






使用labelme制作COCO类型的自定义数据集
一、COCO类型数据集
本文重点介绍COCO类自定义数据集制作,关于COCO数据格式参考以下链接:COCO数据集格式
二、自定义数据集制作步骤
(1)数据集文件夹说明
最终需要的文件夹目录如下图所示,其中data位于mmdetection项目根目录下。
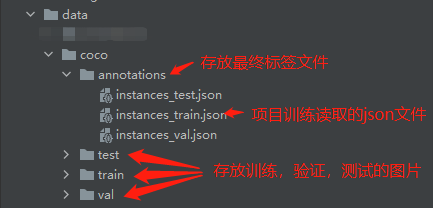
(2)使用labelme标注工具进行标注
具体使用方法参考:LabelMe使用_labelme中所有的create的作用解释-CSDN博客
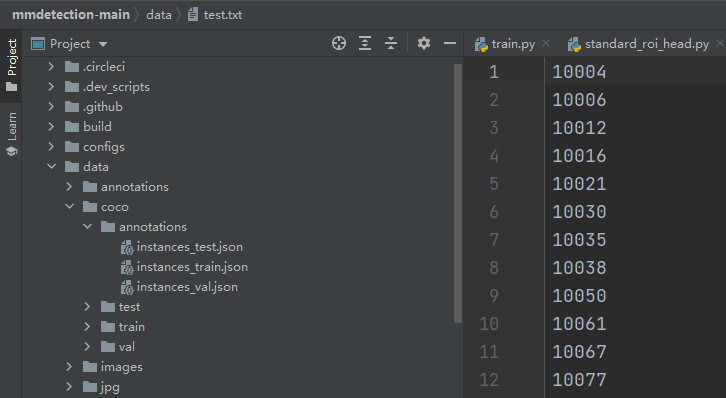
(3)生成需要训练,验证,测试的图片txt文件
使用create_txt.py生成train2019.txt,val2019.txt,test2019.txt,分别对应需要训练,验证,测试的图片名(仅包括名,无扩展名.jpg)如:10001.jpg即保存为10001。create_txt.py文件代码 以及txt文件内容展示如下
# !/usr/bin/python
# -*- coding: utf-8 -*-
import os
import random
trainval_percent = 0.8 # 验证集+训练集占总比例多少
train_percent = 0.7 # 训练数据集占验证集+训练集比例多少
jsonfilepath = 'labels/total'
txtsavepath = './'
total_xml = os.listdir(jsonfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('./trainval.txt', 'w')
ftest = open('./test.txt', 'w')
ftrain = open('./train.txt', 'w')
fval = open('./val.txt', 'w')
for i in list:
name = total_xml[i][:-5] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
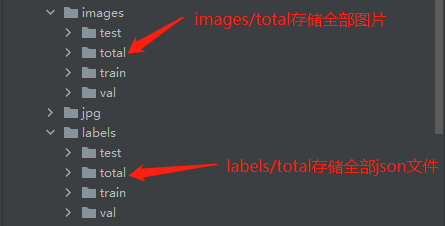
(4)通过classify.py程序将json文件与图片分类
此步骤是为了 将所有标注文件与图片文件按照 上一步三个txt文件里的进行分类对应。
此步骤需要创建文件夹如下图所示。注意!!!images
import shutil
import cv2 as cv
sets=['train', 'val', 'test']
for image_set in sets:
#分别读取三个txt文件中内容并拼接出 所有图片名
image_ids = open('./%s.txt'%(image_set)).read().strip().split()
#将每一类的图片和对应的json文件存入对应的文件夹
for image_id in image_ids:
img = cv.imread('images/total2019/%s.jpg' % (image_id))
json='labelme/total/%s.json'% (image_id)
cv.imwrite('images/%s/%s.jpg' % (image_set,image_id), img)
cv.imwrite('labelme/%s/%s.jpg' % (image_set,image_id), img)
shutil.copy(json,'labelme/%s/%s.json' % (image_set,image_id))
print("完成")
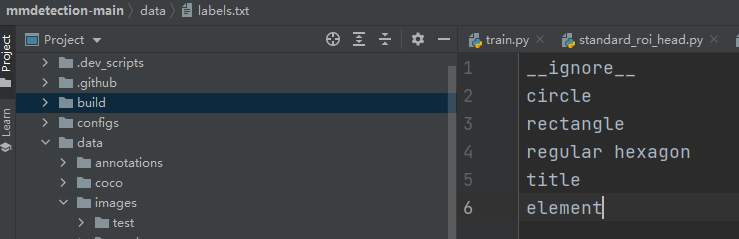
(5)建立建立labels.txt文件,并通过labelme2coco.py生成 instances_train.json,instances_test.json,instances_val.json
label.txt文件包括你自定义数据集的类别信息,其中第一行为背景 (默认忽略)
labelme2coco.py文件负责将标注的json文件都转换到instances_XXX.json中。
下方代码根据个人需要有部分修改。官方labelme2coco.py项目参考链接:labelme2coco/labelme2coco/labelme2coco.py at master · fcakyon/labelme2coco · GitHub
# -*- coding: utf-8 -*-
#!/usr/bin/env python
import argparse
import collections
import datetime
import glob
import json
import os
import os.path as osp
import sys
import uuid
import imgviz
import numpy as np
import PIL.Image as Image
import labelme
try:
import pycocotools.mask
except ImportError:
print("Please install pycocotools:\n\n pip install pycocotools\n")
sys.exit(1)
def main():
# parser = argparse.ArgumentParser(
# formatter_class=argparse.ArgumentDefaultsHelpFormatter
# )
# parser.add_argument("input_dir", help="input annotated directory")
# parser.add_argument("output_dir", help="output dataset directory")
# parser.add_argument("--labels", help="labels file", required=True)
# parser.add_argument(
# "--noviz", help="no visualization", action="store_true"
# )
# args = parser.parse_args()
# 需要变换路径执行三次 分别为train/test/val
input_dir = './labels/test/'
output_dir = './annotations/test/'
labels = 'labels.txt'
noviz = False
if osp.exists(output_dir):
print("Output directory already exists:", output_dir)
sys.exit(1)
os.makedirs(output_dir)
#os.makedirs(osp.join(output_dir, "JPEGImages"))
#if not noviz:
#os.makedirs(osp.join(output_dir, "Visualization"))
print("Creating dataset:", output_dir)
now = datetime.datetime.now()
data = dict(
info=dict(
description=None,
url=None,
version=None,
year=now.year,
contributor=None,
date_created=now.strftime("%Y-%m-%d %H:%M:%S.%f"),
),
licenses=[dict(url=None, id=0, name=None, )],
images=[
# license, url, file_name, height, width, date_captured, id
],
type="instances",
annotations=[
# segmentation, area, iscrowd, image_id, bbox, category_id, id
],
categories=[
# supercategory, id, name
],
)
class_name_to_id = {}
for i, line in enumerate(open(labels).readlines()):
class_id = i # starts with -1
class_name = line.strip()
if class_id == 0:
assert class_name == "__ignore__"
continue
class_name_to_id[class_name] = class_id
data["categories"].append(
dict(supercategory=None, id=class_id, name=class_name, )
)
#out_ann_file 为要保存的最终json文件,注意每次要修改名称
out_ann_file = osp.join(output_dir, "instances_test.json")
# label_files 为所有要读取的标注json文件路径列表
label_files = glob.glob(osp.join(input_dir, "*.json"))
for image_id, filename in enumerate(label_files):
print("Generating dataset from:", filename)
label_file = labelme.LabelFile(filename=filename)
base = osp.splitext(osp.basename(filename))[0]
#out_img_file = osp.join(output_dir, "JPEGImages", base + ".jpg")
# if label_file == "./labels/train/10109.json":
# print("123")
img = labelme.utils.img_data_to_arr(label_file.imageData)
#若果通道数为4 需要砍掉最后一个通道只保留RGB前三个通道
if img.shape[-1]==4:
img=img[:,:,:-1] #i:j,
#print(img.shape,type(img))
#imgviz.io.imsave(out_img_file, img)
data["images"].append(
dict(
license=0,
url=None,
# file_name=osp.relpath(out_img_file, osp.dirname(out_ann_file)),
file_name=base + ".jpg",
height=img.shape[0],
width=img.shape[1],
date_captured=None,
id=image_id,
)
)
masks = {} # for area
segmentations = collections.defaultdict(list) # for segmentation
for shape in label_file.shapes:
points = shape["points"]
label = shape["label"]
group_id = shape.get("group_id")
shape_type = shape.get("shape_type", "polygon")
mask = labelme.utils.shape_to_mask(
img.shape[:2], points, shape_type
)
if group_id is None:
group_id = uuid.uuid1()
instance = (label, group_id)
if instance in masks:
masks[instance] = masks[instance] | mask
else:
masks[instance] = mask
if shape_type == "rectangle":
(x1, y1), (x2, y2) = points
x1, x2 = sorted([x1, x2])
y1, y2 = sorted([y1, y2])
points = [x1, y1, x2, y1, x2, y2, x1, y2]
if shape_type == "circle":
(x1, y1), (x2, y2) = points
r = np.linalg.norm([x2 - x1, y2 - y1])
# r(1-cos(a/2))<x, a=2*pi/N => N>pi/arccos(1-x/r)
# x: tolerance of the gap between the arc and the line segment
n_points_circle = max(int(np.pi / np.arccos(1 - 1 / r)), 12)
i = np.arange(n_points_circle)
x = x1 + r * np.sin(2 * np.pi / n_points_circle * i)
y = y1 + r * np.cos(2 * np.pi / n_points_circle * i)
points = np.stack((x, y), axis=1).flatten().tolist()
else:
points = np.asarray(points).flatten().tolist()
segmentations[instance].append(points)
segmentations = dict(segmentations)
for instance, mask in masks.items():
cls_name, group_id = instance
if cls_name not in class_name_to_id:
continue
cls_id = class_name_to_id[cls_name]
mask = np.asfortranarray(mask.astype(np.uint8))
mask = pycocotools.mask.encode(mask)
area = float(pycocotools.mask.area(mask))
bbox = pycocotools.mask.toBbox(mask).flatten().tolist()
data["annotations"].append(
dict(
id=len(data["annotations"]),
image_id=image_id,
category_id=cls_id,
segmentation=segmentations[instance],
area=area,
bbox=bbox,
iscrowd=0,
)
)
if not noviz:
viz = img
if masks:
listdata_labels = []
listdata_captions = []
listdata_masks = []
for (cnm, gid), msk in masks.items():
if cnm in class_name_to_id:
listdata_labels.append(class_name_to_id[cnm])
listdata_captions.append(cnm)
listdata_masks.append(msk)
listdata = zip(listdata_labels, listdata_captions, listdata_masks)
labels, captions, masks = zip(*listdata)
# labels, captions, masks = zip(*[(listdata_labels, listdata_captions, listdata_masks)])
# print(len(masks))
# labels, captions, masks = zip(
# *[
# (class_name_to_id[cnm], cnm, msk)
# for (cnm, gid), msk in masks.items()
# if cnm in class_name_to_id
# ]
# )
viz = imgviz.instances2rgb(
image=img,
labels=labels,
masks=masks,
captions=captions,
font_size=15,
line_width=2,
)
out_viz_file = osp.join(
output_dir, "Visualization", base + ".jpg"
)
imgviz.io.imsave(out_viz_file, viz)
with open(out_ann_file, "w") as f:
json.dump(data, f)
if __name__ == "__main__":
main()
最终得到 需要的三个json文件 即 instances_train.json,instances_test.json, instances_val.json 将这三个文件存入步骤(1)annotations文件夹中
并将步骤(4)中 分类好的 train、val、test图片文件夹,存入步骤(1)中的文件夹。
上述步骤是关于如何制作COCO类自定义数据集。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









