









1、distribute by [sort by] 或cluster by 优化数据倾斜
数据倾斜排查过程:
1、原始sql 如下:
select *
from jour
join spc on spc.id=jour.parent_id
left join spcadmin on spc.rect_id=spcadmin.rect_id and to_date(jour.create_time) =to_date(spcadmin.dt_date)
left join person on person.id = jour.modify_user_id
where 1 = 1
and jour.deleted='false'
;
2、map 端出现数据倾斜
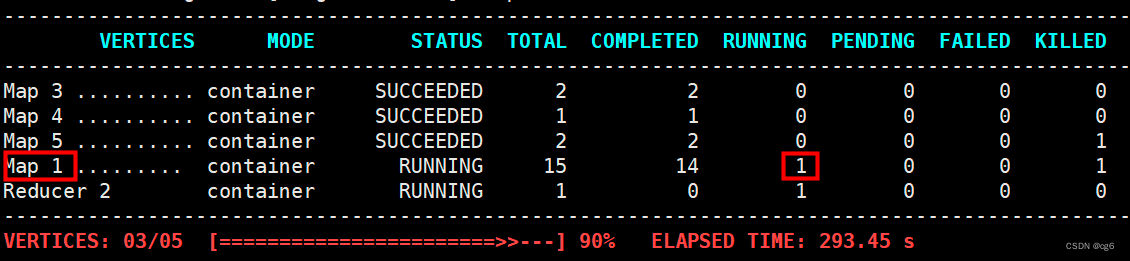
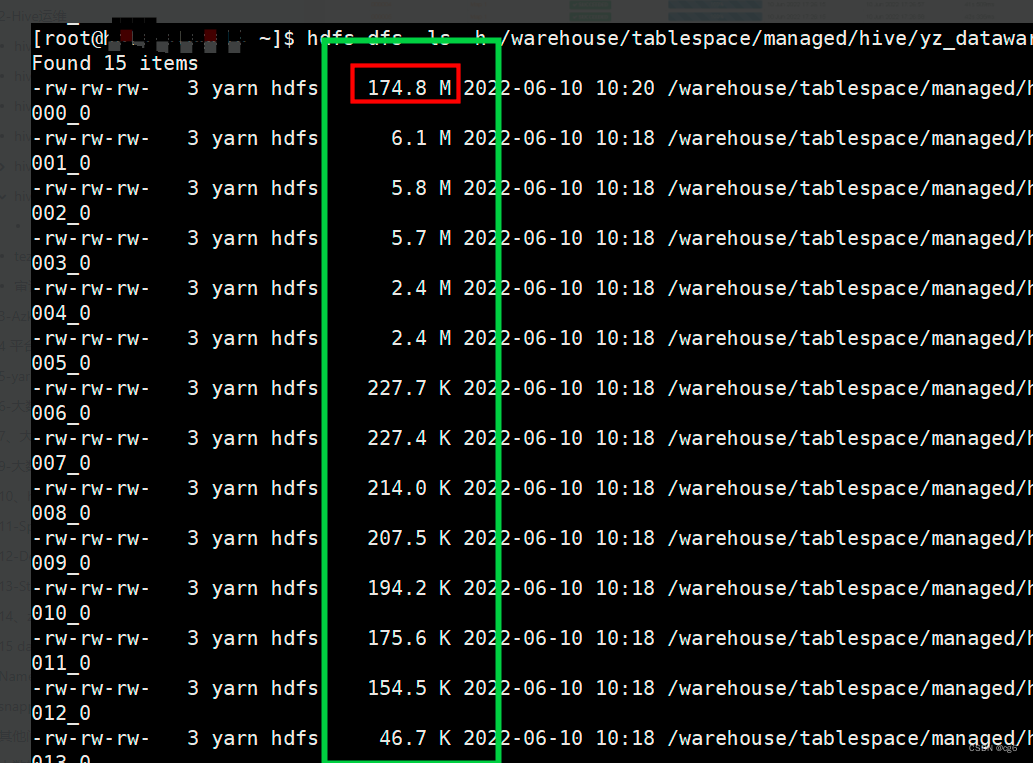
3、大表数据文件分布情况,数据文件分布不均匀,如下图所示
 4、spc表是事务表,严重影响关联查询性能,删表重新创建为非事务表
4、spc表是事务表,严重影响关联查询性能,删表重新创建为非事务表
注意:不需要表为事务表才能修改事务表为内部或外部表
5、创建临时表并对数据进行随机分发
set mapred.reduce.tasks=10; -- 输出10和分布均匀的数据文件
drop table if exists A_tmp;
create table if not exists A_tmp as
select
id,
create_user_id ,
create_time ,
modify_user_id,
modify_time,
tenant_id,
parent_id,
bind_id ,
operation_type,
`type`,
object_type
from A
where deleted='false'
distribute by rand(123)
;
数据重新分发后的数据分布,如下图
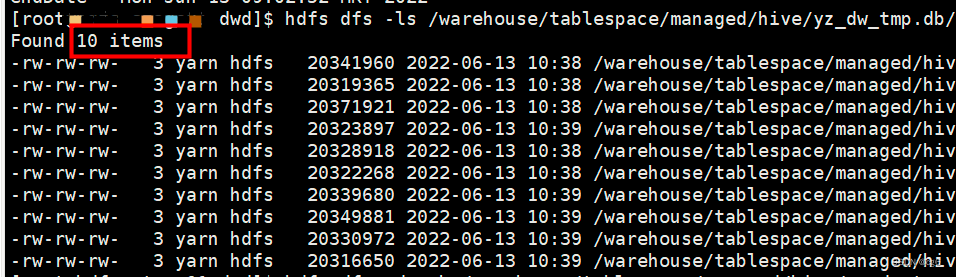
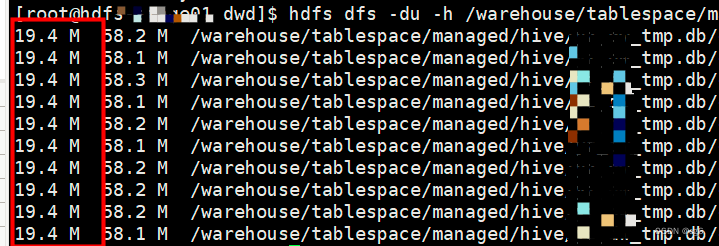
优化sql如下:
set mapred.reduce.tasks=10; -- 输出10和分布均匀的数据文件
drop table if exists A_tmp;
create table if not exists A_tmp as
select
id,
create_user_id ,
create_time ,
modify_user_id,
modify_time,
tenant_id,
parent_id,
bind_id ,
operation_type,
`type`,
object_type
from jour
where deleted='false'
distribute by rand(123)
;
select *
from spc
join jour on spc.id=jour.parent_id
left join spcadmin on spc.rect_id=spcadmin.rect_id and to_date(jour.create_time) =to_date(spcadmin.dt_date)
left join person on person.id = jour.modify_user_id
;
或优化sql如下:
set mapred.reduce.tasks=10;
select *
from spc
join (
select *
from jour
where deleted='false'
distribute by id
)jour on spc.id=jour.parent_id
left join spcadmin on spc.rect_id=spcadmin.rect_id and to_date(jour.create_time) =to_date(spcadmin.dt_date)
left join person on person.id = jour.modify_user_id
;
DAG执行图
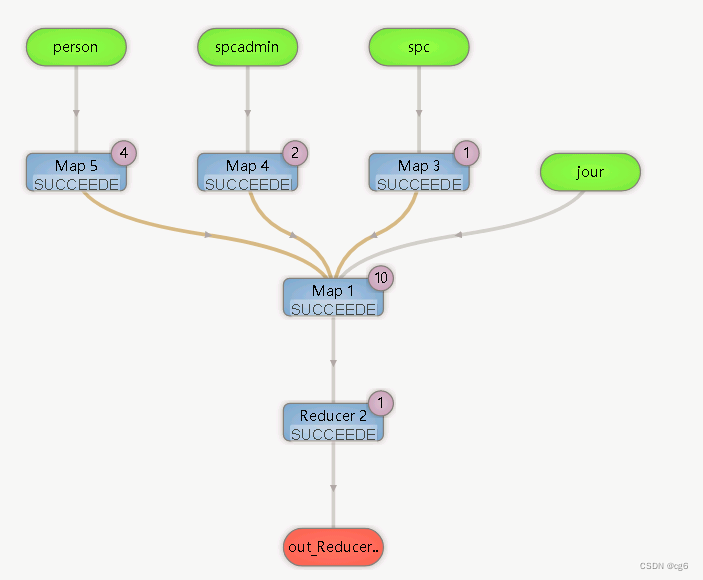
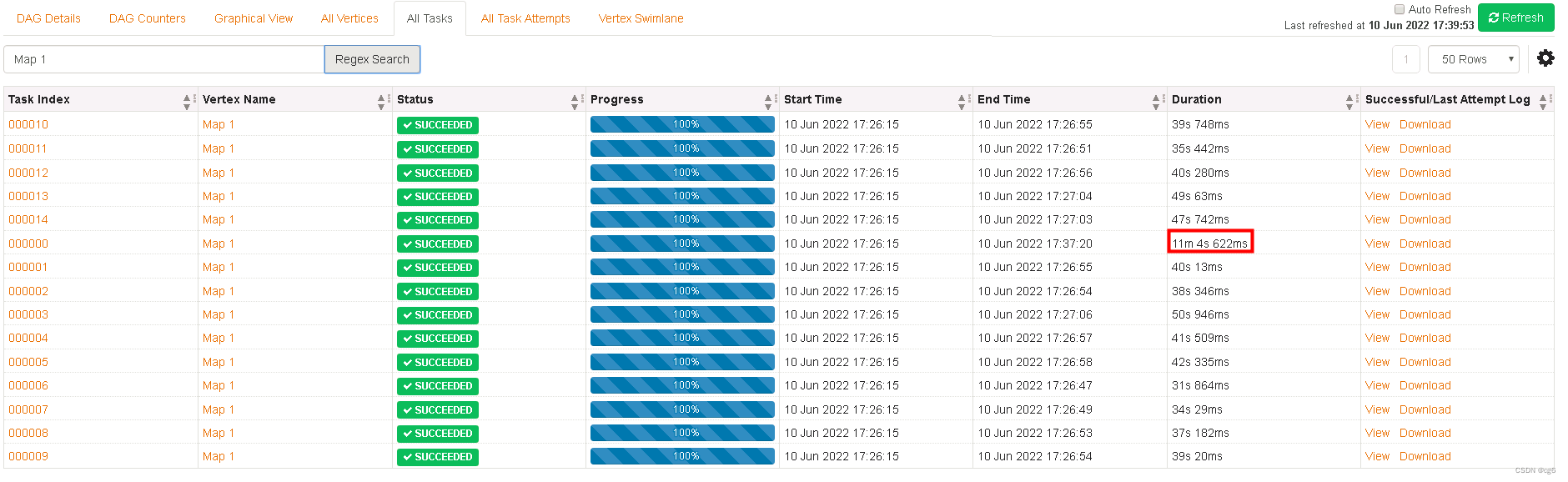
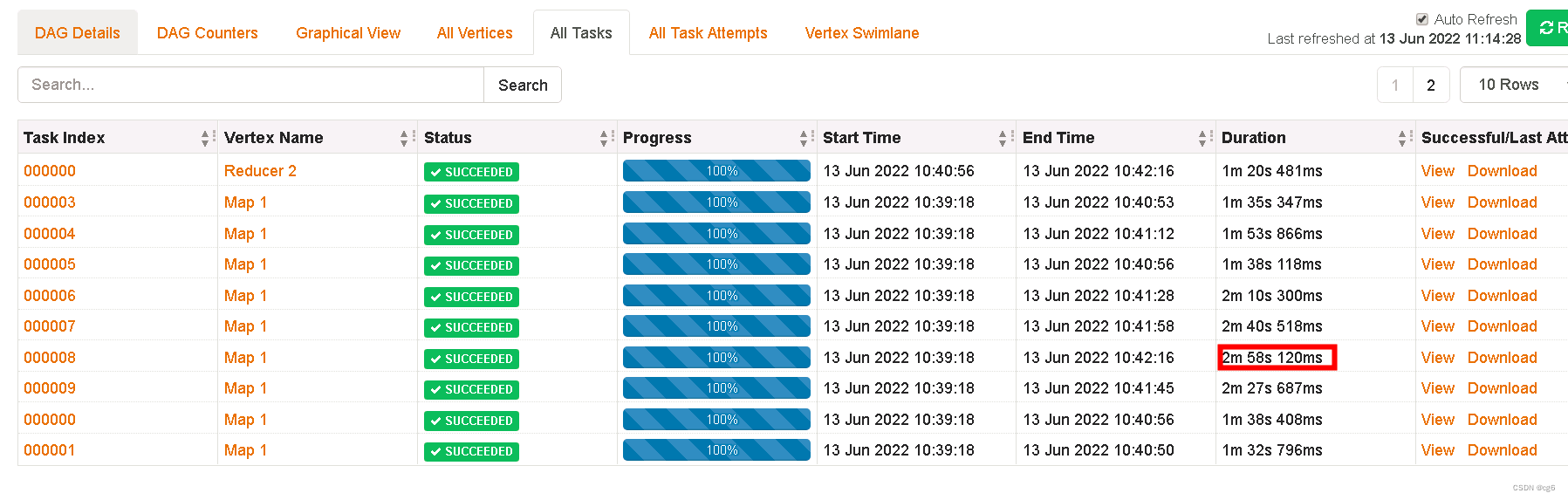
6、执行性能从11min -> 5min 的变化(最优执行时间3min)
优化前:
 优化后:
优化后:















 543
543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









