







我们在实现算法时使用了几种结构性的原语(普通语句、条件语句、循环、嵌套语句和方法调用),所以成本增长的数量级一般都是问题规模N的若干函数之一。下表总结了这些函数以及他们的称谓、与之对应的典型代码以及一些例子。
| 描述 | 增长的数量级 | 典型代码 | 说明 | 举例 |
| 常熟级别 | 1 | a = b + c | 普通语句 | 将两个数相加 |
| 对数级别 | logN | 可查看另外的博客二分查找里面的代码 | 二分策略 | 二分查找 |
| 线性级别 | N | double max = a[0]; for(int i = 1; i < N; ++i) if(a[i] > max) max = a[i] | 循环 | 找出最大元素 |
| 线性对数级别 | NlogN | 分治 | 归并排序 | |
| 平方级别 | N^2 | for(int i = 0; i < N; i++) for(int j = i + 1; j < N; j++) if(a[i] + a[j] == 0) cnt++; | 双层循环 | 检查所有元素对 |
| 立方级别 | N^3 | for(int i = 0; i < N; i++) for(int j = i + 1; j < N; j++) for(int k = j + 1; k++) if(a[i] + a[j] + a[k]== 0) cnt++; | 三层循环 | 检查所有三元组 |
| 指数级别 | 2^N | 穷举查找 | 检查所有子集 |
1.常熟级别
运行时间的增长数量级为常熟的程序完成它的任务所需的操作次数一定,因此它的运行时间不依赖于N。大多数操作所需的时间均为常熟。
2.对数级别
运行时间的增长数量级为对数的程序仅比常熟时间的程序稍慢。运行时间和问题规模成对数关系的程序的经典例子就是二分查找。对数的底数和增长的数量级无关(因为不同的底数仅相当于一个常数因子),所以我们在说明对数级别时一般使用logN。
3.线性级别
使用常数时间处理输入数据中的所有元素或是基于单个for循环的程序十分常见的。此类程序的增长数量级是线性的——它的运行时间和N成正比。
4.线性对数级别
我们用线性对数描述运行时间和问题规模N的关系为NlogN的程序。和之前一样,对数的底数和增长的数量级无关。线性对数算法的典型例子是归并排序。
5.平方级别
一个运行时间的增长数量级为N^2的程序一般都含有两个嵌套的for循环,对有N个元素得到的所有元素进行计算。
6.立方级别
一个运行时间的增长数量级为N^3的程序一般都包含有三个嵌套的for循环,对由N个元素得到的所有三元组进行计算。
7.指数级别
一般我们会使用指数级别来描述增长数量级为b^N的算法,其中b > 1且为常熟,尽管不同的b值得到的运行时间可能完全不同。指数级别的算法非常慢——不可能用他们解决大规模的问题。但指数级别的算法仍然在算法理论中有着重要的地位。因为他们看起来仍然是解决许多问题的最佳方案。
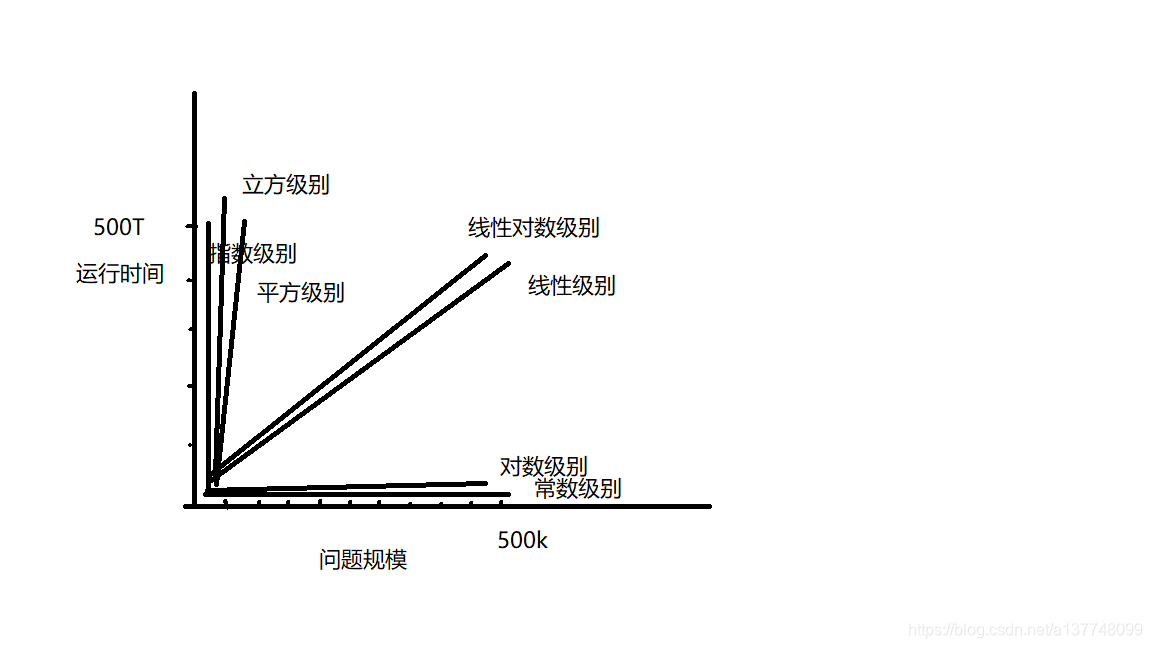
下面画了个草图,直观进行对比:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









