尔进来一次的场景就不会有用了,在这种场景中更重要的是构建不同item之间的相似关系,就是从整个**序列中筛选出来和预估item有类似于(啤酒、尿布)这种关系的item序列
Life-long兴趣建模视角CTR预估模型:Search-based Interest Model - 知乎
3:提取一些较通用的特征,这种特征不分头尾部,在所有item、query上覆盖率都一样,这些一般是基础属性。如果是一些较简单统计类型的特征,可以尝试飞猪的一篇对冷启item的做法,就是利用图网络的思想,把头部item的统计特征泛化到长尾item中
样本
1:对尾部样本进行重复采样(论文:Learning from imbalanced data)
2:在模型训练时,调整尾部样本的loss权重(论文:Classbalanced loss based on effective number of samples)
待研究:Multi-objective optimization for long tail recommendation
3:dqn,强化学习思想
https://blog.csdn.net/a1066196847/article/details/122756688
京东这篇文章虽然不是专门为冷启动做的一个探索,但是也能应用到冷启动上来,无非就是把里面的几个重要参数换下
(1):首先要有一个网络,称为Q网络,要能在给定状态st和推荐结果at的情况下能得到预估到的奖励。参数定义为θ

(2):再有真实的奖励(因为用的真实log数据,这个奖励肯定知道),真实奖励包含两部分,即时奖励+未来一段时间的奖励(这部分奖励用超参数来控制占比)

(3):然后就是计算上面 1 2 的差值,并求 mse 作为误差,并反向传导更新 θ

重点是Q-网络的设计,在京东那篇论文中是这样设计的
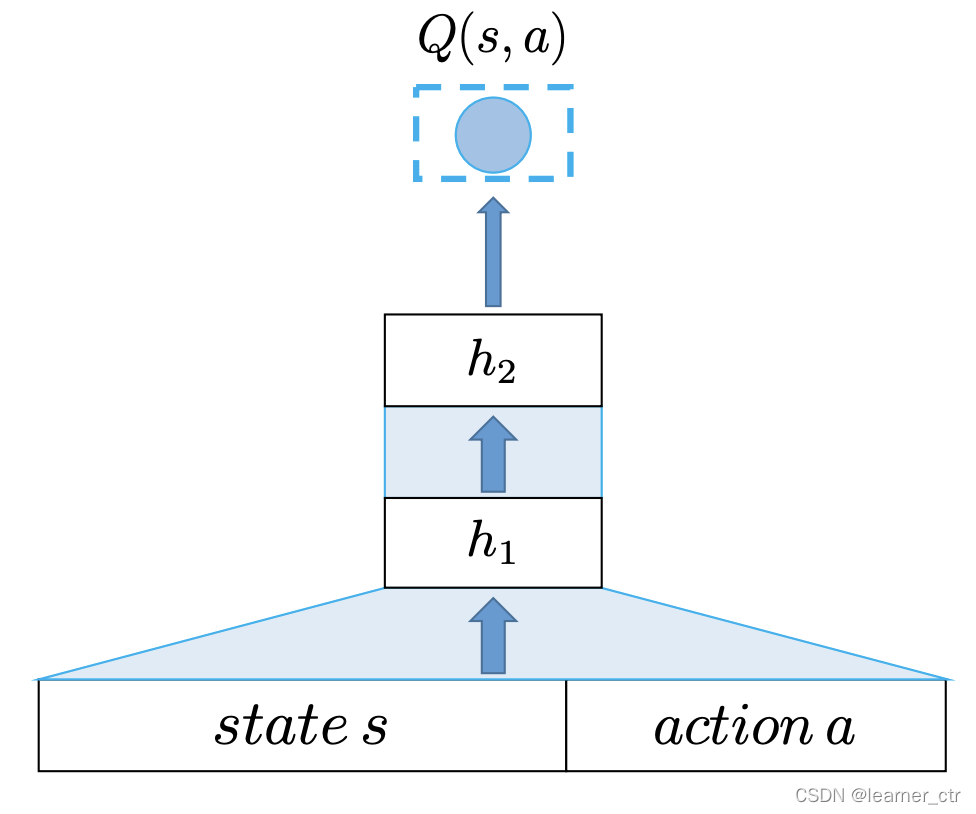
上面两种Q网络,左边那个s a就直接将两个放在concat在一起,然后经过几个mlp网络。右边分别在正负反馈的状态s(经过gru网络将原始状态s给聚合成一个向量)上拼接上推荐item-a,然后mlp得到h1 h1,再把h1 h1 concat在一起得到h2,这样的目的是给左边h1部分学习到尽可能大的权重,右边h1尽量小,这样dqn网络才会尽可能推荐出来会正反馈的item
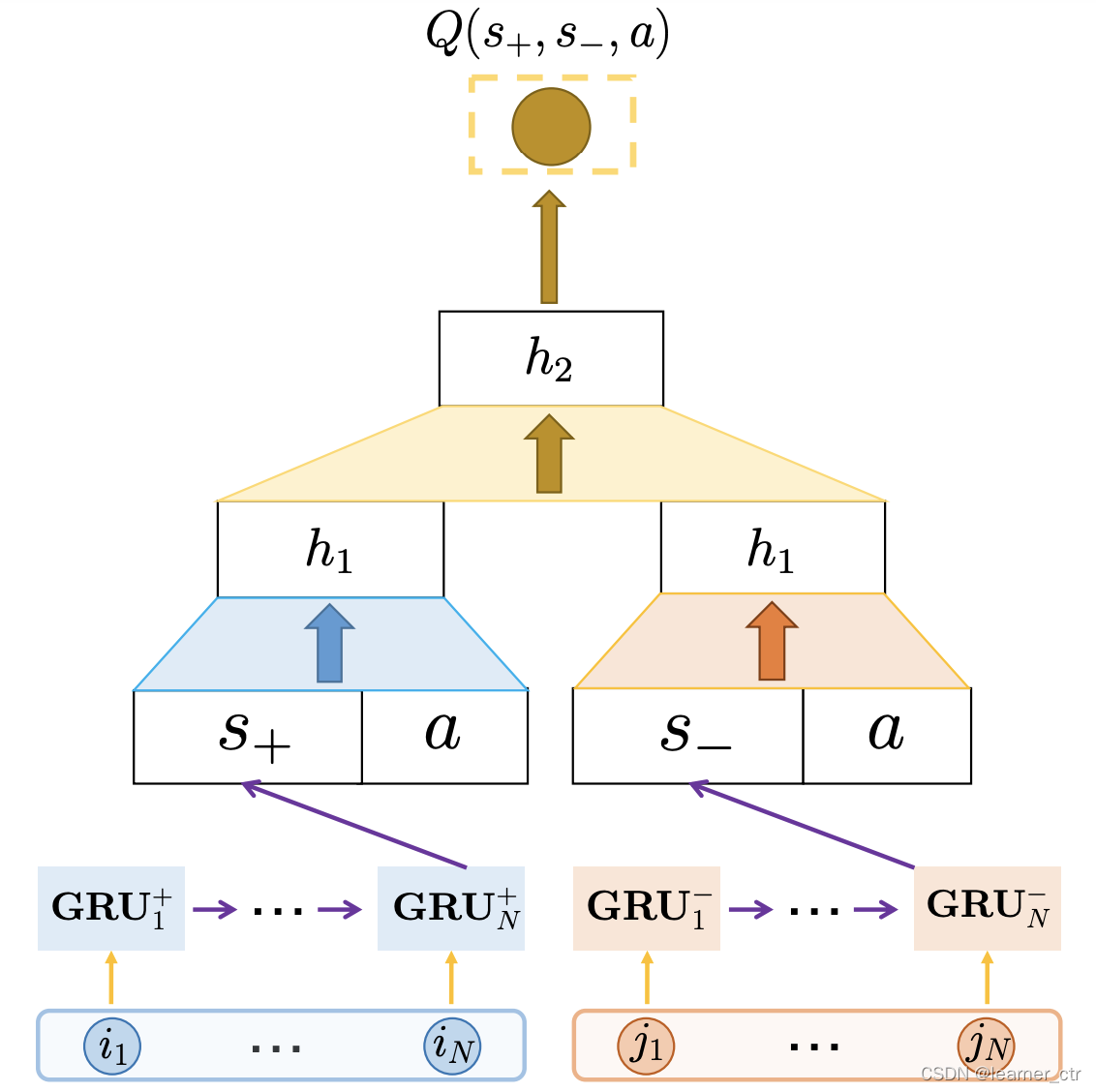
除了上面的涉及,我还看到过下面这种设计。不过设计原因暂时还看不太懂,没有什么解释。不过和上面京东很多地方都很像,比如也是mse作为loss,所以reward是真实奖励,相当于前面京东网络中的 y,所以两侧的网络肯定有一侧相当于Q网络

====================三、query冷启动(长尾query)====================
1:一般是做一些通用的特征
query的embedding向量、类别、长度、纠错后的词、n-gram
2:从样本角度来看,这个得和模型训练结构相融合,如果模型训练时有特征衰减机制,就是说
特征历史出现次数*g(小于但是接近1) + 当次训练样本中的出现次数*m,小于某个阈值就删除
那么可以多积累几天的长尾样本再一起送到模型中去训练
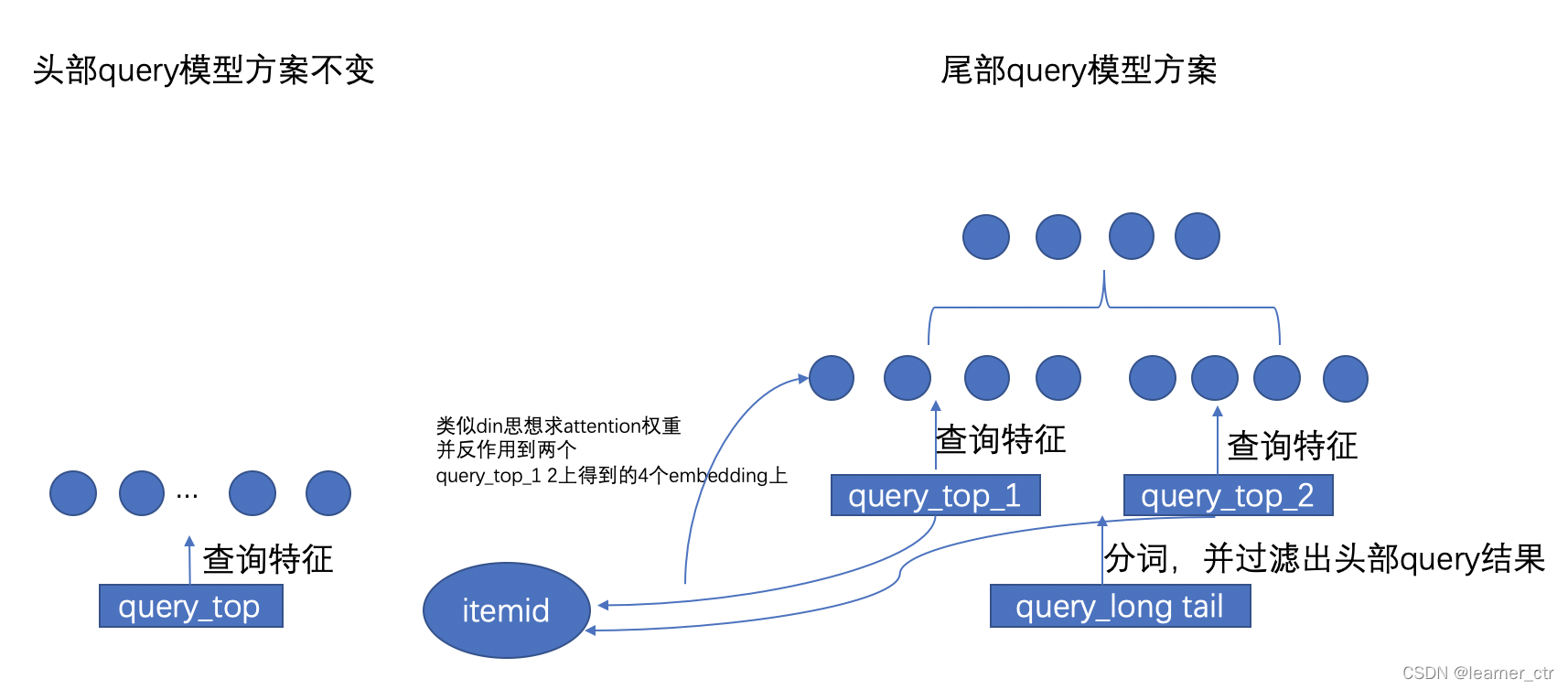
3:模型角度
得到优化思路的原始论文,是淘宝在2021年为了解决long tail query类目预测不准时做的一篇研究,在他们线上产生了很好的效果
论文名:Modeling Across-Context Attention For Long-Tail Query Classification in E-commerce

















 738
738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









