Hive on Spark 详解
安装准备
- 修改好的hive源码包 apache-hive-3.1.3-src.zip
- 纯净版spark安装包 spark-3.2.2-bin-without-hadoop.tgz
- maven程序 apache-maven-3.6.1-bin.tar.gz
下载地址
https://pan.baidu.com/s/1e4JGWbzGv-e0xpPB_G3nqQ?pwd=g7gz
提取码:g7gz
复制这段内容打开「百度网盘APP 即可获取」
安装Maven
- 解压
tar -zxvf apache-maven-3.6.1-bin.tar.gz -C /opt/module/
mv apache-maven-3.6.1-bin maven-3.6.1
- 创建本地maven仓库文件夹
mkdir -p /opt/module/maven_repo
- 配置maven setting
<localRepository>/opt/module/maven_repo</localRepository>
<mirrors>
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirrors>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>spring-plugin</name>
<url>https://maven.aliyun.com/repository/spring-plugin</url>
</mirror>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>*,!cloudera</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
</mirrors>
编译HIVE并安装
- 解压
unzip apache-hive-3.1.3-src.zip
- 编译打包
mvn clean package -Pdist -DskipTests -Dmaven.javadoc.skip=true
mvn clean package -Pdist -DskipTests
- 单独对 Webhcat模块打包
cd hcatalog
mvn package -Pdist -DskipTests
cd ..
mvn clean package -Pdist -DskipTests
- 打包完成 将target下面文件拿出来
mv /opt/software/apache-hive-3.1.3-src/packaging/target/apache-hive-3.1.3-bin /opt/module
cd /opt/module
mv apache-hive-3.1.3-bin hive-3.1.3
- 修改hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl" ?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>
jdbc:mysql://hadoop102:3306/hive?createDatabaseIfNotExist=true
</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop102:8020/spark-jars/*</value> </property>
<property>
<name>hive.spark.client.connect.timeout</name>
<value>10000ms</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>
</configuration>
- hdfs 创建目录
hdfs dfs -mkdir spark-history
- 在conf目录下创建spark配置文件spark-default.xml
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:8020/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
安装spark并配置
- 解压
tar -zxvf spark-3.2.2-bin-without-hadoop.tgz -C /opt/module
mv spark-3.2.2-bin-without-hadoop spark-3.2.2
- spark-env.sh
HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
- spark-defaults.conf
spark.yarn.historyServer.address hadoop102:18080
spark.yarn.jars hdfs://hadoop102:8020/spark-jars/*
- jars下面Jar包修改
rm -f log4j-1.2.17.jar
rm -f parquet-hadoop-1.12.2.jar
cd /opt/module/hive-3.1.3/lib/
cp /opt/module/hive-3.1.3/lib/log4j-*.jar parquet-hadoop-bundle-1.10.0.jar hive-beeline-3.1.3.jar hive-cli-3.1.3.jar hive-exec-3.1.3.jar hive-jdbc-3.1.3.jar hive-metastore-3.1.3.jar log4j-*.jar /opt/module/spark-3.2.2/jars/
hdfs dfs -mkdir /spark-jars
hdfs dfs -put /opt/module/spark-3.2.2/jars/* /opt/module/spark-3.2.2/jars/
启动测试
- hive-3.1.3/lib下添加jar
cp kryo-shaded-4.0.2.jar minlog-1.3.0.jar scala-xml_2.12-1.2.0.jar spark-core_2.12-3.2.2.jar chill-java-0.10.0.jar chill_2.12-0.10.0.jar jackson-module* jersey-container-servlet-core* jersey-server-2.34.jar json4s-ast_2.12-3.7.0-M11.jar spark-launcher_2.12-3.2.2.jar spark-network-shuffle_2.12-3.2.2.jar spark-unsafe_2.12-3.2.2.jar xbean-asm9-shaded-4.20.jar /opt/module/hive/lib
- bin/hive
select count(1) from student;
- 运行结果
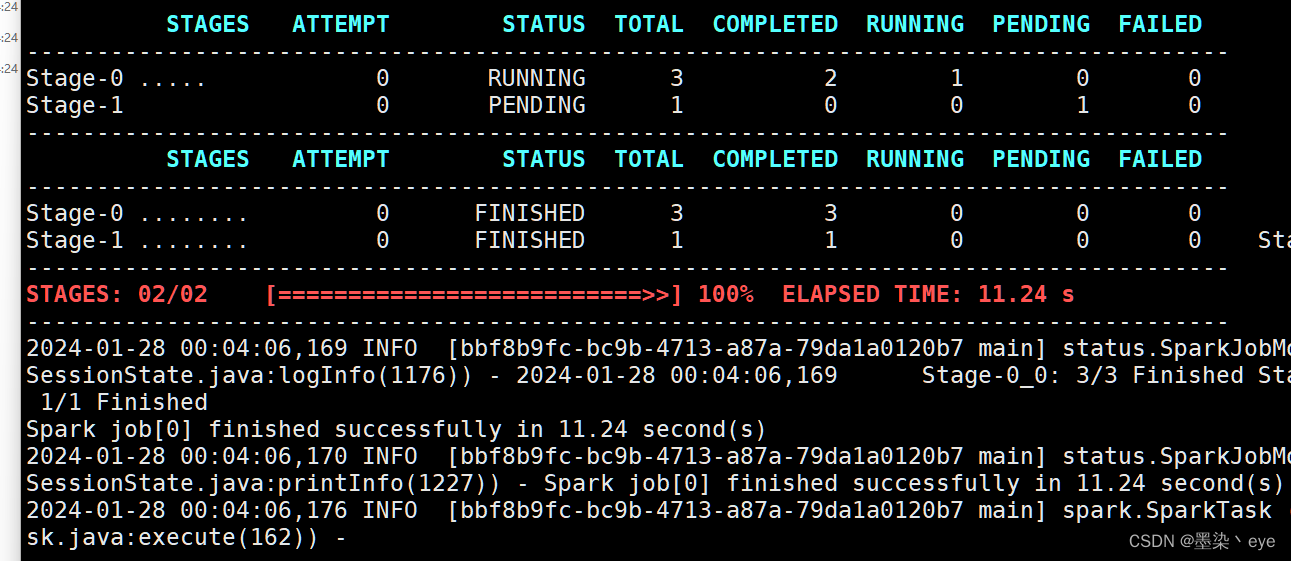






















 6585
6585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









