







一、案例背景
我的朋友海伦一直使用在线约会网站寻找合适自己的约会对象。尽管约会网站会推荐不同的人选,但她并不是喜欢每一个人。经过一番总结,她发现曾交往过三种类型的人:
(1)不喜欢的人;
(2)魅力一般的人;
(3)极具魅力的人;
尽管发现了上述规律,但海伦依然无法将约会网站推荐的匹配对象归入恰当的分类,她觉得可以在周一到周五约会那些魅力一般的人,而周末则更喜欢与那些极具魅力的人为伴。海伦希望我们的分类软件可以更好地帮助她将匹配对象划分到确切的分类中。此外,海伦还收集了一些约会网站未曾记录的数据信息,她认为这些数据更助于匹配对象的归类。
二、案例分析
(1)收集数据:提供文本文件;
(2)准备数据:使用Python解析文本文件;
(3)分析数据:使用Matplotlib画二维扩散图;
(4)训练算法:此步骤不适用于K-近邻算法;
(5)测试算法:使用海伦提供的部分数据作为测试样本,
测试样本和非测试样本的区别在于:测试样本是已经完成分类的数据,如果预测分类与实际类别不同,则标记为一个错误。
(6)使用算法:产生简单的命令行程序,然后海伦可以输入一些特征数据以判断对方是否为自己喜欢的类型。
三、准备数据:从文本文件中解析数据
海伦收集约会数据已经有了一段时间,她把这些数据存放在文本文件datingTestSet.txt中,每个样本数据占据一行,总共有1000行。海伦的样本主要包括以下3种特征:
1.每年获得的飞行常客里程数;
2.玩视频游戏所耗时间百分比;
3.每周消费的冰淇淋公升数;
在将上述特征数据输入到分类器之前,必须将待处理数据的格式改变为分类器可以接受的格式。在kNN.py中创建名为file2matrix的函数,以此来处理输入格式问题。该函数的输入为文本文件名字符串,输出为训练样本矩阵和类标签向量。
将下面的代码增加到kNN.py中:

四、分析数据:使用Matplotlib创建散点图
首先我们使用Matplotlib制作原始数据的散点图,在Python命令行环境中,输入下列命令:
- #!/usr/bin/python278
- # _*_ coding: utf-8 _*_
- import kNN
- reload(kNN)
- datingDataMat,datingLabels=kNN.file2matrix('datingTestSet2.txt')
- import matplotlib
- import matplotlib.pyplot as plt
- zhfont = matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\ukai.ttc')
- fig=plt.figure()
- ax=fig.add_subplot(111)
- from numpy import *
- ax.scatter(datingDataMat[:,1],datingDataMat[:,2])
- plt.xlabel(u'玩游戏所耗时间百分比', fontproperties=zhfont)
- plt.ylabel(u'每周消费的冰淇淋公升数', fontproperties=zhfont)
- plt.show()
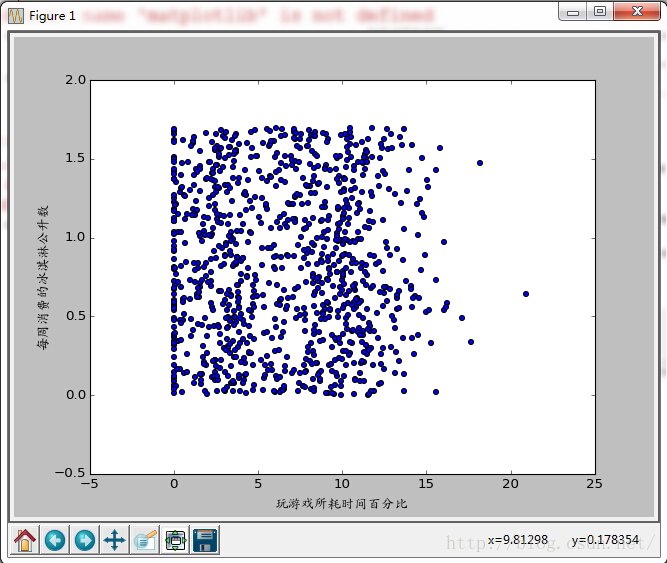
- #!/usr/bin/python278
- # _*_ coding: utf-8 _*_
- import kNN
- reload(kNN)
- datingDataMat,datingLabels=kNN.file2matrix('datingTestSet2.txt')
- import matplotlib
- import matplotlib.pyplot as plt
- zhfont = matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\ukai.ttc')
- fig=plt.figure()
- ax=fig.add_subplot(111)
- from numpy import *
- ax.scatter(datingDataMat[:,1],datingDataMat[:,2],15.0*array(datingLabels),15.0*array(datingLabels))
- plt.xlabel(u'玩游戏所耗时间百分比', fontproperties=zhfont)
- plt.ylabel(u'每周消费的冰淇淋公升数', fontproperties=zhfont)
- plt.show()
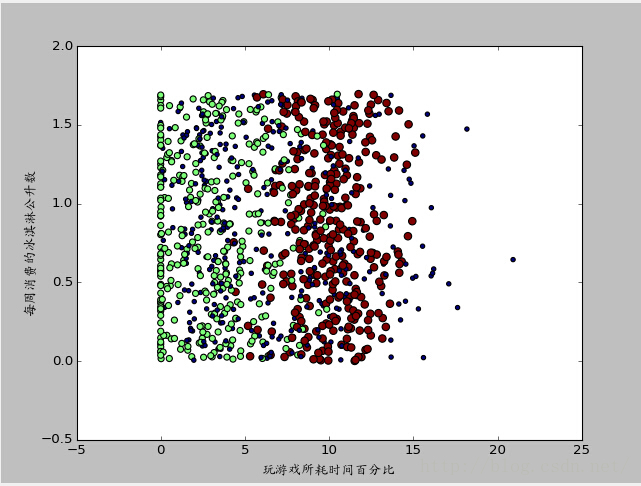
上图是带有样本分类标签的约会数据散点图,虽然能够比较容易地区分数据点从属类别,但依然很难根据这张图得出结论信息。
上图使用了datingDataMat矩阵属性列2和列3展示数据,虽然也可以区别,但下图采用列1和列2的属性值却可以得到更好的效果:
- #!/usr/bin/env python
- # _*_ coding: utf-8 _*_
- import kNN
- reload(kNN)
- import matplotlib
- import matplotlib.pyplot as plt
- matrix, labels = kNN.file2matrix('datingTestSet2.txt')
- print matrix
- print labels
- zhfont = matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\ukai.ttc')
- plt.figure(figsize=(8, 5), dpi=80)
- axes = plt.subplot(111)
- # 将三类数据分别取出来
- # x轴代表飞行的里程数
- # y轴代表玩视频游戏的百分比
- type1_x = []
- type1_y = []
- type2_x = []
- type2_y = []
- type3_x = []
- type3_y = []
- print 'range(len(labels)):'
- print range(len(labels))
- for i in range(len(labels)):
- if labels[i] == 1: # 不喜欢
- type1_x.append(matrix[i][0])
- type1_y.append(matrix[i][1])
- if labels[i] == 2: # 魅力一般
- type2_x.append(matrix[i][0])
- type2_y.append(matrix[i][1])
- if labels[i] == 3: # 极具魅力
- print i, ':', labels[i], ':', type(labels[i])
- type3_x.append(matrix[i][0])
- type3_y.append(matrix[i][1])
- type1 = axes.scatter(type1_x, type1_y, s=20, c='red')
- type2 = axes.scatter(type2_x, type2_y, s=40, c='green')
- type3 = axes.scatter(type3_x, type3_y, s=50, c='blue')
- # plt.scatter(matrix[:, 0], matrix[:, 1], s=20 * numpy.array(labels),
- # c=50 * numpy.array(labels), marker='o',
- # label='test')
- plt.xlabel(u'每年获取的飞行里程数', fontproperties=zhfont)
- plt.ylabel(u'玩视频游戏所消耗的事件百分比', fontproperties=zhfont)
- axes.legend((type1, type2, type3), (u'不喜欢', u'魅力一般', u'极具魅力'), loc=2, prop=zhfont)
- plt.show()
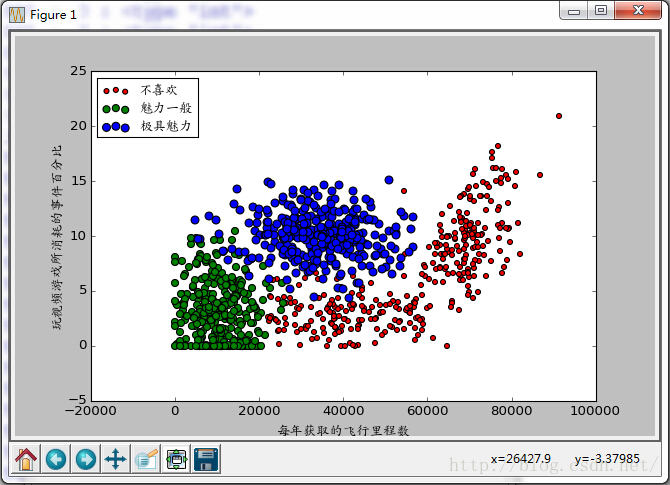
图中清晰的标识了三个不同的样本分类区域,具有不同爱好的人其类别区域也不同,可以看出用图中展示的“每年获取飞行常客里程数”和“玩视频游戏所耗时间百分比”两个特征更容易区分数据点从属的类别。
- def autoNorm(dataSet):
- minVals = dataSet.min(0)
- maxVals = dataSet.max(0)
- ranges = maxVals - minVals
- normDataSet = zeros(shape(dataSet))
- m = dataSet.shape[0]
- normDataSet = dataSet - tile(minVals, (m,1))
- normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
- return normDataSet, ranges, minVals
代码讲解:函数autoNorm()中,每列的最小值放在变量minVals中,最大值放在maxVals中,其中dataSet.min(0)中的参数0使得函数可以从列中选取最小值,而不是选取当前行的最小值。因为特征值矩阵dataSet是1000X3,而minVals和range都是1X3,所以需要利用tile()函数将minVals和range的内容复制成输入矩阵同样大小的矩阵。
- >>> import kNN
- >>> reload(kNN)
- <module 'kNN' from 'kNN.pyc'>
- >>> datingDataMat,datingLabels=kNN.file2matrix('datingTestSet2.txt')
- >>> normMat,ranges,minVals=kNN.autoNorm(datingDataMat)
- >>> normMat
- array([[ 0.44832535, 0.39805139, 0.56233353],
- [ 0.15873259, 0.34195467, 0.98724416],
- [ 0.28542943, 0.06892523, 0.47449629],
- ...,
- [ 0.29115949, 0.50910294, 0.51079493],
- [ 0.52711097, 0.43665451, 0.4290048 ],
- [ 0.47940793, 0.3768091 , 0.78571804]])
- >>> ranges
- array([ 9.12730000e+04, 2.09193490e+01, 1.69436100e+00])
- >>> minVals
- array([ 0. , 0. , 0.001156])
六、测试算法
机器学习算法中一个很重要的工作就是评估算法的正确率,通常我们会将已有数据的90%作为训练样本来训练分类器,而使用其余10%的数据去测试分类器,检测分类器的正确率。
1.分类器对约会网站的测试代码:
- def datingClassTest():
- hoRatio = 0.50 #hold out 10%
- datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') #load data setfrom file
- normMat, ranges, minVals = autoNorm(datingDataMat)
- m = normMat.shape[0]
- numTestVecs = int(m*hoRatio)
- errorCount = 0.0
- for i in range(numTestVecs):
- classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
- print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])
- if (classifierResult != datingLabels[i]): errorCount += 1.0
- print "the total error rate is: %f" % (errorCount/float(numTestVecs))
- print errorCount
- >>> kNN.datingClassTest()
- the classifier came back with: 3, the real answer is: 3
- the classifier came back with: 2, the real answer is: 2
- the classifier came back with: 1, the real answer is: 1
- the classifier came back with: 1, the real answer is: 1
- the classifier came back with: 1, the real answer is: 1
- the classifier came back with: 1, the real answer is: 1
- the classifier came back with: 3, the real answer is: 3
- the classifier came back with: 3, the real answer is: 3
- the classifier came back with: 1, the real answer is: 1
- the classifier came back with: 3, the real answer is: 3
- the classifier came back with: 1, the real answer is: 1
- the classifier came back with: 1, the real answer is: 1
.
- the classifier came back with: 1, the real answer is: 1
- the classifier came back with: 1, the real answer is: 1
- the classifier came back with: 1, the real answer is: 1
- the classifier came back with: 3, the real answer is: 3
- the classifier came back with: 1, the real answer is: 1
- the classifier came back with: 2, the real answer is: 1
- the classifier came back with: 2, the real answer is: 2
- the classifier came back with: 1, the real answer is: 1
- the classifier came back with: 1, the real answer is: 1
- the classifier came back with: 2, the real answer is: 2
- the total error rate is: 0.064000
七、使用算法
输入某人信息,预测出海伦对对方喜欢程度:- def classifyPerson():
- resultList=['not at all','in small doses','in large doses']
- percentTats=float(raw_input("percentage of time spent playing video games?"))
- ffMiles=float(raw_input("frequent flier miles earned per year?"))
- iceCream=float(raw_input("liters of ice cream consumed per year?"))
- datingDataMat,datingLabels=file2matrix('datingTestSet2.txt')
- normMat,ranges,minVals=autoNorm(datingDataMat)
- inArr=array([ffMiles,percentTats,iceCream])
- classifierResult=classify0((inArr-minVals)/ranges,normMat,datingLabels,3)
- print "You will probably like this person:",resultList[classifierResult-1]
- >>> import kNN
- >>> reload(kNN)
- <module 'kNN' from 'kNN.py'>
- >>> kNN.classifyPerson()
- percentage of time spent playing video games?10
- frequent flier miles earned per year?10000
- liters of ice cream consumed per year?0.5
- You will probably like this person: in small doses















 6591
6591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









