







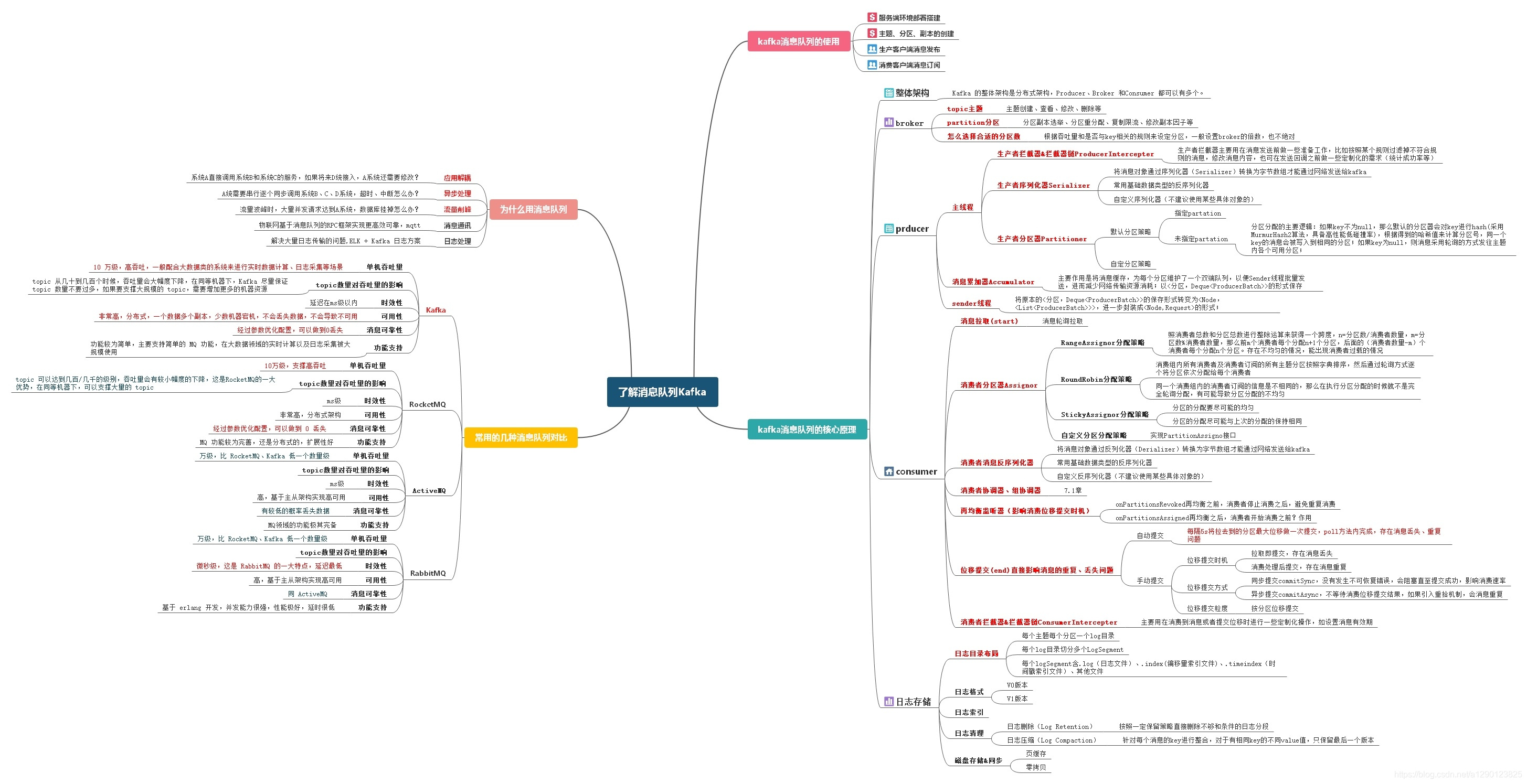
当我们聊kafka消息队列的时候,我们应该想到那些事儿?kafka的整个技术体系包含了哪些方面?(本文只提供1、2、6涉及问问题,3、4、5在生产者、消费者的相关的文章中继续探索)
- 消息队列的本质,用来解决什么问题而出现?
- kafka和众多消息队列之前有什么区别?
- kafka消息队列如何的使用?(项目案例太多,重点考虑一些需要关注的核心配置、操作接口)
- kafka消息队列的整体结构?(producer\consumer\broker)
- 各部分的实现原理(broker关注如何创建topic、partition、分区数的设置考量,以及日志存储;producer应该关注主线程【拦截器、序列化器、分区器】、sender线程【累加器】都做了什么事儿;consumer应该关注消费者做了哪些事儿【分区器、反序列化器、协调器&组协调器、再均衡监听器、拦截器、位移提交】);
- kafka使用过程中关注的热点问题有哪些?(生产端、消费端、broker 消息丢失问题&消息乱序问题&如何解决)
附:kafka体系思维脑图;
1、常用消息队列对比后总结:
- 所以中小型公司,技术实力较为一般,技术挑战不是特别高,用 RabbitMQ 是不错的选择
- 大型公司,基础架构研发实力较强,用 RocketMQ 是很好的选择。
- 当然,中小型公司使用 RocketMQ 也是没什么问题的选择,特别是以 Java 为主语言的公司。
- 如果是大数据领域的实时计算、日志采集等场景,用 Kafka 是业内标准的,绝对没问题,社区活跃度很高,绝对不会黄,何况几乎是全世界这个领域的事实性规范。
- 另外,目前国内也是有非常多的公司,将 Kafka 应用在业务系统中,例如唯品会、陆金所、美团等等。
2、我们讨论的kafka的那些热点问题
2.1、Kafka Producer 有哪些发送模式?
kafka生产者 中的第3部分有详细描述;
Kafka消息发送主要有三种模式,发后即忘(fire-and-forget)、同步(sync)、异步(async),重点对比优劣;producer发送客户端自己控制,并非参数控制。
- fire-and-forge:并不关心消息是否正确送达,效率最高,当发生不可重试异常时,会存在消息丢失(直接调用send()方法,不进行get()同步阻塞获取消息发送结果);
- sync:可靠性高,要么 消息被发送成功,要么异常(这里就涉及到了不同的异常重试机制);如果发生异常可以进行捕获并进行相应处理,不会像“发后即忘”的直接丢(调用完send()函数进行发送后,再调用Future的get());
- async:一般再send方法中指定Callback的回调函数,kafka在发送返回响应是使用该回调函数异步发送确认,一般的回调逻辑要么发送成功,要么抛出异常(这里也涉及到了不同的异常重试机制);实例:
producer.send(record,new CallBack(){
@Override
public void onCompletion(RecordMetaData metadata,Exception exception){
//该方法中的两个参数不并存,要么异常,要么返回消息元数据
if (exception !=null) {
exception.printStackTrace(); //实际中可能需要记录日志分析
} else {
System.out.println(metadata.topic()+"-"+metadata.partation()+":"+metadata.offset());
}
}
});对于异步模式,还有 4 个配套的参数,如下:
- buffer.mermory:消息累加器缓存的大小,可以减少网络请求和磁盘 IO 的次数,当然具体参数设置需要在效率和时效性方面做一个权衡。默认为33554432B=32MB
- batch.size:消息发送到网络之前缓存的ByteBuffer,Producer 会尝试批量发送属于同一个 Partition 的消息以减少请求的数量. 这样可以提升客户端和服务端的性能。默认大小是 16348 byte (16k).
- max.block.ms:生产者消息累加器空间不足时,消息发送send()阻塞的最大时间,默认60s
- ack:消息确认机制默认:
- 为 1标识只要leader副本成功写入消息,就能收到来自服务端的成功响应;如果leader副本的消息被follower副本拉取之前崩溃了,这个时候follower副本中没有leader副本的消息,会存在消息丢失;(可靠性和吞吐量的折中)
- 为0标识消息不需要等待任何服务端的响应;吞吐量的最大化,消息最不可靠;
- 为-1或者all等待所有ISR副本都成功写入消息后客户端才会收到来自服务端的响应;(AR\ISR\OSR分别代表 所有副本、和leader保持一定程度同步的副本、和leader副本相差较多的副本,和leader副本选举有很大关系);
2.2、kafka生产端会不会弄丢数据?
什么节点会丢消息? 发送阻塞超时&重新选举
如果按照上述的思路设置了 acks=all ,一定不会丢,要求是,你的 leader 接收到消息,所有的 follower 都同步到了消息之后,才认为本次写成功了。如果没满足这个条件,生产者会自动不断的重试,重试指定次数(前提是可重试异常)。
关于 Kafka Producer 重试发送消息的逻辑的源码解析,可以看看 《Kafka 重试机制解读》 。
另外,在推荐一篇文章 《360 度测试:KAFKA 会丢数据么?其高可用是否满足需求?》 ,提供了一些测试示例。
2.3、Kafka 消费端弄丢了数据?
消费端消息的丢失和消费位移的提交模式、方式、时机、粒度有密不可分的关系;

消息丢失本质就是:消息没有被真正处理成功(消费实例挂掉、重启、异步提交)、但是消费位移offset却被提交了,broker认为消息已经被消费成功了。
本人公司kafka消费者客户端FinKafkaConsumer,如何做位移提交:
public FinKafkaConsumer(final String topicName,
final String consumerGroup,
final Map<String, String> props,
final FinKafkaMsgListener listener) {
Preconditions.checkArgument(StringUtils.isNotBlank(topicName), "topic name must not be blank");
Preconditions.checkArgument(StringUtils.isNotBlank(consumerGroup), "consumer group must not be blank");
Preconditions.checkNotNull(listener);
Preconditions.checkNotNull(props);
Preconditions.checkArgument(props.containsKey("bootstrap.servers"));
this.topicName = topicName;
this.consumerGroup = consumerGroup;
this.monitorGroup = "kafka:consumer:topic:" + MonitorUtil.normalizedName(this.topicName) +
":group:" + MonitorUtil.normalizedName(this.consumerGroup);
Properties p = new Properties();
for (Map.Entry<String, String> entry : props.entrySet()) {
p.put(entry.getKey(), entry.getValue());
}
p.put("enable.auto.commit", "false");
String keySerClassName = props.getOrDefault("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
String valSerClassName = props.getOrDefault("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
try {
Class.forName(keySerClassName);
Class.forName(valSerClassName);
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
}
p.put("key.deserializer", keySerClassName);
p.put("value.deserializer", valSerClassName);
p.put("group.id", consumerGroup);
rawConsumer = new KafkaConsumer<>(p);
rawConsumer.subscribe(Lists.newArrayList(topicName));
ThreadFactory tfb = new ThreadFactoryBuilder()
.setDaemon(true)
.setNameFormat("thread-consumer-" + topicName + "-" + consumerGroup + "-%d")
.build();
listenExecThread = tfb.newThread(() -> {
LOGGER.info("[kafka_cons][{}][{}] start to poll message from kafka", topicName, consumerGroup);
CommitStatus commitStatus = new CommitStatus();
FinKafkaMsgListener.DefaultCommitStrategy MANUAL = FinKafkaMsgListener.DefaultCommitStrategy.manualCommit();
FinKafkaMsgListener.DefaultCommitStrategy dcs;
while (!destroyed.get()) {
//每次重新设置是否自动提交
dcs = listener.getDefaultCommitStrategy();
if (dcs == null) dcs = MANUAL;
//拉取消息
List<ConsumerMsg> msgs = null;
try {
//拉取消息
msgs = poll(listener.getPollTimeoutMS());
commitStatus.msgCountFromLastCommit += msgs.size();
} catch (Throwable e) {
Throwable inner = ExceptionUtil.unwrapThrowable(e);
LOGGER.error("[kafka_cons][{}][{}] poll msg err, errmsg={}, e", topicName, consumerGroup,
inner.getMessage(), inner);
}
//没有获取到消息
if (CollectionUtils.isEmpty(msgs)) {
//设置为自动提交,并且超过了自动提交的时间限制
if (dcs.isAutoCommit() && dcs.getAutoCommitInterval() > 0) {
if ((System.currentTimeMillis() - commitStatus.timeMsFromLastCommit)
> dcs.getAutoCommitInterval()) {
commitKafka(commitStatus);
}
}
continue;
}
//处理消息
long start = System.currentTimeMillis();
try {
//TODO 如果处理的抛出异常,需要怎么处理
_ReceivedMsgs bm = new _ReceivedMsgs(commitStatus, msgs, rawConsumer);
listener.onMsg(bm);
if (dcs.isAutoCommit()) {
//满足时间策略的自动提交
boolean timeCondOK = (dcs.getAutoCommitInterval() > 0 &&
(System.currentTimeMillis() - commitStatus.timeMsFromLastCommit
> dcs.getAutoCommitInterval()));
if (timeCondOK) {
commitKafka(commitStatus);
} else {
//满足消息条数的提交策略
boolean msgCondOK = (dcs.getAutoCommitMsgCount() > 0 &&
(commitStatus.msgCountFromLastCommit > dcs.getAutoCommitMsgCount()));
if (msgCondOK) {
commitKafka(commitStatus);
}
}
}
Metrics.sum(monitorGroup, "process_msg:count", msgs.size());
} catch (Exception e) {
Metrics.sum(monitorGroup, "process_error:count", msgs.size());
Throwable inner = ExceptionUtil.unwrapThrowable(e);
LOGGER.error("[kafka_cons][{}][{}] poll errmsg={}, e", topicName, consumerGroup,
inner.getMessage(), inner);
STraceLog.newLog(CompType.KAFKA_CONSUMER, "process")
.addTags(consumerGroup, topicName)
.costMs(System.currentTimeMillis() - start)
.putAttr("topicName", topicName)
.putAttr("consumeGroup", consumerGroup)
.markFail("process_fail", inner)
.send();
}
//维护对象池
if (CollectionUtils.isNotEmpty(msgs)) {
for (ConsumerMsg msg : msgs) {
returnBack(msg);
}
}
}
LOGGER.error("[kafka_cons][{}][{}] end to poll message from kafka", topicName, consumerGroup);
});
listenExecThread.start();
}消费位移自动提交消息丢失:
- 基于时间策略的自动提交,距离上一次消费位移提交时间达到指定时间(默认5s)后,自动提交拉取 分区中消息中最大位移;
- 基于消息条数的自动提交,不满足时间策略的自动提交时,检测是否满足消息条数的提交策略
消费位移手动提交消息丢失:
Kafka 会自动提交 offset ,那么只要关闭自动提交 offset ,在处理完之后自己手动提交 offset ,就可以保证数据不会丢。但是此时确实还是可能会有重复消费,比如你刚处理完,还没提交 offset ,结果自己挂了,此时肯定会重复消费一次,自己保证幂等性就好了。
使用手动提交位移时踩过的坑:
生产环境碰到的一个问题,就是说我们的 Kafka 消费者消费到了数据之后是写到一个内存的 queue 里先缓冲一下,结果有的时候,你刚把消息写入内存 queue ,然后消费者会自动提交 offset 。然后此时我们重启了系统,就会导致内存 queue 里还没来得及处理的数据就丢失了。
2.4、Kafka Broker 弄丢了数据?
这块比较常见的一个场景,就是 Kafka 某个 Broker 宕机,然后重新选举 Partition 的 leader。大家想想,要是此时其他的 follower 刚好还有些数据没有同步,结果此时 leader 挂了,然后选举某个 follower 成 leader 之后,不就少了一些数据?这就丢了一些数据啊。
生产环境也遇到过,我们也是,之前 Partition 的 leader 机器宕机了,将 follower 切换为 leader 之后,就会发现说这个数据就丢了。
所以此时一般是要求起码设置如下 4 个参数:
- 给 Topic 设置
replication.factor参数:这个值必须大于 1,要求每个 partition 必须有至少 2 个副本。 - 在 Kafka 服务端设置
min.insync.replicas参数:这个值必须大于 1 ,这个是要求一个 leader 至少感知到有至少一个 follower 还跟自己保持联系,没掉队,这样才能确保 leader 挂了还有一个 follower 吧。 - 在 Producer 端设置
acks=all,这个是要求每条数据,必须是写入所有 replica 之后,才能认为是写成功了。
不过这个也不一定能够绝对保证,例如说,Broker 集群里,所有节点都挂了,只剩下一个节点。此时,
acks=all和acks=1就等价了。当然,也可以通过设置min.insync.replics参数,每次写入要求最小的同步副本数。这块也和朋友交流了下,他们金融场景下,acks=all也是这么配置的。原因嘛,因为他们是金融场景呀。
- 在 Producer 端设置
retries=MAX(很大很大很大的一个值,无限次重试的意思):这个是要求一旦写入失败,就无限重试,卡在这里了。
我们生产环境就是按照上述要求配置的,这样配置之后,至少在 Kafka broker 端就可以保证在 leader 所在 Broker 发生故障,进行 leader 切换时,数据不会丢失。
2.5、Kafka 如何保证消息的顺序性?
Kafka 提供的方案,都是相对有损的。如下:
这里的顺序消息,我们更多指的是,单个 Partition 的消息,被顺序消费。
- 方式一,Consumer ,对每个 Partition 内部单线程消费,单线程吞吐量太低,一般不会用这个。
-
方式二,Consumer ,拉取到消息后,写到 N 个内存 queue,具有相同 key 的数据都到同一个内存 queue 。然后,对于 N 个线程,每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。
这种方式,相当于对【方式一】的改进,将相同 Partition 的消息进一步拆分,保证相同 key 的数据消费是顺序的。不过这种方式,消费进度的更新会比较麻烦。














 666
666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









