









上一篇文章我们简单的介绍《 linux中sqoop实现hive数据导入到mysql》,本文将简单介绍如何通过sqoop把hive数据导入到mysql。
一. 前期准备
实践本文内容,默认您已经安装和部署了hadoop,mysql,hive,sqoop等环境。如相关安装和部署有问题,可以参考《 linux中sqoop实现hive数据导入到mysql》。
二. sqoop实现hdfs文件导出
2.1 hive中插入数据
insert into hivetest.t_user values(7,'dlm666','dlm6'),(8,'dlm777','dlm7');
select * from hivetest.t_user;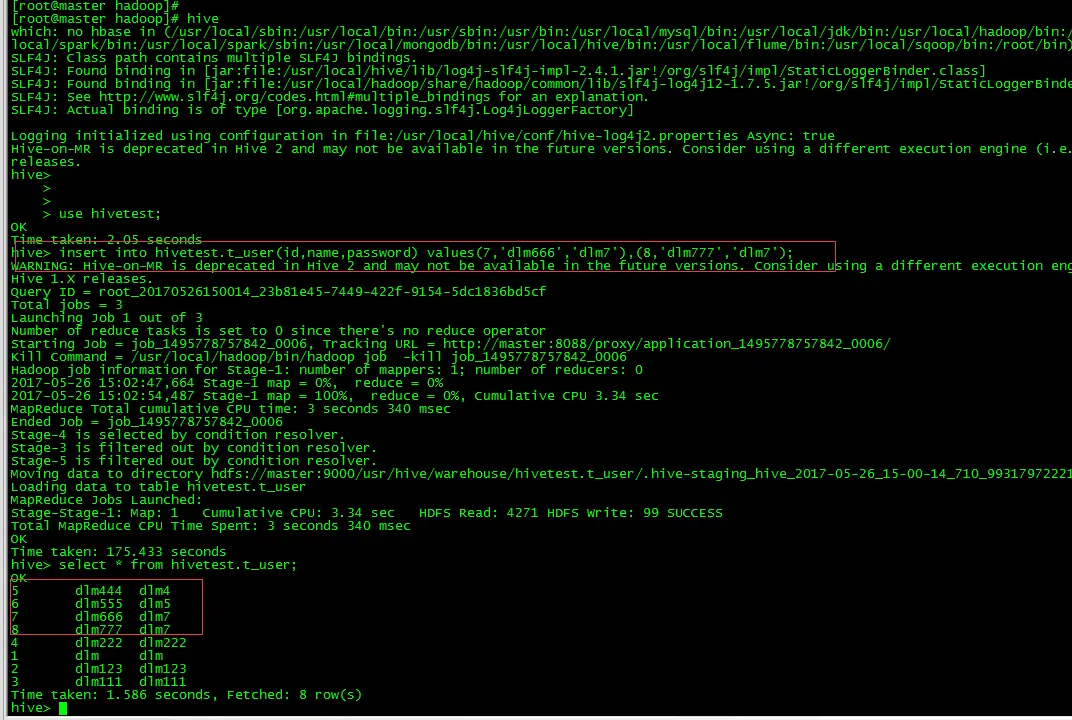
2.2 全表导出
sqoop export --connect jdbc:mysql://192.168.32.128:3306/hive --username root --password root --table t_user --export-dir /usr/hive/warehouse/hivetest.t_user --input-fields-terminated-by '\001'

2.3 表部分字段导出
如果只需要导出id和name,可以设置参数--colums "id,name"
sqoop export --connect jdbc:mysql://192.168.32.128:3306/hive --username root --password root --table t_user --columns "id,name" --export-dir /usr/hive/warehouse/hivetest.t_user --input-fields-terminated-by '\001'三. 异常坑处理
3.1 解析分隔符异常
Error: java.io.IOException: Can't export data, please check failed map task logs
at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:112)
at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:39)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:145)
at org.apache.sqoop.mapreduce.AutoProgressMapper.run(AutoProgressMapper.java:64)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:784)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:163)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1692)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
Caused by: java.lang.RuntimeException: Can't parse input data: '4dlm222dlm222'
at t_user.__loadFromFields(t_user.java:292)
at t_user.parse(t_user.java:230)
at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:83)
... 10 more
Caused by: java.lang.NumberFormatException: For input string: "4dlm222dlm222"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Integer.parseInt(Integer.java:492)
at java.lang.Integer.valueOf(Integer.java:582)
at t_user.__loadFromFields(t_user.java:279)
... 12 more
原因:sqoop导出是根据分隔符去分隔字段值。hive默认的分隔符是‘\001’,sqoop默认的分隔符是','。
解决:在脚本中需要加入 --input-fields-terminated-by '\001' 参数。
3.2 --input-fields-terminated-by和-fields-teminated-by区别
官网:

解析:
--input-fields-terminated-by:表示用于hive或hdfs数据导出到外部存储分隔参数;
--fields-terminated-by:表示用于外面存储导入到hive或hdfs中需要实现字段分隔的参数;
3.3 mapreduce.job超时异常

原因:本次hive是基于hadoop mapreduce去处理计算的。其中mapreduce读取数据是通过job任务去完成,如果在该时间范围内,没有读到任何的数据,那么就抛出这个异常。
本异常不影响结果。















 3987
3987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









