







综合微服务项目 ----- Offer Campus
内容管理
Offer Campus 技术选型尝试 — Dubbo微服务
cfeng着手开发微服务项目,一开始选择了Dubbo进行开发,结果搭建好了结构之后才意识到后面的困难,遂放弃,选用Spring Cloud
Cfeng记录一下技术架构过程中意识到的问题, 最开始记录的是最开始选用Dubbo架构微服务的相关的思考,最开始的愿景
初始选用Dubbo架构
项目采用分布式集群架构,并且使用JenKins进行自动化构建,这样可以降低系统间的耦合度,易于扩展,并且微服务的复用性高,比如用户微服务所有的产品都可以使用
微服务项目的构建主要有Dubbo和SpringCloud两种方案供选择,二者的区别就是Spring有完整的生态体系并且初始定位就是作为一套完整的微服务架构解决方案,而Dubbo最开始只是简单作为RPC框架进行服务的治理, Dubbo的通信使用的应用层协议为Dubbo协议,而SpringCloud使用http协议;
本项目cfeng选用Dubbo进行构建, 理由: 作为一个探索性和长久维护项目, 需要更加DIY,也就是灵活选用各种组件进行微服务相关的功能实现, 而SpringCloud 本身给出一套完善的解决方案,比如Eureka、Ribbon等, 而Dubbo则可以灵活选择各种组件进行搭配(虽然会产生很多Jar依赖问题,但相比maven出现之前可好多了), 并且Dubbo的降级策略、熔断策略等非常值得研究 【按照Cfeng目前的理解,SpringCloud作为完善的解决方案,是一套非常容易上手的解决方案,可以快速构建微服务项目,但是对于理解各组件就…】
因为dubbo开发微服务的难度稍大(因为cfeng想要的是一个完善的微服务,而不是一个假“微服务”)
Dubbo会将系统需要发布的服务发送给注册中心,并且需要消费服务的时候,将会直接建立一条RPC信道,直接进行服务的调用
传统的Dubbo架构 以及劣势
最开始设想的架构:
Dubbo属于rpc调用 — 服务是通过dubbo协议直接暴露的service接口, 所以要使用服务,必须提供一个web层的服务作为http入口给客户端调用,在web层提供安全认证基础功能,web层再对接nginx进行统一入口、负载均衡
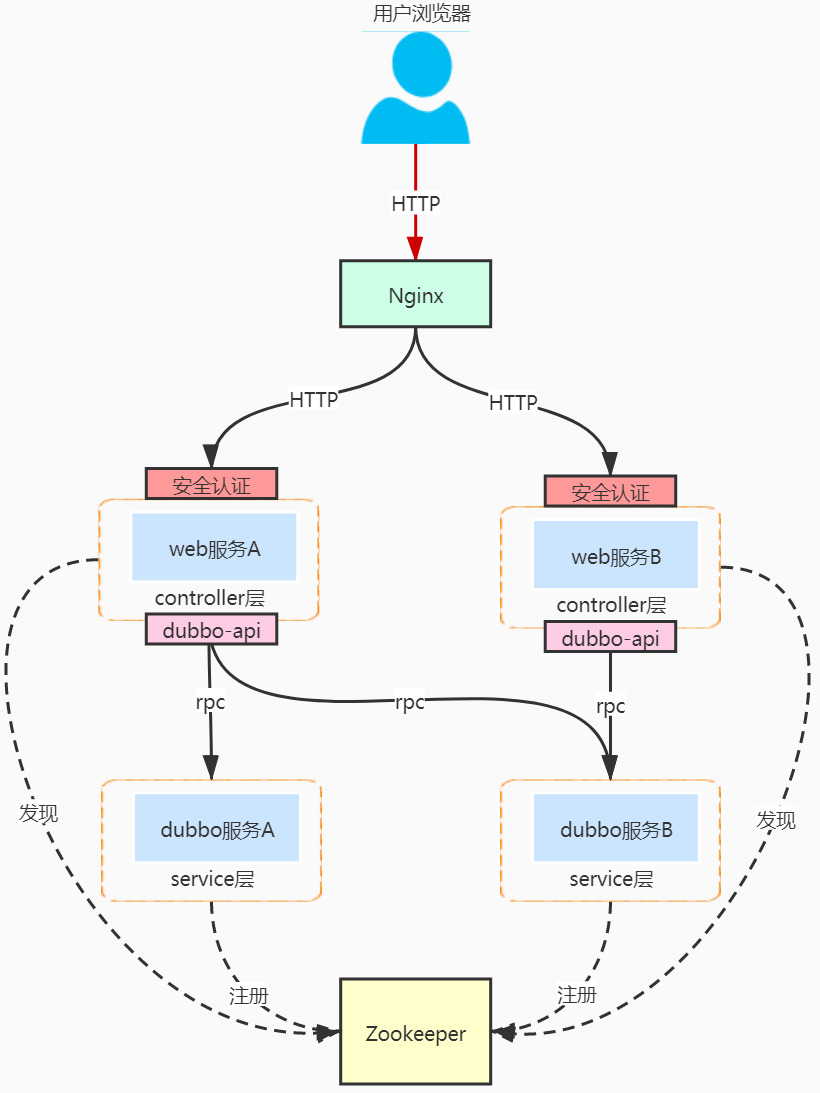
SpringCloud中的网关是作为项目的统一入口的,不可能一个服务一个入口,那么Dubbo中怎么拥有一个网关进行统一调用?
所有的服务都是基于rpc调用的,然后Cfeng意图将所有的controllerweb层整合在一起形成一个API网关,这样就可以方便使用?但是web层没有实现泛化调用 — 需要引入调用方的接口, 那么就必须引入所有的dubbo服务的依赖【Service接口】,网关不稳定 ----- 服务接口变更都需要修改网关的API依赖
原则错误 【单体地狱 】— 整合所有web层为API网关
然后Cfeng再次设想,那为了方便修改,抽象分离一个接口工程就好,所有的接口都放在其中,所有的服务以及API网关共享; 但是这里再次产生问题 ---- 这真的是微服务?解耦一点都不完善
Cfeng设想的项目划分:
- offerCampus-common-api : 接口工程,所有的接口和相关的entity共享,所有服务共享
- offerCampus-doc: 文档微服务
- offerCampus-job: job微服务
- offerCampus-secKilling: 秒杀微服务
- offerCampus-user: 用户微服务
- offerCampus-gateController: 理想化的API网关
依赖关系就是OfferCampus-gateController统一RPC调用所有的远程微服务,而所有的微服务Service统一依赖common-api接口工程
一般来说两个微服务里面不会出现相同的实体,这里Cfeng构想的微服务项目已经就不是微服务了,落入单体地狱 Monolith Hell
offerCampus被RPC调用肢解为一个支离破碎的大单体项目,比纯粹的单体还要糟糕; 微服务失去了意义
dubbo没有完善的网关,并且服务的调用基本上都是RPC方式,开发中需要严格规范服务的版本号, 规范依赖,Cfeng最终放弃
失败尝试的sum-up
- Dubbo初始定位就是服务的RPC调用,选择Dubbo架构微服务还是使用传统的Dubbo架构即可,编写相关的controller即可,不要将所有的web层合并为一个API网关
微服务解耦合彻底点好: 传统的Dubbo架构的接口工程本身就让两个服务之间产生了耦合,不管是实体的共享还是其他的class的共享都本身有悖微服务架构原则; 对于Spring Cloud架构也是一样,如果两个微服务同时依赖一个实体【虽然可以避免实体不一致导致不能解析】,但是会造成依赖的问题【一个接口需要修改,另外一个不需要】, 所以还是保持独立好,各自管理可以减少很多麻烦 【但是需要更严格的规范管理】
Dubbo架构Demo
cfeng经过思考已经放弃了Dubbo架构,但是整个RPC调用,包括服务的注册发现,相关Zookeeper注册中心等都已经完善,也就是说,Cfeng其实都已经将架构完成并且完成了简单的架构测试
下面简单给出demo的代码
首先是使用Dubbo架构的依赖
<!-- dubbo依赖 jdk1.8是不支持3.0以上的dubbo的-->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-spring-boot-starter</artifactId>
<version>${dubbo.version}</version>
</dependency>
<!-- zookeeper依赖 还有curator框架-->
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>${zookeeper.version}</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-x-discovery</artifactId>
<version>${cruator.x.version}</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>${zk.cruator.version}</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>${zk.cruator.version}</version>
</dependency>
调用的服务的接口
public interface SysUserService {
//查询用户详细信息
SysUser queryUser(Integer userId);
}
服务的提供者Provider
实现服务接口 ,使用@DubboService进行服务的暴露
@DubboService(version = "1.0.0")
public class SysUserServiceImpl implements SysUserService {
@Override
public SysUser queryUser(Integer userId) {
//验证微服务
SysUser user = new SysUser();
user.setName("cfeng");
return user;
}
}
服务提供者的yaml【大部分都自动配置了】
dubbo:
application:
name: user-provider # dubbbo服务提供者需要给出名称唯一标识
scan:
base-packages: indv.cfeng.offerCampus.user.service
protocol:
name: dubbo #RPC通信使用dubbo协议
port: 20883 # 本服务对外暴露的端口号,供消费者识别确认
## 注册中心zookeeper
registry:
address: zookeeper://localhost:2181 # zookeeper所在的服务器和端口
## 自定义配置zookeeper
zk:
host: localhost:2181
namespace: cfengHost
服务消费者
消费者直接使用@DubboReference就可以从注册中心远程调用
* 调用远程的用户微服务,这里就和传统的本地调用的方式不同,不再使用@Resource等注入,而是dubbo的@DubboReerence
*/
@RestController
@RequestMapping("/user")
public class SysUserController {
//按照版本号选择响应的实现,同时指定协议-- 服务的路径,这里是远程调用,本地确实没有
@DubboReference(version = "1.0.0", url = "dubbo://127.0.0.1:20883")
private SysUserService sysUserService;
@GetMapping("/test")
public ResponseEntity<SysUser> queryUser(Integer id) {
SysUser user = sysUserService.queryUser(id);
if(!Objects.isNull(user)) {
return ResponseEntity.ok(user);
}
return new ResponseEntity<>(HttpStatus.BAD_REQUEST);
}
}
消费者配置文件(注册中心等)
dubbo:
application:
name: gateController-consumer
scan:
base-packages: indv.cfeng.offerCampus #会从该路径扫描zookeeper管理的服务,完成一次调用,user的服务只是该路径下面的子路径
registry:
address: zookeeper://localhost:2181
这样就可以完成一次调用,RPC调用确实很方便,Cfeng后面如果后面遇到了Dubbo架构会再次分享
初始尝试Dubbo项目的相关pro
Code只是项目构建的一小部分工作,只有良好的设计之后才能快速正确Code;
JPA使用Druid连接池
Druid可以进行利用statViewServlet进行可视化监控,所以使用druid连接池而不是之前的dbcp等(直接引入相关的starter,就可以减少手动配置)
### 数据库连接配置,每一个微服务对应一个单独的数据库
spring:
datasource:
url: jdbc:mysql://localhost:3306/offershow_user?useUnicode=true&characterEncoding=utf-8&useSSL=true&servertimezone=GMT%2B8
username: cfeng
password: a1234567890b
#当执行schema和data.sql的用户不同时,可以配置相关的username和password
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
# dbcp2: #连接池的相关配置
# initial-size: 10
# min-idle: 10
# max-idle: 30
# max-wait-millis: 3000
# time-between-eviction-runs-millis: 200000
# remove-abandoned-timeout: 200000
# Druid的其他属性配置
druid:
# 初始化时建立物理连接的个数
initial-size: 5
# 连接池的最小空闲数量
min-idle: 5
# 连接池最大连接数量
max-active: 20
# 获取连接时最大等待时间,单位毫秒
max-wait: 60000
# 申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。
test-while-idle: true
# 既作为检测的间隔时间又作为testWhileIdel执行的依据
time-between-eviction-runs-millis: 60000
# 销毁线程时检测当前连接的最后活动时间和当前时间差大于该值时,关闭当前连接(配置连接在池中的最小生存时间)
min-evictable-idle-time-millis: 30000
# 用来检测数据库连接是否有效的sql 必须是一个查询语句(oracle中为 select 1 from dual)
validation-query: select 'x'
# 申请连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为true
test-on-borrow: false
# 归还连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为true
test-on-return: false
# 是否缓存preparedStatement, 也就是PSCache,PSCache对支持游标的数据库性能提升巨大,比如说oracle,在mysql下建议关闭。
pool-prepared-statements: false
# 置监控统计拦截的filters,去掉后监控界面sql无法统计,stat: 监控统计、Slf4j:日志记录、waLL: 防御sqL注入
filters: stat,wall,slf4j
# 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100
max-pool-prepared-statement-per-connection-size: -1
# 合并多个DruidDataSource的监控数据
use-global-data-source-stat: true
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
connect-properties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
#配置监控配置项
web-stat-filter:
# 是否启用
enabled: true
# 过滤规则
url-pattern: /*
# 忽略的过滤格式
exclusions: /druid/*,*.js,*.gif,*.jpg,*.png,*.css,*.ico
# 配置StatViewServlet监控信息Html页面
stat-view-servlet:
# 是否启用
enabled: true
# 设置访问路径,访问项目时就会自动跳转
url-pattern: /druid/*
# 是否能够重置数据
reset-enable: false
# 登录名称,密码
login-username: cfeng
login-password: cfeng
# IP白名单
allow: 127.0.0.1
# IP黑名单,共同存在时,deny优先
deny:
jpa: #Spring data jpa的配置,dialect是properties下面的
show-sql: on
open-in-view: on
database: mysql
hibernate:
ddl-auto: update
naming:
physical-strategy: org.springframework.boot.orm.jpa.hibernate.SpringPhysicalNamingStrategy #SpringPhysi
服务开启之后访问XXX/druid输入配置的用户名和密码即可进入数据源的控制台页面,查看执行效率等
RPC服务发布
在传统项目中,直接创建Service层之后,直接定义一个Service接口,直接在项目中创建对应的impl即可,但是在分布式项目中,服务的发布和引用都是依赖接口的; 但是服务的发布方和引用方往往不再同一个系统, 所以需要将发布引用接口放在公共类库, 也就是放在本项目的commons-api模块中,因为所有的业务都直接依赖该模块,所以双方都能够引用
配置之后,Dubbo会将这些类的接口信息+本服务器的IP+spring.dubbo.protocol.port所指定的端口号发送给Zookeeper,Zookeeper会将这些信息存储起来
Dubbo和JDK版本适配
JDK1.8适配的是2.X的,而3.x的dubbo-starter适配高版本的jdk,同时需要引入zookeeper的相关依赖,特别的是:
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-x-discovery</artifactId>
<version>${cruator.x.version}</version>
</dependency>
Failed to configure a DataSource: ‘url‘
这里是因为微服务的controller项目不需要连接数据库,但是因为桩模块中引入了数据库的连接的相关的依赖,但是yml没有配置,出现错误:
如果不需要连接数据库,在启动类处进行配置,需要将Druid的和原本的都要排除
@SpringBootApplication(exclude = {DruidDataSourceAutoConfigure.class,DataSourceAutoConfiguration.class})
本次的offerCampus项目的最开始失败的Dubbo架构分享就完了,如果对dubbo架构感兴趣欢迎交流🎄















 544
544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









