






目录
3.1.3、指定进程运行在cpu1上即第二个逻辑CPU核心上
3.1.4、指定进程运行在cpu0~2上即cpu0、cpu1、cpu2三个逻辑CPU核心上
RK3399芯片作为一款高性能的处理器,其多核性能的优化对于提升整体运算效率至关重要。进程绑定CPU核心是一种常见的优化手段,下面我将从不同角度对RK3399芯片如何优化进程绑定CPU核心进行深入解析,并分享一些实例。
一、理解RK3399芯片架构
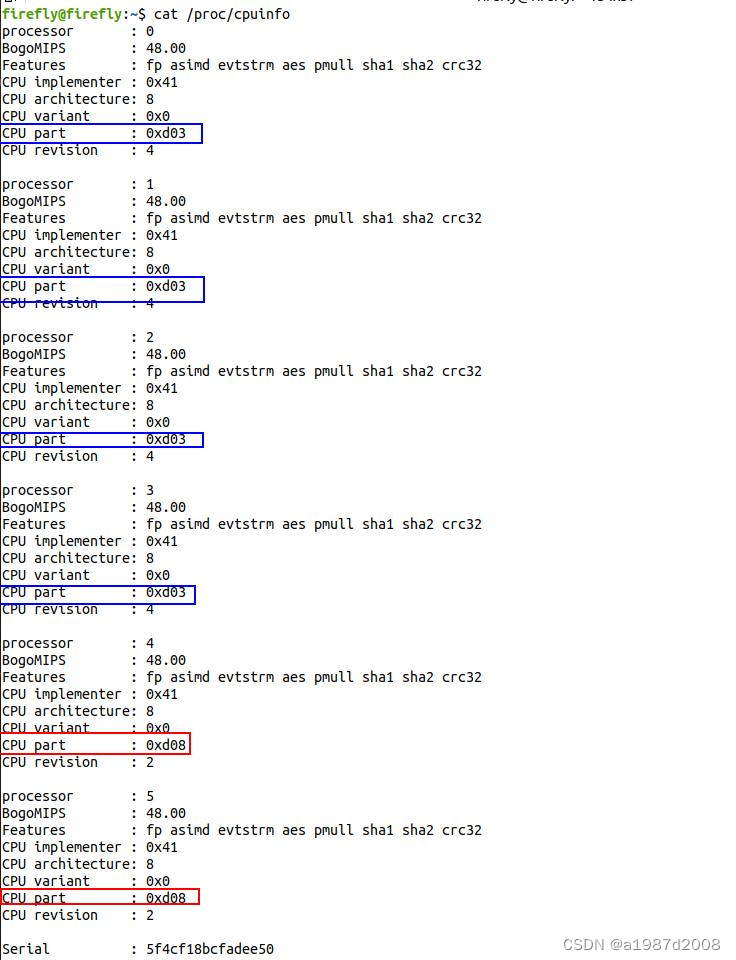
RK3399芯片采用了big.LITTLE架构,拥有两个高性能的ARM Cortex-A72核心和四个低功耗的ARM Cortex-A53核心。这种异构架构使得RK3399既能在高负载场景下提供出色的性能,又能在低负载场景下保持较低的功耗。
二、进程绑定CPU核心的策略
1. 根据进程性质绑定:将计算密集型进程绑定到高性能的A72核心上,将IO密集型进程绑定到低功耗的A53核心上。这样可以充分发挥不同核心的优势,提高整体运算效率。
2. 根据进程优先级绑定:将高优先级的进程绑定到性能更好的核心上,以确保这些进程能够获得更多的计算资源。
3. 动态绑定:根据系统的实时负载情况动态调整进程与核心之间的绑定关系。当某个核心负载较高时,可以将一些进程迁移到其他负载较低的核心上。
三、实例分享
比如以一款运行在RK3399芯片上的图像处理应用为例,该应用需要处理大量的图像数据并进行复杂的计算。通过对该应用的进程进行绑定优化,我们将其绑定到两个Cortex-A72核心上,并充分利用了这些核心的高性能。优化后,应用的处理速度得到了显著提升,同时功耗也保持在了较低水平。
3.1、使用shell命令方式
下面以 bluesea2_node进程展开说明
3.1.1、查看CPU信息
lscpu

cat /proc/cpuinfo
3.1.2、查看进程当前运行在哪个cpu上
taskset -p $(ps -ef | grep "bluesea2_node" | grep -v "grep" | awk '{print $2}')

显示的十进制数字3转换为2进制为11,每个1对应一个cpu,所以进程运行在2个cpu上
3.1.3、指定进程运行在cpu1上即第二个逻辑CPU核心上
taskset -pc 1 $(ps -ef | grep "bluesea2_node" | grep -v "grep" | awk '{print $2}')

3.1.4、指定进程运行在cpu0~2上即cpu0、cpu1、cpu2三个逻辑CPU核心上
taskset -cp 0-2 $(ps -ef | grep "bluesea2_node" | grep -v "grep" | awk '{print $2}')

3.1.5、通过top命令查看进程cpu绑定情况
输入命令:top -p 进程ID,接着输入f,使用键盘箭头移动到P选项(移到P处,按下空格选中),按ESC退出,此时可以看到进程在cpu0 cpu1 cpu2之间不停切换。
top -p $(ps -ef | grep "bluesea2_node" | grep -v "grep" | awk '{print $2}')


#!/bin/bash
# cpu0~3 小核,cpu4~5 大核 实际情况根据每个板子有所不同
# 绑定2D雷达到cpu1
taskset -pc 1 $(ps -ef | grep "bluesea2_node" | grep -v "grep" | awk '{print $2}')
3.2、使用C++代码方式
3.2.1、sched方式
#define _GNU_SOURCE
#include <sched.h>
int sched_setaffinity(pid_t pid, size_t cpusetsize, cpu_set_t *mask);
int sched_getaffinity(pid_t pid, size_t cpusetsize, cpu_set_t *mask);参数:
pid:进程号,如果pid值为0,则表示指定当前进程。
cpusetsize:mask参数所指定数的长度,通常设定为sizeof(cpu_set_t)。
mask:CPU掩码
#include<stdlib.h>
#include<stdio.h>
#include<sys/types.h>
#include<sys/sysinfo.h>
#include<unistd.h>
#define __USE_GNU
#include<sched.h>
#include<ctype.h>
#include<string.h>
#include<pthread.h>
#define THREAD_MAX_NUM 10 //1个CPU内的最多进程数
int CPU_NUM = 0; //cpu中核数
int CPU = 3; // CPU编号
void* threadFun(void* arg)
{
cpu_set_t mask; //CPU核的集合
CPU_ZERO(&mask);
// set CPU MASK
CPU_SET(CPU, &mask);
//设置当前进程的CPU Affinity
if (sched_setaffinity(0, sizeof(mask), &mask) == -1)
{
printf("warning: could not set CPU affinity, continuing...\n");
}
cpu_set_t affinity; //获取在集合中的CPU
CPU_ZERO(&affinity);
// 获取当前进程的CPU Affinity
if (sched_getaffinity(0, sizeof(affinity), &affinity) == -1)
{
printf("warning: cound not get Process affinity, continuing...\n");
}
int i = 0;
for (i = 0; i < CPU_NUM; i++)
{
if (CPU_ISSET(i, &affinity))//判断线程与哪个CPU有亲和力
{
printf("this thread %d is running processor : %d\n", *((int*)arg), i);
}
}
return NULL;
}
int main(int argc, char* argv[])
{
int tid[THREAD_MAX_NUM];
pthread_t thread[THREAD_MAX_NUM];
// 获取核数
CPU_NUM = sysconf(_SC_NPROCESSORS_CONF);
printf("System has %i processor(s). \n", CPU_NUM);
int i = 0;
for(i=0;i<THREAD_MAX_NUM;i++)
{
tid[i] = i;
pthread_create(&thread[i],NULL,threadFun, &tid[i]);
}
for(i=0; i< THREAD_MAX_NUM; i++)
{
pthread_join(thread[i],NULL);
}
return 0;
}3.2.2、pthread方式
#define _GNU_SOURCE
#include <pthread.h>
int pthread_setaffinity_np(pthread_t thread, size_t cpusetsize, const cpu_set_t *cpuset);
int pthread_getaffinity_np(pthread_t thread, size_t cpusetsize, cpu_set_t *cpuset)参数:
pthead:线程对象
cpusetsize:mask参数所指定数的长度,通常设定为sizeof(cpu_set_t)。
mask:CPU掩码
#include<stdlib.h>
#include<stdio.h>
#include<sys/types.h>
#include<sys/sysinfo.h>
#include<unistd.h>
#define __USE_GNU
#include<sched.h>
#include<ctype.h>
#include<string.h>
#include<pthread.h>
#define THREAD_MAX_NUM 10 //1个CPU内的最多进程数
int CPU_NUM = 0; //cpu中核数
int CPU = 3; // CPU编号
void* threadFun(void* arg)
{
cpu_set_t affinity; //获取在集合中的CPU
CPU_ZERO(&affinity);
pthread_t thread = pthread_self();
// 获取当前进程的CPU Affinity
if (pthread_getaffinity_np(thread, sizeof(affinity), &affinity) == -1)
{
printf("warning: cound not get Process affinity, continuing...\n");
}
int i = 0;
for (i = 0; i < CPU_NUM; i++)
{
if (CPU_ISSET(i, &affinity))//判断线程与哪个CPU有亲和力
{
printf("this thread %d is running processor : %d\n", *((int*)arg), i);
}
}
return NULL;
}
int main(int argc, char* argv[])
{
int tid[THREAD_MAX_NUM];
pthread_t thread[THREAD_MAX_NUM];
// 获取核数
CPU_NUM = sysconf(_SC_NPROCESSORS_CONF);
printf("System has %i processor(s). \n", CPU_NUM);
cpu_set_t mask; //CPU核的集合
CPU_ZERO(&mask);
// set CPU MASK
CPU_SET(CPU, &mask);
int i = 0;
for(i=0;i<THREAD_MAX_NUM;i++)
{
tid[i] = i;
pthread_create(&thread[i],NULL,threadFun, &tid[i]);
//设置当前进程的CPU Affinity
if (pthread_setaffinity_np(thread[i], sizeof(mask), &mask) != 0)
{
printf("warning: could not set CPU affinity, continuing...\n");
}
}
for(i=0; i< THREAD_MAX_NUM; i++)
{
pthread_join(thread[i],NULL);
}
return 0;
}四、面临的挑战与解决方案
在进行进程绑定优化时,可能会面临一些挑战,如如何准确判断进程的性质、如何实时监控系统负载等。为了解决这些问题,我们可以采用一些先进的监控工具和技术手段来辅助我们进行进程绑定优化。
注意事项:
1、在绑定cpu时需要注意自己是绑大核还是小核,是绑一个cpu还是多个cpu
2、在绑定多个进程时需要对各进程的资源使用情况及业务场景非常了解,否则不建议绑cpu操作
五、总结与展望
进程绑定CPU核心是优化RK3399芯片性能的重要手段之一。通过深入了解芯片架构、采用合理的绑定策略以及不断尝试和优化,我们可以充分发挥RK3399芯片的性能优势。未来随着技术的不断发展,我们期待有更多的优化手段和技术出现,进一步提升RK3399芯片在多核处理领域的性能表现。
以上就是我对于RK3399芯片如何优化进程绑定CPU核心的一些看法和实例分享。希望能对大家有所帮助。














 4157
4157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









