







目录
3. 三引号 : '''-----''' 或 """----"""(三对双引号)
一、变量命名


#下划线连接的方式更推荐
二、数据类型
(一)字符串类型
chr(n)函数可以把编码为n的符号转换为对应的字符,例如:chr(97)代表字符 'a'
单字符在 Python 中也是作为一个字符串使用,使用单引号或双引号都可以创建字符串:
var1=‘Hello world’
var2="H"
1.原始字符串
在字符串的第一个引号之前加字母"r"或"R",使得字符串中转义字符等都失效,字符串仅仅是字面意思。
例如:>>>print r'\n'
输出结果为:\n
2.字符串运算符
变量 a 值为字符串 "Hello",b 变量值为 "world":
| 操作符 | 描述 | 运算 |
|---|---|---|
| + | 字符串连接 | a + b: 'Helloworld' |
| * | 重复输出字符串 | a * 2 :'HelloHello' |
| [] | 通过索引获取字符串中字符 | a[1]: 'e' |
| in | 如果字符串中包含给定的字符(串)返回 True | "He" in a :True |
| not in | 如果字符串中不包含给定的字符(串)返回 True | ‘a’ not in a:True |
| s[start : end : step] | 截取字符串中的一部分,如a[m:n:p]:从索引m(缺省默认从开头截取)截取到索引n(缺省默认为取到字符串结束),截取时含m不含n,p为步长,p为负数时逆序截取,缺省为1;若以字符串左端为起点,索引从 0 开始;若以字符串右端为起点,索引从 -1 开始计数,-1、-2...... | a[1:4] :'ell' a[2:-2]:l |
注意,字符串中的字符是不可以改变的,因此不能对某个字符a[i]赋值﹐例如,a[0]='b'是错误的。
3.切片操作
s = 'helloworld'
print(s[1]) # e 根据索引得到字符串中某个位置的字符
print(s[1:3]) # el 根据索引截取字符串某个子串 含起始位置不含终止位置 即含1不含3
print(s[:3]) # hel 开始位置缺省 默认从头截取
print(s[-5:-1]) # worl -1表示从右往左数第1个 正序输出起始位置索引为最左边字符的位置
print(s[:-5:-1]) # dlro 逆序输出 起始位置索引为最右边字符的位置,开始位置缺省默认-1
print(s[::-2]) # drwle 逆序输出 步长为2
print(s[1:]) # elloworld 终止位置缺省默认截取到字符串结尾
print(s[::2]) # hlool 起始和终止位置都可缺省,默认为整个字符串;步长为2,从首字符开始取,每2个取1个
4. 三引号 : '''-----''' 或 """----"""(三对双引号)
允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符,使得字符串是所见即所得的。
与其他字符串表示方式的区别:
s1 = 'hello'
print(type(s1)) # <class 'str'>
print(isinstance(s1, str)) # True instance实例
s2 = "hello"
s3 = '''
hello
'''
print(id(s1),id(s2),id(s3)) #s1 is s2:常量赋值,内容一样,地址相同 s3要保留格式(s3的内容不在一行上),地址与前两个不同
s1=input('请输入s1:') # hello
s2=input('请输入s2:') # hello
print(s1==s2) #True
print(s1 is s2) # False input输入底层作了处理,地址不相同
5.字符串内建函数
1.大小写相关
str='hello woRld'
result=str.capitalize() #Hello woRld 首字符若为字母,则转换成大写
result=str.title() #Hello World 将字符串标题化:每个单词首字母大写,其余字母小写
result=str.istitle() #False 判断字符串是否符合标题格式
result=str.upper()#HELLO WORLD 返回一个字符串,把s 中所有的小写字母转换为大写字母。
result=str.lower()#hello world 返回一个字符串,把s 中所有的大写字母转换为小写字母。
案例:随机生成四位验证码
# 案例:随机生成四位验证码
import random
code=''
s='QWERTYUIOPASDFGHJKLZXCVBNMqwertyuiopasdfghjklzxcvbnm0123456789'
for i in range(4): #默认从0开始,等价于range(0,4):包含0不包含4
ran=random.randint(1,len(s))
code+=s[ran-1]
print(code)2.查找、替换相关
1)find函数:从初始位置到结束位置查找字符串中的字符(串),默认查找整个字符串
2)rfind:返回从右往左找到的第一个指定字符的位置,编号仍从左往右
3)index:与find类似,区别在于:找不到时报异常
4)replace(old,new,[max]):将old替换成new,若max指定,则替换次数不超过max次
s1 = 'index lucy lucky goods'
result = 'R' in s1
print(result) # False
position = s1.find('R')
print(position) # 没找到返回-1
position = s1.find('l')
print(position) # 6 返回字母第一次出现的位置
p = s1.find('lu', position + 1) # 从指定开始位置往后找
print(p) # 11
p = s1.find('l', position + 1, len(s1)) # 从指定开始位置到结束位置进行查找
print(p) # 11
s2=s1.replace(' ','#',2)
print(s2) # index#lucy#lucky goods
#去除空格:
s3=s1.replace(' ','')
print(s3) # indexlucyluckygoods
案例1:去掉字符串中的元音字母
s1=input('请输入一个字符串:') # hello world
s2='aeiou'
# #法一:
result=''
for i in s1:
if i not in s2:
result+=i
print('去除元音字母后变为:',result) # hll wrld
# #法二:
for i in s1:
if i in s2:
s1=s1.replace(i,'')
print('去除元音字母后变为:',s1)
#法三:
for i in s2:
if i in s1:
s1=s1.replace(i,'')
print('去除元音字母后变为:',s1) # hll wrld案例2:提取网址中的文件名和文件扩展名 step1:用rfind函数找到网址中最后一个(文件名之前的)‘/’所在的位置 step2:用切片操作截取文件名 step3:用切片操作截取文件扩展名
url = 'https://www.baidu.com/img/logo1.jpg'
p1 = url.rfind('/')
filename = url[p1 + 1:]
print(filename) # logo1.jpg
p2 = url.rfind('.')
extension = url[p2 + 1:]
print(extension) # jpg
3.编码encode/解码decode:网络应用(中文一般会涉及编码问题)
msg='你好,世界!'
#gbk:中文 gb2312:简体中文 utf-8:国际通用
en_code=msg.encode('utf-8') # 编码格式缺省时默认为utf-8
print(en_code)
de_code=en_code.decode('utf-8') # 解码要和编码格式一致
print(de_code) # 你好,世界!4.判断开头结尾 startswith endswith:返回布尔类型的值
s='hello world'
print(s.startswith('H')) # 判断字符串是否以'H'开头: False 区分大小写
print(s.endswith('ld')) # 判断字符串是否以'ld'j4结尾:True5.判断字符串中字符是否为某种格式 ''' isalpha():若字符串不为空且所有字符都是字母则返回true isdigit():若字符串不为空且所有字符都是数字则返回true '''
s1='hello world'
s2='helloworld'
print(s1.isalpha()) # False
print(s2.isalpha()) # True
print(s2.isalnum()) # True
s3='1'
print(s3.isdigit())
6.连接 join(seq):连接字符,以指定字符作为分隔符,将seq中所有的元素合并为一个新的字符串
s1='hello world'
s2='helloworld'
print(s1.isalpha()) # False
print(s2.isalpha()) # True
print(s2.isalnum()) # True
s3='1'
print(s3.isdigit())
new_str='_'.join('abc') # 用’-‘将 ’abc‘连接构成一个新的字符串
print(new_str) # a_b_c
list=['a','b','c','d']
print(''.join(list)) # abcd
x = 'abc'
y = 'def'
z = ['d', 'e', 'f']
print(x.join(y)) # dabceabcf
print(x.join(z)) # dabceabcf
7.截断:截断字符串(从左右两侧) lstrip():截掉字符串左边的空格或指定字符 rstrip():截掉字符串右边的空格或指定字符 rstrip():截掉字符串左右两边的空格或指定字符
s=' all right '
s1=s.lstrip(' a')
print(s1) # 'll right '
s2=s.rstrip('t ')
print(s2) # ' all righ'
s3=s.strip()
print(s3) # 'all right'8.分割 split():用指定字符分割字符串,将分割后得到的各子串保存到列表中,默认指定字符串出现几次就切几次
s='hello world all right'
print(s.count(' ')) # 3
result=s.split(' ') # 用空格切割字符串
print(result) # ['hello', 'world', 'all', 'right']
result=s.split(' ',2) # 用空格切割字符串,两次
print(result) # ['hello', 'world', 'all right'](二)列表类型
1.序列与列表
序列是 Python 中最基本的数据结构。序列中的每个值都有对应的位置值,称之为索引,从 0开始。最常见的是列表和元组。序列都可以进行的操作包括索引,切片,加,乘,检查成员。
列表是最常用的 Python 数据类型,列表的数据项不需要具有相同的类型,只要把逗号分隔的不同的数据项使用方括号括起来即可创建一个列表。
列表:访问、截取、更新、添加、删除
# 列表:访问、截取、更新、添加、删除
list = ['a', 1, 1]
# 访问
print(list[0]) # a
# 截取
print(list[:2]) # ['a', 1]
print(list[-3]) # a
# 更新
list[2] = 2
print(list) # ['a', 1, 2]
# 添加
list.append('ball')
print(list) # ['a', 1, 2, 'ball']
# del删除
del list[0]
print(list) # [1, 2, 'ball']
案例:删除hp和mac品牌
# 案例:删除hp和mac品牌
brand = ['huawei', 'mac-1', 'mac-2', 'sony', 'hp']
l = len(brand)
i = 0
while i < l:
if 'hp' in brand[i] or 'mac' in brand[i]:
del brand[i]
l -= 1
else:
i += 1
print(brand) # ['huawei', 'sony']2.列表操作符

list1 = ['a', 1]
list2 = ['b', 2, 3]
# 拼接
print(list1 + list2) # ['a', 1, 'b', 2, 3]
# 重复
print(list1 * 3) # ['a', 1, 'a', 1, 'a', 1]3.嵌套列表:在列表里创建其它列表
# 列表的嵌套
l1 = ['a', 1]
l2 = ['b', 2]
list = [l1, l2]
print(list) # [['a', 1], ['b', 2]]4.列表list的函数与方法
len(list):返回列表元素个数
max(list):返回列表元素最大值
min(list):返回列表元素最小值
list(iterable):转换成列表类型,参数必须是可迭代的
list.append(obj):在列表末尾添加新的对象
list.count(obj):统计某个元素在列表中出现的次数
list.extend(seq):在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
list.insert(index, obj):将对象插入列表
list.pop([index=-1]):移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
list.remove(obj):移除列表中某个值的第一个匹配项,若不存在则报错
list.reverse():反向列表中元素
list.sort( key=None, reverse=False):对原列表进行排序
list.clear():清空列表
list.copy():复制列表
list.index(a):返回元素a的位置
list1 = [1, 2, 3]
print(len(list1)) # 3
print(max(list1)) # 3
print(min(list1)) # 1
print(list1.count(3)) # 1
#类型转换,转换成列表类型
s = 'abc'
print(list(s)) # ['a', 'b', 'c']
print(list(range(1, 10, 3))) # [1, 4, 7]
list2 = ['a', 'b']
# append(obj):在列表末尾添加新的对象
list1.append(list2)
print(list1) # [1, 2, 3, ['a', 'b']]
print(len(list1)) # 4
# extend(seq):在列表末尾一次性追加另一个序列中的多个值
list1.extend(list2)
print(list1) # [1, 2, 3, ['a', 'b'], 'a', 'b']
print(len(list1)) # 6
list1.insert(0, 2)
print(list1) # [2, 1, 2, 3, ['a', 'b'], 'a', 'b']
list1.pop()
print(list1) # [2, 1, 2, 3, ['a', 'b'], 'a']
list1.pop(-2)
print(list1) # [2, 1, 2, 3, 'a']
list1.remove(2)
print(list1) # [1, 2, 3, 'a']
list1.reverse()
print(list1) # ['a', 3, 2, 1]
'''
列表排序:list.sort( key=None, reverse=False)
reverse -- 排序规则,reverse = True 降序, reverse = False 升序(默认)。
key:指定一个函数,此函数只有一个参数且返回一个值用来进行比较
'''
# reverse的使用
list3 = ['hello', 'BOY', 'apple']
list3.sort(reverse=True)
print(list3) # ['hello', 'apple', 'BOY']
# key的使用
# 通过key指定的函数来忽略字符串的大小写:
list3.sort(key=str.lower)
print(list3) # ['apple', 'BOY', 'hello']
# 用复杂对象的某些值来对复杂对象的序列排序
student_tuples = [
('john', 'A', 15),
('jane', 'B', 12),
('dave', 'B', 10),
] # lambda:匿名函数 ,主体是一个表达式
student_tuples.sort(key=lambda student: student[2]) # sort by age
print(student_tuples) # [('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]
# 导入operator模块及itemgetter
import operator
from operator import itemgetter
student_tuples.sort(key=itemgetter(2), reverse=True)
print(student_tuples) # [('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]
# operator模块还允许多级的排序,例如,先以grade,然后再以age来排序:
student_tuples.sort(key=itemgetter(1, 2))
print(student_tuples) # [('john', 'A', 15), ('dave', 'B', 10), ('jane', 'B', 12)]
# 列表的比较
l1 = [1, 2]
l2 = [1, 2]
l3 = [1, 'a']
print('l1与l2是否相等:', operator.eq(l1, l2)) # True
print('l1与l3是否相等:', operator.eq(l1, l3)) # False
(三)元组类型
1.元组与列表的区别:
元组是 tuple类的类型,与列表list几乎一致。元组与列表的区别如下:
(1)元组数据使用圆括号()来表示,如 t=( 'a' , 'b', 'c' ,'d' ,'e','f')。
(2)若元组中只含有一个元素,元素后面要加一个逗号,否则等价于不加括号的元素类型
t1=()
print(type(t1)) # <class 'tuple'>
t2=("hello")
print(type(t2)) # <class 'str'>
t3=("hello",)
print(type(t3)) # <class 'tuple'>(3)元组数据的元素不能改变,只能读取。可以理解为元组就是只读的列表,除了不能改变外其他特性与列表完全一样。
2.元组中元素的查询
与列表的切片操作相同:
t4 = (1, 2, 3, 4, 5, 6)
print(t4[1]) # 2
print(t4[-2]) # 53.组包与拆包
组包:等号右边有多个数据时,会自动包装为元组
拆包:如果 变量数量 = 容器长度, 容器中的元素会一一对应赋值给变量
需要拆的数据的个数要与变量的个数相同,否则程序会异常
除了对元组拆包之外,还可以对列表、字典等拆包
应用1:交换变量的值
应用2:函数可以同时返回多个数
应用3:字典元素拆包
# 组包
result = 1, 2, 3
print(result) # (1, 2, 3)
print(type(result)) # <class 'tuple'>
# 拆包
a, b, c = (10, 20, 30)
print(b) # 20
t1 = (1, 2, 3, 4, 5)
a, *b, c = t1 # *b可表示任意多个(>=0)值
print(*b) # 2 3 4
print(b) # [2, 3, 4]
a, b, *c = t1
print(a, b, c) # 1 2 [3, 4, 5]
t2 = (1, 2)
a, b, *c = t2
print(a, b, c) # 1 2 []
# 应用1:交换变量的值
a, b = 1, 2
a, b = b, a # 先将b,a组包成(b,a),再将(b,a)拆包,分别赋值给a,b
print(a, b) # 2 1
# 应用2:函数可以同时返回多个数
def return_arg():
return 11, 22, 33
r1, r2, r3 = return_arg() # 返回值直接做拆包
print(r1, r2, r3) # 11 22 33
# 应用3:字典元素拆包
dict={'name': 'lucy'}
for element in dict.items():
print(element) #元组:('name', 'lucy')
key,value=element # 元组拆包
print(key,value) #name lucy(四)字典
1.字典的格式
1)符号:{}
2)关键字:dict,变量名不建议命名为 dict。
3)保存元素的形式为 key:value 元素之间用逗号分割
格式如下:dict1 = {key1 : value1, key2 : value2 }
字典可存储任意类型对象,键一般是唯一的,如果重复最后的一个键值对会替换前面的。值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组,不能是列表。
# # 空字典两种写法:
dict1 = {}
dict2 = dict() # 空列表:lis1t=list() 空元组tuple1=tuple()
# 非空字典
dict3 = {'id1': '37000000000000', 'name': 'lucy', 'age': '15'}
2.字典的增删改查
增加、修改的格式:dict[key]=value 若key之前出现过,则新的value会覆盖旧的value值
删除的格式
1.del dict[key]
2.dict.pop(key[,default]) :返回要删除的key:value对中的value值;若字典中没有找到key,则返回default,default通常为提示信息(没有找到key且没有default时会报错)
3.popitem():删除末尾键值对
4.clear:清空字典元素
查询的格式:dict[key] -->value
# 字典的增删改查
# 增加的格式:dict[key]=value
dict6 = {}
dict6['brand'] = 'huawei'
dict6['price'] = 8999
dict6['color'] = 'red'
print(dict6) # {'brand': 'huawei', 'price': 8999, 'color': 'red'}
# 修改的格式:dict[key]=value 若key之前出现过,则新的value会覆盖旧的value值
dict6['brand'] = 'mi'
print(dict6) # {'brand': 'mi', 'price': 8999, 'color': 'red'}
#查询的格式:dict[key] -->value
print(dict6['brand']) # mi
'''
删除的格式
1.del dict[key]
2.dict.pop(key[,default]) :返回要删除的key:value对中的value值;若字典中没有找到key,则返回default,default通常为提示信息(没有找到key且没有default时会报错)
3.popitem():删除末尾键值对
4.clear:清空字典元素
'''
del dict6['price']
print(dict6) # {'brand': 'mi', 'color': 'red'}
result=dict6.pop('color','没有找到对应属性')
print(dict6) # {'brand': 'mi'}
print(result) # red
result=dict6.pop('width','没有找到对应属性')
print(result) # 没有找到对应属性
dict6={'brand': 'huawei', 'price': 8999, 'color': 'red'}
result=dict6.popitem()
print (result) # ('color', 'red')
print (dict6) #{'brand': 'huawei', 'price': 8999}
dict6.clear()
print (dict6) #{}3.其他内置函数
dict1.update(dict2):将dict2添加到dict1中,若dict2中存在与dict1重名的 key,则dict1中对应的value值被dict2中的替换
#dict1.update(dict2):将dict2添加到dict1中,若dict2中存在与dict1重名的 key,则dict1中对应的value值被dict2中的替换
dict6={'brand': 'huawei', 'color': 'red'}
dict7={'brand':'apple','width':12}
dict6.update(dict7)
print(dict6)#{'brand': 'apple', 'color': 'red', 'width': 12}dict.fromkeys(seq[,default]):将seq转换成字典的表达形式,每个元素都作为 key,seq可以是列表、元组、字典、字符串等,如果没有指定默认的value,默认为none
list=['lily','joe','amada']
new_dict=dict.fromkeys(list,20)
print(new_dict) #{'lily': 20, 'joe': 20, 'amada': 20}4.字典的遍历
# 遍历字典
stu={'lucy': 89, 'joe': 90, 'lisa': 98}
print(stu)
for value in stu:
print(value) # 遍历一个变量的结果是遍历key:lucy joe lisa
# items():把字典转换成列表里面包含元组的形式
print(stu.items()) # dict_items([('lucy', 89), ('joe', 90), ('lisa', 98)])
# 遍历items列表
for i in stu.items():
print(i)
'''
结果:
('lucy', 89)
('joe', 90)
('lisa', 98)
'''
for key,value in stu.items():
print(key,value)
'''
结果:
lucy 89
joe 90
lisa 98
'''案例:将用户注册信息保存到字典中
'''
username
password
email
phone
'''
database=[]
while True:
print('欢迎注册')
username = input("请输入用户名:")
password = input("请输入密码:")
repassword = input("请确认密码:")
if password != repassword:
print("两次输入的密码不一致!注册失败!")
continue
email = input("请输入邮箱地址:")
phone = input("请输入联系电话:")
user={}
user['username']=username
user['password']=password
user['email']=email
user['phone']=phone
print("注册成功!")
print(user)
database.append(user)
answewr=input("是否继续注册(y/n)?")
if answewr=='n':
break
print(database)(五)类型转换
1.type()函数:用来得到变量的类型。
2.isinstance()函数:用来确定变量的类型。这个函数有两个参数﹐第一个参数是待确定类型的数据,第二个参数是指定一个数据类型。isinstance()会根据两个参数返回一个布尔类型的值﹐True表示类型一致﹐False表示类型不一致。
a='hello'
print(type(a)) # <class 'str'>
print(isinstance(a,str)) # True3.float可以转换为int,字符串类型 ‘3’也可以转化成int类型,但 ‘3.5’不能转成int类型。
4.布尔类型和其他类型都可以互相转换 只有变量为0或空字符串时,转换为布尔类型是False,其余情况都是True。
5.list(tuple):类型转换,将元组类型转换为列表
6.tuple(list):列表转换为元组
# 元组转为列表
t = (1, 2, 3, 4)
print(list(t)) # [1, 2, 3, 4]
# 列表转换为元组
l = ["hello"]
print(tuple(l)) # ('hello',)7. 元组/列表转字典
# 元组/列表转字典的前提:元素成对出现
dict4 = dict((('name', 'lucy'), ('age', 18)))
dict5 = dict([('name', 'lucy')])
print(dict4) # {'name': 'lucy', 'age': 18}
print(dict5) # {'name': 'lucy'}8.字典转换成列表里面包含元组的形式
stu={'lucy': 89, 'joe': 90, 'lisa': 98}
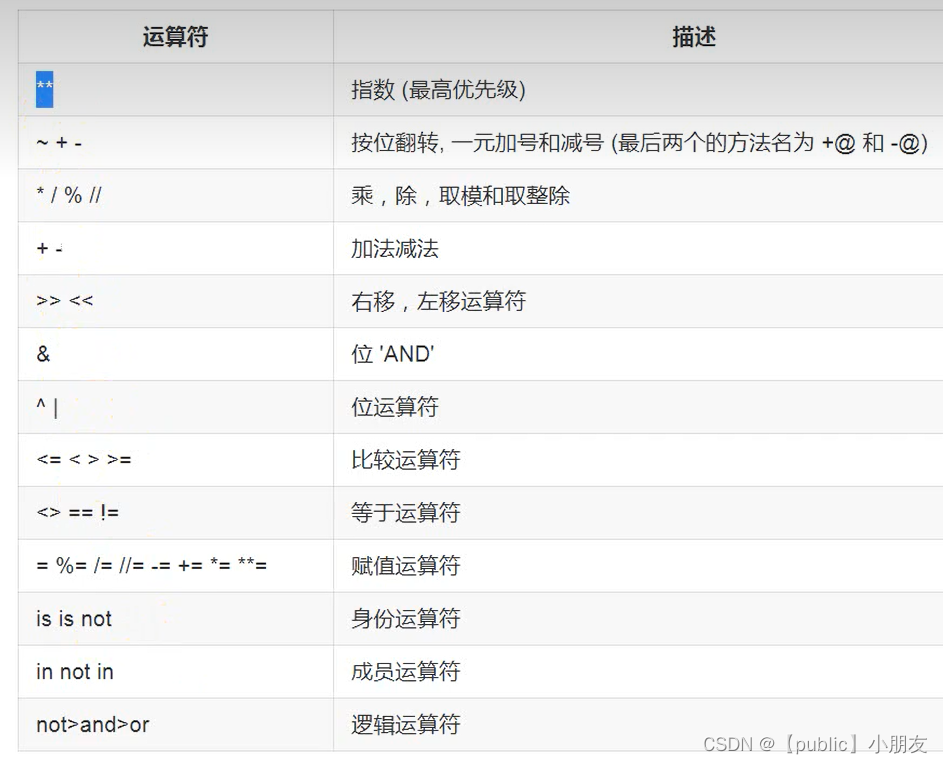
print(stu.items()) # dict_items([('lucy', 89), ('joe', 90), ('lisa', 98)])三、运算符及优先级
1.
/:除号 //:整除 m**n: m的n次方
* 乘号 还可以表示字符串的重复次数,例如‘8’*10的结果为88888888
2.比较运算符:例如判断变量a是否在10到20之间可以写成 print(10<=a<=20)
3.逻辑运算符;
1)and
print(a and b):若a或b为0,输出0,若都不为0,输出后面位置的值,即b的值
2)or
print(a or b):若a和b都为0,输出0;否则输出第一个不为0 的值
3)not
not a:若bool(a)为True,结果为False
4.运算符优先级















 6932
6932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









