







 本文详细介绍了监督学习中的回归与分类任务,包括线性回归、梯度下降法在logistic回归中的应用,以及向量化技术的意义。通过实例阐述了损失函数和代价函数的概念,并讨论了学习率对优化过程的影响。
本文详细介绍了监督学习中的回归与分类任务,包括线性回归、梯度下降法在logistic回归中的应用,以及向量化技术的意义。通过实例阐述了损失函数和代价函数的概念,并讨论了学习率对优化过程的影响。
监督学习的两个任务:回归与分类
回归:预测一个具体的数值输出
分类:预测离散的输出
目录
一、符号表示
m:训练样本的数量
x:输入特征
y:输出变量(要预测的目标变量),真实值
(x,y)表示一个训练样本
表示第i个训练样本
二、二分类算法
在识别一幅图像中是否有猫时,输出的结果有两种:有(用1表示),无(用0表示)。
假如图像大小为64*64*3=12288,
定义输入特征 ,
是一个
=12288维的向量,
,输出变量
m个训练样本集:
令输入特征为
输出为
三、线性回归
表达式:
参数 、
该如何选择呢?
定义一个代价函数:
也称平方误差函数,使函数最小化,得到最优的参数 、
的值
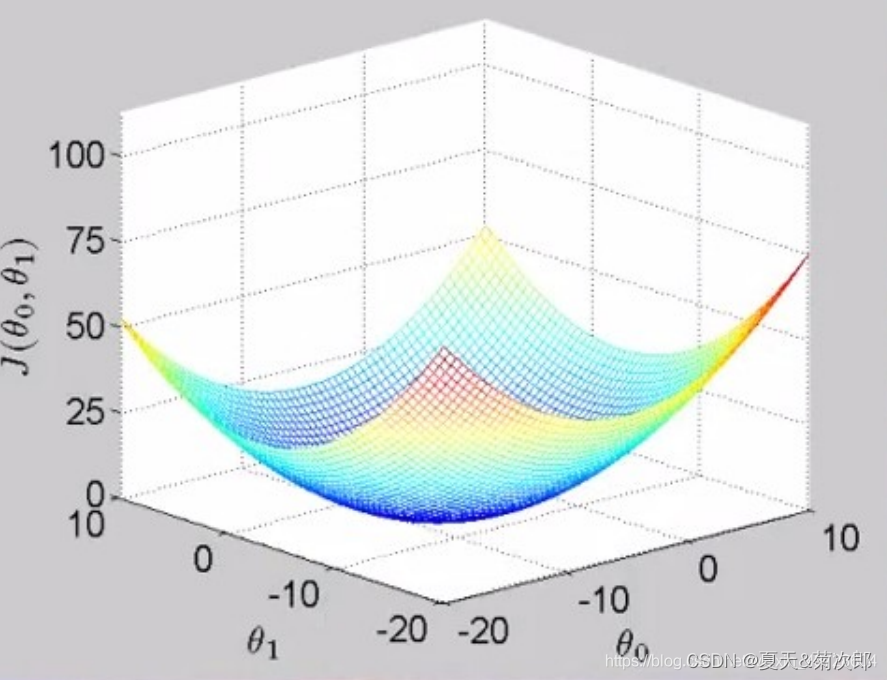
等高线:
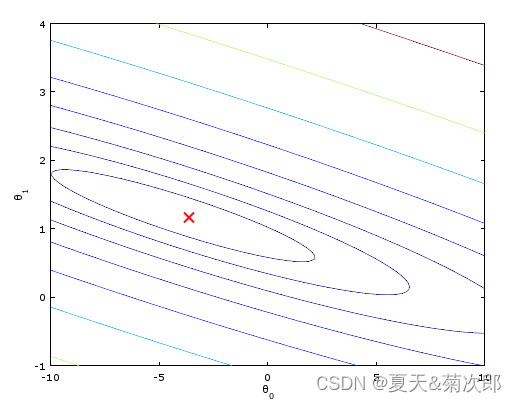
怎么最小化代价函数 呢?
四、梯度下降法
重复以下过程直到收敛:
为保证所有参数同步更新,采用如下办法:
其中 代表学习率,介于0-1之间, 控制着步长,
值的选取很重要。当
太小时,如下左图,每次只能移动一点点,需要很多步才能找到局部最低点,当
太大时,如下右图,可能会越过局部最低点,甚至可能离最低点越来越远,导致无法收敛。
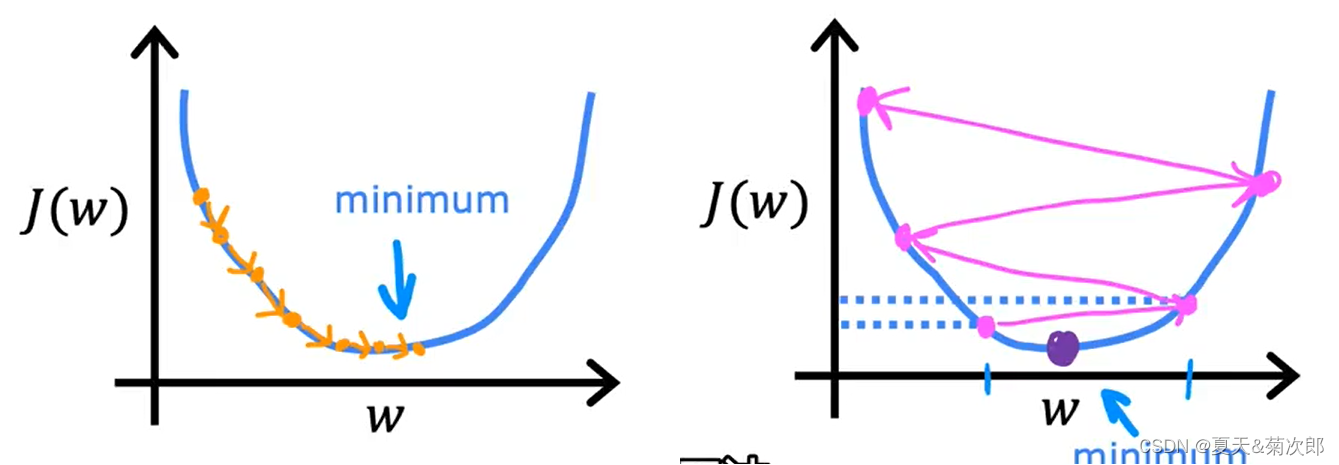
注意,当逐步接近最小值点时,导数值会逐步变小,因此移动的步幅也会变小
五、logistic回归
给定 x,预测值
参数:
输出: (令
)
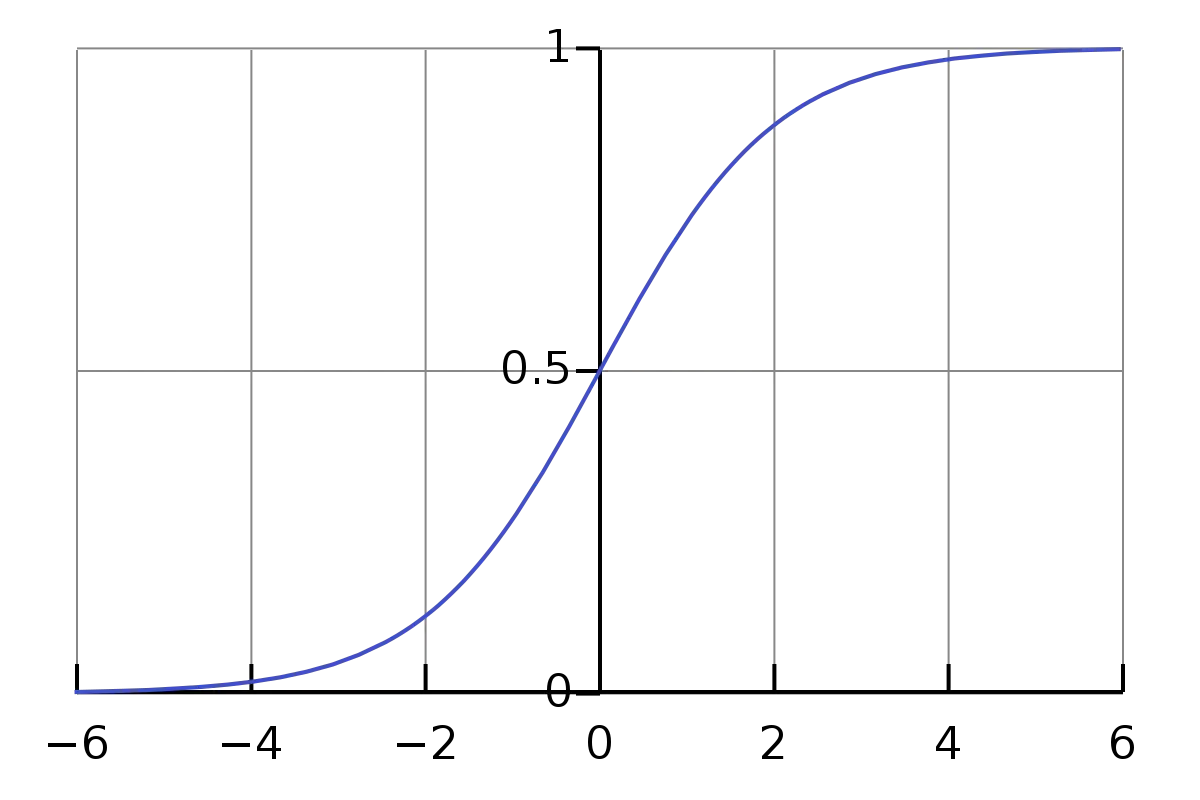
函数的作用是为了保证
在0-1之间,
函数图像如下图所示:
logistic回归的任务:通过代价函数,优化
(一)logistic回归的损失函数与代价函数
1.损失函数(误差函数)
当y=1时, ,L 越小,
越大,越接近y(=1)
当y=0时, ,L 越小,
越小,越接近y(=0)
注:损失函数是在单个训练样本中定义的,是凸函数,可以用梯度下降法进行优化。
2.代价函数(成本函数)
代价函数是在整个训练集上定义的,用来衡量在所有样本上的表现
(二)logistic回归中的梯度下降法
1.单样本、两个输入特征的情况
正向过程:
反向传播:
更新w1,w2,b:
2.m个样本、nx个输入特征的情况的情况
初始化:
一次梯度下降:
For i=1 to m :
六、向量化
向量化的意义
,向量a与b相乘
method 1:for循环
a=[1,2,3]
b=[4,5,6]
c=0
for i in range(3):
c+=a[i]*b[i]
print cmethod 2:内置函数np.dot(a,b)
import numpy as np
a=[1,2,3]
b=[4,5,6]
c=np.dot(a,b)使用内置函数计算比for循环速度快得多,因此在设计新网络时,或只是回归时尽量避免使用for循环。















 896
896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









