







核心内容:
1、Scala IDEA安装过程
2、Spark的3种运行模式
3、Scala IDEA编写Spark的WordCount程序(本地模式与集群模式)
今天学习了用Scala IEDA去编写Spark的第一个程序WordCount,整理一下主要的学习笔记。
一、Scala IDEA的安装过程
直接上截图:
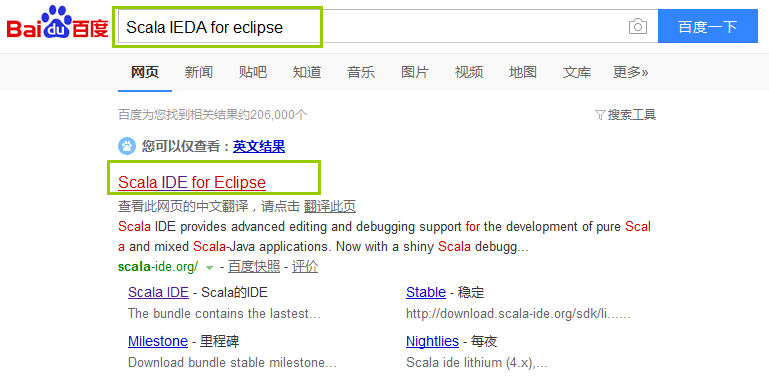
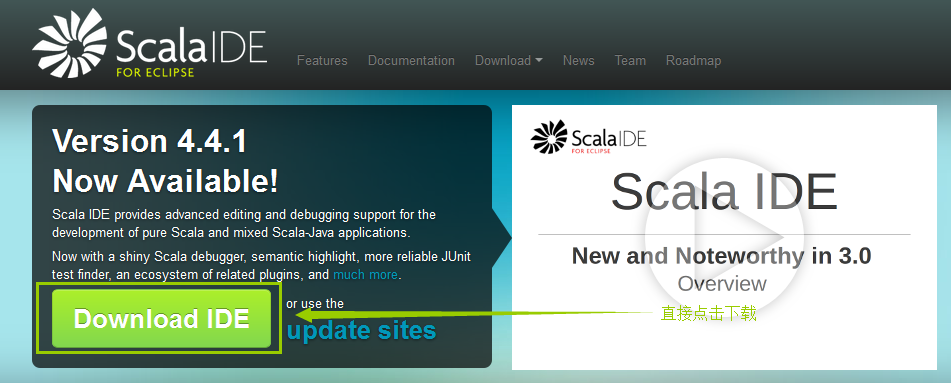
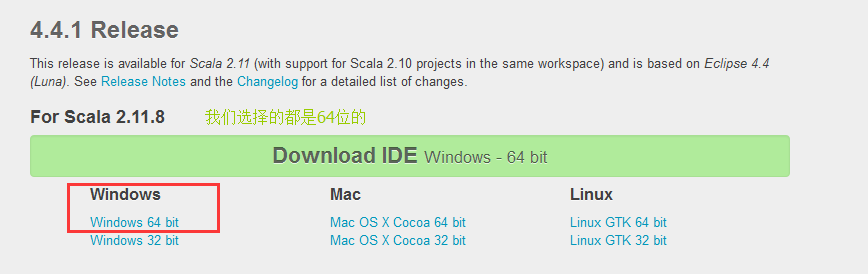
点击之后就可以下载到我们的Scala IDEA:

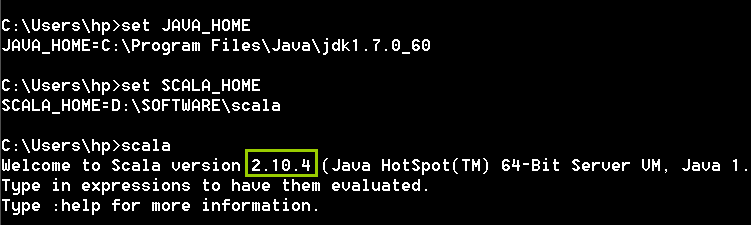
在Scala IDEA安装过程中必须要注意一点:
在安装Scala IDEA之前必须要在本地安装好JDK(最低1.7)和Scala2.10.X版本,并配置好相应的环境变量。
二、Spark的3种运行模式
Spark的运行模式分为3种:本地运行模式、伪分布运行模式、集群运行模式
本地运行模式:不需要运行Spark的任何守护进程,所有程序都在单个JVM上进行执行,这种模式常用于程序员进行编程和本地测试进行使用。
伪分布运行模式:如果Spark的所有守护进程都在同一台服务器上面运行,称为伪分布运行模式,这种运行模式常用于开发人员机器环境受限制的情况下使用。
注意:Spark的伪分布运行模式可以在一台服务器上面模拟集群环境,但仅仅是机器数量少,其通信机制与运行过程与真正的集群环境是一样的。
集群运行模式:如果Spark的守护进程运行在不同的服务器上面,称为集群运行模式,所谓集群模式就是服务器的角色有主有从。
Spark的最佳编程实践:先通过本地模式进行程序测试,随后将程序打成jar包后在集群环境下运行。
三、Scala IDEA编写Spark的WordCount程序(本地模式与集群模式)
在正式开发Spark程序之前,我们需要先配置一下开发环境,达到下面的效果:

注意:项目创建完成以后,默认使用的是scala2.11.X版本,此时我们需要手动将版本换成2.10.X版本,方法如下:
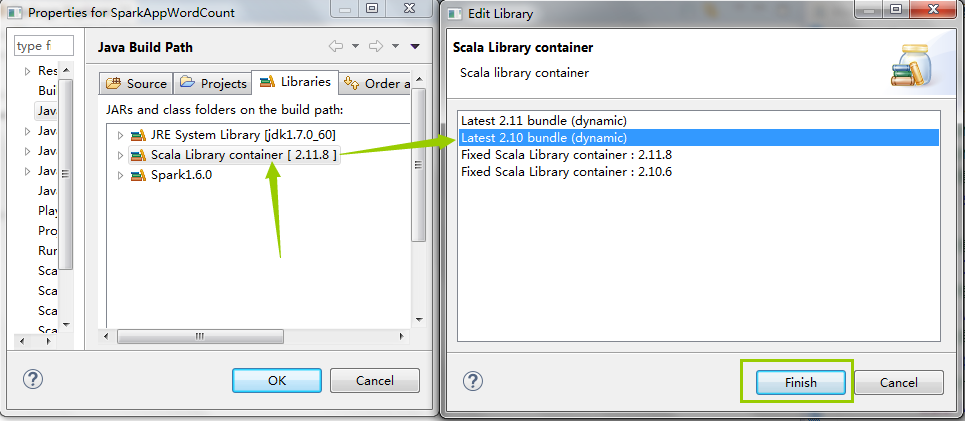
最终效果为:

将上面的操作概括为两点:
1>在项目中加入Spark 1.6.0的jar依赖
2>将项目默认依赖的Scala2.11.X版本手动改为Scala 2.10.X 版本
接下来我们编写本地模式下的Spark-WordCount程序,直接贴代码:
package com.spark.wordcount
import org.apache.spark.rdd.RDD
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object WordCount
{
def main(args:Array[String]):Unit=
{
val conf = new SparkConf()
conf.setAppName("WordCount Of Spark")
conf.setMaster("local") //此时Spark运行在本地模式
//创建SparkContext实例对象
val sc = new SparkContext(conf)
//创建RDD对象,指定输入文件的路径
val lines:RDD[String] = sc.textFile("C:\\word.txt",1)
//对每一行的字符串进行单词拆分,并把所有行的拆分结果通过flat合并为一个大的单词集合
val words = lines.flatMap { line => line.split(" ") }
//在单词拆分的基础上对每个单词实例计数为1,也就是word=>(word,1)
val pairs = words.map { word => (word,1) }
//统计每个单词在文件中出现的总次数,对相同的key,进行value的累积(包括Local和Reduce级别同时Reduce)
val wordCounts = pairs.reduceByKey(_+_)
//打印出单词和相应的数量
wordCounts.foreach(wordNumberPair => println(wordNumberPair._1+":"+wordNumberPair._2))
sc.stop()
}
}程序的运行结果:
Spark:1
you:2
Hello:4
hello:2
baby:1
me:1
Hadoop:1在程序的运行过程中会抛出一个异常:
16/11/19 15:37:19 INFO SparkContext: Running Spark version 1.6.0
16/11/19 15:37:29 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/11/19 15:37:30 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:318)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:333)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:326)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:76)
at org.apache.hadoop.security.Groups.parseStaticMapping(Groups.java:93)
at org.apache.hadoop.security.Groups.<init>(Groups.java:77)
at org.apache.hadoop.security.Groups.getUserToGroupsMappingService(Groups.java:240)
at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:255)
at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:232)
at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:718)
at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:703)
at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:605)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2136)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2136)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:2136)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:322)
at com.spark.wordcount.WordCount$.main(WordCount.scala:16)
at com.spark.wordcount.WordCount.main(WordCount.scala)对于上面的这个错误,是很正常的,因为spark是和hadoop编译在一起的,我们在windows下开发,缺少hadoop的相关配置,上面并不是程序的错误,也不影响我们的任何功能。所以我们不用任何改正。
接下来我们对于上面的程序进行重点分析:

1、创建Spark的配置对象SparkConf,并设置Spark程序运行时的相关配置信息,例如通过setMaster来设置spark的程序运行在本地模式(local)还是集群模式(可以指定Master的URL,不指定也可以);setAppName来指定应用程序的名称,在程序运行时的监控界面可以看到相关名称。

2、创建SparkContext对象
①SparkContext是Spark程序所有功能的唯一入口,无论是采用Scala、Java、Python、R等都必须有一个Spark Context.
②SparkContext的核心作用:初始化Spark应用程序运行时所需要的核心组件,包括DAGScheduler(任务调度器)、TaskScheduler、SchedulerBackend,同时SparkContext还会负责Spark程序往Master进行注册等。
③SparkContext是整个Spark应用程序中最为至关重要的一个对象。

3、根据具体的数据来源(如HDFS、HBase、Local FS、DB、云上的S3等)通过SparkContext来创建RDD。
RDD的创建基本有3种方式:
根据外部的数据来源(例如HDFS)、根据Scala集合(例如rang)、由其他的RDD操作(transformation与action、transformation一般都会产生新的RDD)产生。
数据会被RDD化分成为一些列的Partitions,分配到每个Partition的数据属于一个Task的处理范畴;即我们的数据会被分成不同的partitions,每个partitions就会被task处理。
在sc.textFile()中,第一个参数指的是文件的路径,第二个指的是它的最小的并行度,第二个参数需要根据当前机器的情况来看,sc.textFile(“C:\word.txt”,1)代表读取本地文件并设置为1个partition。
接下来我们接着讲述集群模式下的Spark-WordCount程序:
先贴代码:
package com.spark.wordcount
import org.apache.spark.rdd.RDD
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object WordCountCluster
{
def main(args:Array[String]):Unit=
{
val conf = new SparkConf()
conf.setAppName("WordCount Of Spark")
//下面这行代码可以指定,也可以不指定
//conf.setMaster("spark://hadoop11:7077")
//创建SparkContext实例对象
val sc = new SparkContext(conf)
//创建RDD对象,指定输入文件的路径,可以写成hdfs://NameNode:9000/word.txt
val lines:RDD[String] = sc.textFile("/word.txt")
//对每一行的字符串进行单词拆分,并把所有行的拆分结果通过flat合并为一个大的单词集合
val words = lines.flatMap { line => line.split(" ") }
//在单词拆分的基础上对每个单词实例计数为1,也就是word=>(word,1)
val pairs = words.map { word => (word,1) }
//统计每个单词在文件中出现的总次数,对相同的key,进行value的累积(包括Local和Reduce级别同时Reduce)
val wordCounts = pairs.reduceByKey(_+_)
//打印出单词和相应的数量,注意修改处:
wordCounts.collect.foreach(wordNumberPair => println(wordNumberPair._1+":"+wordNumberPair._2))
sc.stop()
}
}在集群模式下运行上面的程序:
[root@hadoop11 mydata]# spark-submit --class com.spark.wordcount.WordCountCluster --master spark://hadoop11:7077 SparkWordCount.jar运行结果:
scala:1
hello:2
java:2
spark:1
you:1
hadoop:1验证结果:
[root@hadoop11 local]# hadoop fs -cat /word.txt
hello you
spark hadoop
java scala
java hello很明显,程序运行是正确的。
对于Spark的集群的WordCount程序,有一下几个注意事项:

①不建议在程序的编写过程中写conf.setMaster(“spark://Master:7077”),因为一旦指定具体的路径之后,程序的运行就具体依赖于某个具体的集群了,如果不指定,在提交任务的时候提交的命令会根据上下文帮助我们配置相应的内容.
②同理,在编写程序的时候不建议直接写HDFS具体的访问路径,理由同上.
③当程序在集群中运行的时候,可以不用指定并行的数量,即不用指定partition的数量了,因为默认有相应的配置.
④集群中需要改为wordCounts.collect.foreach…..
OK,明天继续努力,今天晚上还要在看几遍程序!!!


















 577
577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











