







首先看下目标网页:
这个就是本次测试的小说书籍:
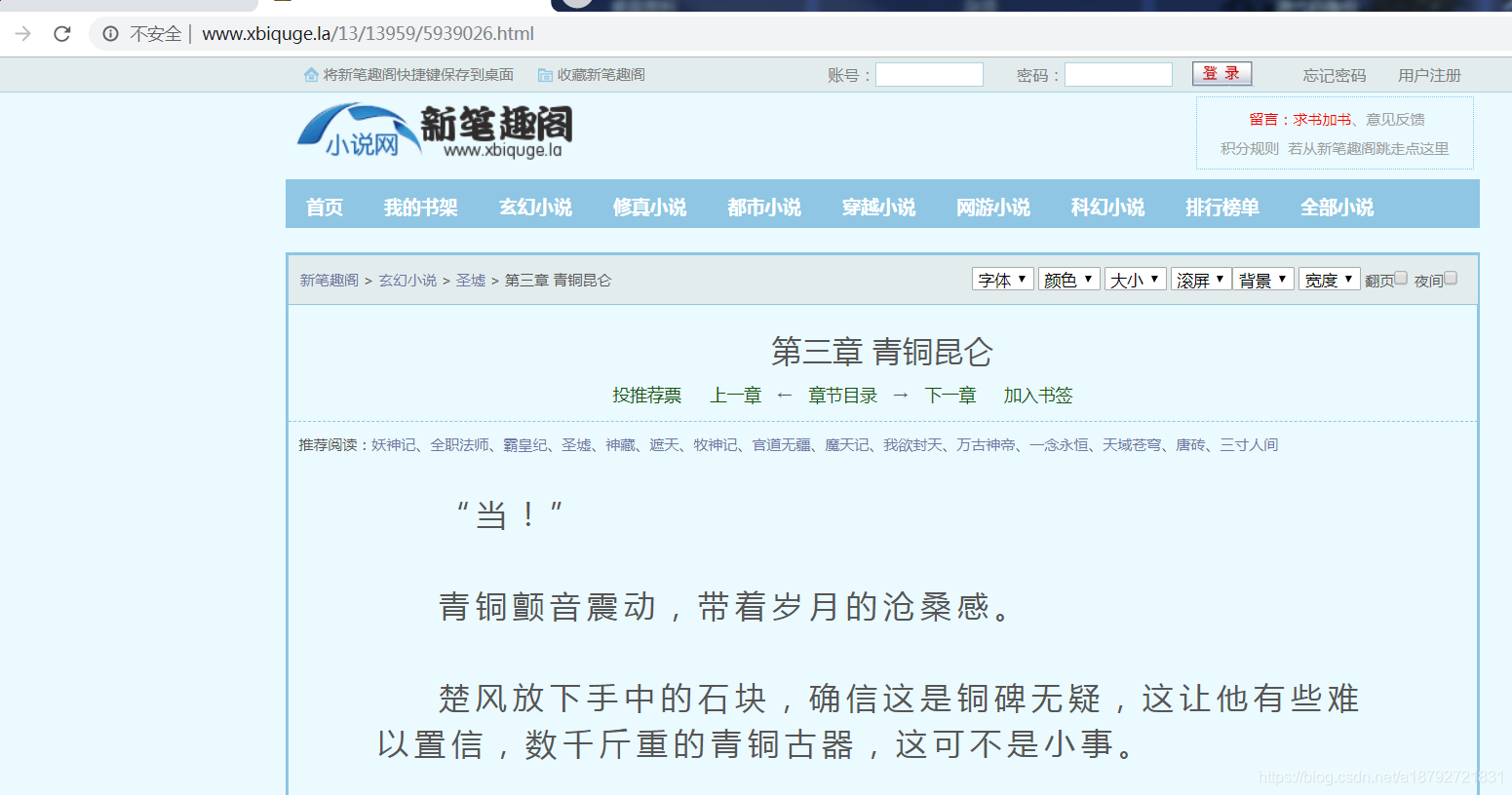
这是正文部分:

url:http://www.xbiquge.la/13/13959/5939025.html
1.爬虫的行为
从初始网页中获取下一个网页的链接;
然后从当前网页获取目标信息。
2.项目设计
文字爬虫的项目分析:
1.输入:
带有目标文字的网站url
2.输出:
符合要求的所有目标文字文件(txt)
项目流程:
1.获取第一个网站的HTML
2.获取baseUrl
3.获取next
4.组装nextUrl
5.放入全局Queue
6.获取网站的HTML
7.获取目标文字
8.目标文字格式化
9.目标文字写入文件(mini.txt)
10.文件合并(mini.txt->all.txt)
11.mini.txt删除
13.为了提高效率,mini.txt就是缓存(100个文件/50个文件一组)
其中抽取:
1.url->HTML
2.HTML->nextUrl
3.HTML->str
4.全局Queue
5.str->mini.txt
6.mini.txt->all.txt
7.del nimi.txt
3.获取静态网页的html代码
import requests
def getHtml(url):
header = {
'Accept': "*/*",
'accept-encoding': "gzip, deflate",
'Connection': "keep-alive",
'Accept-Language' : 'zh-CN,zh;q=0.9',
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
if url is not None and url.strip() != '':
response = requests.request('GET', url = url.strip(), headers = header, timeout = 60)
response.encoding = 'utf-8'
return response.text
这里用到了python的requests库,所以需要安装requests库
安装requests库也是非常的简单:
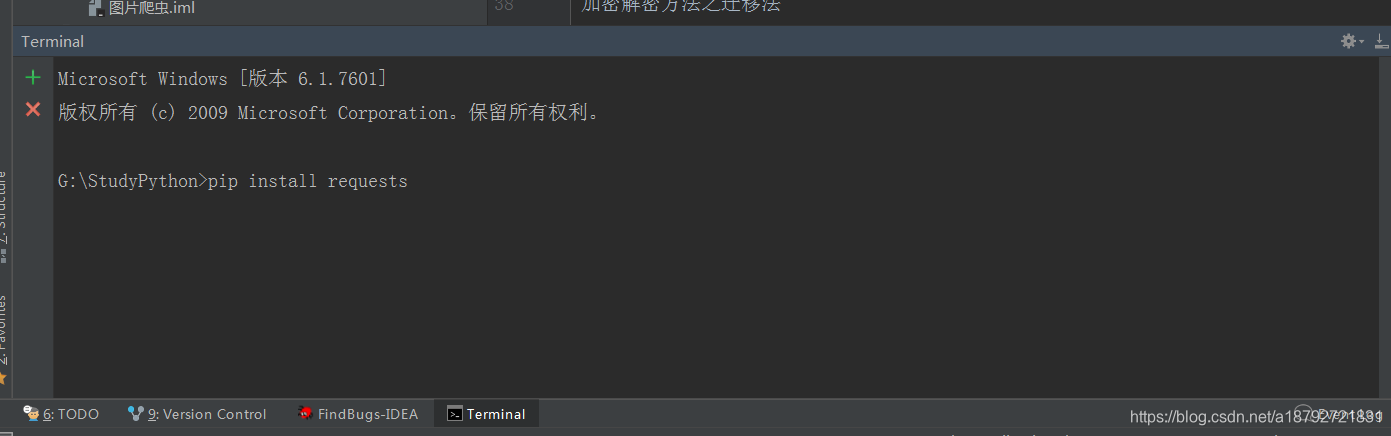
或者更简单的直接import requests,然后requests会报错,在idea的ide下,使用alt+回车,选择下载requests库,让ide去下载第三方库。
第三方库安装后再python的sdk的安装目录的下面:
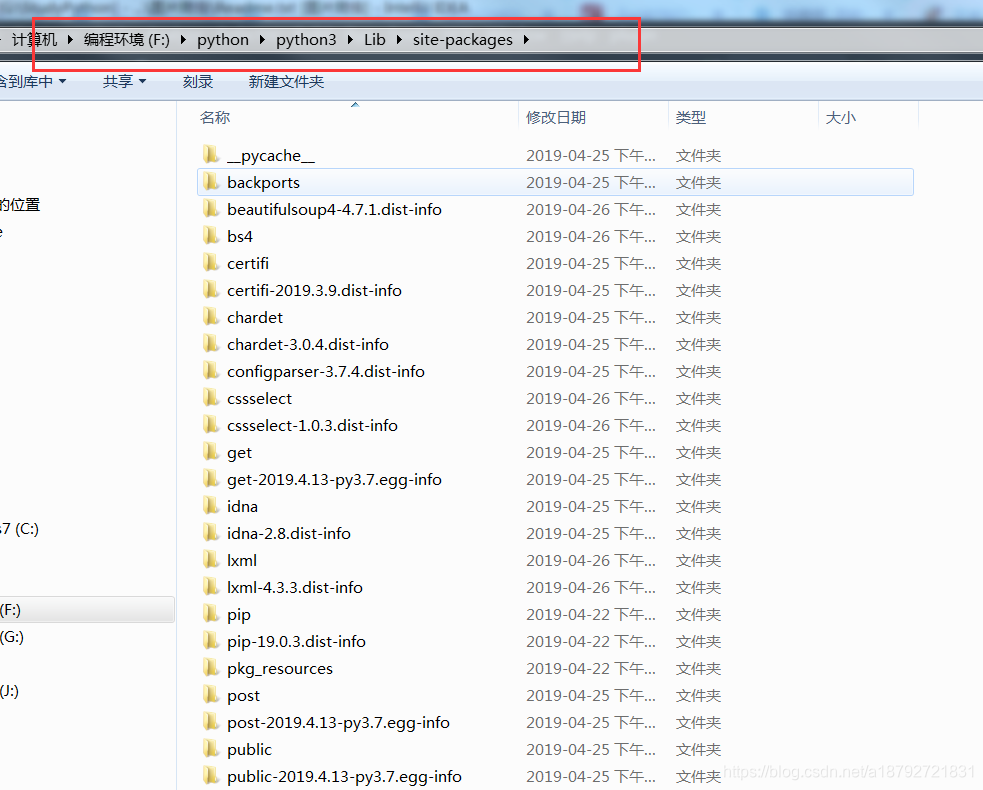

所以如果发现找不到第三方库
在project中看下工作空间的sdk
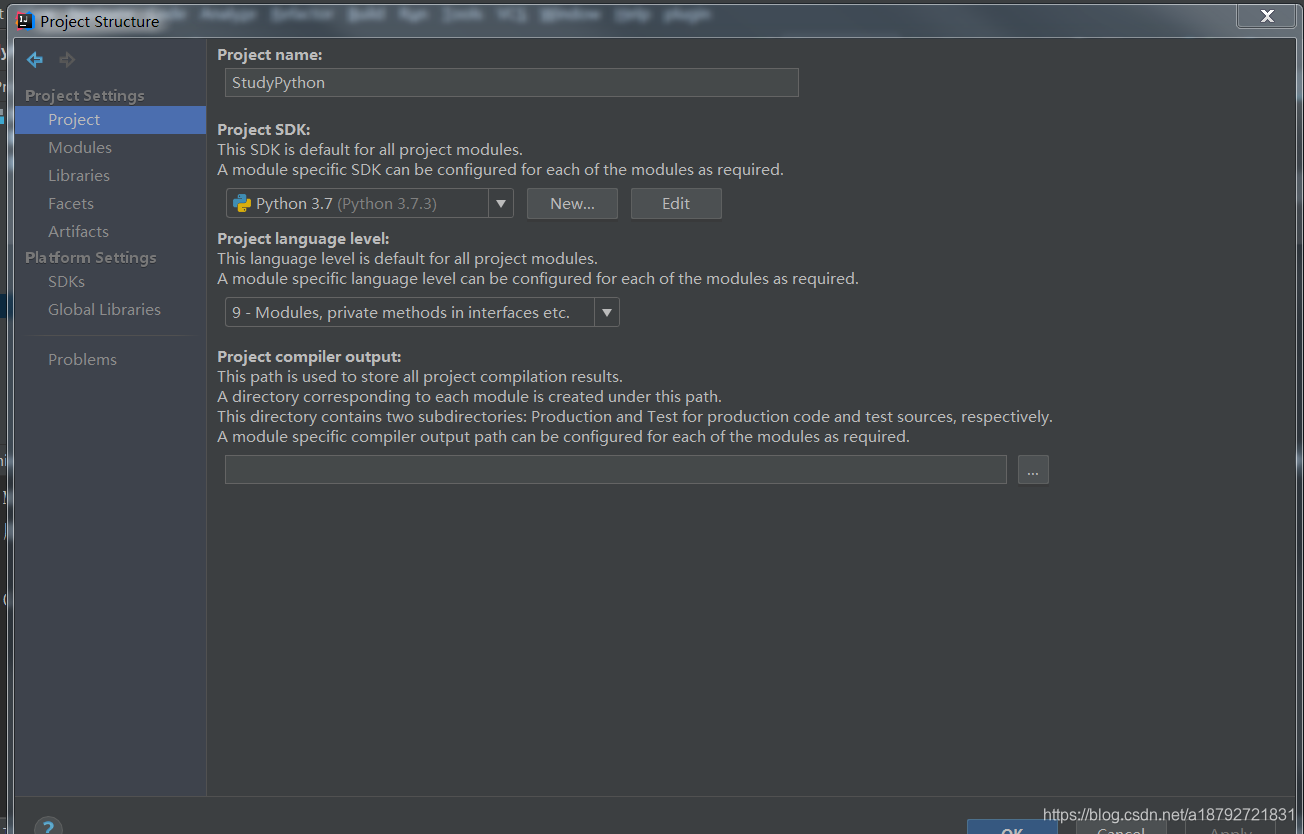
然后看下sdk的package信息
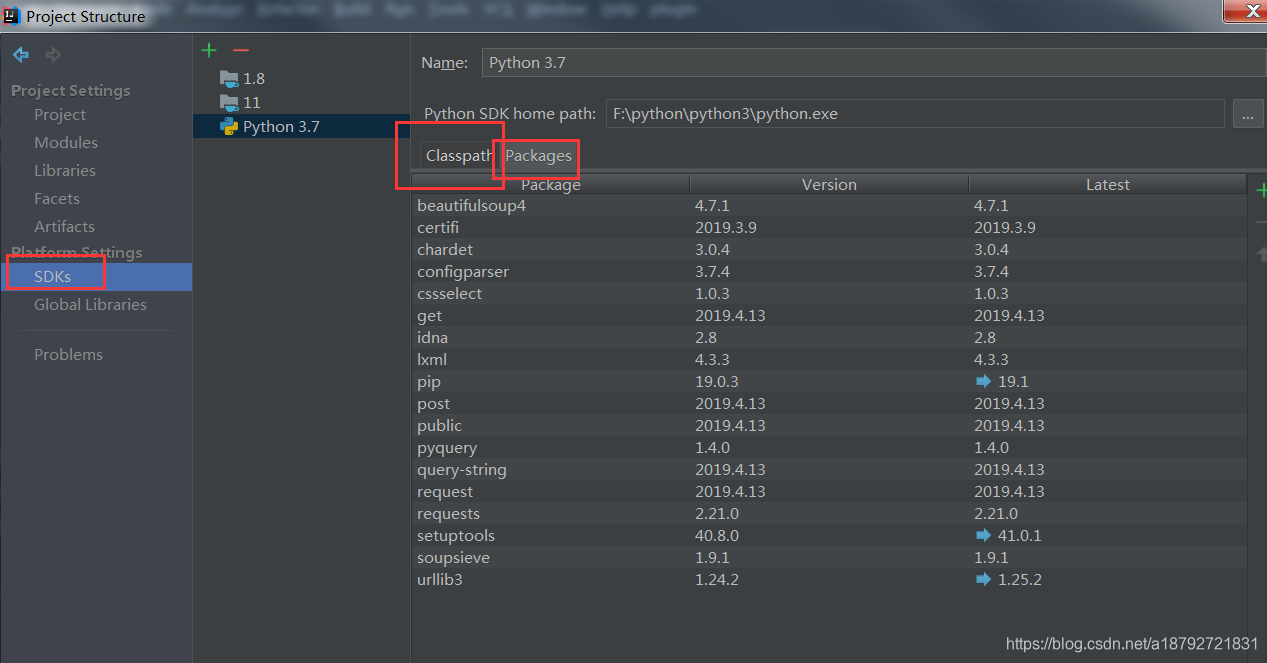
如果发现没有第三方库,有时需要等待一段时间,或者重启,让ide扫描package信息。
言归正传,如何测试获取静态网页的html方法是否正确呢?
在方法的下面直接进行测试:
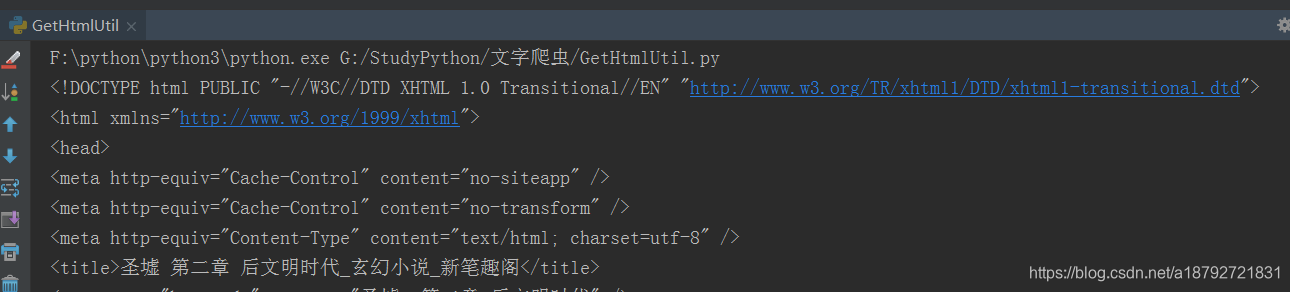
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Cache-Control" content="no-siteapp" />
<meta http-equiv="Cache-Control" content="no-transform" />
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>圣墟 第二章 后文明时代_玄幻小说_新笔趣阁</title>
<meta name="keywords" content="圣墟, 第二章 后文明时代" />
<meta name="description" content="新笔趣阁提供了辰东创作的玄幻小说《圣墟》干净清爽无错字的文字章节: 第二章 后文明时代在线阅读。" />
<link rel="stylesheet" type="text/css" href="http://www.xbiquge.la/images/biquge.css"/>
<script type="text/javascript" src="http://libs.baidu.com/jquery/1.4.2/jquery.min.js"></script>
<script type="text/javascript" src="http://www.xbiquge.la/images/bqg.js"></script>
<script type="text/javascript">
<!--
var preview_page = "index.html";
var next_page = "5939026.html";
var index_page = "index.html";
var article_id = "13959";
var chapter_id = "5939025";
function jumpPage() {
var event = document.all ? window.event : arguments[0];
if (event.keyCode == 37) document.location = preview_page;
if (event.keyCode == 39) document.location = next_page;
if (event.keyCode == 13) document.location = index_page;
}
document.onkeydown=jumpPage;
-->
</script>
</head>
<body>
<div id="wrapper">
<script>login();</script>
<div class="header">
<div class="header_logo">
<a href="http://www.xbiquge.la">新笔趣阁</a>
</div>
<script>bqg_panel();</script>
</div>
<div class="nav">
<ul>
<li><a href="http://xbiquge.la/">首页</a></li>
<li><a href="/modules/article/bookcase.php">我的书架</a></li>
<li><a href="/xuanhuanxiaoshuo/">玄幻小说</a></li>
<li><a href="/xiuzhenxiaoshuo/">修真小说</a></li>
<li><a href="/dushixiaoshuo/">都市小说</a></li>
<li><a href="/chuanyuexiaoshuo/">穿越小说</a></li>
<li><a href="/wangyouxiaoshuo/">网游小说</a></li>
<li><a href="/kehuanxiaoshuo/">科幻小说</a></li>
<li><a href="/paihangbang/">排行榜单</a></li>
<li><a href="/xiaoshuodaquan/">全部小说</a></li>
</ul>
</div>
<div class="content_read">
<div class="box_con">
<div class="con_top">
<script>textselect();</script>
<a href="/">新笔趣阁</a> > <a href="/fenlei/1_1.html">玄幻小说</a> > <a href="http://www.xbiquge.la/13/13959/">圣墟</a> > 第二章 后文明时代 </div>
<div class="bookname">
<h1> 第二章 后文明时代</h1>
<div class="bottem1">
<a href="javascript:;" onclick="showpop_vote(13959);">投推荐票</a> <a href="/13/13959/">上一章</a> ← <a href="http://www.xbiquge.la/13/13959/">章节目录</a> → <a href="/13/13959/5939026.html">下一章</a> <a href="javascript:;" onclick="showpop_addmark(13959,5939025);">加入书签</a>
</div>
<div id="listtj"> 推荐阅读:<a href="/2/2699/" target="_blank">妖神记</a>、<a href="/2/2210/" target="_blank">全职法师</a>、<a href="/2/2208/" target="_blank">霸皇纪</a>、<a href="/13/13959/" target="_blank">圣墟</a>、<a href="/7/7246/" target="_blank">神藏</a>、<a href="/7/7004/" target="_blank">遮天</a>、<a href="/15/15409/" target="_blank">牧神记</a>、<a href="/0/183/" target="_blank">官道无疆</a>、<a href="/0/215/" target="_blank">魔天记</a>、<a href="/0/218/" target="_blank">我欲封天</a>、<a href="/7/7552/" target="_blank">万古神帝</a>、<a href="/9/9419/" target="_blank">一念永恒</a>、<a href="/0/381/" target="_blank">天域苍穹</a>、<a href="/0/993/" target="_blank">唐砖</a>、<a href="/10/10489/" target="_blank">三寸人间</a></div>
</div>
<table style="width:100%; text-align:center;"><tr><td><script>read_1_1();</script></td><td><script>read_1_2();</script></td><td><script>read_1_3();</script></td></tr></table>
<br /> 书评区非常火热,也有很多人飘红,谢谢大家的热情,谢谢所有书友。<br /><br /><p><a href="http://koubei.baidu.com/s/xbiquge.la" target="_blank">亲,点击进去,给个好评呗,分数越高更新越快,据说给新笔趣阁打满分的最后都找到了漂亮的老婆哦!</a><br />手机站全新改版升级地址:http://m.xbiquge.la,数据和书签与电脑站同步,无广告清新阅读!</p></div>
<script>read3();</script><script>bdshare();</script>
<div class="bottem2">
<a href="javascript:;" onclick="showpop_vote(13959);">投推荐票</a> <a href="/13/13959/">上一章</a> ← <a href="http://www.xbiquge.la/13/13959/">章节目录</a> → <a href="/13/13959/5939026.html">下一章</a> <a href="javascript:;" onclick="showpop_addmark(13959,5939025);">加入书签</a>
</div>
<script>read4();</script>
<div id="hm_t_54219"></div>
</div>
</div>
<div class="footer">
<div class="footer_link"> 新书推荐:<a href="/23/23756/" target="_blank">万能卡牌带我飞</a>、<a href="/23/23755/" target="_blank">抗战之无敌战神</a>、<a href="/23/23754/" target="_blank">逆罪而行</a>、<a href="/23/23753/" target="_blank">阴阳先生奇谈</a>、<a href="/23/23752/" target="_blank">烈火救赎</a></div>
<div class="footer_cont">
<script>footer();right();dl();</script>
<!--<script>mark();</script>-->
<div class="reader_mark1"><a href="javascript:;" onclick="showpop_addmark(13959,5939025);"></a></div>
<div class="reader_mark0"><a href="javascript:;" onclick="showpop_vote(13959);"></a></div>
</div>
</div>
</div>
</body>
<script charset="utf-8" src="http://www.baidu.com/js/opensug.js"></script>
<script>
(function(){
var bp = document.createElement('script');
bp.src = '//push.zhanzhang.baidu.com/push.js';
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(bp, s);
})();
</script>
</html>
4.获取下一章的url
通过对静态网页的html的分析发现,或者更简单一些:使用浏览器的检查功能:
在网页中按ctrl+shitf+I(谷歌浏览器)
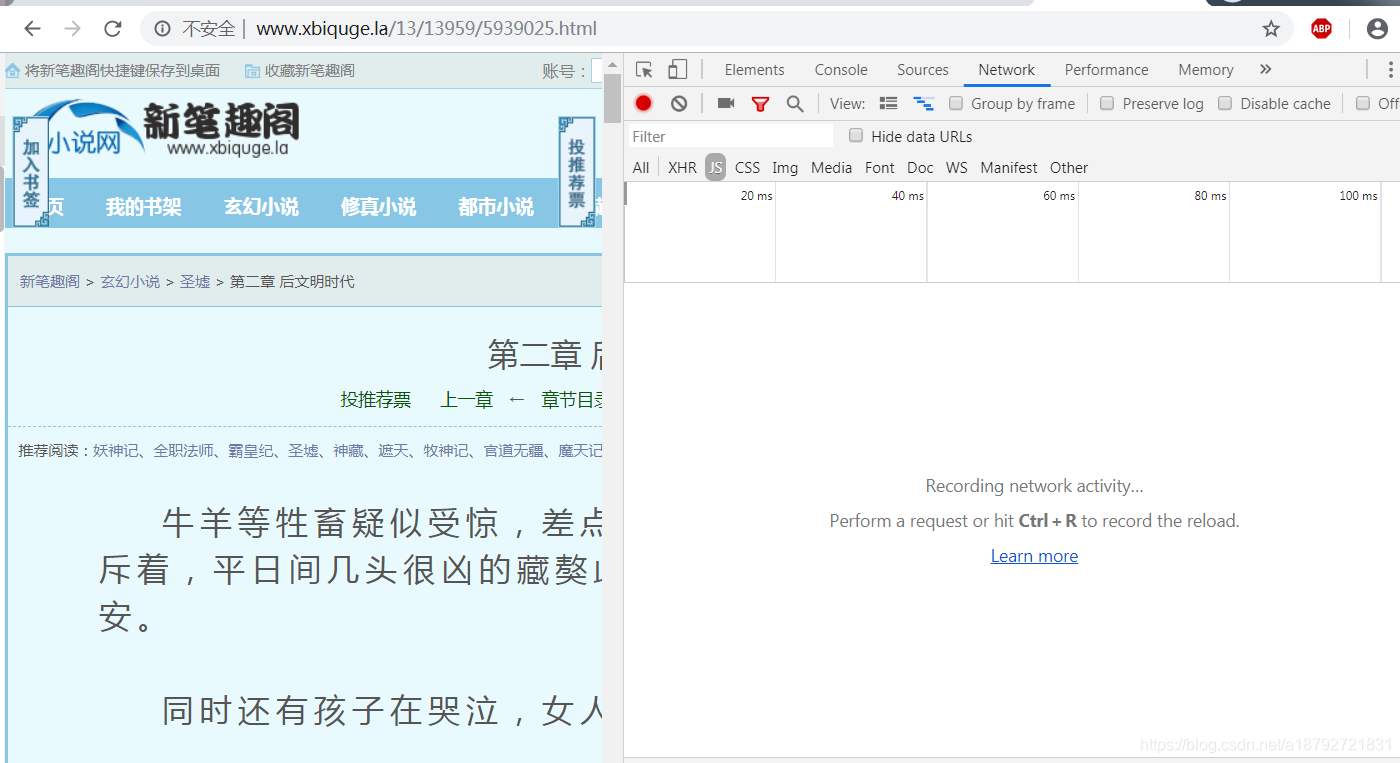
然后切换到
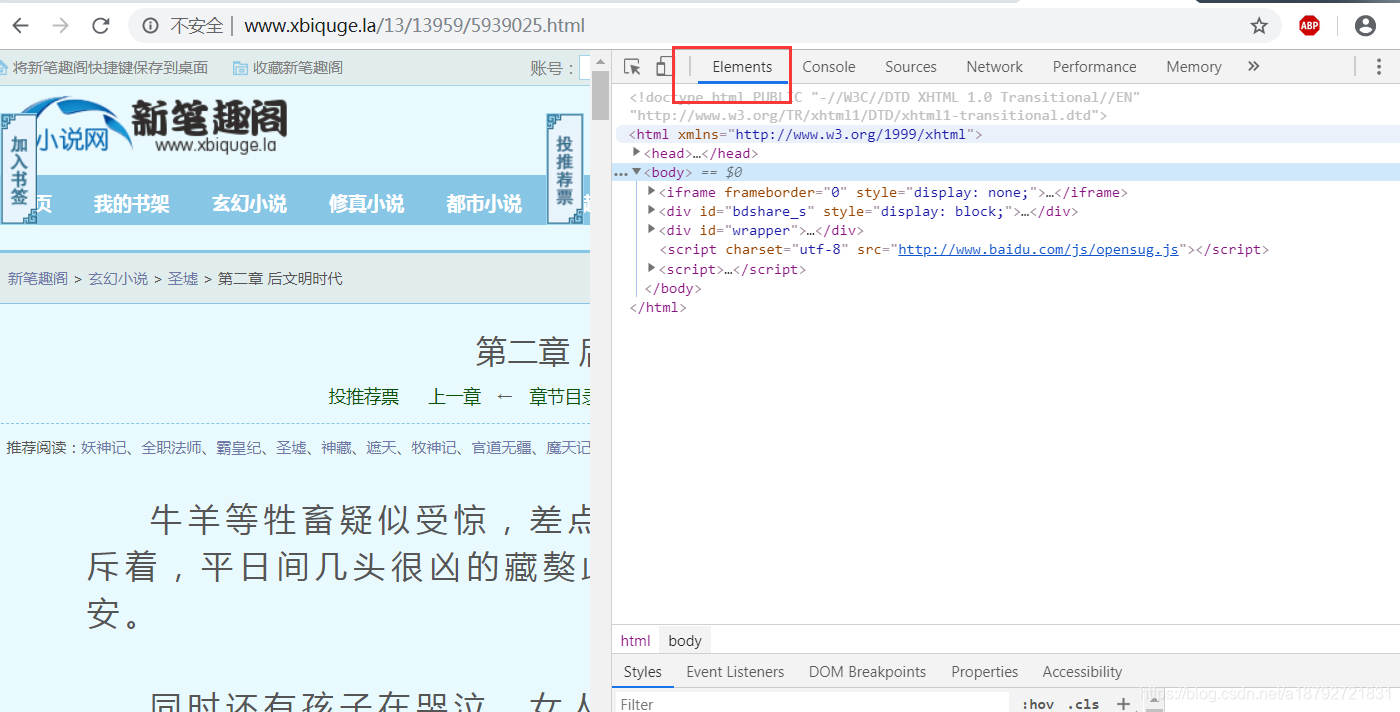
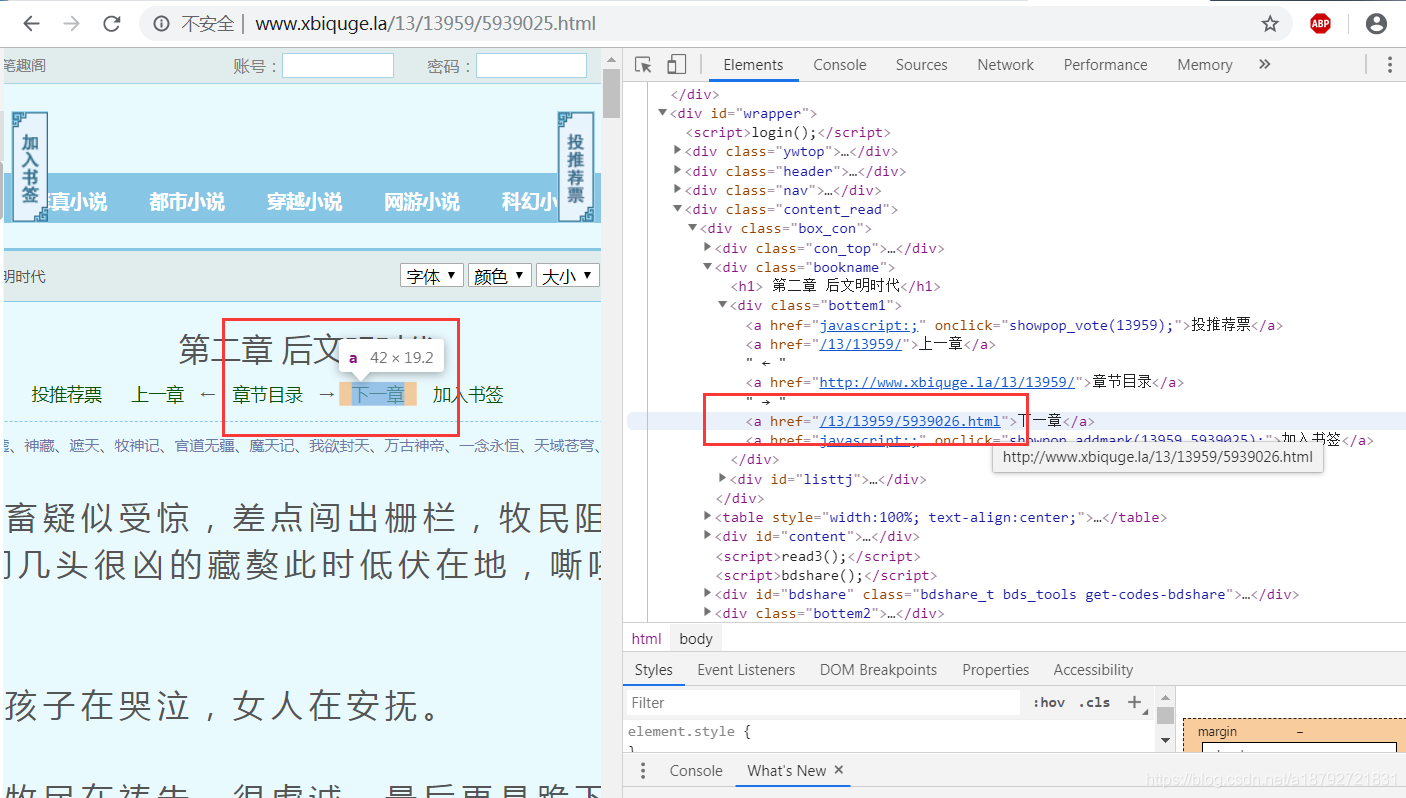
但是这个地址是相对地址,是相对网站的地址,并不是绝对地址,不能直接访问:
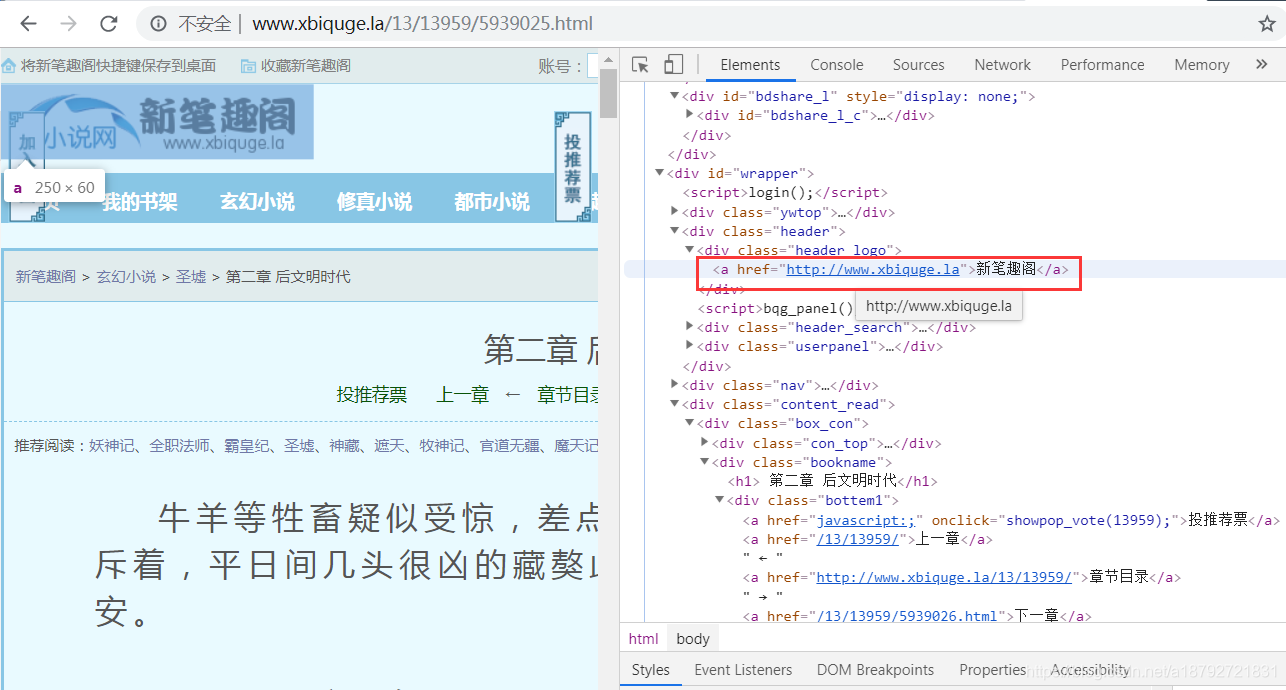
网站的地址可以直接在代码中定义,也可以通过logo获取。
至此,获取下一个网页的url的所有的信息都找到了,那么如何在html中找到呢?
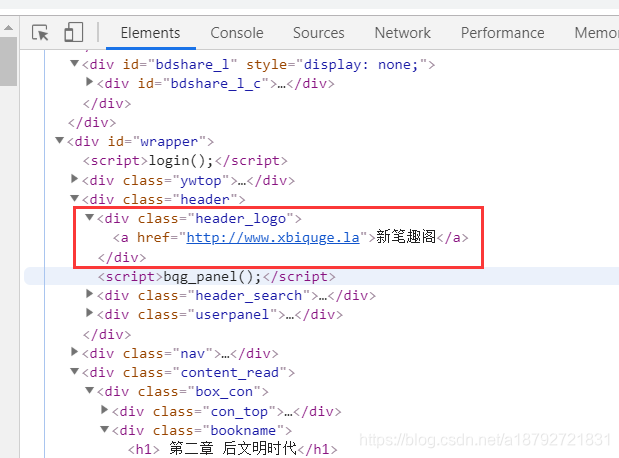
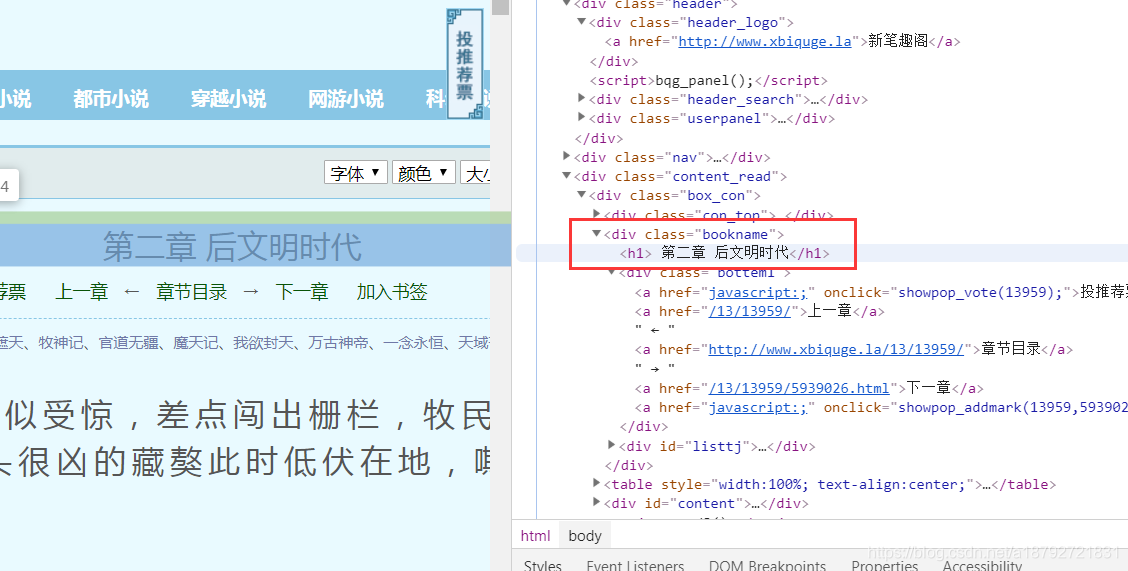
网站的地址比较简单,直接在class为header_logo的div标签的a标签内。
div内也只有一个a标签。
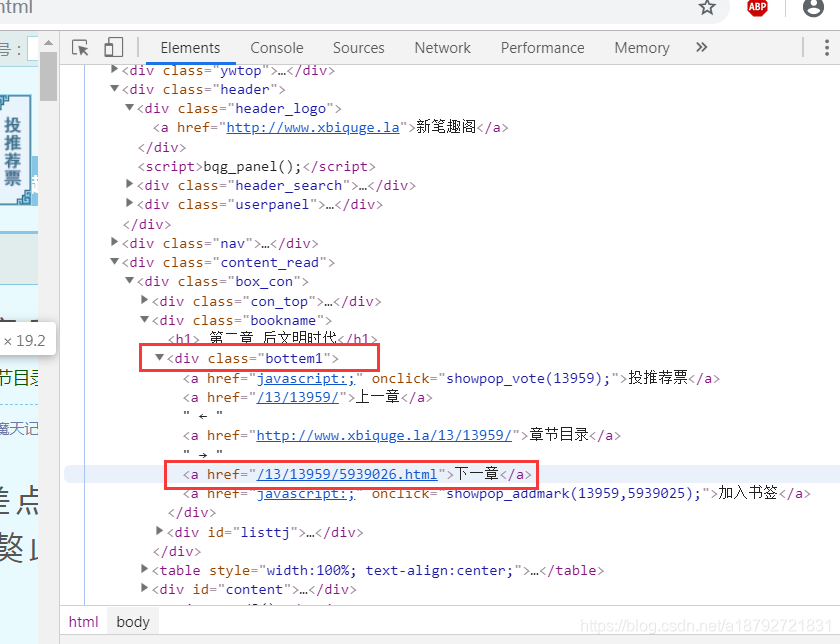
相对地址的获取也比较简单,首先能获取到class为bottem1的div标签。
说明一下,使用的是Jquery的选择器的方法获取节点。
所以获取有属性,id等等的节点比较容易。
获取到div后获取所有的a标签,然后取html输出文字为"下一章"的a标签的href属性值即可。
def getNextUrl(soup):
baseTag = soup.select("div[class='header_logo'] > a")
if len(baseTag):
baseTag = baseTag.pop()
nextTag = soup.select("div[class='bottem2'] > a")
for oneTag in nextTag:
if oneTag.text == '下一章' and oneTag['href'].endswith('.html'):
return baseTag['href'] + oneTag['href']
这里输入参数是一个BeautifulSoup的对象。
我们还需要根据html代码获取目标小说文字,所以需要在Main程序中持有这个soup对象。soup对象就是根据一定的规则解析html代码后的一个对象。
操作这个对象可以进行节点的查找等等。
所以测试的时候需要导入这个库。
因为我使用的是python3,对应的BeautifulSoup是bs4这个库
这个库同样需要下载,下载代码:
pip install bs4
下载完成后增加如下代码进行测试:
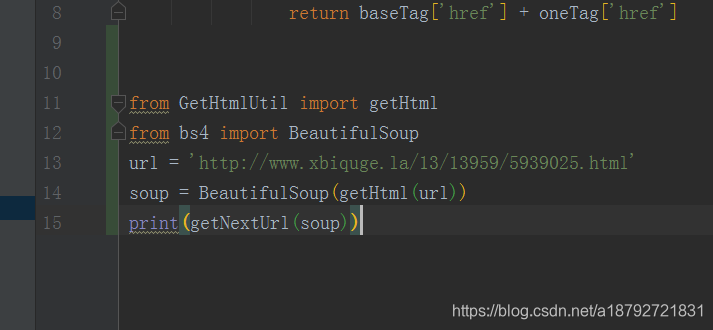
按住ctrl+shift+f10直接运行python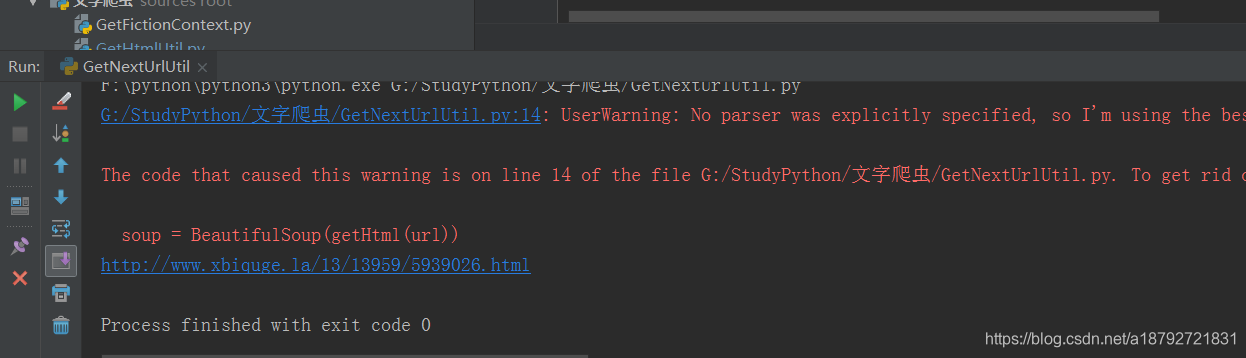
会发现有异常,这是因为我们没有指定解析的方式,但是这个类库非常的强大,及时没有指定解析的模式,也能成功的解析,但是为了不输出异常信息,所以还是指定一下解析方式(具体请参考官方文档(有中文语言的文档))
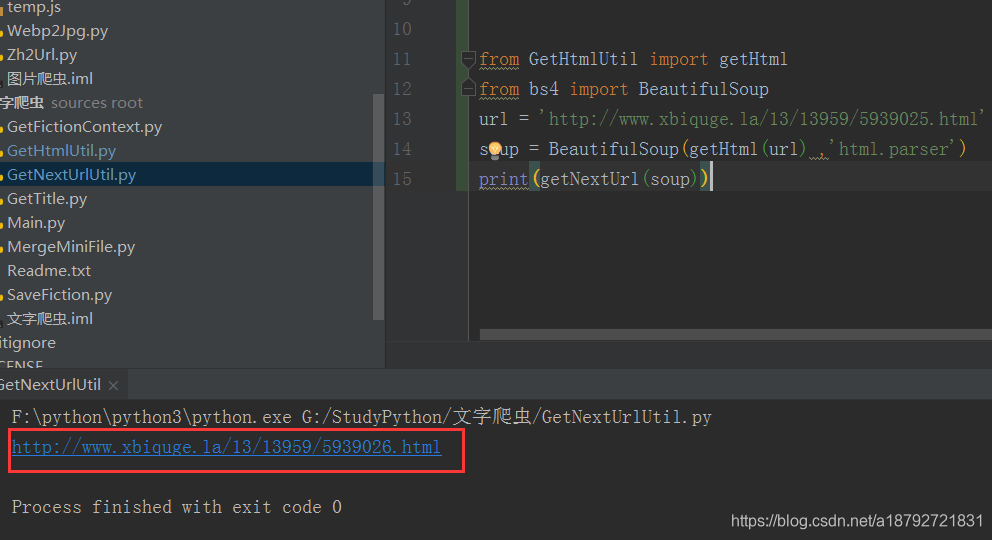
我们拷贝这个地址到浏览器验证
完全正确。
5.获取小说的章节名字
小说的章节名字,是一章小说的精髓所在,所以,如果看小说不看章节名,或者章节名字不怎么好,那么整个小说就会看的比较迷茫。
所以,小说的章节也需要正确的获取。
采用同样的方式进行获取章节名字:
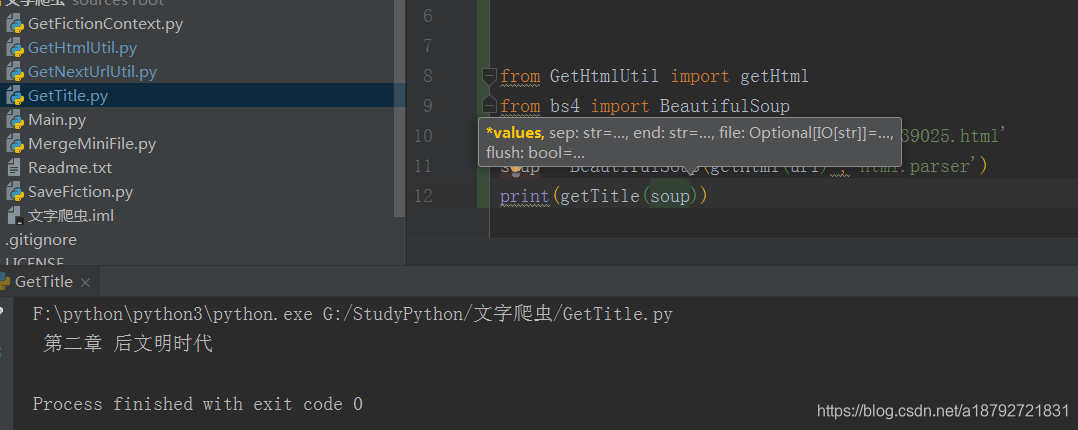
class为bookname的节点下第一个h1标签(也是唯一一个)
def getTitle(soup):
fictionTag = soup.select("div[class='bookname'] > h1")
if len(fictionTag):
fictionTag = fictionTag.pop()
return fictionTag.text
6.获取小说正文
获取小说正文就最简单了
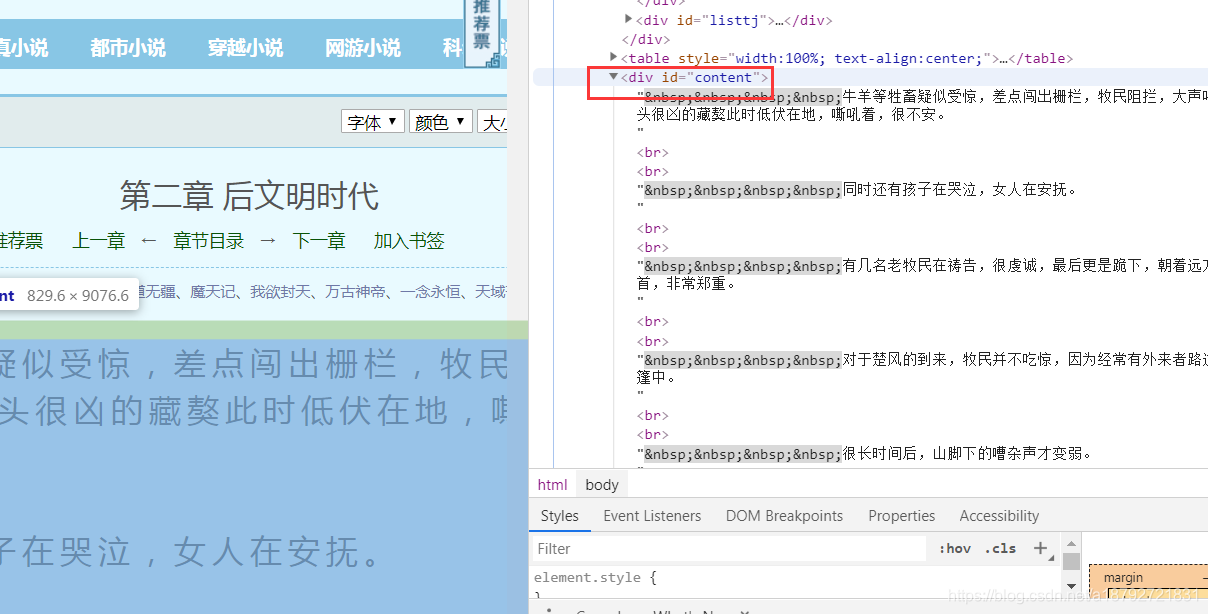
直接根据id获取div节点,然后获取输出文字即可。
但是,一章完整的小说应该还包括章节名字,所以这里需要把章节名字加入。
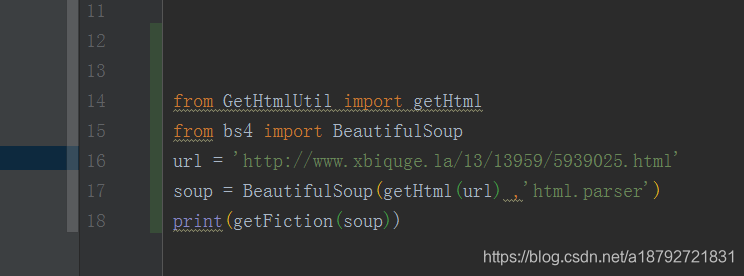
from GetTitle import getTitle
def getFiction(soup):
fictionTag = soup.select('#content')
if len(fictionTag):
fictionTag = fictionTag.pop()
result = '\n\n\n' + getTitle(soup) + '\n\n\n'
result += fictionTag.text
return result
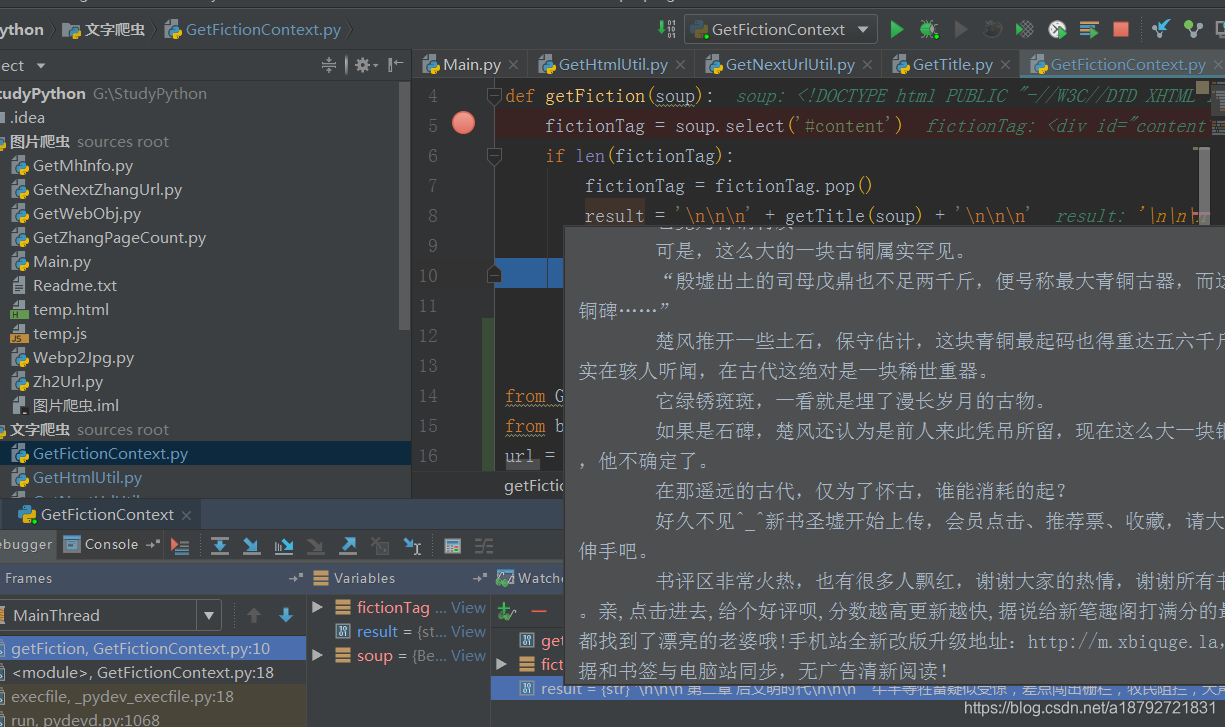
这里有一个比较坑爹的地方:
调试结果如上:
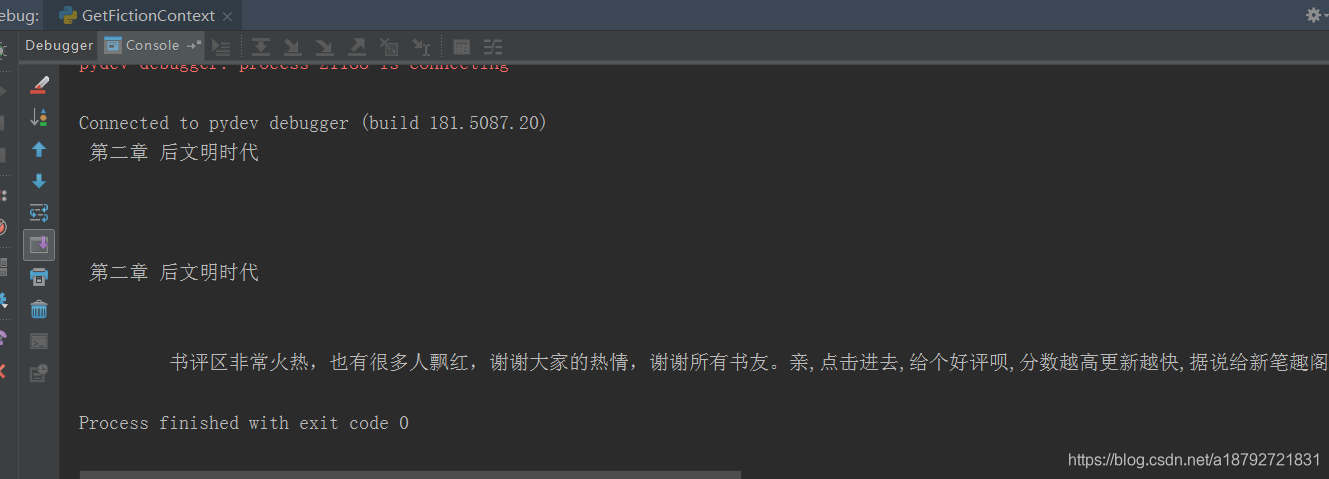
实际输出结果
感觉有些信息被丢失了,所以输出结果与预期不同,不要惊慌,静下心来,慢慢调试。
7.保存章节小说
之前就说过,因为I/O的速度比较慢,所以为了防止文件被占用的问题(此项目中不存在,因为是单线程项目)
使用了缓冲文件的机制。
让每一章都用单独的临时文件保存,当所有的文件全部下载完成后,在进行文件的合并。
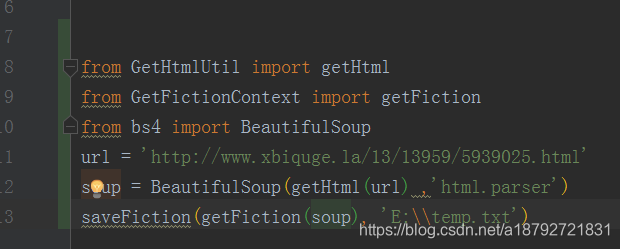
def saveFiction(fiction, filePath):
if fiction is not None and fiction.strip() != '':
file = open(filePath, 'w', encoding='utf-8')
file.write(fiction)
file.close()
这里输入的是带有章节名字的小说正文,和临时文件的存储路径和存储名字。
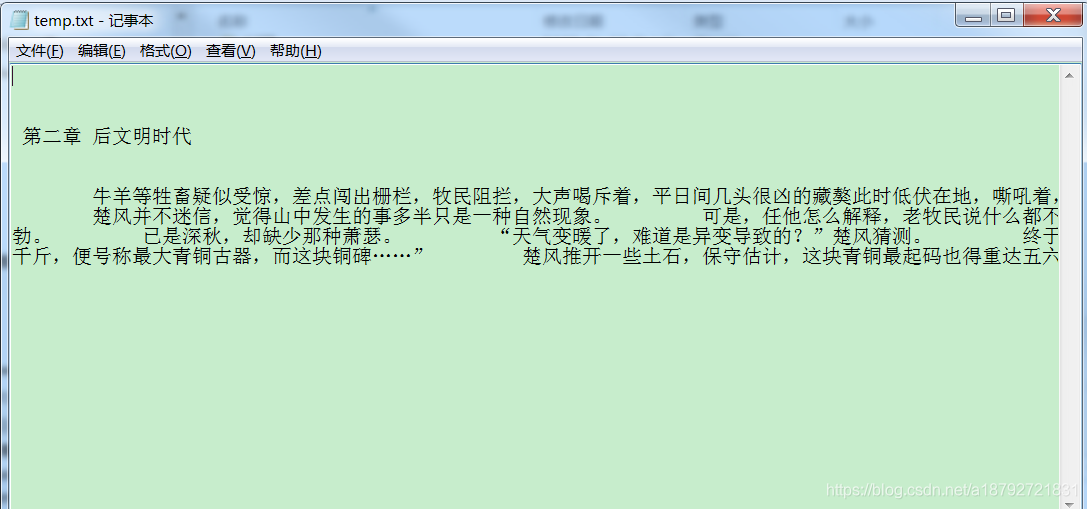
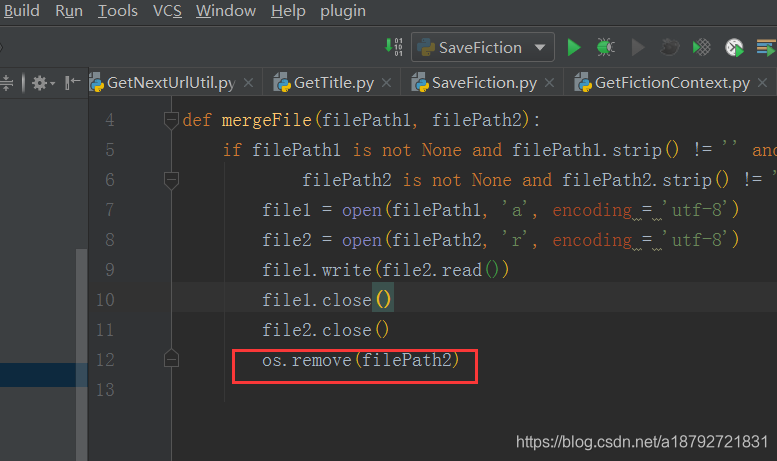
8.合并临时文件
import os
def mergeFile(filePath1, filePath2):
if filePath1 is not None and filePath1.strip() != '' and \
filePath2 is not None and filePath2.strip() != '':
file1 = open(filePath1, 'a', encoding = 'utf-8')
file2 = open(filePath2, 'r', encoding = 'utf-8')
file1.write(file2.read())
file1.close()
file2.close()
os.remove(filePath2)
这里用到了os模块,os模块是Python标准库中就有的,所以无需下载
9.主程序
现在我们完成了静态网页文字爬虫的所有模块,那么,如何把这些模块合并到一起呢?
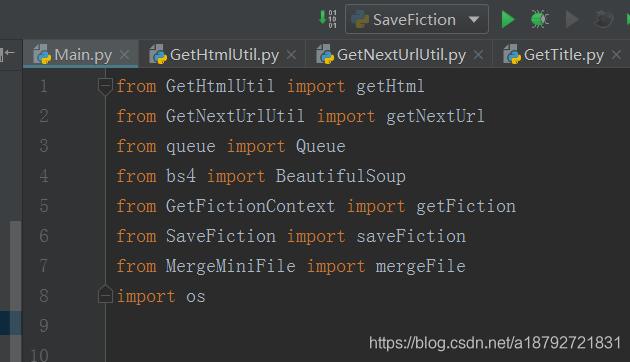
现在各个模块的代码已经完成,所以可以注释或者删除各个模块内部的测试代码
首先主程序组织所有的模块就需要把所有的模块加入:
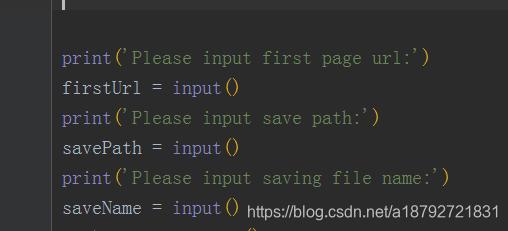
然后为了友好的进行交互:
这里采用了全局队列的处理方式:
首先把初始连接url加入全局的url队列中:
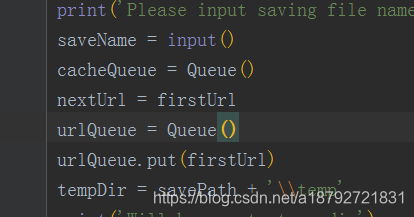
创建临时文件夹
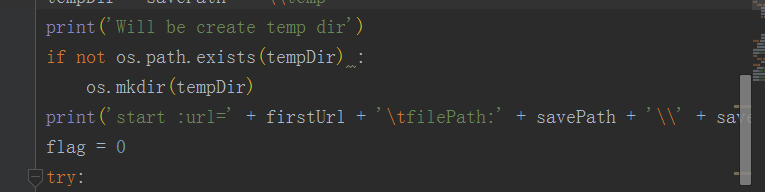
输出进度信息
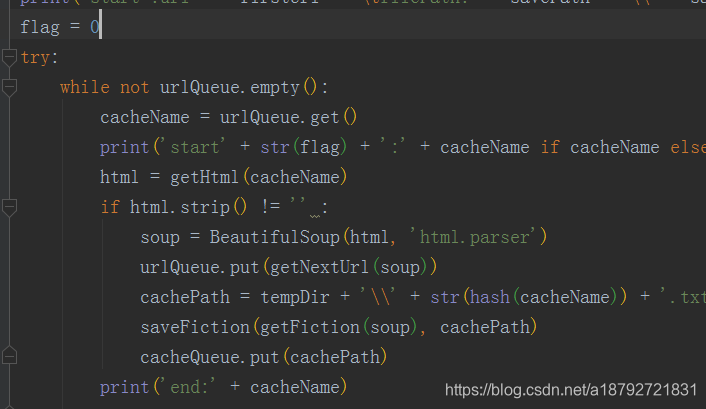
然后临时文件也需要一个全局队列
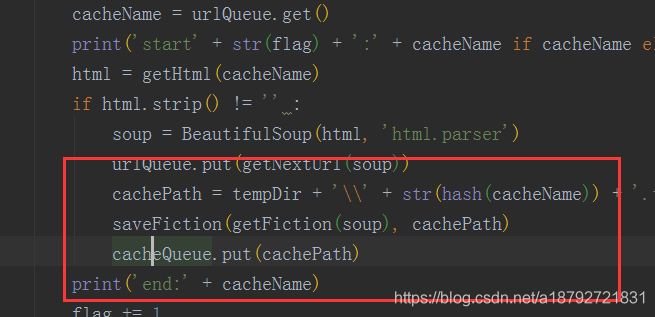
把临时文件目录放入缓冲队列。
临时文件名字生成:
当前网页的url的哈希值
当所有的章节都下载完成后,合并临时文件(合并临时文件后会删除临时文件)
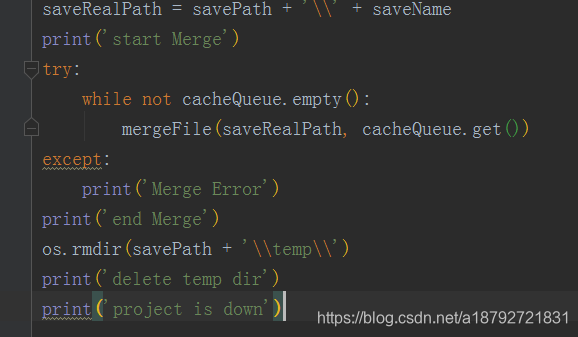
合并完所有的临时文件后会删除临时文件夹。
这个项目因为最后一章是回去不到下一章的链接的,所以需要用try——except处理。
整个项目需要输入三个参数:
1.目标url(只能是此站点,其余站点需要适当修改)
2.小说文件存放目录(临时文件存放目录)
3.小说存储名字(自定义名字)
10.总结
总体来说,使用Python做爬虫比使用java做爬虫简单一些,特别是第三方库的丰富,大大的减轻了做爬虫时重复造轮子的过程。
但是Python确实比较慢(可能与获取网站的网页html速度有直接关系)
最后,附上github地址:https://github.com/a18792721831/StudyPython.git



















 4564
4564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











