









- 零散知识点
- ACID:原子性、一致性、隔离性、持久性
- 事务的隔离级别,四种:(1)未提交读(可能出现脏读);(2)提交读(可能出现不可重复读);(3)可重复读(可能出现幻读,但mysql的innodb通过mvcc解决了这个问题);(4)可串行化读(行行加锁,太重了,一般不用)
- 索引篇
- 索引主要分为B+树索引和Hash索引。
- 索引的最左匹配原则:比如设定一个索引为(col1,col2,col3),那么必须在where子句中含有最左边的列col1的时候,索引才会起作用。其他如where col2=val and col3= val。。。。都是不使用索引的。
- 聚集索引定义:一种逻辑索引和物理索引相同的索引。一张表只能有一个聚集索引,因为物理索引只有一种。根据这个特性,适用于范围查找。主键列默认是聚集索引。
- 聚集索引的优点:(1)适合范围查找 缺点:(1)对于数据更新开销大
- 非聚集索引与聚集索引的区别:(1)叶子节点并非数据节点 (2)叶子节点为每一个真正的数据行存储一个“键-指针对 (3)叶子节点中还存储了一个指针偏移量,根据页指针及指针偏移可以定位到具体的数据行。 (4)在除叶节点外的其他索引节点,存储的是类似内容,只不过是指向下一级索引页。
- 自适应hash索引:对某些多次访问的列,自动加上hash索引方便查询。
- 聚集索引
- InnoDB的聚集索引实际上在同样的结构中保存了B-树索引和数据行
- 数据行实际保存在索引的叶子页。(B-树特性)
- “聚集”的定义:指实际的数据行和相关的键值都保存在一起
- 优点:(1)适合范围查找,比如可以按照学号聚集,查出一个学生所有的成绩。(2)数据访问快,因为是聚集的,所以索引和数据都保存到了同一颗B树上。(3)使用覆盖索引的查询可以使用包含在叶子节点中的主键值
- 缺点:(1)聚集索引适合I/O密集型,如果数据量很小,能够装入内存,那就没有太大的意义。(2)更新操作困难,插入依赖于插入顺序,最快就是按照主键插入。
- B+树索引
- 特点:B+树和B树类似,都是平衡的M叉多路访问树。但B+树在叶子节点上增加了前后指针,方便快速访问叶节点。且B+树的非叶节点是索引,叶节点才存储需要的关键字数据。
- 对于B树索引来说,索引的列顺序很重要,因为需要遵守最左匹配原则
- 优点:(1)是平衡树,从根节点到叶节点路径短,且同层级有指针方便快速移动(2)能够减少磁盘I/O次数,因为索引文件是也要占空间的,而B类树(B-/B+)有大量的非叶节点存储索引。且B+树中的非叶节点没有数据域,空间更大,存储的容量更多,即减少磁盘读写。
- 缺点:(1)对于重复性低的表查询速度没有hash快。(2)等值查询没有hash快
- Hash索引
- 优点:我们知道hash索引在查找上性能非常好,在合理的碰撞情况下可以认为是O(1);这样对于磁盘的I/O次数就相对更少,我们知道磁盘的I/O非常花时间。
- 缺点:(1)有利有弊,因为hash是通过散列值一次确定位置,所以无法使用于范围查找。(2)hash索引无法用来避免排序操作:我们知道在构建索引的时候可以顺便将索引的列进行排序,这样在后期使用的时候就不用再排序了,而hash索引做不到这点。(3)hash索引任何时候都无法避免表扫描,因为碰撞的存在。
- 特点:Hash索引不支持最左匹配原则
- 全文索引
- 出现在Myisam引擎中
- 它不是使用where子句来比较相等性,而是执行相关的关键字操作,是基于数据的关联性,而非比较。
- 在表中通过连接字符列构造索引,并把他们当成很长的字符串进行索引
- 数据结构是双重平衡B树,容易出现 碎片
- 全文索引的添加/删除/修改 都很慢
- 覆盖索引
- 定义:包含(覆盖)所有满足查询需要的数据的索引。
- 原理:索引中保存了它包含列的数据;因此hash索引、全文索引都不能满足,只有B-树索引能够支持。
- 想要创建一个覆盖索引,这个索引必须包含指定表上包括WHERE语句、ORDER BY语句、GROUP BY语句(如果有的话)以及SELECT语句中的所有列。
- 关于索引建立的方式
- 习惯性的想法是不要在选择性很差的列上建索引,比如sex,可选范围只有man/woman,因为这样会返回大量满足条件的记录。但也有特殊情况
- 针对上一条,如果这个列虽然选择性很差,但是很多查询的where子句中都会用到它,那么可以采取变通的方法:(1)将该列设为索引的最左,即引用最左前缀匹配,那么对于大多数查询来说是可以用的上索引的。 (2)其次,如果不使用这列,那么可以使用sex in('male','female')这样来过滤。它实际上不会过滤任何行,但我们依然能使用上索引。
- 将范围判据放到索引的最后,这样优化器就会尽可能多的使用索引。同时请注意不要忘记:B树索引只能优化第一个范围条件左边的列。比如 where last_name='Smith' and first_name like 'J%' and bir_day='1978-12-31',那么只能优化last_name和first_name列。
- 总结:(1)选择性低的一般不用作索引 (2)如果查询中经常用到选择性低的列,那就把它放在索引列的前面,使用In()替换 (3)对于范围判据,放在索引列的后面,因为范围后面的列不会被优化 (5)如果有多个范围,将其中可以的转换为In() (6)如果不能转换为In(),那么转换为一个等值性的判断。
- 关于索引的使用
- 如果在查询中没有隔离索引的列,MySQL通常不会使用索引。
- 隔离列:既不是表达式的一部分,也没有位于函数中。比如 select* ......where to_days(current_date)-to_days(date_col)<=10,这个就不会使用索引,因为“-”既不是函数,也没有在表达式中。如果要使用索引应该是where date_col>=date_sub(current_date,interval 10 days)
- 如果是bolb/text或者很长的varchar,必须定义前缀索引,因为不允许索引它们的全文
- 对于大的表,应当使它的前缀选择率接近它的全列选择性。
- 前缀索引不能用在order by和group by子句中
- 关于索引对排序的优化
- 我们知道,B-树索引可以帮助排序。而MySQL有两种排序方法:(1)文件排序(2)索引排序,而索引排序只有在满足条件的情况下才能使用;在其他不满足的情况下我们使用索引排序。
- 按理来说,索引排序的速度应该是比文件排序快的,但这建立在索引是可以被覆盖查询的情况下,否则就是得顺序查找,这就成了近似于随机I/O。
- 索引排序成立条件:(1)所有列排序方向一致(DESC,ASC)(2)索引中列的顺序和order by子句中的顺序一致 (3)满足最左前缀原则
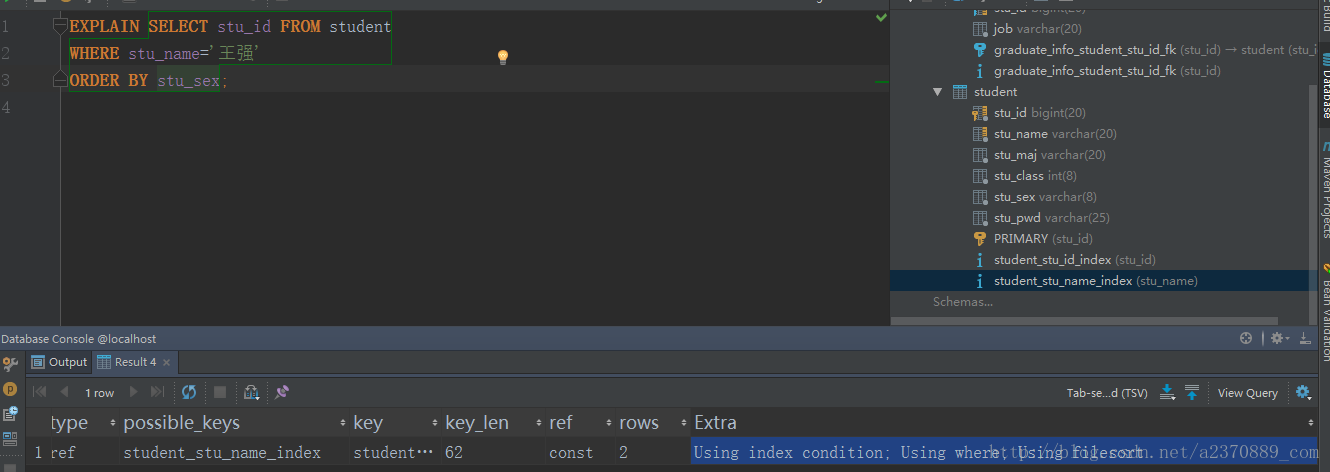
- 举个反例:这个里面我定义了两个索引,一个id,一个stu_name,然后order by子句里面是按sex的,这个时候因为order by子句中不含有索引列,所以不满足,可以看到Extra中是Using filesort(文件排序)的。
- 引擎篇
- MySQL中最常用的两种引擎分别是:MyISAM,InnoDB。MySQL5.1前的默认引擎是MyISAM。较为常用的是InnoDB
- MyISAM
- 支持全文索引
- 采用表锁
- 不支持事务,这也是为什么很多人以前会认为MySQL不是事务型数据库
- 采用压缩前缀索引,因此适用于I/O密集型。
- 不支持外键
- 使用B+树索引,但在子节点存储的不是主键,而是数据对应行的id(ROWID)
- 在没有使用任何where子句的情况下,使用Count(*)函数的性能会很好。
- 将每个表存储为两个文件:数据文件和索引文件,.MYD/.MYI,有跨平台性
- myisam表最大可用支持256TB数据处理,并有6字节的指针记录数据、
- 具有延迟更新索引,适用于数据经常改变且频繁使用的表,大大提高了表的处理性能。
- InnoDB
- 支持事务,默认的事务隔离级别是第三级(区别于其他数据库的第二级不可重复读),可重复读。理论上这一级的传播级别难以避免会出现幻读,但InnoDB通过MVCC(多版本并发控制)解决了幻读的问题。
- 采用的是行级锁,区别于MyISAM的表锁
- 也是为了解决幻读的情况,InnoDB还采取了间隙锁(next-key lock),即不但锁定当前行,也锁定前后范围的行。
- 索引有B+树索引和自适应hash索引,引擎采用聚簇索引,主键查找效率高。
- InnoDB不会压缩索引。且它的辅助索引也会包含主键列,因此尽量把主键定义的小一点。
- InnoDB的聚集索引在实际同样的结构中保存了B-树索引和数据行
- InnoDB按照主键进行聚集;如果没有主键就会在唯一的非空索引代替;否则就会定义一个隐的主键,在上面聚集。
- InnoDB的第二索引(非聚集索引)的叶子节点包含了对应行的主键值作为指向行的“指针”,而不是“行指针”。即,比如一行数据,col1是主键列,大小为18;col2是第二索引,大小为9;那么9中的叶子节点存储的不是行指针,而是指向主键列18那行的指针。这使得索引变的更大,但是也意味着innodb能够移动行而无需更新指针。
- 前面提到,聚集索引插入最优情况就是按照主键顺序来,即设置为auto_increment。如果是类似于UUID(通用唯一识别码 )这种,每次新生成的键不一定比原来的键大,则引擎不得不为它另外寻找插入位置,而这时候可能出现:(1)换页产生,目标页面被移除缓存,这时候不得不进行磁盘I/O
- varchar和char的区别
- varchar
- varchar是可变长度的字符串,即它不是固定的,它只占用了自己需要的空间,也就是较短的值占用的空间就会比较少。比如varchar(10),我插入了一个"hello"进去,那么那个字段实际的长度就是5而不是10.
- varchar在使用row_format=fixed的myisam表中是固定长度的
- varchar还会使用额外的1~2字节才存储值的长度(列的最大长度<255使用1个,否则2个)
- 缺点:varchar虽然能节省空间,但是正因为是可变的,所以在更新的时候可能会引起额外的操作。所以varchar的列最好不要频繁更新。
- 适用情况:(1)最大长度远大于平均长度,且很少发生更新的时候。(2)使用复杂可变字符集,比如utf-8的时候
- char
- char是固定长度的
- 针对上面描述varchar可变的情况,char通过在右边填充空格到字符串末尾解决的,因此是固定长度
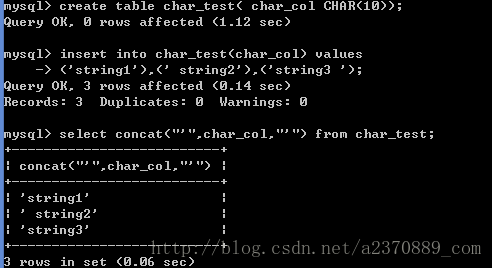
- 对于字符串后面的空格,在select查询结果的时候,右边的字符串空格不会被保存。我们可以看见string3右边的空格是没有被保存的,而string2左边的空格是被保存了的。如果是varchar的话,那么string3右边的空格也会被保存。(基于InnoDB)
- 适用:(1)很短的字符串或长度相似的字符串,比如密码的MD5散列值 (2)经常需要更新的值 (3)长度很短的列,比如一个字节的(ASCII),前面提到VARCHAR还会拿1~2字节存储长度,所以一个字节长度的char更短。
- 具体区别
- varchar是可变长度,char是固定长度,不足的用空格填充
- 对于字符串右边的空格字符,varchar保留,char不保留(针对InnoDB 5.6)
- varchar会用1~2字节存储它的实际长度(取决于最长长度大小是否大于255 store=maxLength<255?1:2),而char没有
- varchar不适合常更新的列,而char表现不错
- char还适合存储固定格式(长度相近)的字段,或者长度很短的(原因为3)
- 虽然varchar是可变的,但在设定大小的时候还是要尽量贴合实际。因为在内存中还是固定分配分区算法,(比如创建临时表)
- 日期和时间类型
- DATETIME
- 能保存大范围的值,从1001年到9999年,精度为秒,格式为YYYYMMDDHHMMSS的整数中,与时区无关,使用了8字节的存储空间
- MySQL以可排序的格式显示,符合ANSI标准
- TIMESTAMP
- 依赖于时区,MySQL服务器、操作系统和客户端连接都有设置
- 只能保存1970-2038年,
- 4字节的大小
- 二者的比较
- 通常应该使用timestamp,因为它占有的空间更小
- timestamp默认的是not null
- 两者的精度都只到秒,如果要使用毫秒级的,可以使用bigint/double型的保存秒的分数部分。
- 查询优化
- 向服务器请求了不必要的数据
- 尽量不要使用select * ,一是容易带上不必要的列,二是如果对表列进行增删操作可能会返回意想不到的结果。
- 在多表连接的时候,注意提取的列。
- MySQL检查了太多的数据吗?
- 检验开销的指标主要有三个:执行时间、检查的行数、返回的行数
- 执行时间:可以通过慢速查询日志检查。
- 尽量使检查行和返回行的比例小一些。
- 使用合理的索引
- 重构查询的方式
- 考虑将一个大的复杂的查询分解成多个简单的查询,因为现代网络已经很快了,而且MySQL能高效的连接/断开服务器
- 分治法:让查询在本质上不改变,但每次只执行一小部分,以减少受影响的行数。 例子:清理陈旧数据,这需要大量的查询,会长时间的锁住多行数据,塞满日志;而采取细化语句,可以改进性能,并在复制时减少延迟。(采用Limit限制一次删除的数量)
- 分解联接:将一个多表联接分解成多个单个查询,然后在服务器端实现联接操作 适用情形:(1)可以缓存早期查询的数据 (2)使用了多个myisam表 (3)数据分布在不同的服务器上 (4)对大表使用了In替代联接 (5)一个联接引用了一张表多次
MySQL架构
1.1.1 连接管理与安全性
- 每个客户连接在服务器的进程中都拥有自己的线程(线程独立),客户端连接到MySQL可以基于SSL方式
1.2.2锁粒度
- 在给定的资源上,被加锁的数据量越小,并发性越好。
- 但加锁也会消耗资源
- 所谓锁策略,就是在锁开销和数据安全间寻求平衡
- 表级锁:开销最小;写锁互斥,读/读可并发;写锁的优先级高于读锁,写锁在读锁前,读锁不能在写锁前。
- 行级锁:并发性最好,开销最大
1.3.4 mysql中的事务
- MySQL默认操作模式是autocommit,即如果不是显式的开启一个事务,否则它将会把每一个查询视为一个单独的事务自动执行
- InnoDB的事务在任何时候都可以获得锁,但只有在提交/回滚时才能释放锁(所有),这是一种隐式锁定
- 除非是在一个事务中,且autocommit被禁止,否则不要使用lock tables命令。
1.4 MVCC(多版本并发控制)
- 产生原因:解决事务隔离级别为可重复读情况下产生的“幻读”情况
- 实现技术:通过及时保存某些时刻的数据快照而得以实现的。这意味着同一事务的多个实例,在同时运行的时候,它们看到的数据视图是一致的。
- 具体方法:InnoDB为每个行增加两个隐含值来实现,记录了行的创建时间以及它的过期时间(或删除事件)。每一行都存储了事件发生时的系统版本号。每一次开始一个新事务的时候,版本号都会递增。每个事物都会保存它在开始时的“当前版本号”
- 对操作的要求:(1)只查询<=当前版本号的数据并返回 (2)数据行的删除版本必须是未定义或大于当前版本的,用于确保事务开始时数据行是未删除的。
- 好处:(1)避免幻读 (2)避免了很多情况下的加锁操作,降低了系统开销 (3)允许非锁定行的数据读取
- 工作范围:只工作在第二级和第三级,即提交读和可重复读















 6975
6975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









