






参与者被授予三种不同的角色,即更新提供者、聚合者和验证者。更新提供者用于基于其私有训练数据来训练模型并将其本地更新共享给聚合器。它独立工作。聚合器负责收集本地更新并选择其中一定数量的更新来聚合全局更新。它也可以独立工作。验证者共同主持选择合适的全局更新,并将其与验证者私钥创建的数字签名以及聚合器和更新提供者的身份打包到新添加到区块链中的块中。他们独立评分全局更新,并协作选择一个全局更新。图1中独立和协作的步骤用不同的颜色标记。在BlockDFL中,添加一个块意味着所有参与者都进行了一轮通信(相当于在FL中执行一次FedAVG算法)。如果该块不为空,则所有参与者将根据新添加的块中包含的全局更新来更新其模型。
在每轮通信开始时,每个参与者都会根据最后一个块的哈希值随机分配一个角色(如过程①所示)然后,更新提供者在自己的训练集上使用随机梯度下降 (SGD) 算法训练本地模型,并通过梯度压缩稀疏本地更新,然后将其广播到聚合器(过程②)。每个聚合器持续接收本地更新,直到获得一定数量的本地更新,然后独立地开始聚合(过程③)。聚合器首先根据相应提供者的权益从接收到的本地更新中采样一定数量的本地更新。然后,它对采样的本地更新进行评分,并选择其中的一些来聚合全局更新,然后将其广播给验证者。当验证者收到足够的全局更新(例如,来自绝大多数聚合器的全局更新)时,验证开始(过程④)。每个验证者独立对全局更新进行评分,并根据评分对其进行投票,从而选择一个认可的全局更新。最后,批准的全局更新及其相关信息被包装在一个新的块中,然后广播给所有参与者。

为了在每一轮中选出唯一合适的全局更新,我们简化了去中心化 FL 的 PBFT,并基于简化的 PBFT 设计了一种基于投票的验证机制,该机制具有以下优点:(1)由于验证者是一小群随机选择的参与者,因此效率很高。(2)可以处理恶意参与者和断线问题,即使是PBFT的领导者(3)它永远不会分叉。
第一个选定的验证者是验证者的Leader,逐一发起全局更新的验证。这种验证的顺序可以由Leader决定。提议的投票机制中,每次全局更新都需要经历三个阶段,即pre-prepare, prepare, commit。令![]() 为本轮通信中候选全局更新的集合。假设Gi ∈
为本轮通信中候选全局更新的集合。假设Gi ∈![]() 是第一个选择的要验证的全局更新。在对 Gi 的验证中,Leader首先向其他验证者发送带有 Gi 数字签名的 pre-prepare 消息。当验证者收到pre-prepare消息时,它向所有验证者广播带有Gi数字签名的prepare消息。当验证者收到超过 2/3|V| 时prepare消息,它开始commit阶段。在commit中,验证者通过 Krum对每个 Gi 进行评分,其中较低的分数表示较高的质量。令 f 为恶意参与者的百分比,
是第一个选择的要验证的全局更新。在对 Gi 的验证中,Leader首先向其他验证者发送带有 Gi 数字签名的 pre-prepare 消息。当验证者收到pre-prepare消息时,它向所有验证者广播带有Gi数字签名的prepare消息。当验证者收到超过 2/3|V| 时prepare消息,它开始commit阶段。在commit中,验证者通过 Krum对每个 Gi 进行评分,其中较低的分数表示较高的质量。令 f 为恶意参与者的百分比,![]() 表示最接近 Gi 的 (1−f)
表示最接近 Gi 的 (1−f) ![]() −2 全局更新,Krum 通过计算 Gi 到
−2 全局更新,Krum 通过计算 Gi 到 ![]() 中全局更新的距离来对 Gi 进行评分,如下:
中全局更新的距离来对 Gi 进行评分,如下:

![]() 中其他全局更新的得分以相同的方式计算(图中的步骤4-1)。然后验证者向领导者发送一条签名的提交消息,其中包含对 Gi 的投票。只有Gi的得分超过2/3全局更新的得分才能对Gi投赞成票,如下:
中其他全局更新的得分以相同的方式计算(图中的步骤4-1)。然后验证者向领导者发送一条签名的提交消息,其中包含对 Gi 的投票。只有Gi的得分超过2/3全局更新的得分才能对Gi投赞成票,如下:

其中1和0分别表示赞成票和反对票。Ⅱ是指示函数,满足条件时值为1,否则为0。
如果Leader收到超过 2/3|V|commit消息并获得肯定票,验证结束,Gi成为本轮通信批准的全局更新(图中的步骤4-2)。然后Leader构建一个区块,其中包含:(1)Gi 的元素,(2)Gi 聚合者和更新提供者的身份,以及(3)投票支持的验证者的身份。该区块由Leader签名并广播给所有参与者(图中的步骤 4-3)。(2)和(3)中列出的参与者均等地获得股份。然而,如果Leader收到的反对票提交消息数量超过1/3|V|,则Gi的验证结束,Leader开始验证另一个全局更新Gj。需要注意的是,在后续全局更新的验证中,可以直接使用第一次全局更新验证时得到的分数。如果 G 中的所有全局更新都经过验证但没有人获得批准,则Leader会广播一个空块。当参与者收到一个块时,如果该块包含已批准的全局更新,它将更新本地模型。然后下一轮沟通开始。
值得注意的是,领导者的恶意行为能力是有限的,因为只有获得超过 2/3 验证者的赞成票,领导者才能广播全局更新。如果没有获得超过2/3验证者的投票,则只能选择验证下一次全局更新或结束本轮通信。因此,如果Leader是恶意的,它可以对系统造成损害的就是拒绝其他验证者的投票并广播一个空块来延迟 FL 的迭代。
《Blockchain-based Federated Learning with Secure Aggregation in Trusted Execution Environment for Internet-of-Things》中的模型验证与共识
基于区块链的防篡改全局模型存储与分发
在此阶段,区块链网络接收 SGX enclave 生成的所有远程证明并运行共识机制。共识机制验证新交所飞地生成的全局模型的远程证明。如果所有远程证明都经过验证,并且相应模型的大多数哈希值相同,则区块链网络中的区块链节点将全局模型MG作为区块添加到区块链中。此外,全局模型作为更新操作FL被发送到所有边缘服务器。图 6 给出了该步骤的概述。

(1)由区块链节点验证证明报告:假设每个区块链节点都配备有报价飞地,并具有证明密钥![]() 来签署
来签署![]() 生成的远程证明报告
生成的远程证明报告![]() 。
。![]() 与
与![]() 签署以生成报价Qi
签署以生成报价Qi![]() 。引用包含证明飞地
。引用包含证明飞地![]() 的身份、执行模式详细信息(例如安全版本号级别 Si)以及其他元数据。用于生成
的身份、执行模式详细信息(例如安全版本号级别 Si)以及其他元数据。用于生成![]() 的函数可以表示为:
的函数可以表示为:![]() = Sign(
= Sign(![]() ,
, ![]() )。
)。![]() 使用 Intel Attestation Service (IAS) 的公钥
使用 Intel Attestation Service (IAS) 的公钥![]() 进行加密并生成 E(
进行加密并生成 E(![]() ,
, ![]() )。
)。 ![]() 嵌入在所有支持 SGX 的处理器的报价飞地中。每个
嵌入在所有支持 SGX 的处理器的报价飞地中。每个![]() 将其 E(
将其 E(![]() ,
, ![]() )共享给区块链网络的其他支持 SGX 的处理器。一旦从所有 n 个区块链节点的支持 SGX 的处理器接收到所有加密报价,
)共享给区块链网络的其他支持 SGX 的处理器。一旦从所有 n 个区块链节点的支持 SGX 的处理器接收到所有加密报价,![]() 就会创建从所有节点接收到的加密报价的集合,用
就会创建从所有节点接收到的加密报价的集合,用 ![]() = {E(
= {E(![]() ,
, ![]() ), E(
), E(![]() ,
, ![]() ), ......…..E(
), ......…..E(![]() ,
,![]() )}表示。
)}表示。
区块链节点 ![]() 在 IAS 的帮助下验证每个加密报价,并确定报价是否正确以及相应的远程证明 enclave 是否已创建它。验证是使用函数 verify(E(Qi
在 IAS 的帮助下验证每个加密报价,并确定报价是否正确以及相应的远程证明 enclave 是否已创建它。验证是使用函数 verify(E(Qi![]() , PKIAs
, PKIAs![]() ), PKIAs
), PKIAs![]() ) 完成的,其中P 是 IAS 的私钥。一旦报价得到验证,Q就会广播到区块链网络,以获得全球模型的共识。算法 2 概述了此步骤。
) 完成的,其中P 是 IAS 的私钥。一旦报价得到验证,Q就会广播到区块链网络,以获得全球模型的共识。算法 2 概述了此步骤。

(2)区块链网络达成共识:共识机制有几个步骤。首先,区块链节点 ![]() 检查每个报价的有效性以及报价生成飞地的真实性。其次,从每个报价中提取全局模型,并验证它们的哈希值。如果所有全局模型的哈希值相同,则达成共识。如果所有哈希值不相同,则区块链节点
检查每个报价的有效性以及报价生成飞地的真实性。其次,从每个报价中提取全局模型,并验证它们的哈希值。如果所有全局模型的哈希值相同,则达成共识。如果所有哈希值不相同,则区块链节点![]() 确定具有最大匹配哈希值的全局模型
确定具有最大匹配哈希值的全局模型![]() ,其中 k ≤ p。第三,
,其中 k ≤ p。第三,![]() 向区块链网络提出
向区块链网络提出![]() 添加到区块链中。最后,如果
添加到区块链中。最后,如果![]() 对于大多数节点的全局模型是相同的,则达成共识并添加到区块链中。算法 3 显示了伪代码,图 7 提供了共识机制的概述。全局模型的区块链数据结构如图8所示。
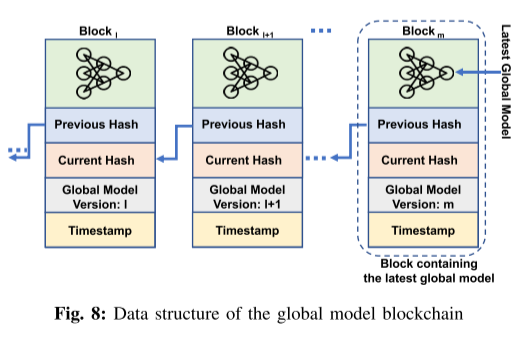
对于大多数节点的全局模型是相同的,则达成共识并添加到区块链中。算法 3 显示了伪代码,图 7 提供了共识机制的概述。全局模型的区块链数据结构如图8所示。

















 3511
3511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









