







现在有11类食物,有训练集和测试集,其中训练集中有带标签的数据和不带标签的数据。
一、需要导入的包和固定随机种子
1.1包
import random
import torch
import torch.nn as nn
import numpy as np
import os
from torch.utils.data import Dataset, DataLoader
from PIL import Image#读取图片数据
from tqdm import tqdm#进度
from torchvision import transforms
import time
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
from pylab import mpl
from model_utils.model import initialize_model1.2固定随机种子函数
#把所有的随机固定
def seed_everything(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
random.seed(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
seed_everything(0)seed_everything(0) 是一个用于固定随机种子的函数,目的是确保实验的可复现性。在深度学习中,许多操作(如权重初始化、数据打乱、Dropout 等)依赖于随机性,如果不固定随机种子,每次运行的结果可能会不同。通过设置随机种子,可以确保每次运行代码时生成的随机数序列相同,从而得到一致的结果。
接着我们先来处理一下训练集中带标签的数据。
二、训练集带标签数据处理
2.1读取数据
HW = 224 #在深度学习中,一般将图片的宽高设置成224
train_transform = transforms.Compose(
[
transforms.ToPILImage(),#将输入数据转换为 PIL 图像格式
transforms.RandomResizedCrop(224),#随机裁剪图像并调整大小为 224x224
transforms.RandomRotation(50),#随机旋转图像,旋转角度范围为 -50° 到 50°
transforms.ToTensor()#将 PIL 图像转换为 PyTorch 张量
]
)
class food_data(Dataset):
def __init__(self, path):
self.X, self.Y = self.read_file(path)
self.Y = torch.LongTensor(self.Y) # 标签转为长整型
self.transform = train_transform
def read_file(self, path):#读取数据
for i in range(11):
file_dir = path + "\%02d"%i
file_list = os.listdir(file_dir)
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8)#存储图像数据
yi = np.zeros((len(file_list)), dtype=np.uint8)#存储标签
for j, img_name in enumerate(file_list):
img_path = os.path.join(file_dir, img_name)#将图像路径和图像名拼接到一起
img = Image.open(img_path)#打开图像文件
img = img.resize((HW, HW))#设置大小
xi[j, ...] = img#将当前加载的图像数据放到xi的第j个位置
yi[j] = i#存储标签
if i == 0:
X = xi
Y = yi
else:#将每个子文件夹的数据和标签合并到 X 和 Y 中
X = np.concatenate((X, xi), axis=0)
Y = np.concatenate((Y, yi), axis=0)
print("读了%d个数据"%len(Y))
return X,Y
def __getitem__(self, item):
return self.transform(self.X[item]), self.Y[item]
def __len__(self):
return len(self.X)
train_path = r"C:\Users\Lenovo\Desktop\classify\food_classification\food-11_sample\training\labeled"
train_dataset = food_data(train_path)为了使模型的泛化能力更强,我们要对数据进行数据增广,通过定义train_transform来实现,将经过旋转裁剪等操作后得到的图形全部作为训练集。
2.2搭建模型
class myModule(nn.Module):
def __init__(self, num_class):
super(myModule, self).__init__()
self.layer0 = nn.Sequential( #一开始是3*224*224 目标是512*7*7
nn.Conv2d(3, 64, 3, 1, 1),
nn.BatchNorm2d(64),#归一化
nn.ReLU(),
nn.MaxPool2d(2) #64*112*112
)
self.layer1 = nn.Sequential(
nn.Conv2d(64, 128, 3, 1, 1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2) # 128*56*56
)
self.layer2 = nn.Sequential(
nn.Conv2d(128, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2) # 256*28*28
)
self.layer3 = nn.Sequential(
nn.Conv2d(256, 512, 3, 1, 1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2) # 512*14*14
)
self.pool1 = nn.MaxPool2d(2) #512*7*7 == 25088
self.fc1 = nn.Linear(25088, 1000)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(1000, num_class)
def forward(self, x):
x = self.layer0(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.pool1(x)
x = x.view(x.size()[0], -1)
x = self.fc1(x)
x = self.relu1(x)
x = self.fc2(x)
return xx = x.view(x.size()[0], -1) 的作用是将多维张量展平为二维张量,保留批量大小作为第一维度,其余维度自动展平为第二维度。这种操作通常用于将卷积层的输出转换为全连接层的输入
三、测试集数据处理
由于测试集不需要对图片数据进行数据增广,所以测试集的transform和训练集的不一样。所以要在数据读取部分传入类型mode来区分。
val_transform = transforms.Compose(
[
transforms.ToPILImage(),#将输入数据转换为 PIL 图像格式
transforms.ToTensor()#将 PIL 图像转换为 PyTorch 张量
]
)在init里面代码改成:
class food_data(Dataset):
def __init__(self, path, mode="train"):
self.mode = mode
self.X, self.Y = self.read_file(path)
if mode == "train":
self.transform = train_transform
else:
self.transform = val_transform四、训练模型
代码比之前新冠病毒多加了统计正确率。
def train_val(model, train_loader, val_loader, device, epochs, optimizer, loss, save_path):
model = model.to(device)
plt_train_loss = []
plt_val_loss = []
plt_train_acc = []
plt_val_acc = []
max_acc = 0.0
for epoch in range(epochs):
train_loss = 0.0
val_loss = 0.0
train_acc = 0.0
val_acc = 0.0
start_time = time.time()
model.train() #模型调为训练模式
for batch_x, batch_y in train_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
train_bat_loss = loss(pred, target)
train_bat_loss.backward()
optimizer.step()#更新模型
optimizer.zero_grad()
train_loss += train_bat_loss.cpu().item()
train_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
plt_train_loss.append(train_loss / train_loader.__len__())
plt_train_acc.append(train_acc / train_loader.dataset.__len__())
model.eval()
with torch.no_grad():
for batch_x, batch_y in val_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
val_bat_loss = loss(pred, target)
val_loss += val_bat_loss.cpu().item()
val_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
plt_val_loss.append(val_loss / val_loader.__len__())
plt_val_acc.append(val_acc / val_loader.dataset.__len__())
if val_acc > max_acc:
torch.save(model, save_path)
max_acc = val_acc
print("[%03d/%03d] %2.2f sec(s) Trainloss: %.6f |Valloss: %.6f Trainacc: %.6f |Valacc: %.6f"% \
(epoch, epochs, time.time()-start_time, plt_train_loss[-1], plt_val_loss[-1], plt_train_acc[-1], plt_val_acc[-1]))
plt.plot(plt_train_loss)
plt.plot(plt_val_loss)
plt.title("loss")
plt.legend(["train", "val"])
plt.show()
plt.plot(plt_train_acc)
plt.plot(plt_val_acc)
plt.title("acc")
plt.legend(["train", "val"])
plt.show()
SGD、Adam和AdamW区别:
| 特性 | SGD | Adam | AdamW |
| 学习率 | 固定 | 自适应 | 自适应 |
| 动量 | 可选 | 内置 | 内置 |
| 权重衰减 | 直接加入损失函数 | 与梯度更新耦合 | 与梯度更新解耦 |
| 收敛速度 | 较慢 | 较快 | 较快 |
| 泛化性能 | 较好 | 较差 | 较好 |
| 适用场景 | 数据集较小或需要精细调优 | 数据集较大且需要快速收敛 | 模型规模较大且需要更好的泛化性能 |
CrossEntropyLoss是交叉熵损失
model = myModule(11)
lr = 0.001
device = "cuda" if torch.cuda.is_available() else "cpu"
epochs = 15
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=1e-4)
loss = nn.CrossEntropyLoss()
save_path = "model_save/best_model.pth"
train_val(model, train_loader, val_loader, device, epochs, optimizer, loss, save_path)五、训练集不带标签数据处理
对于无标签的数据,我们可以将其放入模型中,得到预测值,再根据概率和置信度来决定是否将数据和预测值放入一个新的集来作为有标签训练集对模型进行训练。
首先要读取数据,在原本的代码上对mode为semi的进行其他处理:
class food_data(Dataset):
def __init__(self, path, mode="train"):
self.mode = mode
if mode == "semi":
self.X = self.read_file(path)
else:
self.X, self.Y = self.read_file(path)
self.Y = torch.LongTensor(self.Y) # 标签转为长整型
if mode == "train":
self.transform = train_transform
else:
self.transform = val_transform
def read_file(self, path):#读取数据
if self.mode == "semi":
file_list = os.listdir(path)
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8) # 存储图像数据
for j, img_name in enumerate(file_list):
img_path = os.path.join(path, img_name)
img = Image.open(img_path)
img = img.resize((HW, HW))
xi[j, ...] = img
return xi
else:
for i in range(12):
file_dir = path + "\%02d"%i
file_list = os.listdir(file_dir)
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8)#存储图像数据
yi = np.zeros((len(file_list)), dtype=np.uint8)#存储标签
for j, img_name in enumerate(file_list):
img_path = os.path.join(file_dir, img_name)#将图像路径和图像名拼接到一起
img = Image.open(img_path)#打开图像文件
img = img.resize((HW, HW))#设置大小
xi[j, ...] = img#将当前加载的图像数据放到xi的第j个位置
yi[j] = i#存储标签
if i == 0:
X = xi
Y = yi
else:#将每个子文件夹的数据和标签合并到 X 和 Y 中
X = np.concatenate((X, xi), axis=0)
Y = np.concatenate((Y, yi), axis=0)
print("读了%d个文件"%len(Y))
return X,Y
def __getitem__(self, item):
if self.mode == "semi":
return self.transform(self.X[item]), self.X[item]
else:
return self.transform(self.X[item]), self.Y[item]
def __len__(self):
return len(self.X)
我们想创建semiloader的话就得确定semiset是存在的,所以不能在全局中创建,应该写一个dataset函数,将无标签数据先用模型得出预测值,然后转换成概率,获得最大概率值,如果概率值大于一定值的时,就将该原本数据和预测值分别放入列表,循环直至读完无标签数据,最后返回两个列表。如果列表不为空的话就设置一个变量,如flag=T入额,否则flag=False;再创建一个函数(比如叫get)来接收这个dataset函数传回的dataset并判断flag的值,如果为false的话就返回None,不是的话就创建semiloader。
接着我们要在训练模型那边操作,当预测的准确度大于thres时就调用get函数;并且判断如果semiloader不为空时就开始训练模型。
部分代码如下:
class semiData(Dataset):
def __init__(self, no_label_loader, model, device, thres=0.99):
x, y = self.get_label(no_label_loader, model, device, thres)
if x == []:
self.flag = False
else:
self.flag = True
self.X = np.array(x)
self.Y = torch.LongTensor(y)
self.transform = train_transform
def get_label(self, no_label_loader, model, device, thres):
model = model.to(device)
pred_prob = []
labels = []
x = []
y = []
soft = nn.Softmax(dim=1)#将模型输出转换为概率分布
with torch.no_grad():
for bat_x, _ in no_label_loader:
bat_x = bat_x.to(device)
pred = model(bat_x)
pred_soft = soft(pred) #转换成概率
pred_max, pred_val = pred_soft.max(1) #按每行找最大概率及其下标
pred_prob.extend(pred_max.cpu().numpy().tolist())
labels.extend(pred_val.cpu().numpy().tolist())
for index, prob in enumerate(pred_prob):
if prob > thres :
x.append(no_label_loader.dataset[index][1])
y.append(labels[index])
return x, y
def __getitem__(self, item):
return self.transform(self.X[item]), self.Y[item]
def __len__(self):
return len(self.Y)
def get_semi_loader(no_label_loader, model, device, thres):
semiset = semiData(no_label_loader, model, device, thres)
if semiset.flag == False:
return None
else:
semiloader = DataLoader(semiset, batch_size=4, shuffle=False)
return semiloader
六、完整代码
import random
import torch
import torch.nn as nn
import numpy as np
import os
from torch.utils.data import Dataset, DataLoader
from PIL import Image#读取图片数据
from tqdm import tqdm#进度
from torchvision import transforms
import time
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
from pylab import mpl
from model_utils.model import initialize_model
# 设置中文显示字体
mpl.rcParams["font.sans-serif"] = ["SimHei"]
#把所有的随机固定
def seed_everything(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
random.seed(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
seed_everything(0)
HW = 224 #在深度学习中,一般将图片的宽高设置成224
train_transform = transforms.Compose(
[
transforms.ToPILImage(),#将输入数据转换为 PIL 图像格式
transforms.RandomResizedCrop(224),#随机裁剪图像并调整大小为 224x224
transforms.RandomRotation(50),#随机旋转图像,旋转角度范围为 -50° 到 50°
transforms.ToTensor()#将 PIL 图像转换为 PyTorch 张量
]
)
val_transform = transforms.Compose(
[
transforms.ToPILImage(),#将输入数据转换为 PIL 图像格式
transforms.ToTensor()#将 PIL 图像转换为 PyTorch 张量
]
)
class food_data(Dataset):
def __init__(self, path, mode="train"):
self.mode = mode
if mode == "semi":
self.X = self.read_file(path)
else:
self.X, self.Y = self.read_file(path)
self.Y = torch.LongTensor(self.Y) # 标签转为长整型
if mode == "train":
self.transform = train_transform
else:
self.transform = val_transform
def read_file(self, path):#读取数据
if self.mode == "semi":
file_list = os.listdir(path)
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8) # 存储图像数据
for j, img_name in enumerate(file_list):
img_path = os.path.join(path, img_name)
img = Image.open(img_path)
img = img.resize((HW, HW))
xi[j, ...] = img
return xi
else:
for i in range(11):
file_dir = path + "\%02d"%i
file_list = os.listdir(file_dir)
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8)#存储图像数据
yi = np.zeros((len(file_list)), dtype=np.uint8)#存储标签
for j, img_name in enumerate(file_list):
img_path = os.path.join(file_dir, img_name)#将图像路径和图像名拼接到一起
img = Image.open(img_path)#打开图像文件
img = img.resize((HW, HW))#设置大小
xi[j, ...] = img#将当前加载的图像数据放到xi的第j个位置
yi[j] = i#存储标签
if i == 0:
X = xi
Y = yi
else:#将每个子文件夹的数据和标签合并到 X 和 Y 中
X = np.concatenate((X, xi), axis=0)
Y = np.concatenate((Y, yi), axis=0)
print("读了%d个数据"%len(Y))
return X,Y
def __getitem__(self, item):
if self.mode == "semi":
return self.transform(self.X[item]), self.X[item]
else:
return self.transform(self.X[item]), self.Y[item]
def __len__(self):
return len(self.X)
class semiData(Dataset):
def __init__(self, no_label_loader, model, device, thres=0.99):
x, y = self.get_label(no_label_loader, model, device, thres)
if x == []:
self.flag = False
else:
self.flag = True
self.X = np.array(x)
self.Y = torch.LongTensor(y)
self.transform = train_transform
def get_label(self, no_label_loader, model, device, thres):
model = model.to(device)
pred_prob = []
labels = []
x = []
y = []
soft = nn.Softmax(dim=1)#将模型输出转换为概率分布
with torch.no_grad():
for bat_x, _ in no_label_loader:
bat_x = bat_x.to(device)
pred = model(bat_x)
pred_soft = soft(pred) #转换成概率
pred_max, pred_val = pred_soft.max(1) #按每行找最大概率及其下标
pred_prob.extend(pred_max.cpu().numpy().tolist())
labels.extend(pred_val.cpu().numpy().tolist())
for index, prob in enumerate(pred_prob):
if prob > thres :
x.append(no_label_loader.dataset[index][1])
y.append(labels[index])
return x, y
def __getitem__(self, item):
return self.transform(self.X[item]), self.Y[item]
def __len__(self):
return len(self.Y)
def get_semi_loader(no_label_loader, model, device, thres):
semiset = semiData(no_label_loader, model, device, thres)
if semiset.flag == False:
return None
else:
semiloader = DataLoader(semiset, batch_size=4, shuffle=False)
return semiloader
class myModule(nn.Module):
def __init__(self, num_class):
super(myModule, self).__init__()
self.layer0 = nn.Sequential( #一开始是3*224*224 目标是512*7*7
nn.Conv2d(3, 64, 3, 1, 1),
nn.BatchNorm2d(64),#归一化
nn.ReLU(),
nn.MaxPool2d(2) #64*112*112
)
self.layer1 = nn.Sequential(
nn.Conv2d(64, 128, 3, 1, 1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2) # 128*56*56
)
self.layer2 = nn.Sequential(
nn.Conv2d(128, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2) # 256*28*28
)
self.layer3 = nn.Sequential(
nn.Conv2d(256, 512, 3, 1, 1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2) # 512*14*14
)
self.pool1 = nn.MaxPool2d(2) #512*7*7 == 25088
self.fc1 = nn.Linear(25088, 1000)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(1000, num_class)
def forward(self, x):
x = self.layer0(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.pool1(x)
x = x.view(x.size()[0], -1)
x = self.fc1(x)
x = self.relu1(x)
x = self.fc2(x)
return x
def train_val(model, train_loader, val_loader, no_label_loader, device, epochs, optimizer, loss, thres, save_path):
model = model.to(device)
semiloader = None
plt_train_loss = []
plt_val_loss = []
plt_train_acc = []
plt_val_acc = []
max_acc = 0.0
for epoch in range(epochs):
train_loss = 0.0
val_loss = 0.0
semi_loss = 0.0
train_acc = 0.0
val_acc = 0.0
semi_acc = 0.0
start_time = time.time()
model.train() #模型调为训练模式
for batch_x, batch_y in train_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
train_bat_loss = loss(pred, target)
train_bat_loss.backward()
optimizer.step()#更新模型
optimizer.zero_grad()
train_loss += train_bat_loss.cpu().item()
train_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
plt_train_loss.append(train_loss / train_loader.__len__())
plt_train_acc.append(train_acc / train_loader.dataset.__len__())
if semiloader != None:
for batch_x, batch_y in semiloader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
semi_bat_loss = loss(pred, target)
semi_bat_loss.backward()
optimizer.step() # 更新模型
optimizer.zero_grad()
semi_loss += semi_bat_loss.cpu().item()
semi_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
print("半监督数据集的训练准确率为:", semi_acc / train_loader.dataset.__len__())
model.eval()
with torch.no_grad():
for batch_x, batch_y in val_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
val_bat_loss = loss(pred, target)
val_loss += val_bat_loss.cpu().item()
val_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())
plt_val_loss.append(val_loss / val_loader.__len__())
plt_val_acc.append(val_acc / val_loader.dataset.__len__())
if plt_val_acc[-1] > thres:
semiloader = get_semi_loader(no_label_loader, model, device, thres)
if val_acc > max_acc:
torch.save(model, save_path)
max_acc = val_acc
print("[%03d/%03d] %2.2f sec(s) Trainloss: %.6f |Valloss: %.6f Trainacc: %.6f |Valacc: %.6f"% \
(epoch, epochs, time.time()-start_time, plt_train_loss[-1], plt_val_loss[-1], plt_train_acc[-1], plt_val_acc[-1]))
plt.plot(plt_train_loss)
plt.plot(plt_val_loss)
plt.title("loss")
plt.legend(["train", "val"])
plt.show()
plt.plot(plt_train_acc)
plt.plot(plt_val_acc)
plt.title("acc")
plt.legend(["train", "val"])
plt.show()
train_path = r"C:\Users\Lenovo\Desktop\classify\food_classification\food-11_sample\training\labeled"
val_path = r"C:\Users\Lenovo\Desktop\classify\food_classification\food-11_sample\validation"
no_label_path = r"C:\Users\Lenovo\Desktop\classify\food_classification\food-11_sample\training\unlabeled\00"
train_dataset = food_data(train_path, "train")
val_dataset = food_data(val_path, "val")
no_label_dataset = food_data(no_label_path, "semi")
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=4, shuffle=True)
no_label_loader = DataLoader(no_label_dataset, batch_size=4, shuffle=False)
model = myModule(11)
lr = 0.001
device = "cuda" if torch.cuda.is_available() else "cpu"
epochs = 15
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=1e-4)
loss = nn.CrossEntropyLoss()
save_path = "model_save/best_model.pth"
thres = 0.99
train_val(model, train_loader, val_loader, no_label_loader, device, epochs, optimizer, loss, thres, save_path)
七、用resnet18模型的对比
这是使用了resnet18后的运行结果:
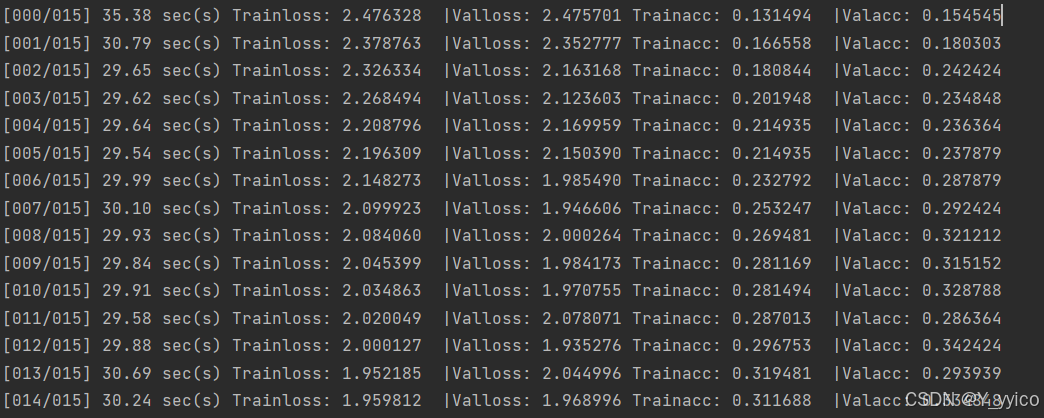
这是用自己的模型结果:

将代码换一下就可以用rednet18了:
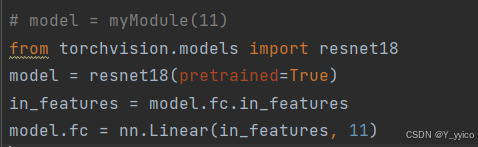
from torchvision.models import resnet18
model = resnet18(pretrained=True)
in_features = model.fc.in_features
model.fc = nn.Linear(in_features, 11)
















 396
396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









