







flink 1.13.2 自定义实现KeyedSerializationSchema或TypeInformationKeyValueSerializationSchema - 写多 topic和动态新增cdc表
pom.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>flink_using</artifactId>
<groupId>org.example</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>flinkStreamSql</artifactId>
<url>http://maven.apache.org</url>
<properties>
<flink.version>1.13.2</flink.version>
<connector.kafka.version>1.13.2</connector.kafka.version>
<cdc.version>2.2.1</cdc.version>
<scala.version>2.11</scala.version>
<kafka.version>2.4.0</kafka.version>
<redis.version>3.3.0</redis.version>
<lombok.version>1.18.6</lombok.version>
<fastjson.verson>1.2.72</fastjson.verson>
<jdk.version>1.8</jdk.version>
<version.debezium>1.9.5.Final</version.debezium>
</properties>
<dependencies>
<!-- flink table-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table</artifactId>
<version>${flink.version}</version>
<type>pom</type>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.version}</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<!--table planner-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.version}</artifactId>
<version>${flink.version}</version>
<!-- <scope>仅限于flink 13版本及以下,flink14要注释掉</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.12</artifactId>
<version>1.11.6</version>
<exclusions>
<exclusion>
<groupId>log4j</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-postgres-cdc</artifactId>
<version>${cdc.version}</version>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-debezium</artifactId>
<version>${cdc.version}</version>
</dependency>
<!-- debezium engine -->
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-api</artifactId>
<version>${version.debezium}</version>
</dependency>
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-core</artifactId>
<version>${version.debezium}</version>
</dependency>
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-connector-postgres</artifactId>
<version>${version.debezium}</version>
</dependency>
<dependency>
<groupId>org.rocksdb</groupId>
<artifactId>rocksdbjni</artifactId>
<version>7.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.12.0</version>
</dependency>
</dependencies>
<build>
<finalName>
flink-XXX
</finalName>
<resources>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.sql</include>
</includes>
<filtering>false</filtering>
</resource>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.sql</include>
<include>**/*.json</include>
<include>**/*.config</include>
</includes>
<filtering>false</filtering>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
<compilerArgs>
<arg>-extdirs</arg>
<arg>${project.basedir}/jar</arg>
</compilerArgs>
</configuration>
</plugin>
<!-- 配置依赖包 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<!-- 将依赖包打包至target下的lib目录 -->
<outputDirectory>${project.build.directory}/lib</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
自定义实现KeyedSerializationSchema
主类代码
package flinkCDCTest;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.contrib.streaming.state.EmbeddedRocksDBStateBackend;
import org.apache.flink.contrib.streaming.state.PredefinedOptions;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import com.ververica.cdc.connectors.postgres.PostgreSQLSource;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import java.util.Properties;
public class CDCPostgreSinkToKafka {
// checkpoint 存储路径
private static String checkpointPath = "";
private static String serviceId = "";
// 是否开启checkpoint
private static boolean enableCheckpoint = true;
// checkpoint 时间间隔
private static long checkpointInterval = 2 * 60 * 1000;
// checkpoint 超时时间
private static long checkpointTimeout = 60 * 1000L;
// 失败容忍次数
private static int failureNum = 2;
public static void main(String[] args) throws Exception {
String tableList = args[0];
// String tableList = "t1,t2";
Properties prop = new Properties();
prop.put("bootstrap.servers","kafka-hostname:端口,kafka-hostname:端口,kafka-hostname:端口");
// kafka开启了sasl才需要配置
// prop.put("security.protocol","SASL_PLAINTEXT");
// prop.put("sasl.mechanism","PLAIN");
// prop.put("sasl.jaas.config","org.apache.kafka.common.security.plain.PlainLoginModule required username=username password=pwd;");
FlinkKafkaProducer<String> kafkaProducer = new FlinkKafkaProducer<>(
"topic_error", // topic 为 null , 就转发到此topic
new UDFTopicSchema(), // 自定义分发到不同topic
prop);
SourceFunction<String> sourceFunction = PostgreSQLSource.<String>builder()
.hostname("localhost")
.port(端口)
.database("") // monitor postgres database
.schemaList("") // monitor inventory schema
.tableList(tableList) // monitor products table
.username("")
.password("")
.slotName("")
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> streamSource = env.addSource(sourceFunction);
streamSource.addSink(kafkaProducer);
// 是否启动checkpoint
if(enableCheckpoint){
// 开启checkpoint , 同时设置 checkpoint 配置项
getCheckpointConfig(env, checkpointInterval , checkpointTimeout , failureNum);
// 设置checkpoint后端,设置 checkpoint 路径
setCheckpointStateBackend(env);
}
env.execute();
}
/**
* 设置checkpoint配置项
* @param env
* @param checkpointInterval
* @param checkpointTimeout
* @param failureNum
*/
public static void getCheckpointConfig(StreamExecutionEnvironment env , long checkpointInterval , long checkpointTimeout , int failureNum) {
// 开启checkpoint , 每 checkpointInterval 时间开始一次 checkpoint
env.enableCheckpointing(checkpointInterval);
// 高级选项设置
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 确认 checkpoints 之间的时间会进行 500 ms
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// Checkpoint 必须在一分钟内完成,否则就会被抛弃
env.getCheckpointConfig().setCheckpointTimeout(checkpointTimeout);
// 失败容忍次数
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(failureNum);
// 同一时间只允许一个 checkpoint 进行
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
}
/**
* 设置checkpoint
* @param env
*/
private static void setCheckpointStateBackend(StreamExecutionEnvironment env) {
String osName = System.getProperty("os.name");
String checkpointDataUrl = hdfs://" + serviceId + checkpointDir;
System.out.println("checkpointDataUrl : " + checkpointDataUrl);
if(!osName.toLowerCase().startsWith("win")){
checkpointDataUrl = "hdfs://XXXXX";
// 当外部传入checkpoint 路径,使用外部传入的路径
if(StringUtils.isNotEmpty(checkpointPath)){
checkpointDataUrl = checkpointPath;
}
System.out.println("checkpointDataUrl:" + checkpointDataUrl);
EmbeddedRocksDBStateBackend rocksDBStateBackend = new EmbeddedRocksDBStateBackend(true);
rocksDBStateBackend.setPredefinedOptions(PredefinedOptions.SPINNING_DISK_OPTIMIZED_HIGH_MEM);
env.setStateBackend(rocksDBStateBackend);
env.getCheckpointConfig().setCheckpointStorage(checkpointDataUrl);
}else{
EmbeddedRocksDBStateBackend rocksDBStateBackend = new EmbeddedRocksDBStateBackend(true);
rocksDBStateBackend.setPredefinedOptions(PredefinedOptions.SPINNING_DISK_OPTIMIZED_HIGH_MEM);
env.setStateBackend(rocksDBStateBackend);
env.getCheckpointConfig().setCheckpointStorage("file:///D:/flinkTest/checkpoints/" + "flinktest");
}
}
}
自定义实现:KeyedSerializationSchema【高版本已废弃】
package flinkCDCTest;
import com.alibaba.fastjson.JSON;
import org.apache.flink.streaming.util.serialization.KeyedSerializationSchema;
public class UDFTopicSchema implements KeyedSerializationSchema<String> {
/**
* 写入kafka的key字段
* @param value
* @return
*/
@Override
public byte[] serializeKey(String value) {
String after = JSON.parseObject(value).getString("after");
String id = JSON.parseObject(after).getString("id");
return id.getBytes();
}
/**
* 写入kafka的value字段
* @param value
* @return
*/
@Override
public byte[] serializeValue(String value) {
return value.getBytes();
}
/**
* 从业务记录中提取分发的topic
* @param value
* @return
*/
@Override
public String getTargetTopic(String value) {
String source = JSON.parseObject(value).getString("source");
String db = JSON.parseObject(source).getString("db");
String schema = JSON.parseObject(source).getString("schema");
String table = JSON.parseObject(source).getString("table");
// yz.bigdata.test_bizcenter_hmc.test_bizcenter_hmc.hmc_org
String topic_name = "xxx." + db + "." + schema + "." + table + "_test";
return topic_name;
}
}
自定义实现:TypeInformationKeyValueSerializationSchema
主类代码
备注:与上面的主类代码有很多雷同
package flinkCDCTest;
import com.alibaba.fastjson.JSONObject;
import com.ververica.cdc.debezium.DebeziumDeserializationSchema;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.api.common.ExecutionConfig;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.contrib.streaming.state.EmbeddedRocksDBStateBackend;
import org.apache.flink.contrib.streaming.state.PredefinedOptions;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import com.ververica.cdc.connectors.postgres.PostgreSQLSource;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer011;
import java.util.Properties;
public class CDCPostgreSinkToKafka {
// checkpoint 存储路径
private static String checkpointPath = "";
private static String serviceId = "";
// 是否开启checkpoint
private static boolean enableCheckpoint = true;
// checkpoint 时间间隔
private static long checkpointInterval = 1 * 60 * 1000;
// checkpoint 超时时间
private static long checkpointTimeout = 60 * 1000L;
// 失败容忍次数
private static int failureNum = 2;
public static void main(String[] args) throws Exception {
String tableList = args[0];
Properties prop = new Properties();
prop.put("bootstrap.servers","host:post");
prop.put("security.protocol","SASL_PLAINTEXT");
prop.put("sasl.mechanism","PLAIN");
prop.put("sasl.jaas.config","XXX");
SourceFunction<Tuple2<String, JSONObject>> sourceFunction = PostgreSQLSource.builder()
.hostname("localhost")
.port(XXX)
.database("XXX") // monitor postgres database
.schemaList("XXX") // monitor inventory schema
.tableList(tableList) // monitor products table
.username("XXX")
.password("XXX")
// .deserializer(new JsonDebeziumDeserializationSchema()) // converts SourceRecord to JSON String
.slotName("test_bizcenter_hmc_hmc_org")
.deserializer((DebeziumDeserializationSchema)new UdfDebeziumDeserializationSchema()) // converts SourceRecord to Map<Object,Object>
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Tuple2<String, JSONObject>> streamSource = env.addSource(sourceFunction);
streamSource.print("source >>>>>>");
FlinkKafkaProducer011<Tuple2<String, JSONObject>> kafkaProducer011 = new FlinkKafkaProducer011<>(
"topic",
new CustomProducerSchema(String.class, JSONObject.class, new ExecutionConfig()),
prop
);
streamSource.addSink(kafkaProducer011);
// 是否启动checkpoint
if(enableCheckpoint){
// 开启checkpoint , 同时设置 checkpoint 配置项
getCheckpointConfig(env, checkpointInterval , checkpointTimeout , failureNum);
// 设置checkpoint后端,设置 checkpoint 路径
setCheckpointStateBackend(env);
}
env.execute();
}
/**
* 设置checkpoint配置项
* @param env
* @param checkpointInterval
* @param checkpointTimeout
* @param failureNum
*/
public static void getCheckpointConfig(StreamExecutionEnvironment env , long checkpointInterval , long checkpointTimeout , int failureNum) {
// 开启checkpoint , 每 checkpointInterval 时间开始一次 checkpoint
env.enableCheckpointing(checkpointInterval);
// 高级选项设置
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 确认 checkpoints 之间的时间会进行 500 ms
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// Checkpoint 必须在一分钟内完成,否则就会被抛弃
env.getCheckpointConfig().setCheckpointTimeout(checkpointTimeout);
// 失败容忍次数
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(failureNum);
// 同一时间只允许一个 checkpoint 进行
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
}
/**
* 设置checkpoint
* @param env
*/
private static void setCheckpointStateBackend(StreamExecutionEnvironment env) {
String osName = System.getProperty("os.name");
// String checkpointDir = "/flink-checkpoints/";
String checkpointDataUrl = ""; // "hdfs://" + "XXX";
System.out.println("checkpointDataUrl : " + checkpointDataUrl);
if(!osName.toLowerCase().startsWith("win")){
checkpointDataUrl = "hdfs://XXX";
// 当外部传入checkpoint 路径,使用外部传入的路径
if(StringUtils.isNotEmpty(checkpointPath)){
checkpointDataUrl = checkpointPath;
}
System.out.println("checkpointDataUrl:" + checkpointDataUrl);
EmbeddedRocksDBStateBackend rocksDBStateBackend = new EmbeddedRocksDBStateBackend(true);
rocksDBStateBackend.setPredefinedOptions(PredefinedOptions.SPINNING_DISK_OPTIMIZED_HIGH_MEM);
env.setStateBackend(rocksDBStateBackend);
env.getCheckpointConfig().setCheckpointStorage(checkpointDataUrl);
}else{
EmbeddedRocksDBStateBackend rocksDBStateBackend = new EmbeddedRocksDBStateBackend(true);
rocksDBStateBackend.setPredefinedOptions(PredefinedOptions.SPINNING_DISK_OPTIMIZED_HIGH_MEM);
// HashMapStateBackend hashMapStateBackend = new HashMapStateBackend();
env.setStateBackend(rocksDBStateBackend);
env.getCheckpointConfig().setCheckpointStorage("file:///D:XXX");
}
}
}
自定义实现TypeInformationKeyValueSerializationSchema
备注:实现写入kafka的多个topic
package flinkCDCTest;
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.api.common.ExecutionConfig;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.util.serialization.TypeInformationKeyValueSerializationSchema;
public class CustomProducerSchema extends TypeInformationKeyValueSerializationSchema<String, JSONObject> {
public CustomProducerSchema(Class<String> keyClass, Class<JSONObject> valueClass, ExecutionConfig config) {
super(keyClass, valueClass, config);
}
@Override
public byte[] serializeKey(Tuple2<String, JSONObject> element) {
return element.f0.getBytes();
}
@Override
public byte[] serializeValue(Tuple2<String, JSONObject> element) {
return element.f1.get("value").toString().getBytes();
}
@Override
public String getTargetTopic(Tuple2<String, JSONObject> element) {
String topic = element.f1.get("topic");
System.out.println(">>>>>> topic : " + topic);
return topic != null ? topic : "topic_error";
}
}
cdc 记录格式化代码
package flinkCDCTest;
import com.alibaba.fastjson.JSONObject;
import com.ververica.cdc.debezium.DebeziumDeserializationSchema;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.source.SourceRecord;
import java.util.Map;
public class UdfDebeziumDeserializationSchema implements DebeziumDeserializationSchema<Tuple2<String, JSONObject>> {
@Override
public void deserialize(SourceRecord sourceRecord, Collector<Tuple2<String, JSONObject>> out) throws Exception{
try{
Tuple2<String, JSONObject> jsonObject = StringUtils.getJsonObjectTuple2(sourceRecord);
System.out.println(">>>>>> jsonObject : " + jsonObject);
// map.put(topic,jsonObject);
out.collect(jsonObject);
}catch (Exception e){
System.out.println(e.getMessage());
System.out.println("Deserialize throws exception:");
}
}
@Override
public TypeInformation getProducedType() {
return BasicTypeInfo.of(Map.class);
}
}
cdc 记录格式化转换为json工具类代码
package flinkCDCTest;
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;
import java.util.List;
public class StringUtils {
public static Tuple2<String,JSONObject> getJsonObjectTuple2(SourceRecord sourceRecord) {
// 获取topic、记录的主键
String topic = sourceRecord.topic();
Struct keyStruc = (Struct)sourceRecord.key();
Struct valueStruct = (Struct)sourceRecord.value();
// 获取key - value
String id = keyStruc.get("id").toString();
String op = valueStruct.get("op").toString();
String ts_ms = valueStruct.get("ts_ms").toString();
JSONObject beforeObject = getTypeJsonObject("before", valueStruct);
JSONObject afterObject = getTypeJsonObject("after", valueStruct);
JSONObject sourceObject = getTypeJsonObject("source", valueStruct);
// 组装kafka消息样式
JSONObject jsonValue = getJsonValue(op, ts_ms, beforeObject, afterObject, sourceObject);
JSONObject jsonObject = getJsonObject(topic, id, jsonValue);
return new Tuple2<>(id,jsonObject);
}
private static JSONObject getJsonObject(String topic, String id, JSONObject jsonValue) {
JSONObject jsonObject = new JSONObject();
jsonObject.put("topic",topic);
jsonObject.put("key", id);
jsonObject.put("value" , jsonValue);
return jsonObject;
}
private static JSONObject getJsonValue(String op, String ts_ms, JSONObject beforeObject, JSONObject afterObject, JSONObject sourceObject) {
JSONObject jsonValue = new JSONObject();
jsonValue.put("before", beforeObject != null ? beforeObject : null);
jsonValue.put("after",afterObject);
jsonValue.put("source",sourceObject);
jsonValue.put("op",op);
jsonValue.put("ts_ms",ts_ms);
return jsonValue;
}
private static JSONObject getTypeJsonObject(String type, Struct valueStruct) {
Struct typeStruct = valueStruct.getStruct(type);
JSONObject typeObject = new JSONObject();
String name;
Object value;
if (typeStruct != null) {
List<Field> afterFields = typeStruct.schema().fields();
for (Field field : afterFields) {
name = field.name();
value = typeStruct.get(name);
typeObject.put(name, value);
}
}
return typeObject;
}
}
程序启动脚本
#!/bin/bash
source /etc/profile
export HADOOP_CLASSPATH=$(hadoop classpath)
#flink路径及版本
path="xxx"
flink_version="flink-1.13.2"
#发版日期及sql路径
version="xxx"
yarn_name="flinkCDCTest""_${version}"
tableList="t1,t2"
checkpoint="-s checkpoint路径"
#内存配置及运行队列,并发度
yjm=1024
ytm=2048
qu=flink
ys=1
p=1
${path}${flink_version}/bin/flink run -m yarn-cluster -ys $ys -p $p -ynm ${yarn_name} $checkpoint -yjm $yjm -ytm $ytm -yqu $qu -c flinkCDCTest.CDCPostgreSinkToKafka "../flink-xxx-1.0-SNAPSHOT"${jar_suffix}".jar" $tableList
动态新增cdc表
在启动脚本中,把tableList=“t1,t2” 改为tableList=“t1,t2,t3”, 即新增表t3 , 再次从checkpoint 启动任务
注意:因为checkpoint 保存了cdc 数据库日志的位移,从checkpoint启动任务,cdc会接着上次的位移读取日志数据;后续新增的表只能增量cdc采集数据,必须配合离线全量采集【全量快照】后,再启动增量任务
遗留问题
1、动态新增cdc表偶尔不生效或较长时间才生效,具体原因未知,若有大佬知悉的,望在评论区告知,十分感谢!
从checkpoint启动如下图:
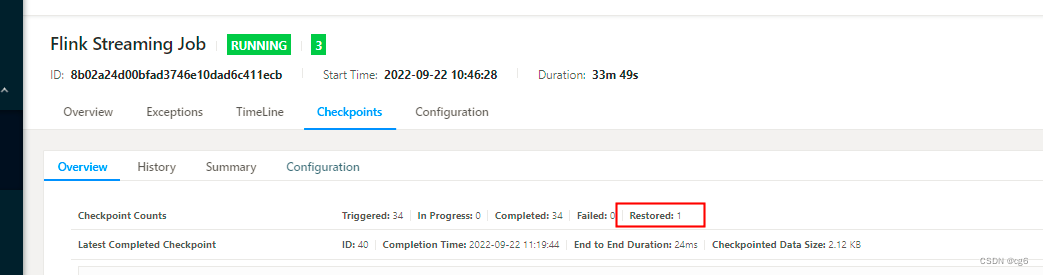
更新表数据,source 没有变化
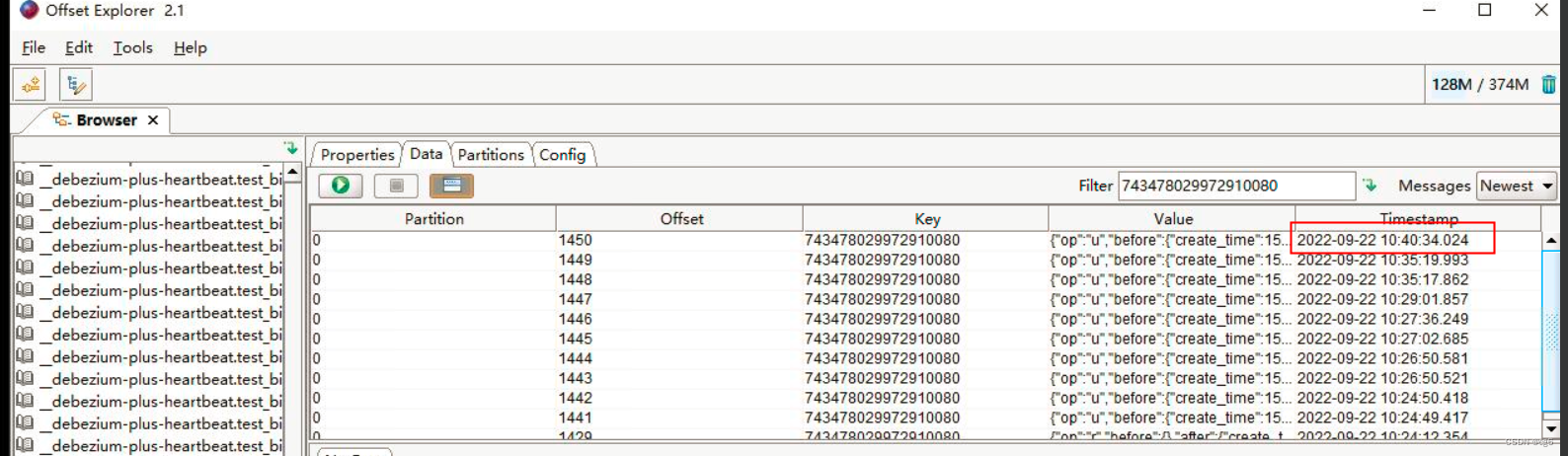
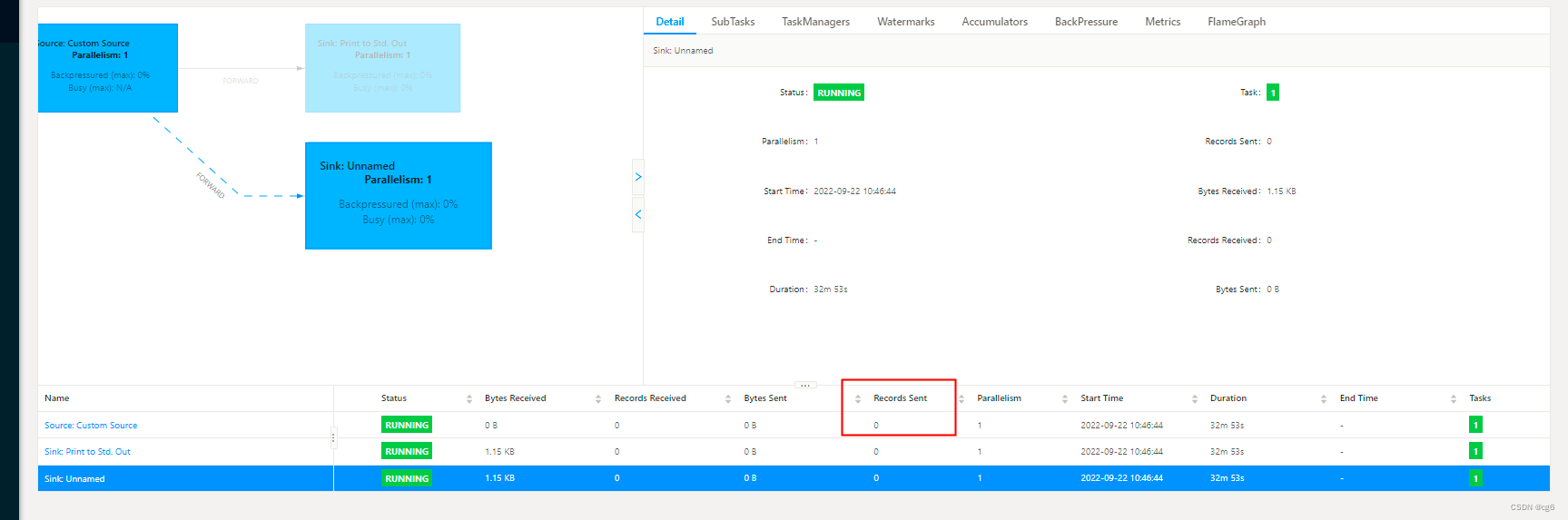 任务启动时间:2022.9.22 10:49 , 截止2022.9.22 11:27 , kafka 数据没有新增
任务启动时间:2022.9.22 10:49 , 截止2022.9.22 11:27 , kafka 数据没有新增
报错
Disconnected from the target VM, address: ‘127.0.0.1:64325’, transport: ‘socket’
原因是注释了env.execute(); 忘记取消了,使得程序停止了,放开注释即可
知识补充
postgres数据库slot查询
select
slot_name,
pg_size_pretty(pg_wal_lsn_diff(pg_current_wal_lsn(), restart_lsn)) as from_restart_lsn,
pg_size_pretty(pg_wal_lsn_diff(pg_current_wal_lsn(), confirmed_flush_lsn)) as from_confirmed_flush_lsn
from pg_replication_slots
where 1=1
and slot_name like '%slot_name%'
;
postgres数据库slot删除
select pg_drop_replication_slot('slot_name') from pg_replication_slots where slot_name = 'slot_name';















 1952
1952











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









