







 本文详细解析了HDFS中NameNode和SecondaryNameNode的工作机制,包括NN元数据存储、为何需要2NN、NN和2NN的工作流程、Fsimage和Edits的合并以及CheckPoint时间设置。通过理解这一机制,可以更好地掌握Hadoop分布式文件系统的稳定运行。
本文详细解析了HDFS中NameNode和SecondaryNameNode的工作机制,包括NN元数据存储、为何需要2NN、NN和2NN的工作流程、Fsimage和Edits的合并以及CheckPoint时间设置。通过理解这一机制,可以更好地掌握Hadoop分布式文件系统的稳定运行。
一、NN元数据储存在哪以及为何要引入2NN?
首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在内存中,一旦断电,元数据丢失,整个集群就无法工作了。因此产生在磁盘中备份元数据的FsImage。
这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦NameNode节点断电,就会产生数据丢失。因此,引入Edits文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。 这样,一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。
但是,如果长时间添加数据到Edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行FsImage和Edits的合并,如果这个操作由 NN 节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。
二、NN和2NN工作机制图示
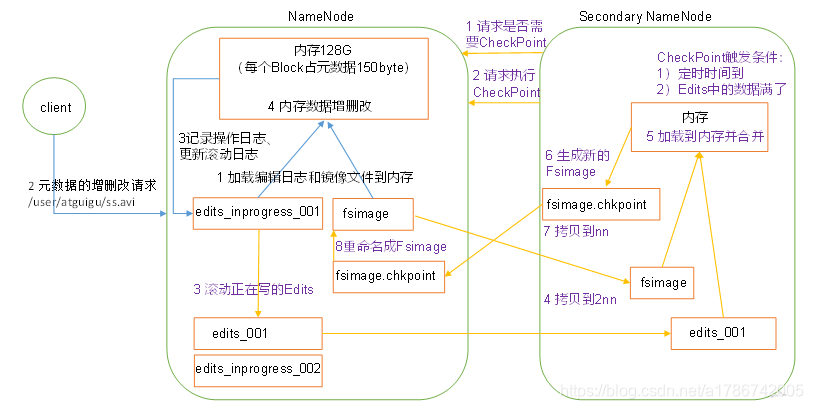
三、NN和2NN工作流程
1、第一阶段:NameNode启动
(1) 第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2) 客户端对元数据进行增删改的请求。
(3) NameNode记录操作日志,更新滚动日志。
(4) NameNode在内存中对数据进行增删改。
2、第二阶段:Secondary NameNode工作
(1) Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2) Secondary NameNode请求执行CheckPoint。
(3) NameNode滚动正在写的Edits日志。
(4) 将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5) Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6) 生成新的镜像文件fsimage.chkpoint。
(7) 拷贝fsimage.chkpoint到NameNode。
(8) NameNode将fsimage.chkpoint重新命名成fsimage。
四、NN和2NN工作机制详解
Fsimage:NameNode内存中元数据序列化后形成的文件。
Edits:记录客户端更新元数据信息的每一步操作(可通过Edits运算出元数据)。
NameNode启动时,先滚动Edits并生成一个空的edits.inprogress,然后加载Edits和Fsimage到内存中,此时NameNode内存就持有最新的元数据信息。Client开始对NameNode发送元数据的增删改的请求,这些请求的操作首先会被记录到edits.inprogress中(查询元数据的操作不会被记录在Edits中,因为查询操作不会更改元数据信息),如果此时NameNode挂掉,重启后会从Edits中读取元数据的信息。然后,NameNode会在内存中执行元数据的增删改的操作。
由于Edits中记录的操作会越来越多,Edits文件会越来越大,导致NameNode在启动加载Edits时会很慢,所以需要对Edits和Fsimage进行合并(所谓合并,就是将Edits和Fsimage加载到内存中,照着Edits中的操作一步步执行,最终形成新的Fsimage)。SecondaryNameNode的作用就是帮助NameNode进行Edits和Fsimage的合并工作。
SecondaryNameNode首先会询问NameNode是否需要CheckPoint(触发CheckPoint需要满足两个条件中的任意一个,定时时间到和Edits中数据写满了)。直接带回NameNode是否检查结果。SecondaryNameNode执行CheckPoint操作,首先会让NameNode滚动Edits并生成一个空的edits.inprogress,滚动Edits的目的是给Edits打个标记,以后所有新的操作都写入edits.inprogress,其他未合并的Edits和Fsimage会拷贝到SecondaryNameNode的本地,然后将拷贝的Edits和Fsimage加载到内存中进行合并,生成fsimage.chkpoint,然后将fsimage.chkpoint拷贝给NameNode,重命名为Fsimage后替换掉原来的Fsimage。NameNode在启动时就只需要加载之前未合并的Edits和Fsimage即可,因为合并过的Edits中的元数据信息已经被记录在Fsimage中。
五、Fsimage和Edits解析
1、概念
 2、查看oiv和oev命令
2、查看oiv和oev命令
 3、oiv查看Fsimage文件
3、oiv查看Fsimage文件
(1) 基本语法
hdfs oiv -p 文件类型 -i 镜像文件 -o 转换后文件输出路径
[test@hadoop151 ~]$ hdfs oiv
Usage: bin/hdfs oiv [OPTIONS] -i INPUTFILE -o OUTPUTFILE
Offline Image Viewer
View a Hadoop fsimage INPUTFILE using the specified PROCESSOR,
saving the results in OUTPUTFILE.
The oiv utility will attempt to parse correctly formed image files
and will abort fail with mal-formed image files.
The tool works offline and does not require a running cluster in
order to process an image file.
The following image processors are available:
* XML: This processor creates an XML document with all elements of
the fsimage enumerated, suitable for further analysis by XML
tools.
* FileDistribution: This processor analyzes the file size
distribution in the image.
-maxSize specifies the range [0, maxSize] of file sizes to be
analyzed (128GB by default).
-step defines the granularity of the distribution. (2MB by default)
* Web: Run a viewer to expose read-only WebHDFS API.
-addr specifies the address to listen. (localhost:5978 by default)
* Delimited (experimental): Generate a text file with all of the elements common
to both inodes and inodes-under-construction, separated by a
delimiter. The default delimiter is \t, though this may be
changed via the -delimiter argument.
Required command line arguments:
-i,--inputFile <arg> FSImage file to process.
Optional command line arguments:
-o,--outputFile <arg> Name of output file. If the specified
file exists, it will be overwritten.
(output to stdout by default)
-p,--processor <arg> Select which type of processor to apply
against image file. (XML|FileDistribution|Web|Delimited)
(Web by default)
-delimiter <arg> Delimiting string to use with Delimited processor.
-t,--temp <arg> Use temporary dir to cache intermediate result to generate
Delimited outputs. If not set, Del 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 683
683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









