










DNA Sorting
One measure of ``unsortedness'' in a sequence is the number of pairs of entries that are out of order with respect to each other. For instance, in the letter sequence ``DAABEC'', this measure is 5, since D is greater than four letters to its right and E is greater than one letter to its right. This measure is called the number of inversions in the sequence. The sequence ``AACEDGG'' has only one inversion (E and D)--it is nearly sorted--while the sequence ``ZWQM'' has 6 inversions (it is as unsorted as can be--exactly the reverse of sorted).
You are responsible for cataloguing a sequence of DNA strings (sequences containing only the four letters A, C, G, and T). However, you want to catalog them, not in alphabetical order, but rather in order of ``sortedness'', from ``most sorted'' to ``least sorted''. All the strings are of the same length.
输入:
m表示有m个测试字符串数据, n表示每一组字符串的长度。
The first line of the input is an integer M, then a blank line followed by M datasets. There is a blank line between datasets.The first line of each dataset contains two integers: a positive integer n ( ![]() ) giving the length of the strings; and a positive integer m (
) giving the length of the strings; and a positive integer m (![]() ) giving the number of strings. These are followed by m lines, each containing a string of length n.
) giving the number of strings. These are followed by m lines, each containing a string of length n.
输出:
每一个字符串被排好的程度。 排的最好的排在最上面。 评价排好的程度是利用字符串中的逆序对的个数。 所以我们只需要统计每个字符串的逆序对的个数。 另外, 还要求当两个字符串排序的程序相同的时候(即逆序对相同), 不打乱两个字符串在原始字符串中的相对问题(谁先谁后不被打乱了)。 这要求我们选择一个stable sorting(稳定排序)。
For each dataset, output the list of input strings, arranged from ``most sorted'' to ``least sorted''. If two or more strings are equally sorted, list them in the same order they are in the input file.Print a blank line between consecutive test cases.
输入:
10 6 AACATGAAGG TTTTGGCCAA TTTGGCCAAA GATCAGATTT CCCGGGGGGA ATCGATGCAT
输出:
CCCGGGGGGA
AACATGAAGG
GATCAGATTT
ATCGATGCAT
TTTTGGCCAA
TTTGGCCAAA首先, 这里涉及到两个问题:
(1)求每一个字符串的逆序对数的问题。
(2) 对逆序数排序问题。 由于要求不打乱原始的顺序。 我们需要选择stable的排序。
问题一: 求逆序数的问题。
(方法一)由于题目中只有四个字母。 所以我们可以使用四个计数器a[4], 均初始化为0。这样, 我们只需要对字符串从后面往前扫一遍, 在线性时间内完成逆序对的求解问题。 下面分析这四个计数器:
a[0]: 从后往前扫的时候, 遇到A时, 前面比A小的字母的个数。 显然, 一直为0。 所以我们不需要更新这个值, 使其一直保持0即可。
下面我们说说其他三个计数器的更新细节, 以及cnt的记录总的结果。
从后往前数, 遇到:
遇到"A": 遇到A的时候, 表示前面如果再遇到比A大的, 就需要对相关的a[1], a[2], a[3]进行 ++ 的操作, 表示遇到了一个A。 此时当然不需要更新cnt, 因为A无法作为逆序对的第一个字母啦。
遇到"C": 表明接下来往前扫, 如果扫到G, T, 这就组成了一个逆序对了。不过这只是潜在的。 所以对a[2], a[3]均进行++的操作。 此时需要对cnt + a[1]的更新操作, a[1]表示C前面的遇到的A的个数。 C可以和A组成逆序对嘛。
遇到"G": 同理。 如果接下来在 往前扫, 如果遇到T, 就会组成逆序对。 所以我们更新a[3]进行++的操作。 此时要更新cnt + a[2]的操作。 表示G和后面已经扫过的潜在的(现在成了现实)组成的逆序对的个数。
遇到"T": 此时, 我们只需要更新cnt += a[3], a[3]表示与当前遇到的T和已经扫过的组成的逆序对个数。 此时不需要更新任何计数器。 因为前面在遇到的字母根本无法和现在遇到的T在组成逆序对了。
问题二: 选择一个稳定排序
常见的stable sort有如下:
(1) bubble sort(冒泡排序)
(2) bucket sort(桶排序)
(3)Insertion sort(插入排序)
(4) counting sort(计数排序)
(5) merge sort(归并排序)
(6) radix sort(基排序)
(7) 二叉搜索树排序
不稳定的排序算法:
(1) heap sort(堆排序)
(2) quick sort(快排) (快排的不稳定源于partition。 例如99914, 假如我们选择4为pivot, 那么必然会发生, 19994, 第三个9是第一个9的。 交换了。 然后找到了4的位置,移动数组即可。 最终成了14999)
(3)selection sort(选择排序)
(4) 希尔排序(shell sorting)。
由于<algorithm>下面的std::sort排序算法实现了quick sort 的插入排序, 或者堆排序, 插入排序的混合排序, 所以不一定是stable的啦。 最好不要用啦。
不过STL 里面有一个stable::stable_sort函数是稳定的排序, 可以使用啦。
声明如下, <algorithm>:
template <class RandomAccessIterator> void stable_sort ( RandomAccessIterator first, RandomAccessIterator last ); template <class RandomAccessIterator, class Compare> void stable_sort ( RandomAccessIterator first, RandomAccessIterator last, Compare comp );时间复杂度:
If enough extra memory is available, linearithmic in the distance between first and last: Performs up to N*log2(N)element comparisons (where N is this distance), and up to that many element moves.
Otherwise, polyloglinear in that distance: Performs up to N*log22(N) element comparisons, and up to that many element swaps.
程序如下:
#include <iostream>
#include <string>
#include <fstream>
#include <algorithm>
using namespace std;
struct DNA {
string str;
int cnt;
} w[1000 + 10];
bool cmp(DNA a, DNA b) { //因为不是对默认的数排序, 有卫星数据, 所以需要定义这个比较函数
return a.cnt < b.cnt;
}
int count_inv(string str, int len) { // 求逆序对
int cnt = 0;
int a[4] = {0};
for(int i = len - 1; i >= 0; --i) {
switch(str[i]) {
case 'A':
a[1]++;
a[2]++;
a[3]++;
break;
case 'C':
a[2]++;
a[3]++;
cnt += a[1];
break;
case 'G':
a[3]++;
cnt += a[2];
break;
case 'T':
cnt += a[3];
break;
default:
break;
}
}
return cnt;
}
int main() {
int length, Cases;
ifstream input("in.txt");
ofstream output("out.txt");
input >> length >> Cases;
for(int i = 0; i < Cases; ++i) {
// getline(input, w[i].str);
input >> w[i].str;
w[i].cnt = count_inv(w[i].str, length);
}
stable_sort(w, w + Cases, cmp);
for(int i = 0; i < Cases; ++i) {
output << w[i].str << endl;
}
return 0;
}
运行即如果如下:
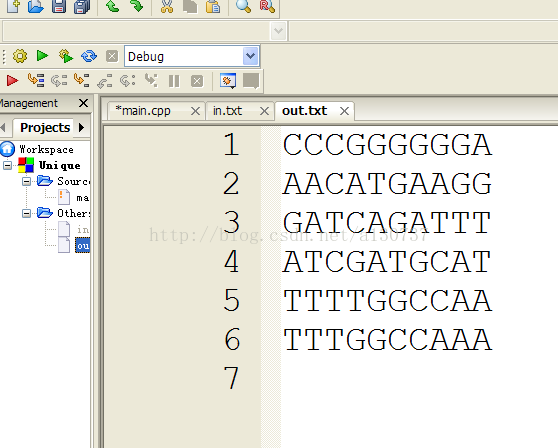
另外, 如果不选择std::stable_sort, 可以选择写一个bubber sort的排序算法。
另外, 在计算逆序对数目的时候, 可以直接使用双重循环获得,方法如下:
#include <iostream>
#include <string>
#include <fstream>
#include <algorithm>
using namespace std;
struct DNA {
string str;
int cnt;
} w[1000 + 10];
bool cmp(DNA a, DNA b) { // 其实要不要都一样, std::sort默认的就是
return a.cnt < b.cnt;
}
int count_inv(string str, int len) { // 求逆序对
int cnt = 0;
for(int j = 1; j < len; j++)
for(int k = 0; k < j; k++) // j 前面的与j 组成逆序对
if(str[j] < str[k])//求逆序数
cnt++;
return cnt;
}
int main() {
int length, Cases;
ifstream input("in.txt");
ofstream output("out.txt");
input >> length >> Cases;
for(int i = 0; i < Cases; ++i) {
//getline(input, w[i].str);
input >> w[i].str;
w[i].cnt = count_inv(w[i].str, length);
}
stable_sort(w, w + Cases, cmp);
for(int i = 0; i < Cases; ++i) {
output << w[i].str << endl;
}
return 0;
}














 446
446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









