







说到Redis持久化,先简单说一下Redis的配置文件,在以后的工作做一些配置更加方便使用。文件在redis解压包redis.windows.conf
①单位,注意Redis不区分大小写,Redis配置对大小写不敏感。
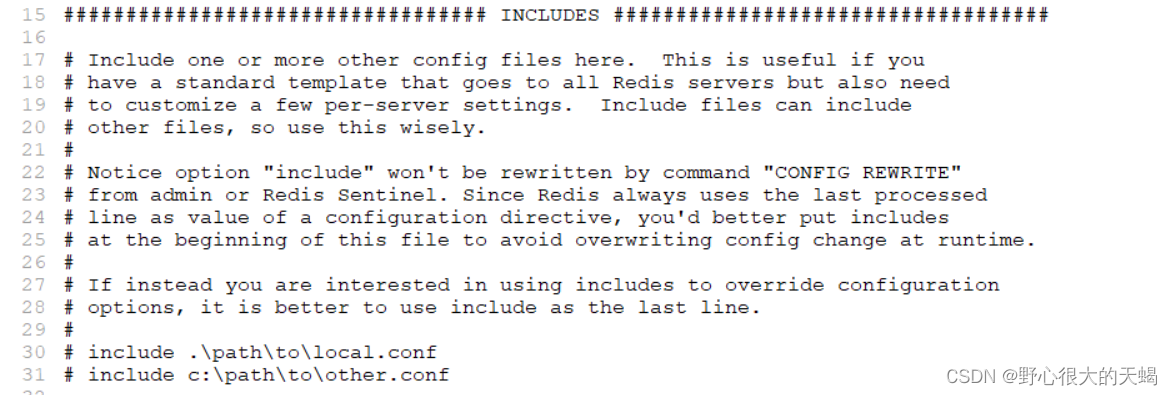
②包含,搭建Redis集群的时候,可以使用Include包含其他配置文件
③网络


bind 127.0.0.1 # 绑定的ip
protected-mode yes # 保护模式
port 6379 # 端口设置
④通用


daemonize yes # 以守护进程的方式运行,默认是 no,我们需要自己开启为yes!
pidfile /var/run/redis.pid # 如果以后台的方式运行,我们就需要指定一个 pid 文件!
# 日志
# Specify the server verbosity level.
# This can be one of:
# debug (a lot of information, useful for development/testing)
# verbose (many rarely useful info, but not a mess like the debug level)
# notice (moderately verbose, what you want in production probably) 生产环境
# warning (only very important / critical messages are logged)
loglevel notice
logfile "" # 日志的文件位置名
databases 16 # 数据库的数量,默认是 16 个数据库
⑤持久化(RDB),持久化,在规定的时间内,执行了多少次操作则会持久化到文件.rdb.aof文件
注意Redis是内存数据库,如果没有持久化,那么数据断电即消失!

# 如果900s内,如果至少有一个1 key进行了修改,我们及进行持久化操作
save 900 1
# 如果300s内,如果至少10 key进行了修改,我们及进行持久化操作
save 300 10
# 如果60s内,如果至少10000 key进行了修改,我们及进行持久化操作
save 60 10000
# 我们之后学习持久化,自己定义这个测试!
⑥security安全,这里可以设置Redis密码,Redis默认是没有密码的。
1)通过命令设置
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> config get requirepass #获取Redis的密码
1) "requirepass"
2) ""
127.0.0.1:6379> config set requirepass "333" #设置Redis的密码为333
OK
# Ctrl+C 退出当前连接,从新打开客户端
127.0.0.1:6379> ping #测试ping,失败,所有的命令都显示无权限
(error) NOAUTH Authentication required.
127.0.0.1:6379> set k1 v1 #失败,所有的命令都显示无权限
(error) NOAUTH Authentication required.
127.0.0.1:6379> auth 333 #auth + 密码 登陆上去
OK
127.0.0.1:6379> ping #正常
PONG
127.0.0.1:6379> config get requirepass #获取密码,正常
1) "requirepass"
2) "333"
2)通过修改配置文件设置,添加密码

测试连接:
127.0.0.1:6379> ping
(error) NOAUTH Authentication required.
127.0.0.1:6379> auth 333
OK
127.0.0.1:6379> ping
PONG
127.0.0.1:6379>⑦限制clients
maxclients 10000 #设置能连接上redis的最大客户端的数量
maxmemory <bytes> #redis 配置最大的内存容量
maxmemory-policy noeviction #内存到达上限之后的处理策略
1、volatile-lru:只对设置了过期时间的key进行LRU(默认值)
2、allkeys-lru : 删除lru算法的key
3、volatile-random:随机删除即将过期key
4、allkeys-random:随机删除
5、volatile-ttl : 删除即将过期的
6、noeviction : 永不过期,返回错误
⑧append only 模式aof配置(持久化保存)
appendonly no #默认是不开启aof模式的,默认是使用rdb方式持久化的,在大部分所有的情况下,rdb完全够用!
appendfilename "appendonly.aof" #持久化的文件的名字
# appendfsync always # 每次修改都会 sync。消耗性能
appendfsync everysec # 每秒执行一次 sync,可能会丢失这1s的数据!
# appendfsync no #不执行 sync,这个时候操作系统自己同步数据,速度最快!
接下来简单说一下Redis持久化
我们要知道Redis是内存数据库,如果不将内存中的数据状态保存到磁盘中,那么一旦服务器进程退出,服务器中的数据库状态也会消失,所以Redis持久化是很有必要的。
1、RDB(Redis DataBase)
1)进入redis解压文件,找到dump.rdb文件
2)测试触发rdb操作,打开redis.config配置文件,将其中的save 60 10000 改为 save 60 5 意味着在60s内进行了5次操作,即写入rdb文件中进行持久化保存
3)触发机制,save的规则满足的情况下,会自动触发rdb规则,先删除dump.rdb文件,实验触发规则,在redis中操作5次命令,查看是否生成dump.rdb文件,存在则成功,再次删除dump.rdb文件,随后执行flushall命令也会触发rdb规则,会从新生成dump.rdb文件。退出Redis也会触发rdb规则,将dump.rdb文件删除,然后退出Redis,会发现dump.rdb文件重新生成。
4)恢复rdb文件,只需要将备份的rdb文件放在我们的redis启动目录即可,Redis启动的时候会自动检查dump.rdb文件并恢复其中的数据!查找文件位置的命令:
127.0.0.1:6379> config get dir
1) "dir"
2) "E:\\project\\frame-stage\\Redis-x64-3.2.100" # 如果在这个目录下存在 dump.rdb 文件,启动就会自动恢复其中的数据
127.0.0.1:6379>优点:
1、适合大规模的数据恢复!
2、对数据的完整性要求不高!
缺点:
1、需要一定的时间间隔进程操作!如果redis意外宕机了,这个最后一次修改数据就没有的了!
2、fork进程的时候,会占用一定的内容空间
2、AOF(Append Only File)
1)Redis默认使用的是RDB模式,所以需要手动开启AOF模式,在配置文件中将,appendonly no 改为 appendonly yes,然后退出 重启,会发现新文件appendonly.aof
2)aof文件容,我们先进行一些添加操作,打开aof文件,会发现存储的是我们先前操作的命令
3)修复aof,如果将aof文件给修改了,我们重启redis,会发现重启失败,会报错配置信息加载失败,使用redis-check-aof --fix appendonly.aof 来进行修复,显示成功Successfully truncated AOF 我们再打开aof文件,发现其中虽然错误的内容少了,但是正确的也有一定的丢失!所以这个修复无法做到百分百修复!但是丢弃一小部分和丢失全部,再次重启试试!成功。
4)AOF重写规则,aof默认的就是文件的无限追加,文件会越来越大,在配置文件中可以设置文件的大小。
# appendfsync always # 每次修改都会 sync。消耗性能
appendfsync everysec # 每秒执行一次 sync,可能会丢失这1s的数据! # appendfsync no # 不执行 sync,这个时候操作系统自己同步数据,速度最快!
appendfilename "appendonly.aof" # 持久化的文件的名字
appendonly no # 默认是不开启aof模式的,默认是使用rdb方式持久化的,在大部分所有的情况下, rdb完全够用!
auto-aof-rewrite-percentage 100 #写入百分比
auto-aof-rewrite-min-size 64mb #写入的文件最大值是多少,一般在实际工作中我们会将其设置为5gb左右!
优点:
1、每一次修改都同步,文件的完整性会更加好!
2、每秒同步一次,最多会丢失一秒的数据!
3、从不同步,效率最高的!
缺点:
1、相对于数据文件来说,aof远远大于 rdb,修复的速度也比 rdb慢!
2、Aof 运行效率也要比 rdb 慢,所以我们redis默认的配置就是rdb持久化!
1、RDB 持久化方式能够在指定的时间间隔内对你的数据进行快照存储
2、AOF 持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以Redis 协议追加保存每次写的操作到文件末尾,Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。
3、只做缓存,如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化
4、同时开启两种持久化方式,1)在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。2)RDB 的数据不实时,同时使用两者时服务器重启也只会找AOF文件,那要不要只使用AOF呢?建议不要,因为RDB更适合用于备份数据库(AOF在不断变化不好备份),快速重启,而且不会有AOF可能潜在的Bug,留着作为一个万一的手段。
5、性能建议,1)因为RDB文件只用作后备用途,建议只在Slave上持久化RDB文件,而且只要15分钟备份一次就够了,只保留 save 900 1 这条规则。2)如果Enable AOF ,好处是在最恶劣情况下也只会丢失不超过两秒数据,启动脚本较简单只load自己的AOF文件就可以了,代价一是带来了持续的IO,二是AOF rewrite 的最后将 rewrite 过程中产生的新数据写到新文件造成的阻塞几乎是不可避免的。只要硬盘许可,应该尽量减少AOF rewrite的频率,AOF重写的基础大小默认值64M太小了,可以设到5G以上,默认超过原大小100%大小重写可以改到适当的数值。3)如果不Enable AOF ,仅靠 Master-Slave Repllcation 实现高可用性也可以,能省掉一大笔IO,也减少了rewrite时带来的系统波动。代价是如果Master/Slave 同时倒掉,会丢失十几分钟的数据,启动脚本也要比较两个 Master/Slave 中的 RDB文件,载入较新的那个,微博就是这种架构。















 1549
1549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









