MIndspore数据处理
数据加载
- 数据加载的思想很简单,数据只存放在硬盘里,无论是云端硬盘还是本地硬盘。而数据加载就是从硬盘中将数据取出,放入到内存中执行指令做运算
- 打个比方,就像是从冰箱取出食材,这就是数据加载的过程,而在取出食材之前需要找到冰箱中食材的位置,故而加载数据唯一需要的是Path
- 而从云端download数据需要提供数据源URL,资源定位符
- 通过URL加载数据代码如下,其中url是需要填写的,kind表示是zip压缩类型,解压后的位置就是MNIST_Data/train,shuffle表示开启或者关闭洗牌模式,也就是打乱数据集
path = download(url, "./", kind="zip", replace=True)
train_dataset = MnistDataset("MNIST_Data/train", shuffle=True)
数据迭代
def visualize(dataset):
figure = plt.figure(figsize=(4, 4))
cols, rows = 3, 3
plt.subplots_adjust(wspace=0.5, hspace=0.5)
for idx, (image, label) in enumerate(dataset.create_tuple_iterator()):
figure.add_subplot(rows, cols, idx + 1)
plt.title(int(label))
plt.axis("off")
plt.imshow(image.asnumpy().squeeze(), cmap="gray")
if idx == cols * rows - 1:
break
plt.show()
- 通过dataset.create_tuple_iterator()接口创建数据迭代器,迭代就是将数据分成固定大小多批次,方便多批将固定数量的数据放入内存进行模型训练。
数据处理
- shuffle,前文中已有提到,是对数据集进行打乱的操作,避免数据集分布不均匀。
- map,在Hadoop中有做map-reduce的操作,这个map是将行数据进行指定的分割,转换为数组输出。在机器学习中的map也是做数据的转换,如将图片做压缩或者声音做去噪,是一个数据预处理的操作,数据预处理包含数据清洗、数据切分。对图片做一个rescale(1/255.0),让图片除以255。
train_dataset = train_dataset.map(vision.Rescale(1.0 / 255.0, 0), input_columns='image')
- batch也已经提到了,是批次的意思,表示每一个batch包含多少张数据集,在硬件资源不够的情况下,使用batch进行分批次,就可以用大量的数据对模型进行训练了,例如总数据位2W张,按照batch划分可以划分为每一个batch1000张,这样就大大减小了内存的负载压力,基于一个batch做单次训练,多个batch组成一个epoch(一轮),所以batch的size需要依据已用的硬件资源来设定,如分布式处理本质上也是分多个batch,同时训练多个batch来提高效率,而在单机上的训练是串型的。
train_dataset = train_dataset.batch(batch_size=32)
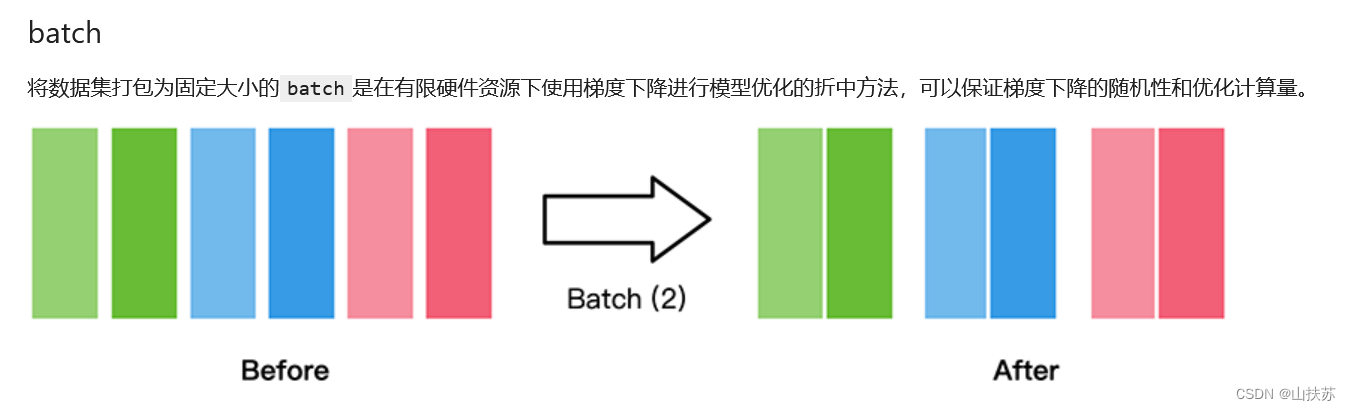
- 此处设定了此数据集的每一个batch的大小,假设总大小为320,那么现在数据集就是1032,需要标明是哪一个batch的哪张图片。数据的维数也就由一维上升到二维,这里也可以看到维数并不是什么复杂的东西,维数是应对精确表达的需要而产生的,回想张量的学习,一个33232的图片,表示的是3232大小的RGB三通道彩色图片,要精确表达每一个像素点就需要(x,y,RGB),注意RGB表示的是该像素点的R(0,255),G(0,255),B(0,255),三张叠在一起。如果分批次的话,假设现在有32张33232的图片,我们给他分成8批次,也就是8433232,其中某张图片用向量表示就是[5,2,133,100,22,21,21],表示的是第六batch的第三张图片,RGB及图片大小。
- 当MIndspore不支持你想要训练的数据集表示怎么办?可随机访问数据集提供了不支持直接加载数据之外的数据访问方式,简言之就是只要给的数据集是(DATA,Label)这个样式的,训练的本质就是模型能够通过DATA预测Label,那么唯一要解决的问题就是数据的随机访问,像数组一样访问(key,value),RandomAccessDataset()提供了数据集的随机访问加载方式。
loader = RandomAccessDataset()
dataset = GeneratorDataset(source=loader, column_names=["data", "label"])
for data in dataset:
print(data)






















 1034
1034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









