







- 组合问题:N个数里面按一定规则找出k个数的集合
- 排列问题:N个数按一定规则全排列,有几种排列方式
- 切割问题:一个字符串按一定规则有几种切割方式
- 子集问题:一个N个数的集合里有多少符合条件的子集
- 棋盘问题:N皇后,解数独等等
组合
Cn…k:
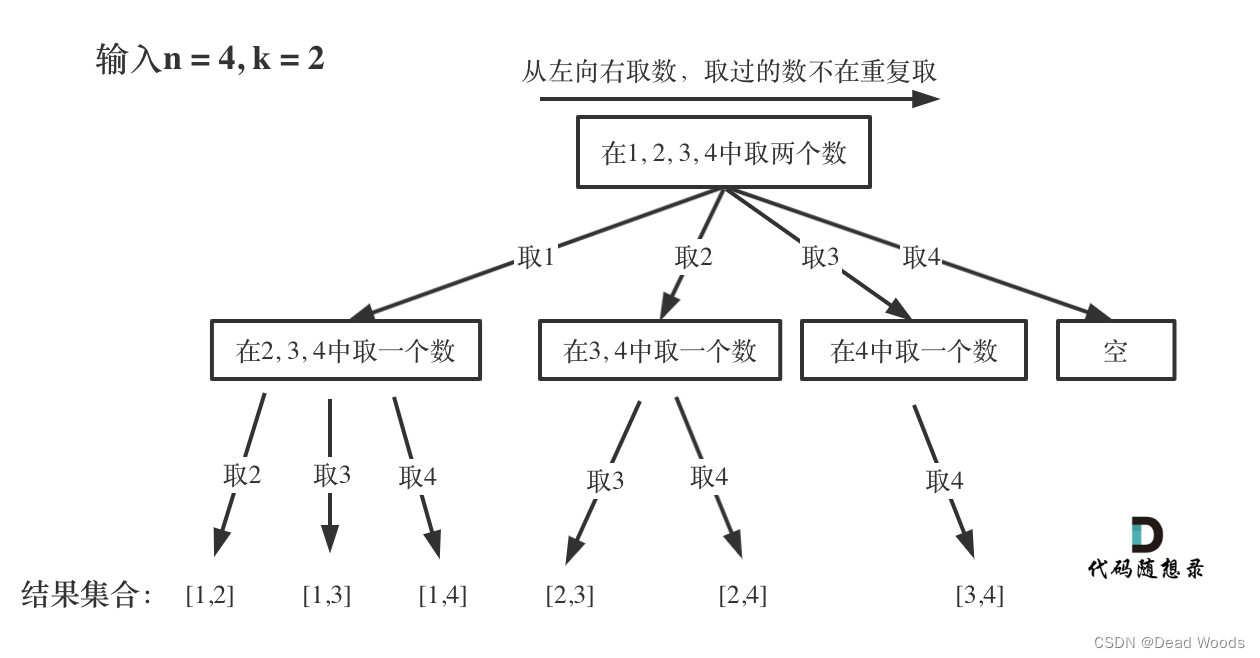
可以看出这棵树,一开始集合是 1,2,3,4, 从左向右取数,取过的数,不再重复取。
第一次取1,集合变为2,3,4 ,因为k为2,我们只需要再取一个数就可以了,分别取2,3,4,得到集合[1,2] [1,3] [1,4],以此类推。
每次从集合中选取元素,可选择的范围随着选择的进行而收缩,调整可选择的范围。
图中可以发现n相当于树的宽度,k相当于树的深度。
那么如何在这个树上遍历,然后收集到我们要的结果集呢?
图中每次搜索到了叶子节点,我们就找到了一个结果。
优化:
接下来看一下优化过程如下:
已经选择的元素个数:path.size();
还需要的元素个数为: k - path.size();
在集合n中至多要从该起始位置 : n - (k - path.size()) + 1,开始遍历
for (int i = startIndex; i <= n - (k - path.size()) + 1; i++){ path.add(i); combineHelper(n, k, i + 1); path.removeLast(); }

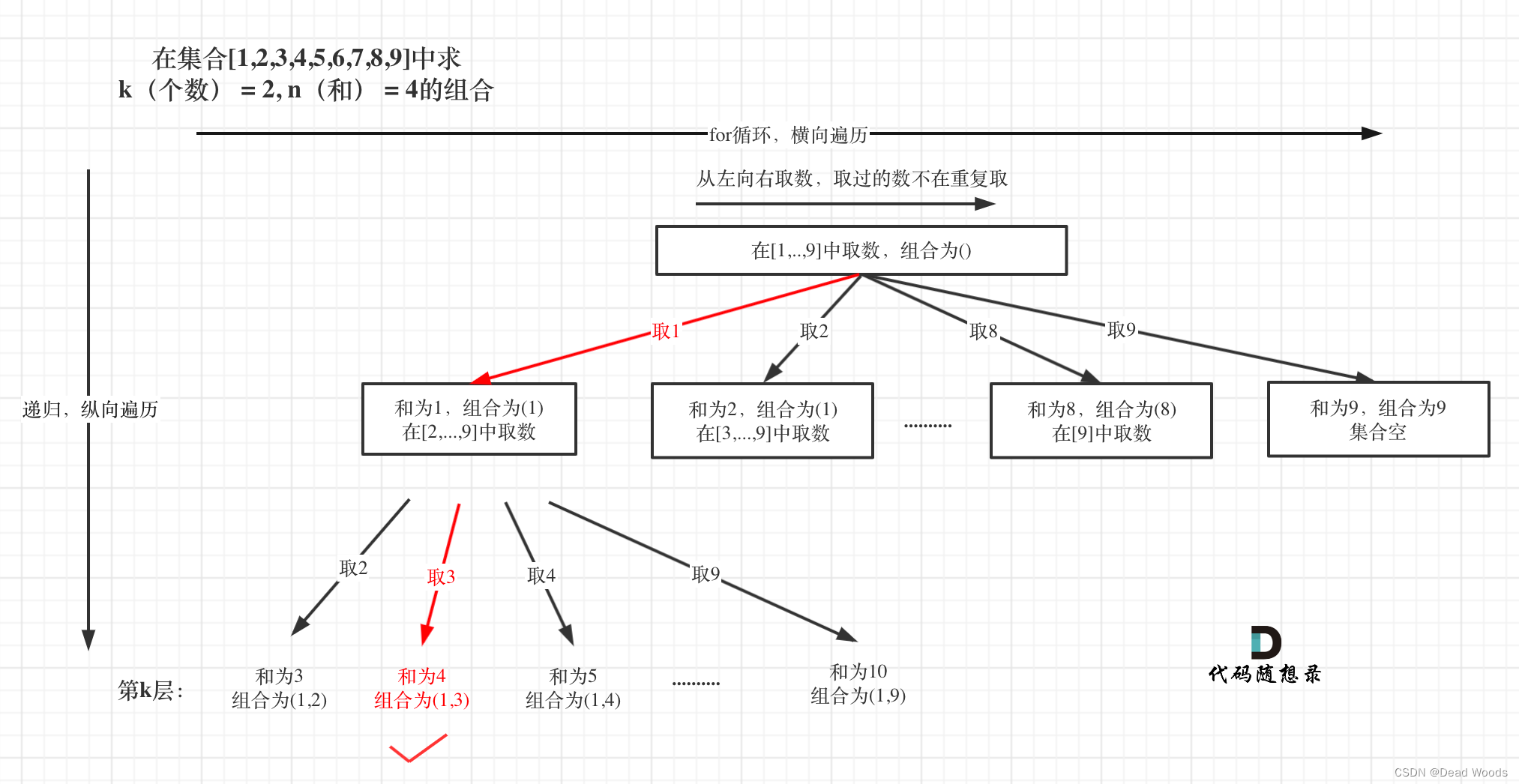
相加之和为 n 的 k 个数的组合。组合中只允许含有 1 - 9 的正整数,并且每种组合中不存在重复的数字。
- 解集不能包含重复的组合。
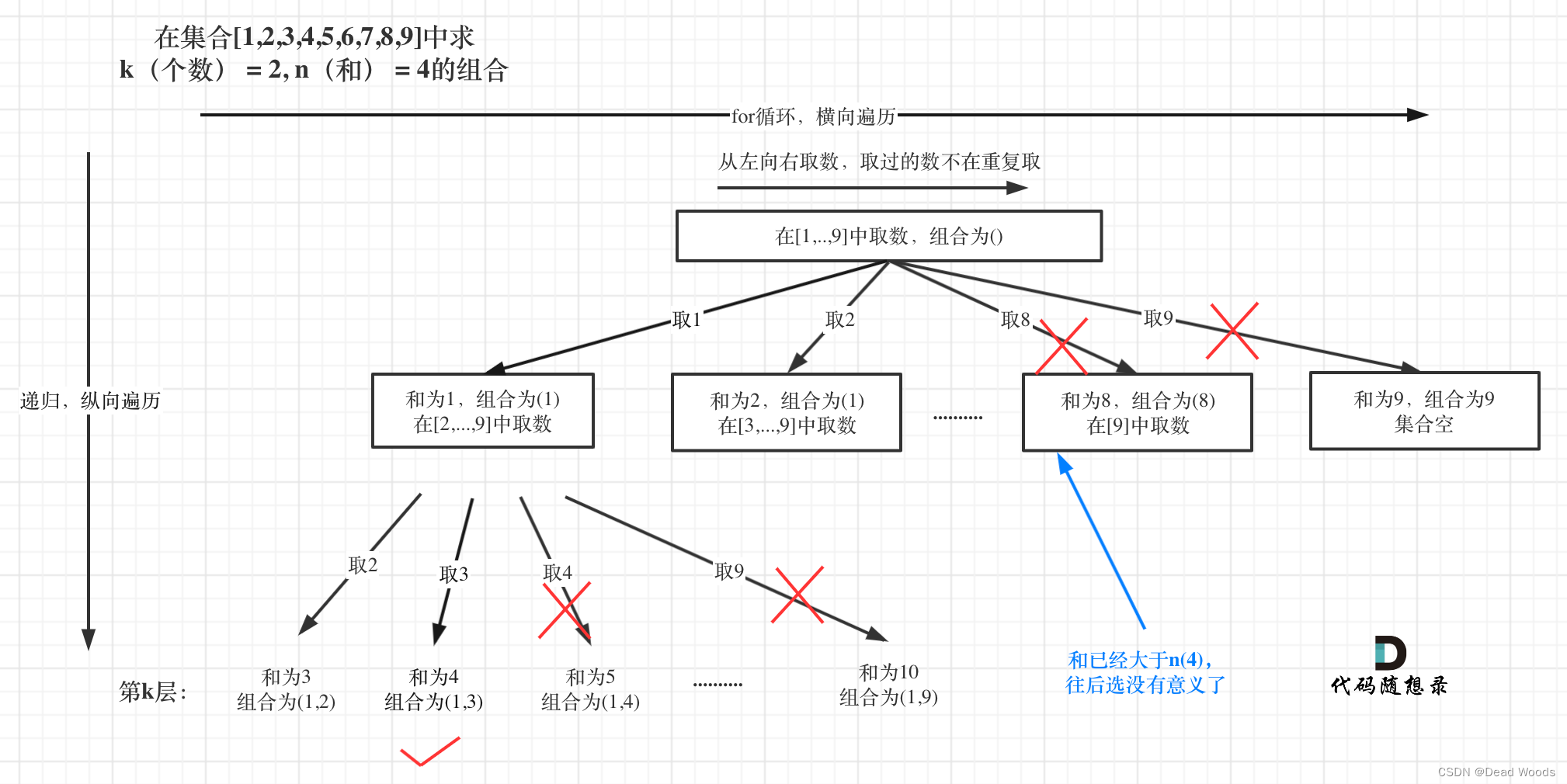
剪枝:
已选元素总和如果已经大于n(图中数值为4)了,那么往后遍历就没有意义了,直接剪掉。
for(int i = start;i<=9- (k - path.size()) + 1;i++){ if(i<=n){ path.add(i); dfs(k,n-i,i+1); path.removeLast(); } }
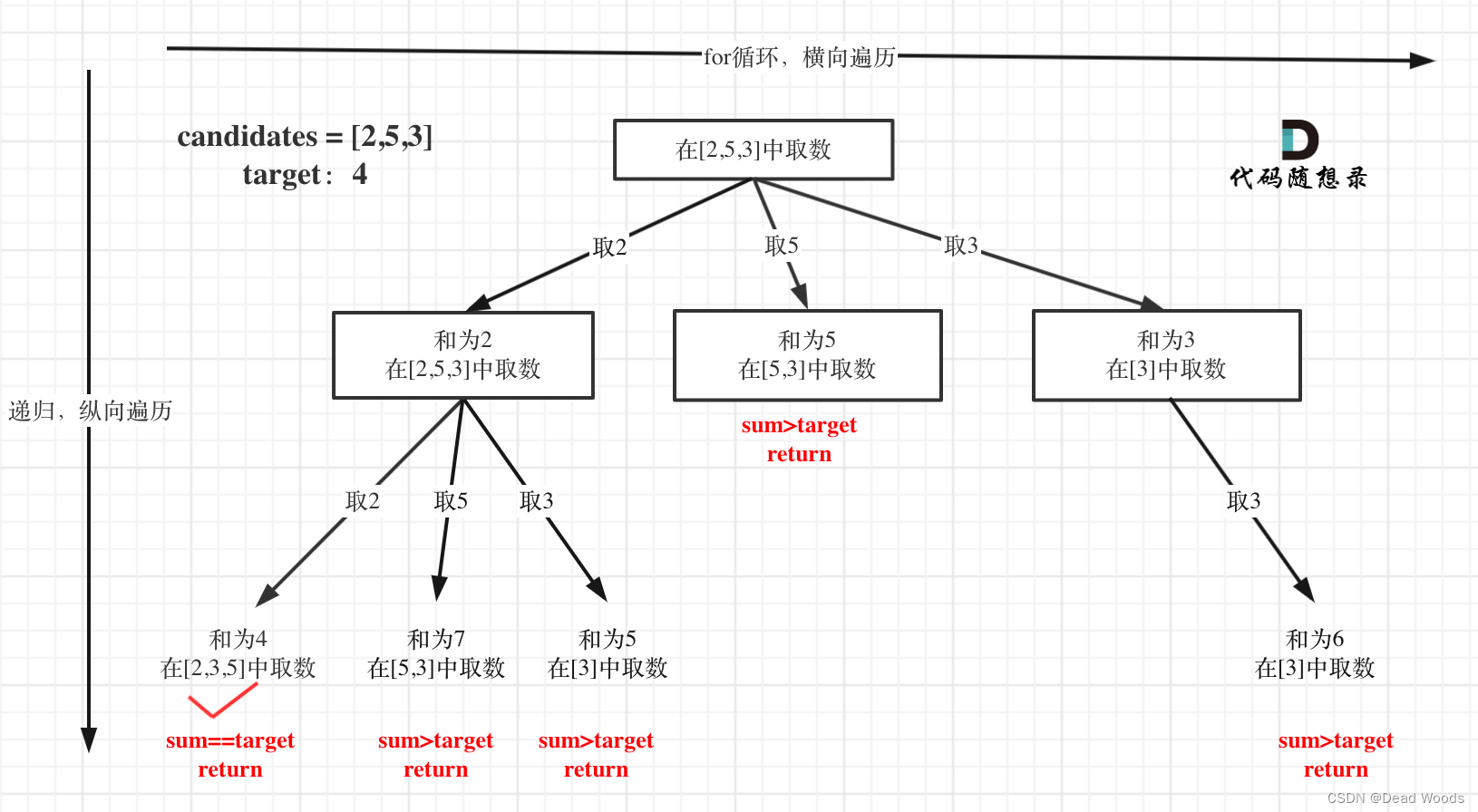
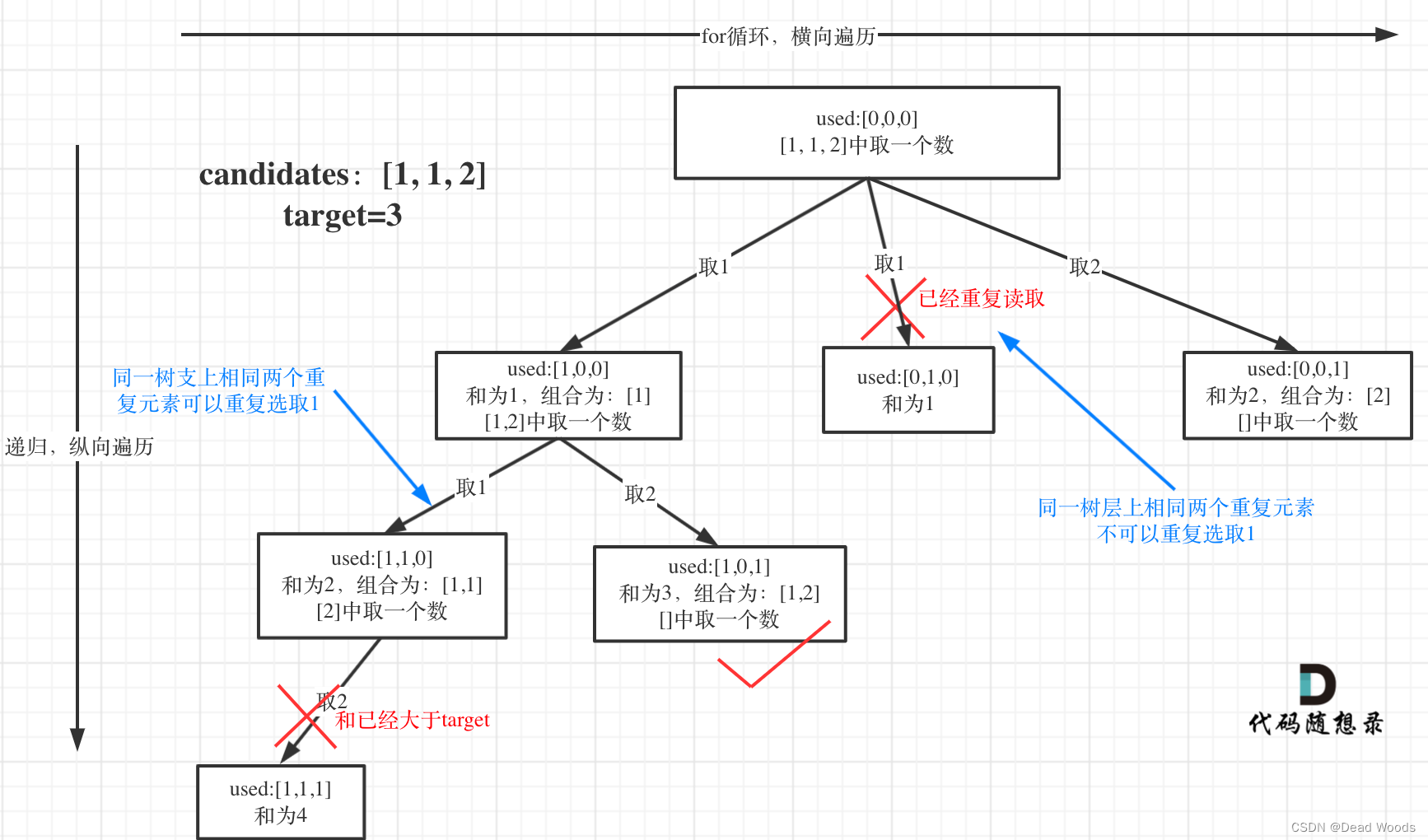
无重复元素的数组 candidates 和一个目标数 target ,candidates 中的数字可以无限制重复被选取。
for(int i= start ; i<candidates.length;i++){ if(candidates[i]<=target){ path.add(candidates[i]); dfs(candidates,target-candidates[i],i); path.removeLast(); } }
找出 (不是无重复)candidates 中所有可以使数字和为 target 的组合。candidates 中的每个数字在每个组合中只能使用一次。解集不能包含重复的组合。
“树枝去重”和“树层去重”。
都知道组合问题可以抽象为树形结构,那么“使用过”在这个树形结构上是有两个维度的,一个维度是同一树枝上“使用过”,一个维度是同一树层上“使用过”。没有理解这两个层面上的“使用过” 是造成大家没有彻底理解去重的根本原因。
for (int i = startIndex; i < candidates.length; i++) { if (sum + candidates[i] > target) { break; } // 出现重复节点,同层的第一个节点已经被访问过,所以直接跳过 if (i > 0 && candidates[i] == candidates[i - 1] && !used[i - 1]) { continue; } used[i] = true; sum += candidates[i]; path.add(candidates[i]); // 每个节点仅能选择一次,所以从下一位开始 backTracking(candidates, target, i + 1); used[i] = false; sum -= candidates[i]; path.removeLast(); }
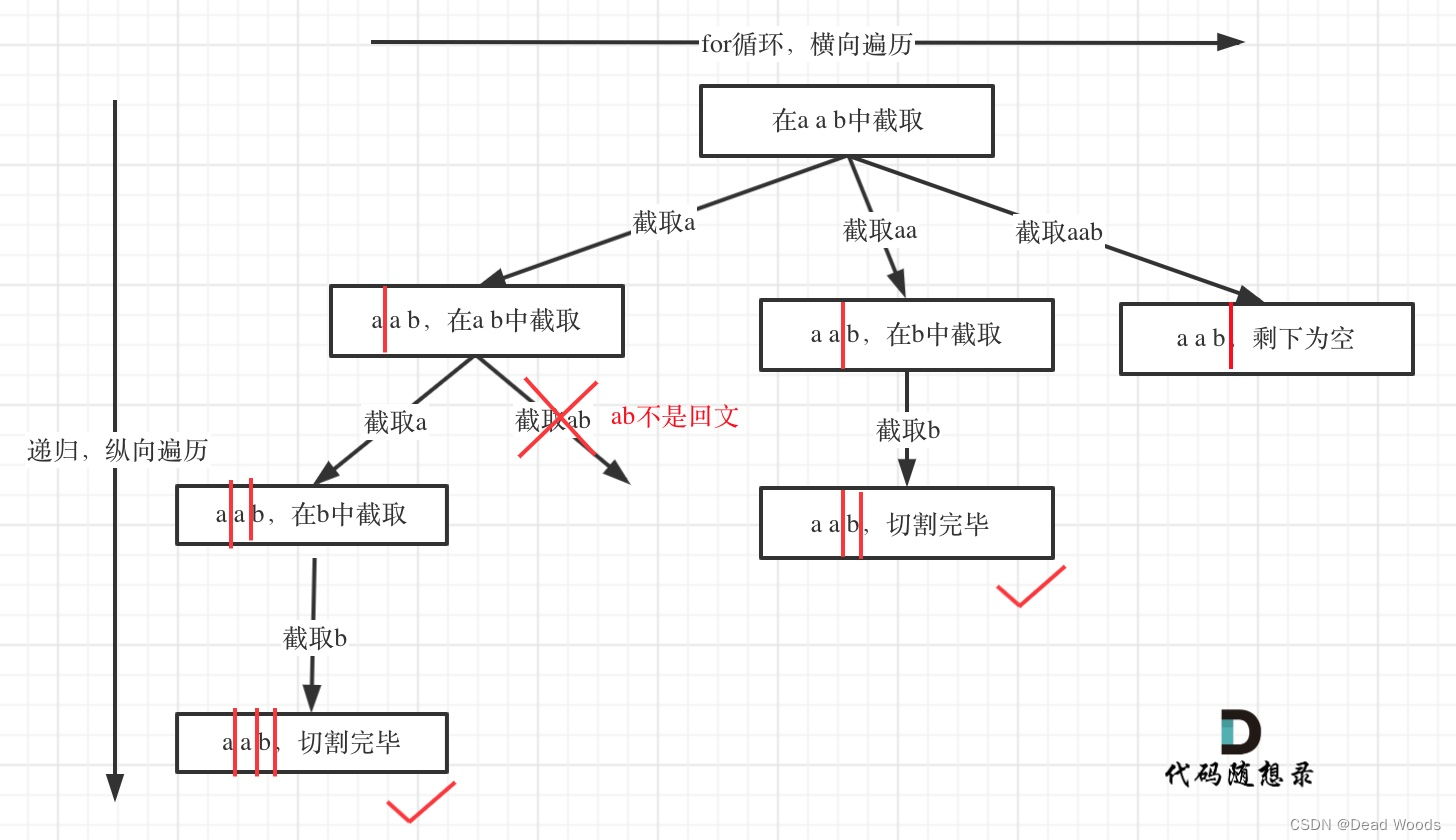
分割
- 组合问题:选取一个a之后,在bcdef中再去选取第二个,选取b之后在cdef中再选取第三个.....。
- 切割问题:切割一个a之后,在bcdef中再去切割第二段,切割b之后在cdef中再切割第三段.....。
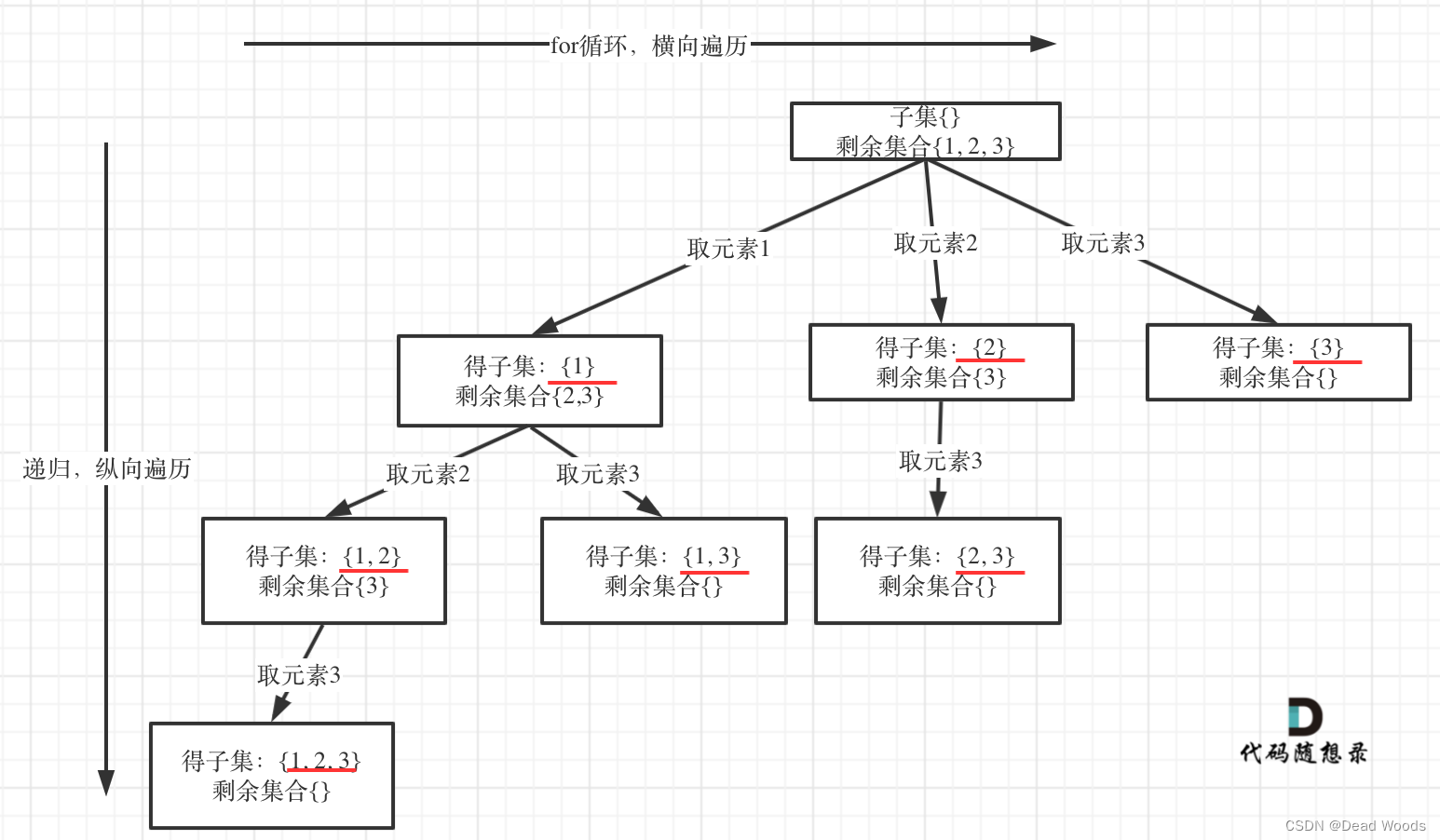
子集
如果把 子集问题、组合问题、分割问题都抽象为一棵树的话,那么组合问题和分割问题都是收集树的叶子节点,而子集问题是找树的所有节点!
其实子集也是一种组合问题,因为它的集合是无序的,子集{1,2} 和 子集{2,1}是一样的。
那么既然是无序,取过的元素不会重复取,写回溯算法的时候,for就要从startIndex开始,而不是从0开始!
有同学问了,什么时候for可以从0开始呢?
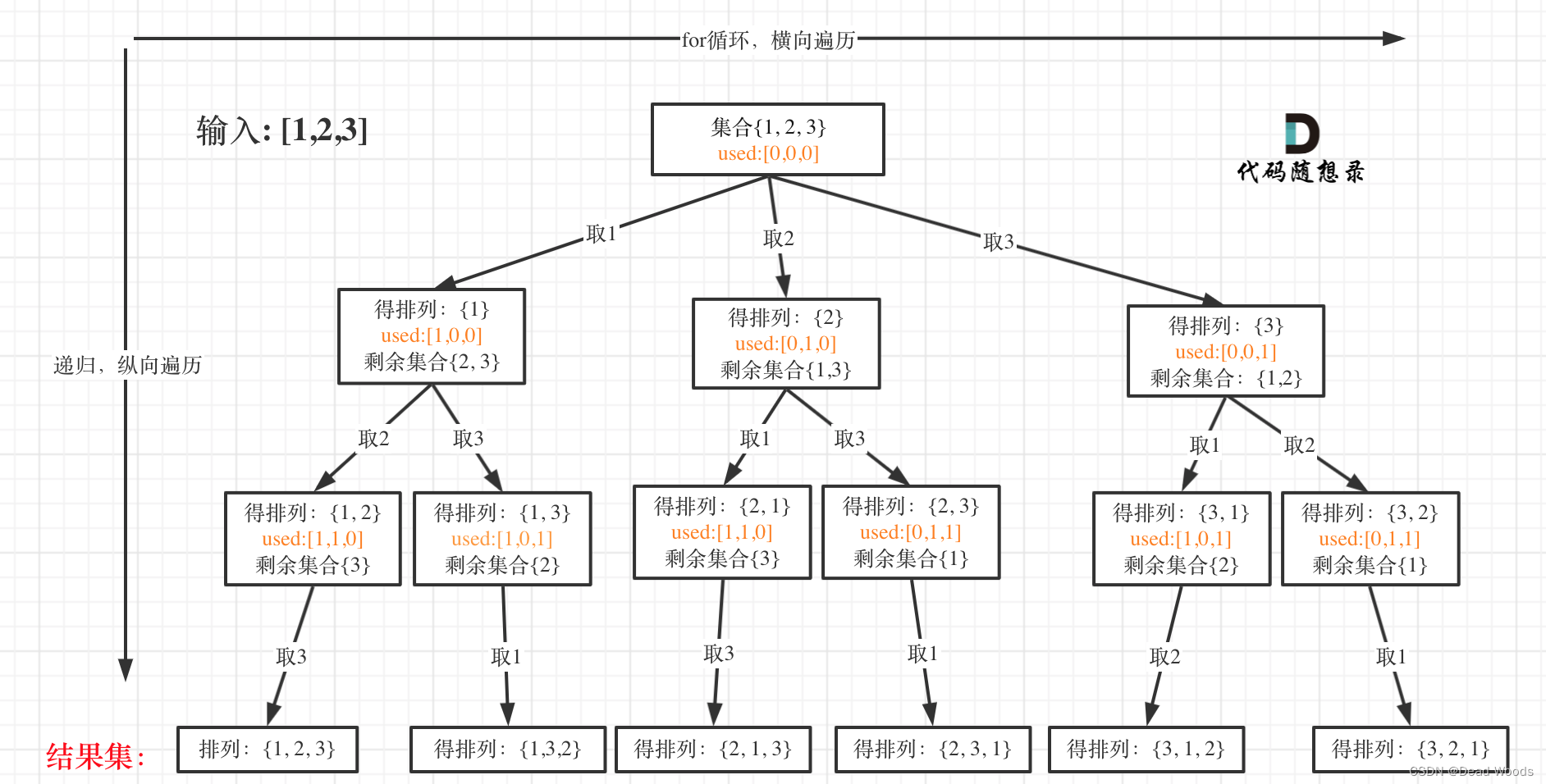
求排列问题的时候,就要从0开始,因为集合是有序的,{1, 2} 和{2, 1}是两个集合,排列问题我们后续的文章就会讲到的。
从图中红线部分,可以看出遍历这个树的时候,把所有节点都记录下来,就是要求的子集集合。
剩余集合为空的时候,就是叶子节点。
那么什么时候剩余集合为空呢?
就是startIndex已经大于数组的长度了,就终止了,因为没有元素可取了
求取子集问题,不需要任何剪枝!因为子集就是要遍历整棵树。
private void subsetsHelper(int[] nums, int startIndex){ result.add(new ArrayList<>(path));//「遍历这个树的时候,把所有节点都记录下来,就是要求的子集集合」。 if (startIndex >= nums.length){ //终止条件可不加 return; } for (int i = startIndex; i < nums.length; i++){ path.add(nums[i]); subsetsHelper(nums, i + 1); path.removeLast(); } }
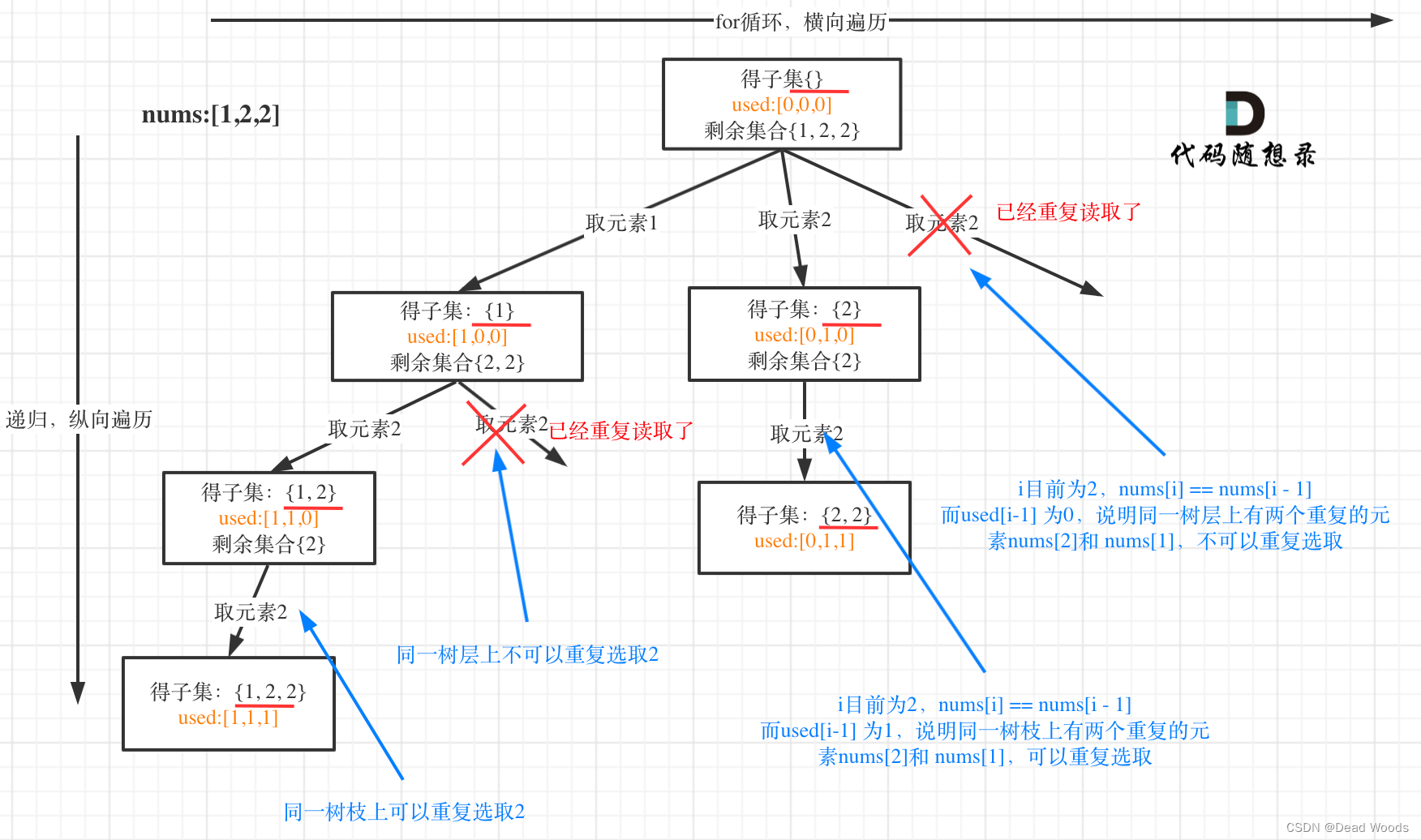
给定一个可能包含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
说明:解集不能包含重复的子集。
for (int i = startIndex; i < nums.length; i++){ if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1]){ continue; } path.add(nums[i]); used[i] = true; subsetsWithDupHelper(nums, i + 1); path.removeLast(); used[i] = false; }for ( int i = start; i < nums.length; i++ ) { // 跳过当前树层使用过的、相同的元素 if ( i > start && nums[i - 1] == nums[i] ) { continue; } path.add( nums[i] ); subsetsWithDupHelper( nums, i + 1 ); path.removeLast(); }
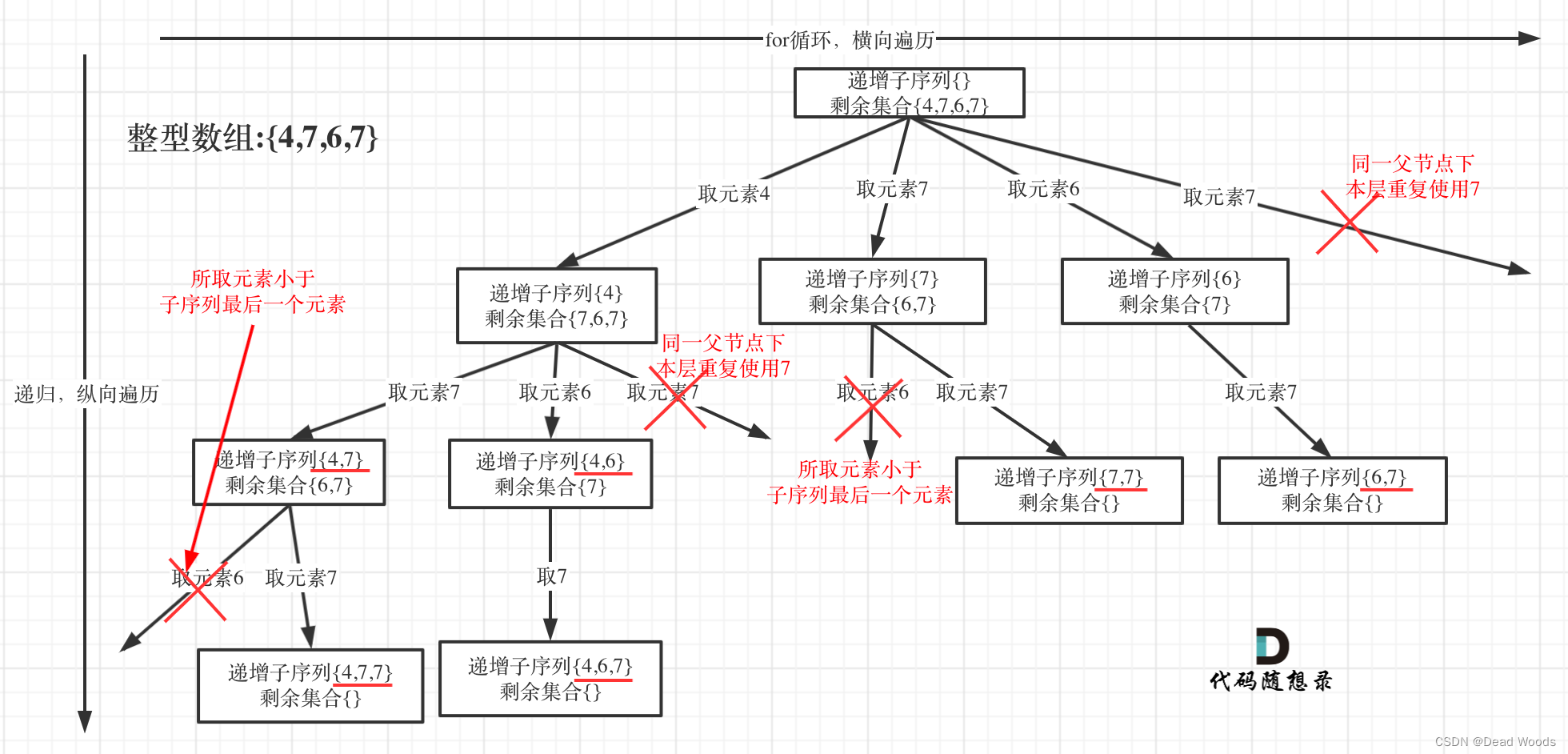
这个递增子序列比较像是取有序的子集。而且本题也要求不能有相同的递增子序列。
这又是子集,又是去重。
在90.子集II (opens new window)中我们是通过排序,再加一个标记数组来达到去重的目的。
而本题求自增子序列,是不能对原数组进行排序的,排完序的数组都是自增子序列了。
所以不能使用之前的去重逻辑!
在图中可以看出,同一父节点下的同层上使用过的元素就不能再使用了。
HashSet<Integer> hs = new HashSet<>(); for(int i = startIndex; i < nums.length; i++){ if(!path.isEmpty() && path.get(path.size() -1 ) > nums[i] || hs.contains(nums[i])) continue; hs.add(nums[i]); path.add(nums[i]); backTracking(nums, i + 1); path.remove(path.size() - 1); }
排列
没有重复 数字的序列,返回其所有可能的全排列。
for (int i = 0; i < nums.length; i++){ if (used[i]){ continue; } used[i] = true; path.add(nums[i]); permuteHelper(nums); path.removeLast(); used[i] = false; }
给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
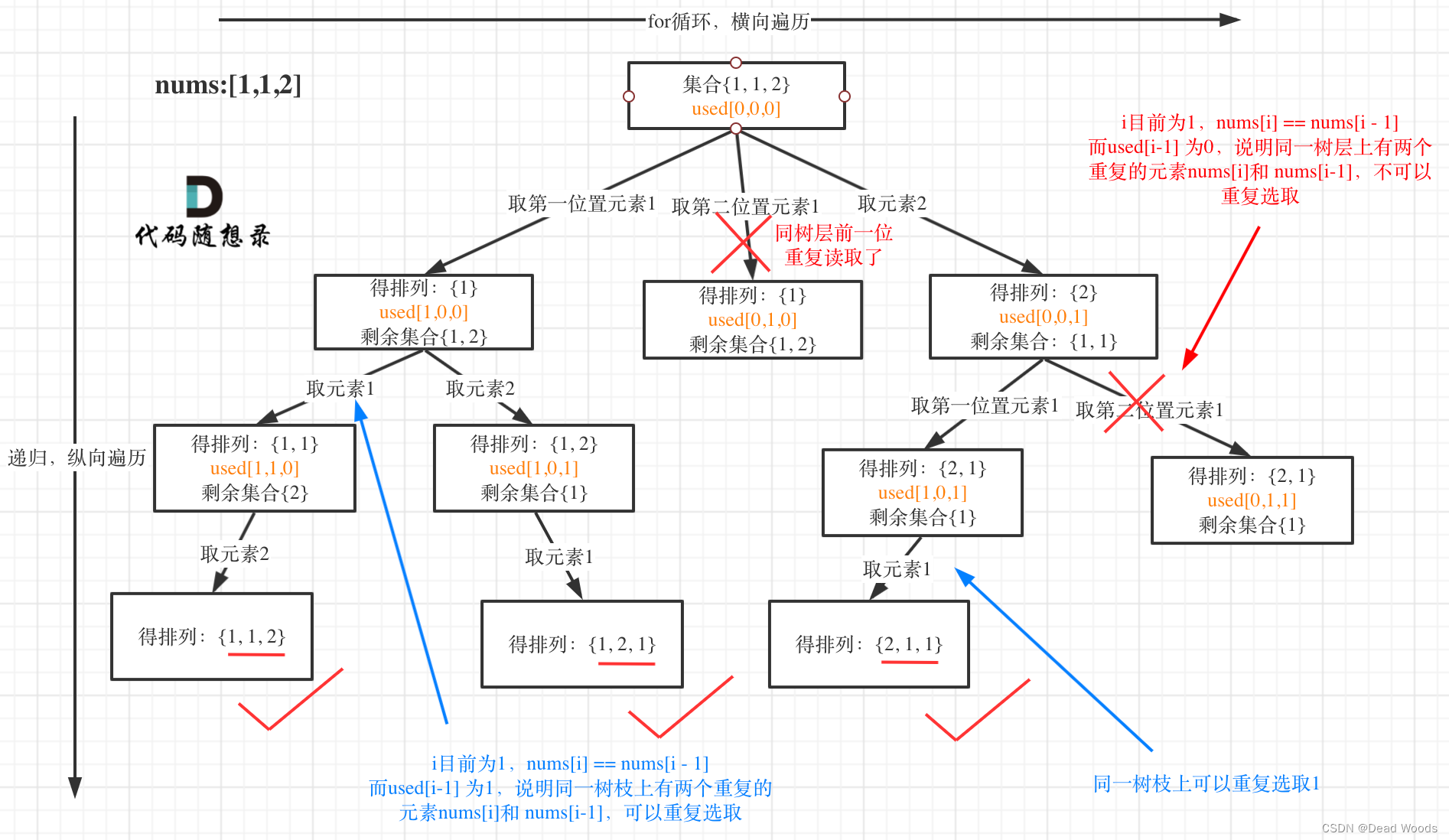
for (int i = 0; i < nums.length; i++) {
// used[i - 1] == true,说明同⼀树⽀nums[i - 1]使⽤过
// used[i - 1] == false,说明同⼀树层nums[i - 1]使⽤过
// 如果同⼀树层nums[i - 1]使⽤过则直接跳过
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) {
continue;
}
//如果同⼀树⽀nums[i]没使⽤过开始处理
if (used[i] == false) {
used[i] = true;//标记同⼀树⽀nums[i]使⽤过,防止同一树枝重复使用
path.add(nums[i]);
backTrack(nums, used);
path.remove(path.size() - 1);//回溯,说明同⼀树层nums[i]使⽤过,防止下一树层重复
used[i] = false;//回溯
}
}














 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









