






what?
1、什么是容器
容器就是编程语言提供给我们开发者使用的对象(包含性质)
why?
2、为什么学习容器
大量数据的时候,批量的管理和操作大量数据
where\when
3、什么时候用
大量数据、特殊数据
4、怎么用户(how)
python官方为大家提供四种常见的容器
|-- list 列表
|-- set 集合
|-- tuple 元组
|-- dict 字典
list:
有序的数列
在程序中,线性表:数组、链表、栈、队列
python的list底层就是基于双向链表结构设计的
如何定义list
1、借助弱数据类型语言的特点
[] # 列表是以[]的形式表现
ls = [] # 空列表
ls = [1, 2,3,4,5,6] # 创建了一个有如下元素的列表
2、借助python提供的一个全局函数创建list
ls = list()
ls = list([1,23,3,4,4554])
访问list中的元素(element)
线性表,都是具有下标(索引)的
列表对象[下标]
注意:下标从0开始,注意下标越界问题!!!
print(ls[4]) # 访问ls中的第五个元素
ls[1] = 100 # 将ls列表中的第二个元素值修改为100
如何统计list中的元素:
全局函数:len()
如何遍历列表
使用循环遍历
for index in ls2:
print(index)
# 使用while循环遍历列表
index = 0
while index < len(ls2):
print(ls2[index])
index += 1
list的常见方法:
[‘append’, ‘clear’, ‘copy’, ‘count’, ‘extend’, ‘index’,
‘insert’, ‘pop’, ‘remove’, ‘reverse’, ‘sort’]
|-- append(元素) # 在列表尾部追加元素
|-- insert(index, 元素) # 在对应索引为插入元素
|-- remove(元素) # 移除元素,如果不存在,则报错
|-- pop(index=-1) # 默认移除最后一个元素,如果存在参数,则该参数就是要移除的下标,注意:下标有误,会抛出异常
|-- clear() # 清空列表
|-- reverse() # 翻转列表元素顺序
|-- sort() # 排序
|-- index(元素) # 查找元素的位置
|-- count(元素) # 统计元素的数量
|-- extend # 合并列表
|-- copy() # 复制列表对象,其本质是浅拷贝
set(集合)
特点:1、无序的;2、不能重复
底层使用的hash表(哈希表)的结构设计的
定义
1、借助弱数据类型语言的特点
注意:必须要存在值,否则默认空{}是字典类型,而不是set
s = {1,2,4}
2、全局set函数
s = set()
遍历只能使用for循环遍历,while没有办法遍历(无序)
常见方法:
'add', 'clear', 'copy', 'difference', 'difference_update',
'discard', 'intersection', 'intersection_update',
'isdisjoint', 'issubset', 'issuperset', 'pop',
'remove', 'symmetric_difference',
'symmetric_difference_update', 'union', 'update']
|-- add() # 添加元素
|-- clear() # 清除列表
|-- copy() # 浅拷贝对象
|-- difference() # 差集
|-- intersection() # 交集
|-- union() # 并集
|-- remove(元素) # 移除元素,如果不存在,则报错
|-- pop(元素) # 随机(arbitrary)移除,不存在,则报错
|-- discard(元素) # 随机(arbitrary)移除,不存在,则什么都不做
tuple(元组)
不可变数据类型,就是说,它里面的元素是不允许被修改的!!
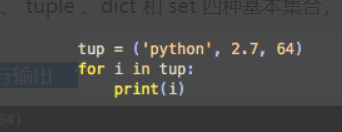
tuple 类型举例
注明:程序将以此按行输出 ‘python’, 2.7 和 64。
定义和前面的一样,也存在两种方式
常见方法:
|-- count # 统计元素个数
|-- index # 查看元素索引位置
***注意:
t = (1)
t = (1.)
解释:表示浮点数,其实是省略了.后面的0。 整数和浮点数各有各的用途,按需选择。其实.前面的0也可以省略如print(.618),但是小数部分和整数部分至少要写一个,光写个.是不会被认成数值的。(PS:摘自知乎)***
字典:
定义:
d = {}
d = {k1: v1, k2: v2}
d = dict({…})

要先定义,然后再进入集合。
可以使用key访问到key对应的值
d[“k1”]
d.get(“k2”)
p["name"] = "lisi" # 增加键值对
常见方法:
clear', 'copy', 'fromkeys', 'get', 'items',
'keys', 'pop', 'popitem', 'setdefault',
'update', 'values']
|-- clear
|-- copy
|-- get
|-- keys() # 将所有的key返回
|-- values() # 将所有的值返回
|-- setdefault
|-- items() # 一对一对的返回
|-- pop(key) # 通过key删除对应键值对
|-- popitem() # 安装 LIFO (last-in, first-out) order 删除键值对,遵循后进先出原则。
(**什么叫遍历?
所谓遍历(Traversal),字面意思是遍历就是全部走遍,到处周游的意思。程序代码上的意思是指沿着某条搜索路线,依次对树中每个结点均做一次且仅做一次访问,访问结点所做的操作依赖于具体的应用问题。**)
字典的遍历方式:
1、
for key in p:
print(key, p[key])
2、
for key in p.keys():
print(key , p.get(key))
3、
for key, value in p.items():
print(key, value)
for (key, value) in p.items():
print(key, value)
for t in p.items():
print(t[0], t[1])
***一、for循环遍历
lists = [“m1”, 1900, “m2”, 2000]
for item in lists:
print(item)
lists = [“m1”, 1900, “m2”, 2000]
for item in lists:
item = 0;
print(lists)
运行结果:
[‘m1’, 1900, ‘m2’, 2000]
二、while循环遍历:
lists = [“m1”, 1900, “m2”, 2000]
count = 0
while count < len(lists):
print(lists[count])
count = count + 1
lists = [“m1”, 1900, “m2”, 2000]
count = 0
while count < len(lists):
print(lists[count])
count = count + 1
三、索引遍历:
for index in range(len(lists)):
print(lists[index])***
全局函数:
print()
input()
type()
range()
list()
len()
exit()
help() # 调用帮助问题
dir() # 查询对象的所有属性或者方法
reverse() # 翻转列表
什么是len函数?
描述
len函数返回序列类型对象(字符或字符串、元组、列表和字典等)的项目个数(长度)。
语法
len(object)
函数返回一个大于0的int型整数,表示对象的项目个数。
实例
- 当参数是序列类型对象(字符、字符串、列表、元组或者是字典)时:
test = [1, 3, 5, ‘sdw’]
print(len(test))
程序的返回值是4.
- 当参数是非序列对象时:
print(len(45.36))
运行报错:
Traceback (most recent call last):
File “/Users/untitled3/myapps/Test.py”, line 1, in
print(len(45.36))
TypeError: object of type ‘float’ has no len()
注意事项
-
当参数是字典时,len函数返回的是字典中的键值对数量
-
当参数是非序列对象时,Python会报错















 2464
2464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









