









一.前期准备
1.开发环境
window7
eclipse
jdk1.8
2.linux环境
zookeeper-3.4.8
hadoop-2.6.4
spark-1.6.0
scala-2.10.6
kafka_2.10-0.10.1.0
各环境的安装和部署请自行准备。
二.疑难杂症
1. spark+scala+kafka版本要一致
2. org.apache.spark.SparkException: A master URL must be set in your configuration

原因:

SparkConf中未设置master。由于Master为cluster程序管理中心,负责接收Client提交的作业,管理Worker,并命令Worker启动Driver和Executor。
解决:
在SparkConf中设置master,本处设置为“local[2]”.
local(default) 在本地而非集群跑Spark作业,并且只有一个worker thread(所以,并事实上没有并行)
local[k] 在本地跑Spark Application,有k个worker thread
spark://HOST:PORT 连接到指定URL的standalone集群
mesos://HOST:PORT 连接到指定的Mesos集群
yarn 连接到默认的YARN集群。yarn集群在SPARK_HOME/conf/yarn-site.xml中指定
3. object not serializable (class: org.apache.kafka.clients.consumer.ConsumerRecord)
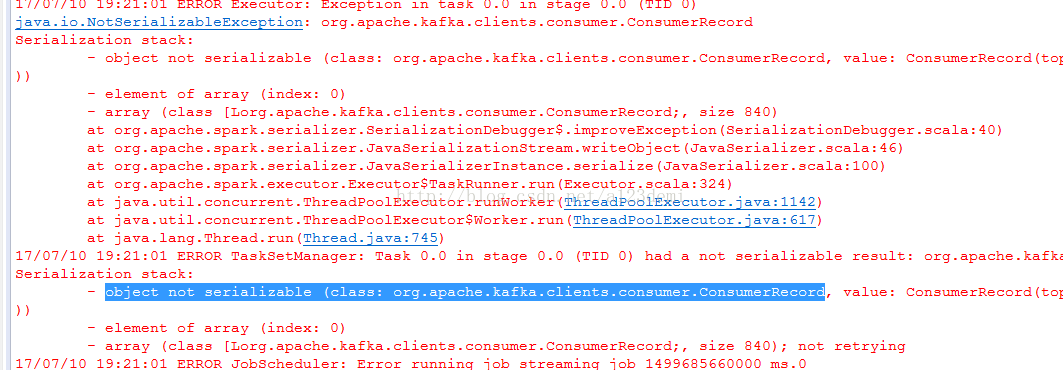
原因:
ConsumerRecord是Kafka10版本自带的类。该类为接受kafka消息的key-value类,而异常时该类未序列化。而程序中调用JavaRdd的collect方法,而该方法需要将数据加载到内存,需要进行序列化。

解决:
方法1:将获取数据集合的形式转化单个数据获取。

方法2:通过kryo序列化ConsumerRecord类


三.代码实现
1. sparkStreaming+kafka处理
package com.lm.spark;
import java.io.Serializable;
import java.util.Arrays;
import java.util.Collection;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.api.java.function.VoidFunction2;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.Time;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
@Component
public class SparkStreamingKafka implements Serializable {
/**
*
*/
private static final long serialVersionUID = 1L;
public static Logger LOGGER = LoggerFactory.getLogger(SparkStreamingKafka.class);
@Value("${spark.appname}")
private String appName;
@Value("${spark.master}")
private String master;
@Value("${spark.seconds}")
private long second;
@Value("${kafka.metadata.broker.list}")
private String metadataBrokerList;
@Value("${kafka.auto.offset.reset}")
private String autoOffsetReset;
@Value("${kafka.topics}")
private String kafkaTopics;
@Value("${kafka.group.id}")
private String kafkaGroupId;
public void processSparkStreaming() throws InterruptedException {
// 1.配置sparkconf,必须要配置master
SparkConf conf = new SparkConf().setAppName(appName).setMaster(master);
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
conf.set("spark.kryo.registrator", "com.lm.kryo.MyRegistrator");
// 2.根据sparkconf 创建JavaStreamingContext
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(second));
// 3.配置kafka
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", metadataBrokerList);
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer", StringDeserializer.class);
kafkaParams.put("group.id", kafkaGroupId);
kafkaParams.put("auto.offset.reset", autoOffsetReset);
kafkaParams.put("enable.auto.commit", false);
// 4.kafka主题
Collection<String> topics = Arrays.asList(kafkaTopics.split(","));
// 5.创建SparkStreaming输入数据来源input Stream
final JavaInputDStream<ConsumerRecord<String, String>> stream =
KafkaUtils.createDirectStream(jsc, LocationStrategies.PreferConsistent(),
ConsumerStrategies.<String, String> Subscribe(topics, kafkaParams));
// 6.spark rdd转化和行动处理
stream.foreachRDD(new VoidFunction2<JavaRDD<ConsumerRecord<String, String>>, Time>() {
private static final long serialVersionUID = 1L;
@Override
public void call(JavaRDD<ConsumerRecord<String, String>> v1, Time v2) throws Exception {
List<ConsumerRecord<String, String>> consumerRecords = v1.collect();
System.out.println("获取消息:" + consumerRecords.size());
}
});
// 6. 启动执行
jsc.start();
// 7. 等待执行停止,如有异常直接抛出并关闭
jsc.awaitTermination();
}
}2. kryo序列化接收器
package com.lm.kryo;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.spark.serializer.KryoRegistrator;
import com.esotericsoftware.kryo.Kryo;
public class MyRegistrator implements KryoRegistrator {
@Override
public void registerClasses(Kryo arg0) {
arg0.register(ConsumerRecord.class);
}
}














 3108
3108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









