








##常见URL过滤方法
###1 直接查询比较
即假设要存储url A,在入库前首先查询url库中是否存在 A,如果存在,则url A 不入库,否则存入url库。这种方法准确性高,但是一旦数据量变大,占用的存储空间也变大,同时,由于要查库,数据一多,查询时间变长,存储效率下降。
###2 基于hash的存储
对于给定的url,通过建立的hash函数,来获得对应的hash值,并将该值存入库中。当在检查url是否存在库中时,只要将要检查的url,通过hash函数获取其hash值,然后查看库中是否存在该hash值,存在则丢弃,否则入库。这种方法在数据量变大时,占用的存储空间也会增大,查询时间也会加长。但是它可以将url进行压缩。对于很长的url,hash值可以相对很短。
以上方法中,为加快查询速度,一般可以选择 Redis作为查询库。
##布隆过滤器 Bloom Filter
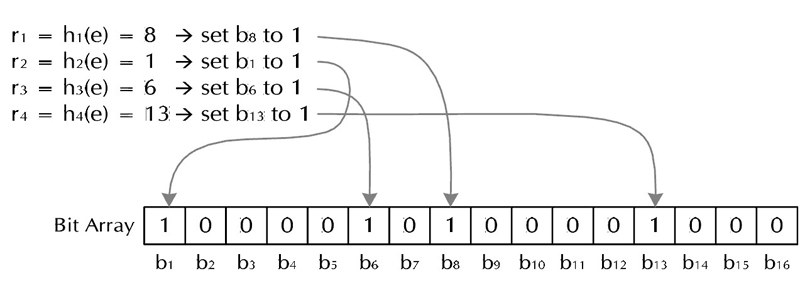
基本思路(网上一大堆):
1, 设数据集合
A
=
{
a
1
,
a
2
,
.
.
.
.
,
a
n
}
A=\{a_1,a_2,....,a_n\}
A={a1,a2,....,an},含
n
n
n个元素,作为待操作的集合。
2, Bloom Filter用一个长度为 m m m的位向量 V V V表示的集合中的元素,位向量初始值全为0。
3, k k k个具有均匀分布特性的散列函数 h 1 , h 2 , . . . . , h k h_1,h_2,....,h_k h1,h2,....,hk.
4, 对于要加入的元素,首经过k个散列函数产生k个随机数 h 1 , h 2 , . . . . . . h k h_1,h_2,......h_k h1,h2,......hk,使向量 V V V的相应位置 h 1 , h 2 , . . . . . . h k h_1,h_2,......h_k h1,h2,......hk均置为1。集合中其他元素也通过类似的操作,将向量 V V V的若干位置为1。
5, 对于新要加入的元素的检查,首先将该元素经过上步中类似操作,获得k个随机数 h 1 , h 2 , . . . . . . h k h_1,h_2,......h_k h1,h2,......hk,然后查看向量 V V V的相应位置 h 1 , h 2 , . . . . . . h k h_1,h_2,......h_k h1,h2,......hk上的值,若全为1,则该元素已经在之前的集合中;若至少有一个0存在,表明,此元素不在之前的集合中,为新元素。
算法特点:
对于已经在集合中的元素,通过5中的查找方法,一定可以判定该元素在集合中。
对于不在集合中的元素,可能会被误判在集合中。
其整个流程可以参照以下伪代码:
classBloom:
""" Bloom Filter """
def __init__(self,m,k,hash_fun):
"""m, size of the vector
k, number of hash fnctions to compute
hash_fun, hash function to use
"""
self.m = m
self.vector =[0]*m # initialize the vectorself.k = k
self.hash_fun = hash_fun
self.data ={}
# data structure to store the data
self.false_positive =0
def insert(self,key,value):
""" insert the pair (key,value) in the database """
self.data[key]= value
for i in range(self.k):
self.vector[self.hash_fun(key+str(i))%self.m]=1
def contains(self,key):
""" check if key is cointained in the database
using the filter mechanism """
for i in range(self.k):
if self.vector[self.hash_fun(key+str(i))%self.m]==0:
return False
# the key doesn't existreturnTrue# the key can be in the data set
def get(self,key):
""" return the value associated with key """
if self.contains(key):
try:returnself.data[key]# actual lookup
except KeyError: self.false_positive +=1
参数计算:
在Bloom Filter表示方法中,对于一元素,某一位被置1的概率为
1
m
\frac{1}{m}
m1,为0的概率为
1
−
1
m
1-\frac{1}{m}
1−m1,散列函数执行k次,对于集合中所有元素,执行次数kn次,所以在运算结束时,某位仍为0 的概率为:
P
0
=
(
1
−
1
m
)
k
n
P_0=(1-\frac{1}{m})^{kn}
P0=(1−m1)kn
由于
lim
x
→
∞
(
1
−
1
x
)
−
x
≈
e
\lim_{x\to \infty} (1-\frac{1}{x})^{-x} \approx e
x→∞lim(1−x1)−x≈e
有
P
0
=
e
−
k
n
m
P_0=e^{\frac{-kn}{m}}
P0=em−kn
因此误判概率为:
P
=
(
1
−
P
0
)
k
=
(
1
−
e
−
k
n
m
)
k
P =(1-P_0)^k = (1-e^\frac{-kn}{m})^k
P=(1−P0)k=(1−em−kn)k
由以上式可知,m增大,P减小;对于给定的n和m,求最小的P值。
将上式取对数有:
ln
P
=
k
ln
(
1
−
e
−
k
n
m
)
\ln P = k\ln (1-e^{\frac{-kn}{m}})
lnP=kln(1−em−kn)
对k求导:
1
P
∂
P
∂
k
=
ln
(
1
−
e
−
k
n
m
)
+
k
1
(
1
−
e
−
k
n
m
)
(
−
1
)
(
e
−
k
n
m
)
(
−
n
m
)
\frac{1}{P} \frac{\partial P}{\partial k} = \ln (1-e^{\frac{-kn}{m}}) + k\frac{1}{(1-e^{\frac{-kn}{m}})}(-1)(e^{\frac{-kn}{m}}) (-\frac{n}{m})
P1∂k∂P=ln(1−em−kn)+k(1−em−kn)1(−1)(em−kn)(−mn)
令
∂
P
∂
k
=
0
\frac{\partial P}{\partial k} =0
∂k∂P=0
有:
ln
(
1
−
e
−
k
n
m
)
∗
(
1
−
e
−
k
n
m
)
=
(
−
k
n
m
)
*
e
−
k
n
m
\ln (1-e^{\frac{-kn}{m}}) *(1-e^{\frac{-kn}{m}}) = (\frac{-kn}{m})*e^{\frac{-kn}{m}}
ln(1−em−kn)∗(1−em−kn)=(m−kn)*em−kn
可以发现,在上式中等号的任意一边,后一个数取对数刚好是前一个数,所以等号左右两边结构相似。则有:
(
1
−
e
−
k
n
m
)
=
e
−
k
n
m
(1-e^{\frac{-kn}{m}}) = e^{\frac{-kn}{m}}
(1−em−kn)=em−kn
求得:
1
2
=
e
−
k
n
m
\frac{1}{2}=e^{\frac{-kn}{m}}
21=em−kn
求得:
k
=
m
n
ln
2
≈
0.7
m
n
k = \frac{m}{n}\ln2 \approx 0.7\frac{m}{n}
k=nmln2≈0.7nm
时,误判率最小
##python3中pybloom
自己使用的是python3.5, 而官网pypi上下载的pybloom是时候python2版本的。所以直接安装pip install pybloom 或者python setup.py install会出错。自己将文件中部分内容修改后就可以正常安装(python setup.py install)与运行。
源文件见个人CSDN下载页。
http://download.csdn.net/detail/a1368783069/9597338
from pybloom import BloomFilter
f = BloomFilter(capacity=10000, error_rate=0.001)
for i in range(0, f.capacity):
_ = f.add(i)
0 in f
#True
f.capacity in f
#False
len(f) <= f.capacity
#True
abs((len(f) / float(f.capacity)) - 1.0) <= f.error_rate
#True
from pybloom import ScalableBloomFilter
sbf = ScalableBloomFilter(mode=ScalableBloomFilter.SMALL_SET_GROWTH)
count = 10000
for i in range(0, count):
_ = sbf.add(i)
sbf.capacity > count
#True
len(sbf) <= count
#True
abs((len(sbf) / float(count)) - 1.0) <= sbf.error_rate
#True
pybloom源码,可直接作为module调用。
# -*- encoding: utf-8 -*-
"""This module implements a bloom filter probabilistic data structure and
an a Scalable Bloom Filter that grows in size as your add more items to it
without increasing the false positive error_rate.
Requires the bitarray library: http://pypi.python.org/pypi/bitarray/
>>> from pybloom import BloomFilter
>>> f = BloomFilter(capacity=10000, error_rate=0.001)
>>> for i in range(0, f.capacity):
... _ = f.add(i)
...
>>> 0 in f
True
>>> f.capacity in f
False
>>> len(f) <= f.capacity
True
>>> abs((len(f) / float(f.capacity)) - 1.0) <= f.error_rate
True
>>> from pybloom import ScalableBloomFilter
>>> sbf = ScalableBloomFilter(mode=ScalableBloomFilter.SMALL_SET_GROWTH)
>>> count = 10000
>>> for i in range(0, count):
... _ = sbf.add(i)
...
>>> sbf.capacity > count
True
>>> len(sbf) <= count
True
>>> abs((len(sbf) / float(count)) - 1.0) <= sbf.error_rate
True
"""
import math
import hashlib
from struct import unpack, pack, calcsize
try:
import bitarray
except ImportError:
raise ImportError('pybloom requires bitarray >= 0.3.4')
__version__ = '1.1'
__author__ = "Jay Baird <jay@mochimedia.com>, Bob Ippolito <bob@redivi.com>,\
Marius Eriksen <marius@monkey.org>,\
Alex Brasetvik <alex@brasetvik.com>"
def make_hashfuncs(num_slices, num_bits):
if num_bits >= (1 << 31):
fmt_code, chunk_size = 'Q', 8
elif num_bits >= (1 << 15):
fmt_code, chunk_size = 'I', 4
else:
fmt_code, chunk_size = 'H', 2
total_hash_bits = 8 * num_slices * chunk_size
if total_hash_bits > 384:
hashfn = hashlib.sha512
elif total_hash_bits > 256:
hashfn = hashlib.sha384
elif total_hash_bits > 160:
hashfn = hashlib.sha256
elif total_hash_bits > 128:
hashfn = hashlib.sha1
else:
hashfn = hashlib.md5
fmt = fmt_code * (hashfn().digest_size // chunk_size)
num_salts, extra = divmod(num_slices, len(fmt))
if extra:
num_salts += 1
salts = [hashfn(hashfn(pack('I', i)).digest()) for i in range(num_salts)]
def _make_hashfuncs(key):
#if isinstance(key, unicode):
# key = key.encode('utf-8')
#else:
# key = str(key)
key = str(key).encode("utf-8")
rval = []
for salt in salts:
h = salt.copy()
h.update(key)
rval.extend(uint % num_bits for uint in unpack(fmt, h.digest()))
del rval[num_slices:]
return rval
return _make_hashfuncs
class BloomFilter(object):
FILE_FMT = '<dQQQQ'
def __init__(self, capacity, error_rate=0.001):
"""Implements a space-efficient probabilistic data structure
capacity
this BloomFilter must be able to store at least *capacity* elements
while maintaining no more than *error_rate* chance of false
positives
error_rate
the error_rate of the filter returning false positives. This
determines the filters capacity. Inserting more than capacity
elements greatly increases the chance of false positives.
>>> b = BloomFilter(capacity=100000, error_rate=0.001)
>>> b.add("test")
False
>>> "test" in b
True
"""
if not (0 < error_rate < 1):
raise ValueError("Error_Rate must be between 0 and 1.")
if not capacity > 0:
raise ValueError("Capacity must be > 0")
# given M = num_bits, k = num_slices, p = error_rate, n = capacity
# solving for m = bits_per_slice
# n ~= M * ((ln(2) ** 2) / abs(ln(P)))
# n ~= (k * m) * ((ln(2) ** 2) / abs(ln(P)))
# m ~= n * abs(ln(P)) / (k * (ln(2) ** 2))
num_slices = int(math.ceil(math.log(1 / error_rate, 2)))
# the error_rate constraint assumes a fill rate of 1/2
# so we double the capacity to simplify the API
bits_per_slice = int(math.ceil(
(2 * capacity * abs(math.log(error_rate))) /
(num_slices * (math.log(2) ** 2))))
self._setup(error_rate, num_slices, bits_per_slice, capacity, 0)
self.bitarray = bitarray.bitarray(self.num_bits, endian='little')
self.bitarray.setall(False)
def _setup(self, error_rate, num_slices, bits_per_slice, capacity, count):
self.error_rate = error_rate
self.num_slices = num_slices
self.bits_per_slice = bits_per_slice
self.capacity = capacity
self.num_bits = num_slices * bits_per_slice
self.count = count
self.make_hashes = make_hashfuncs(self.num_slices, self.bits_per_slice)
def __contains__(self, key):
"""Tests a key's membership in this bloom filter.
>>> b = BloomFilter(capacity=100)
>>> b.add("hello")
False
>>> "hello" in b
True
"""
bits_per_slice = self.bits_per_slice
bitarray = self.bitarray
if not isinstance(key, list):
hashes = self.make_hashes(key)
else:
hashes = key
offset = 0
for k in hashes:
if not bitarray[offset + k]:
return False
offset += bits_per_slice
return True
def __len__(self):
"""Return the number of keys stored by this bloom filter."""
return self.count
def add(self, key, skip_check=False):
""" Adds a key to this bloom filter. If the key already exists in this
filter it will return True. Otherwise False.
>>> b = BloomFilter(capacity=100)
>>> b.add("hello")
False
>>> b.add("hello")
True
"""
bitarray = self.bitarray
bits_per_slice = self.bits_per_slice
hashes = self.make_hashes(key)
if not skip_check and hashes in self:
return True
if self.count > self.capacity:
raise IndexError("BloomFilter is at capacity")
offset = 0
for k in hashes:
self.bitarray[offset + k] = True
offset += bits_per_slice
self.count += 1
return False
def copy(self):
"""Return a copy of this bloom filter.
"""
new_filter = BloomFilter(self.capacity, self.error_rate)
new_filter.bitarray = self.bitarray.copy()
return new_filter
def union(self, other):
""" Calculates the union of the two underlying bitarrays and returns
a new bloom filter object."""
if self.capacity != other.capacity or \
self.error_rate != other.error_rate:
raise ValueError("Unioning filters requires both filters to have \
both the same capacity and error rate")
new_bloom = self.copy()
new_bloom.bitarray = new_bloom.bitarray | other.bitarray
return new_bloom
def __or__(self, other):
return self.union(other)
def intersection(self, other):
""" Calculates the union of the two underlying bitarrays and returns
a new bloom filter object."""
if self.capacity != other.capacity or \
self.error_rate != other.error_rate:
raise ValueError("Intersecting filters requires both filters to \
have equal capacity and error rate")
new_bloom = self.copy()
new_bloom.bitarray = new_bloom.bitarray & other.bitarray
return new_bloom
def __and__(self, other):
return self.intersection(other)
def tofile(self, f):
"""Write the bloom filter to file object `f'. Underlying bits
are written as machine values. This is much more space
efficient than pickling the object."""
f.write(pack(self.FILE_FMT, self.error_rate, self.num_slices,
self.bits_per_slice, self.capacity, self.count))
self.bitarray.tofile(f)
@classmethod
def fromfile(cls, f, n=-1):
"""Read a bloom filter from file-object `f' serialized with
``BloomFilter.tofile''. If `n' > 0 read only so many bytes."""
headerlen = calcsize(cls.FILE_FMT)
if 0 < n < headerlen:
raise ValueError('n too small!')
filter = cls(1) # Bogus instantiation, we will `_setup'.
filter._setup(*unpack(cls.FILE_FMT, f.read(headerlen)))
filter.bitarray = bitarray.bitarray(endian='little')
if n > 0:
filter.bitarray.fromfile(f, n - headerlen)
else:
filter.bitarray.fromfile(f)
if filter.num_bits != filter.bitarray.length() and \
(filter.num_bits + (8 - filter.num_bits % 8)
!= filter.bitarray.length()):
raise ValueError('Bit length mismatch!')
return filter
def __getstate__(self):
d = self.__dict__.copy()
del d['make_hashes']
return d
def __setstate__(self, d):
self.__dict__.update(d)
self.make_hashes = make_hashfuncs(self.num_slices, self.bits_per_slice)
class ScalableBloomFilter(object):
SMALL_SET_GROWTH = 2 # slower, but takes up less memory
LARGE_SET_GROWTH = 4 # faster, but takes up more memory faster
FILE_FMT = '<idQd'
def __init__(self, initial_capacity=100, error_rate=0.001,
mode=SMALL_SET_GROWTH):
"""Implements a space-efficient probabilistic data structure that
grows as more items are added while maintaining a steady false
positive rate
initial_capacity
the initial capacity of the filter
error_rate
the error_rate of the filter returning false positives. This
determines the filters capacity. Going over capacity greatly
increases the chance of false positives.
mode
can be either ScalableBloomFilter.SMALL_SET_GROWTH or
ScalableBloomFilter.LARGE_SET_GROWTH. SMALL_SET_GROWTH is slower
but uses less memory. LARGE_SET_GROWTH is faster but consumes
memory faster.
>>> b = ScalableBloomFilter(initial_capacity=512, error_rate=0.001, \
mode=ScalableBloomFilter.SMALL_SET_GROWTH)
>>> b.add("test")
False
>>> "test" in b
True
>>> unicode_string = u'¡'
>>> b.add(unicode_string)
False
>>> unicode_string in b
True
"""
if not error_rate or error_rate < 0:
raise ValueError("Error_Rate must be a decimal less than 0.")
self._setup(mode, 0.9, initial_capacity, error_rate)
self.filters = []
def _setup(self, mode, ratio, initial_capacity, error_rate):
self.scale = mode
self.ratio = ratio
self.initial_capacity = initial_capacity
self.error_rate = error_rate
def __contains__(self, key):
"""Tests a key's membership in this bloom filter.
>>> b = ScalableBloomFilter(initial_capacity=100, error_rate=0.001, \
mode=ScalableBloomFilter.SMALL_SET_GROWTH)
>>> b.add("hello")
False
>>> "hello" in b
True
"""
for f in reversed(self.filters):
if key in f:
return True
return False
def add(self, key):
"""Adds a key to this bloom filter.
If the key already exists in this filter it will return True.
Otherwise False.
>>> b = ScalableBloomFilter(initial_capacity=100, error_rate=0.001, \
mode=ScalableBloomFilter.SMALL_SET_GROWTH)
>>> b.add("hello")
False
>>> b.add("hello")
True
"""
if key in self:
return True
filter = self.filters[-1] if self.filters else None
if filter is None or filter.count >= filter.capacity:
num_filters = len(self.filters)
filter = BloomFilter(
capacity=self.initial_capacity * (self.scale ** num_filters),
error_rate=self.error_rate * (self.ratio ** num_filters))
self.filters.append(filter)
filter.add(key, skip_check=True)
return False
@property
def capacity(self):
"""Returns the total capacity for all filters in this SBF"""
return sum([f.capacity for f in self.filters])
@property
def count(self):
return len(self)
def tofile(self, f):
"""Serialize this ScalableBloomFilter into the file-object
`f'."""
f.write(pack(self.FILE_FMT, self.scale, self.ratio,
self.initial_capacity, self.error_rate))
# Write #-of-filters
f.write(pack('<l', len(self.filters)))
if len(self.filters) > 0:
# Then each filter directly, with a header describing
# their lengths.
headerpos = f.tell()
headerfmt = '<' + 'Q'*(len(self.filters))
f.write('.' * calcsize(headerfmt))
filter_sizes = []
for filter in self.filters:
begin = f.tell()
filter.tofile(f)
filter_sizes.append(f.tell() - begin)
f.seek(headerpos)
f.write(pack(headerfmt, *filter_sizes))
@classmethod
def fromfile(cls, f):
"""Deserialize the ScalableBloomFilter in file object `f'."""
filter = cls()
filter._setup(*unpack(cls.FILE_FMT, f.read(calcsize(cls.FILE_FMT))))
nfilters, = unpack('<l', f.read(calcsize('<l')))
if nfilters > 0:
header_fmt = '<' + 'Q'*nfilters
bytes = f.read(calcsize(header_fmt))
filter_lengths = unpack(header_fmt, bytes)
for fl in filter_lengths:
filter.filters.append(BloomFilter.fromfile(f, fl))
else:
filter.filters = []
return filter
def __len__(self):
"""Returns the total number of elements stored in this SBF"""
return sum([f.count for f in self.filters])
if __name__ == "__main__":
import doctest
doctest.testmod()
参考文章
1,pybloom
http://pydoc.net/Python/pybloom/1.0.3/pybloom.pybloom/
2, 基于布隆过滤器算法的网页消重技术的实现与应用















 339
339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









