







一. 概述
1.1 对话系统
对话系统(Dialogue System),是一种模拟人类并旨在与人类形成连贯通顺对话的计算机系统。它能够理解用户输入的文本或语音,然后根据用户的需求做出相应的回应。对话系统一般包括任务型对话、生成式对话和检索式对话等场景。它是人工智能领域的重要应用之一,能够被广泛应用在客服机器人、语音助手、智能家居等领域。
1.2 任务型对话
任务型对话系统,旨在通过对话交互的形式,有效率地帮助用户完成一些特定的任务,其多用于垂直领域业务,譬如预约餐馆、查询天气、预订机票、推荐音乐。常见的相关产品主要包括微软小冰、百度小度、阿里小蜜、小米的小爱等。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
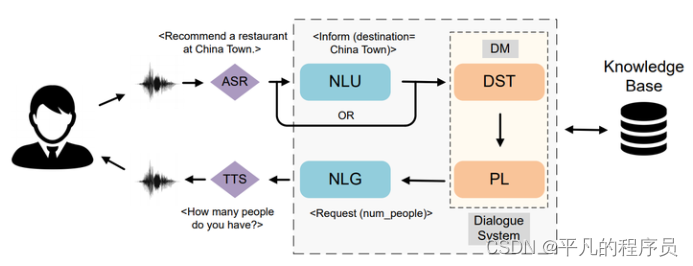
一般完整的任务型系统包括自然语言理解(NLU)、对话管理(DM)、自然语言生成(NLG)几个模块,其中对话管理又包含对话状态追踪(DST)、对话策略(DP)两个模块。语言理解接受用户语句并实现两个功能,一是意图识别,二是语义槽填充;对话管理记录当前的对话状态并决定下一步采取什么策略;语言生成则生成最后的文本回复给用户。对话管理和语言生成的过程当中会遇到知识库和APIs。APIs在实际的应用过程中,可能会调一些查天气和地理位置的APIs,这些都可以被包含在任务型对话资源里面。
1.3 生成式对话
生成式对话模型是指使用机器学习或深度学习等技术,根据给定的对话历史和上下文信息,生成连贯的自然语言回复。一般可以理解为seq2seq的任务类型,类似于机器翻译,都是输入一个query,然后输出另一个query。如参考以下示例:
source: 你喜欢杭州吗?
target: Do you linke HangZhou?
生成式对话的一般是一对多的场景,即输入一个query,系统的回复可能会有多个不同的回复。如:
query: 你喜欢杭州吗?
answer1: 是的,我喜欢杭州这个城市。
answer2: 当然,这里的气候太好了。
answer3: 我不知道,这里工作很合适,但是好吃的东西太少了。
answer4: 房价太高了,我不喜欢。
1.4 面临的挑战
基于海量语料预训练出的大模型,已经可以产生比较连贯的回复,但仍然存在很多问题。
第一个是回复的内容可能比较简略空洞、缺乏实质性的内容信息,容易降低用户的聊天意愿。如:
User: 你喜欢打篮球吗?
Robot: 没有呀。
User: 你回复好简洁呀。
Robot: 没有吧。
User: 我们聊点啥呢?
Robot: 不知道呢。
另一个问题是模型幻觉,大模型回复的一些详细信息有时候是错误的、编造的,如:
User: 武汉到杭州有多远?
Robot: 大概8km左右。
User: 杭州有什么好吃的?
Robot: 热干面。
注: 武汉到杭州的距离约720km,热干面是武汉地区的特色美食,不是杭州的。
二. 相关技术
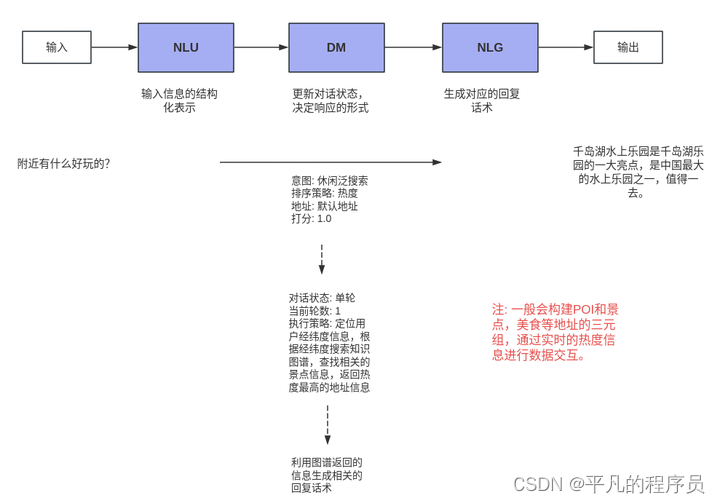
2.1 任务型对话pipeline
ASR和TTS主要负责语音和文本之间信号的转换,这里仅分析NLP内部的业务模块。
2.2 自然语言理解
自然语言处理(Natural Language Understanding, NLU), 主要负责对用户输入的自然语言进行理解,一般标识为意图和槽位信息的格式。在实践中一般会标注为(domain, intent, slot)形式的结构化数据,便于下游模块更好地生成对应的action。
如: query = 播放周杰伦的歌曲
domain=music
intent = 播放指定音乐
slots = {“action”: “music_play”, “singer”: “周杰伦”}
实现上述功能一般有以下几种方式:
基于规则引擎的方法:
如: 通过批量配置匹配模板,设置对应的意图和槽位信息,可以快速实现意图识别和槽位抽取的功能。

基于分类+实体识别的方法:
示例: query = 播放周杰伦的歌曲
domain=music
intent = 播放指定音乐
slots = {“action”: “music_play”, “singer”: “周杰伦”, “agent”: “classify_ner”}
score = 1.0

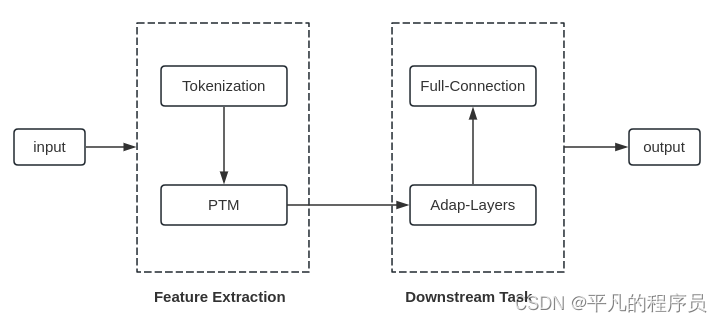
常用的网络结构:
意图识别:
实体识别:
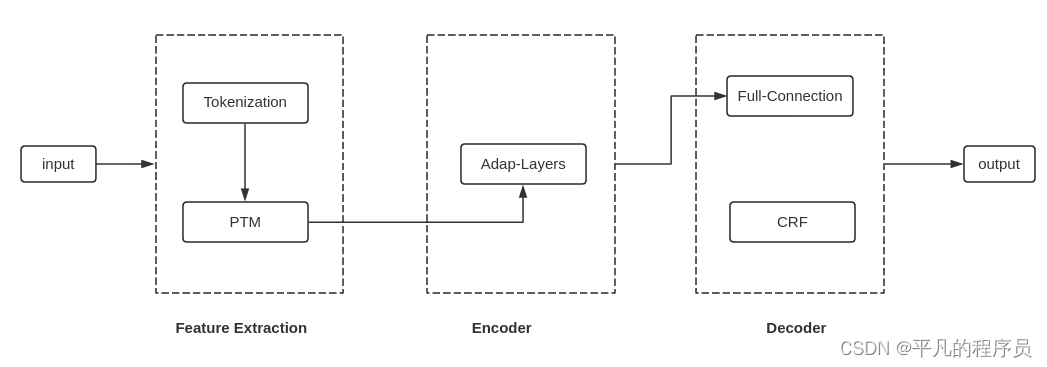
目前业界用的较多的PTM一般包括: BERT, AL-BERT, Adapt-BERT, ERNIE, RoBERTa。Adap-Layers一般是根据具体的业务,新增的网络适配层,可以自行配置LSTM, CNN等网络结构。针对于中文的任务场景,特别是NER任务,公认的还是ERNIE和RoBERTa效果要好。但针对于服务性能要求高的业务场景,线上服务用的更多的是AL-BERT系列的PTM模型。
基于向量召回的方法:
示例: query = 看一下股市行情怎么样
domain=stock
intent=股市行情泛查询
slots = {“action”: “stock_general_search”, “entity_type”:“股票”, “agent”: “senmantic_vector”}
score = 1.0
候选匹配意图集(标准句):
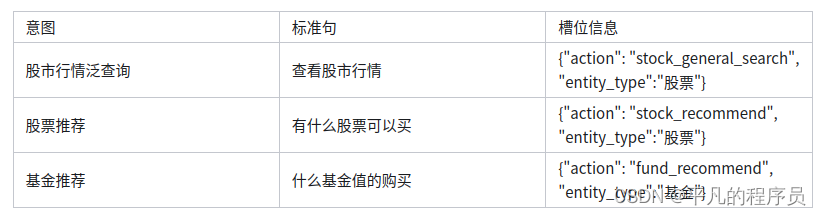
一般针对于query相关的固定,对应answer内容不确定,适合这类模型。
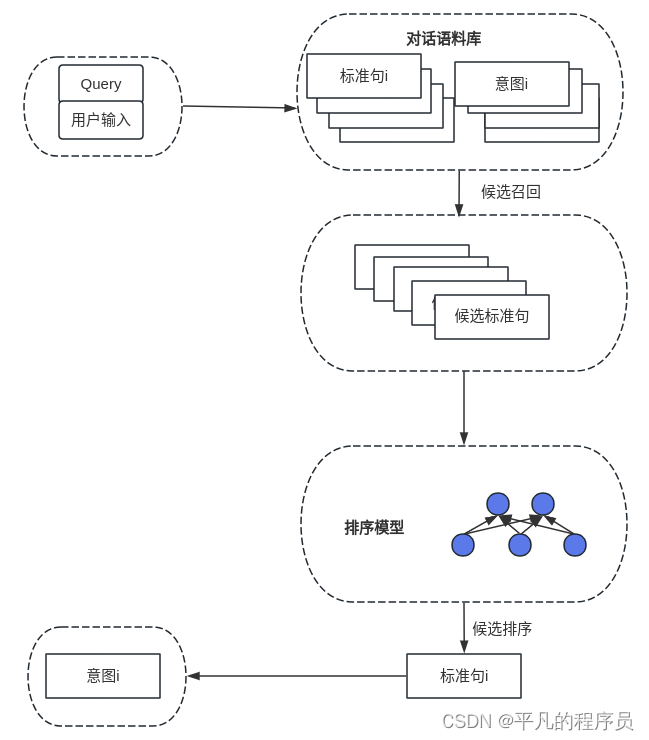
参考的网络: BERT Whitening,Sentence BERT,BERT Flow,SimBERT,SimCSE,Trans Encoder,ProCSE
基于阅读理解的方法:
示例: query = 播放手牵着手一步两步三步四步望着天
domain = music
intent = 播放指定音乐
slots = {“action”: “music_play”, “singer”: “周杰伦”, “song”: “星晴”}
score = 1.0
MRC建模方法: doc = 歌词,query=用户输入,返回是否匹配到doc中的某一段文本。利用知识库建立metaId到歌词的映射,即可实现该功能,代表的网络结构有CoQA和QuAC等。
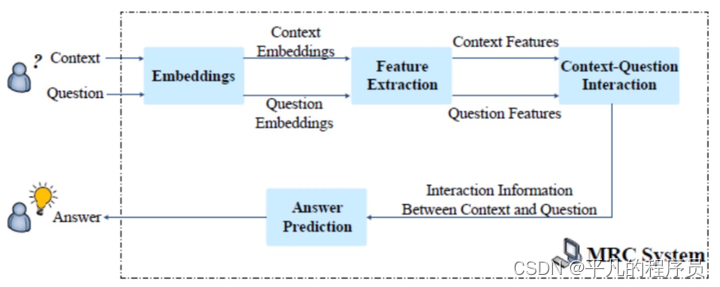
2.3 自然语言生成
自然语言生成(Natural Language Generation, NLG)是本文型对话系统中的最后一部,一般会有下列几种情况:
任务型对话:
这里NLG任务一般是通过NLU识别结果和DM的推理策略结果,来生成指定的回复内容。如澄清用户需求、引导用户、询问用户需求、对话结束语等等。一般可以通过配置化的NLG管理平台实现该功能,其特点是系统便于维护,对线上服务比较友好,而且回复的内容质量相对较高。
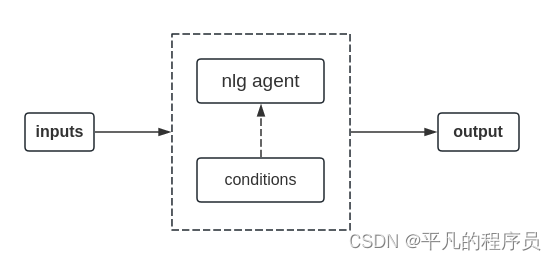
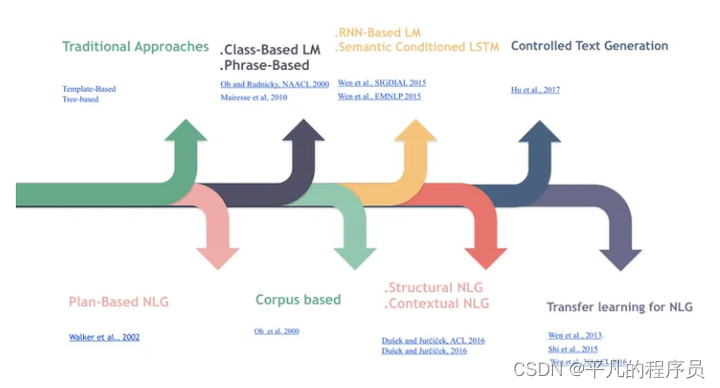
这里常用的NLG Agent的方法有基于传统的NLG方法和深度学习的NLG方法,分别可以描述为:
Rule-Based NLG:
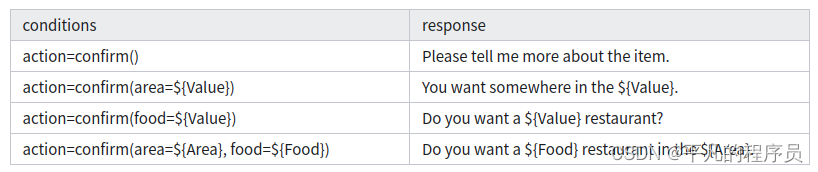
Plan-Based NLG:
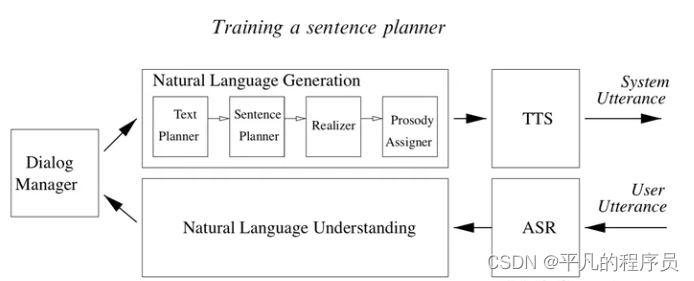
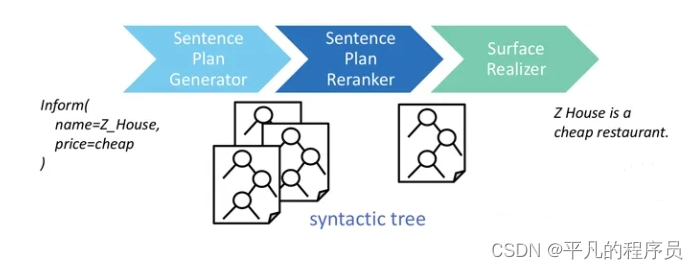
Phrase-Based NLG:
使用了语言模型,相对高效,准确率高,缺点是需要很多semantic alignment和stack。
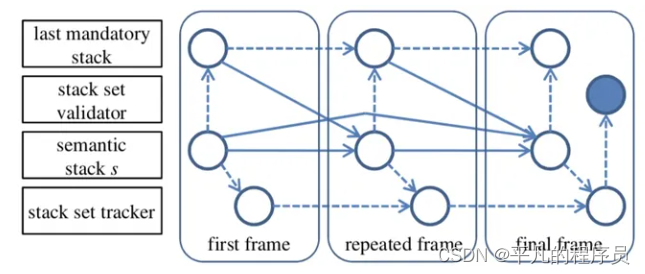
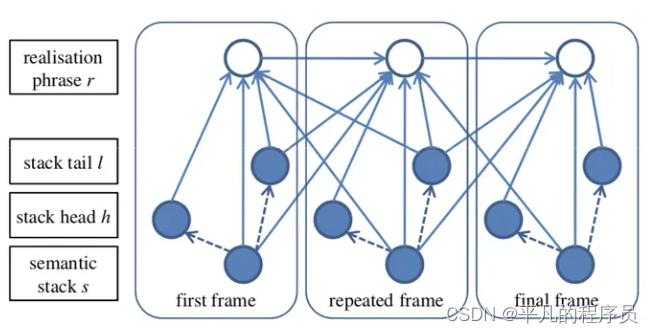
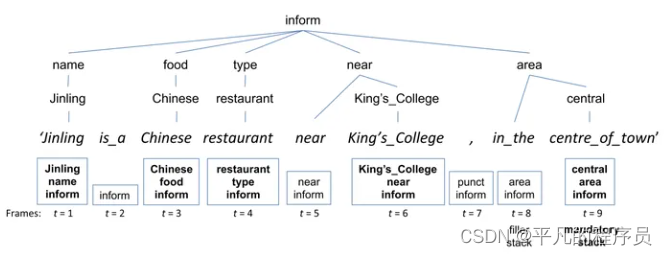
Corpus Based NLG:
句子生成的过程为: unordered mandatory Stack set-> ordered mandatory Stack sets -> full stack sequence -> sentences。这种方法的优点是极大的减少了人的工作以及可能带来的错误,缺点是需要预先定义一些特征集合。
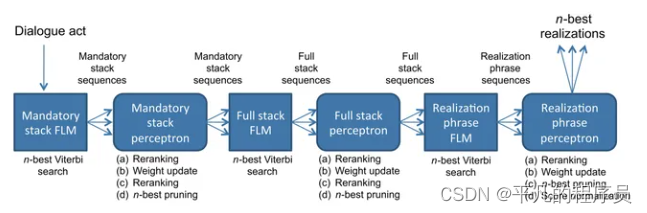
生成式对话:
RNN-Based LM:
这种方法结合了神经网络和语言模型,减少了很多人工,也可以对任意长的句子句子建模。
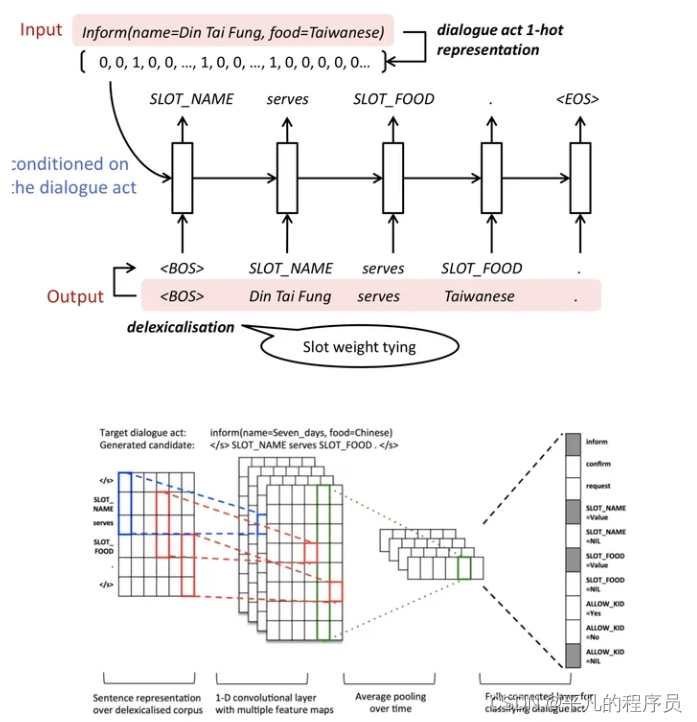
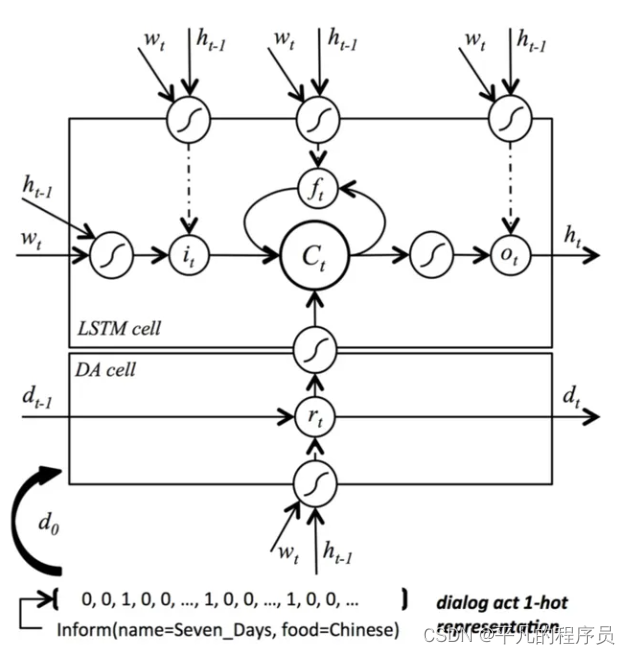
Semantic Conditioned LSTM:
在使用lstm时加入了semantic,整个网络包括原始的标准lstm和dialogue act cell。
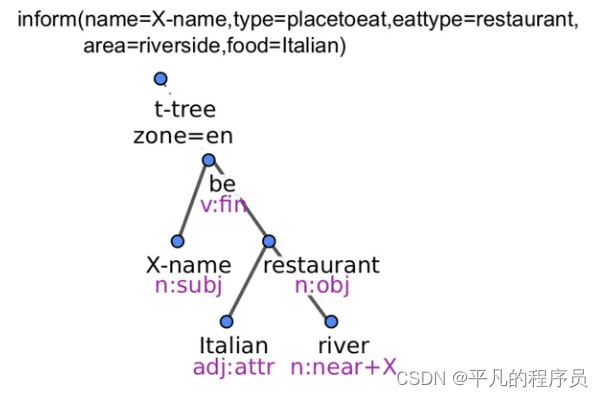
Structural NLG:
这个就是传说中的句法树+神经网络,encode trees as sequences, 然后seq2seq做句子生成。
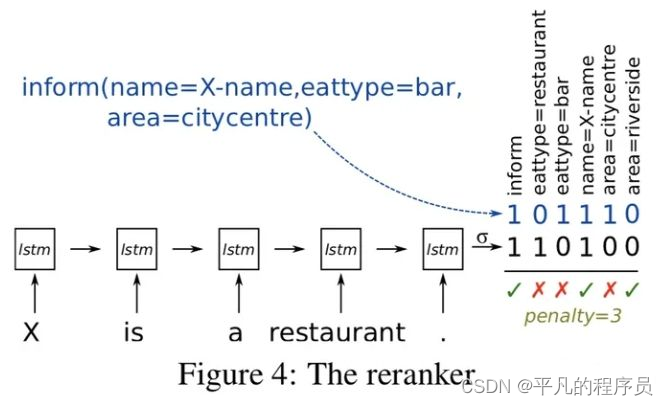
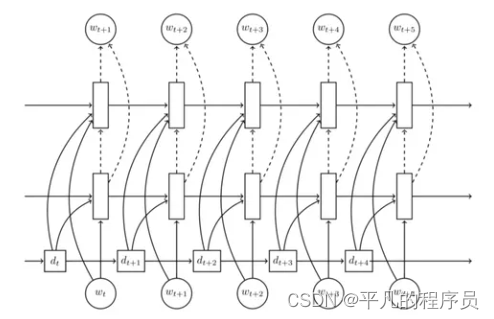
Contextual NLG:
也属于seq2seq模型,好处是生成的回复会考虑上下文,比较适合多轮对话场景。

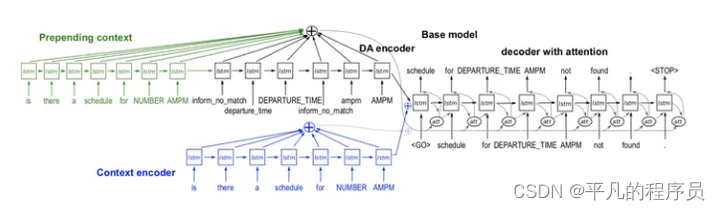
Controlled Text Generation:
基于GAN的NLG,seq2seq系列模型。
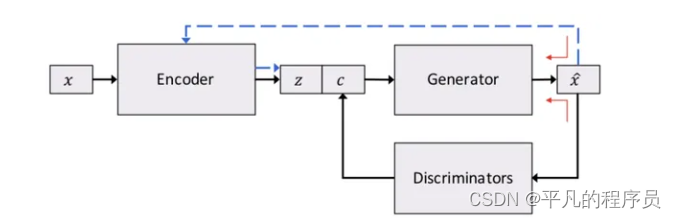
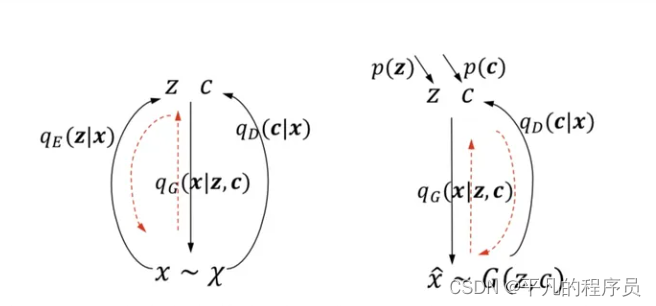

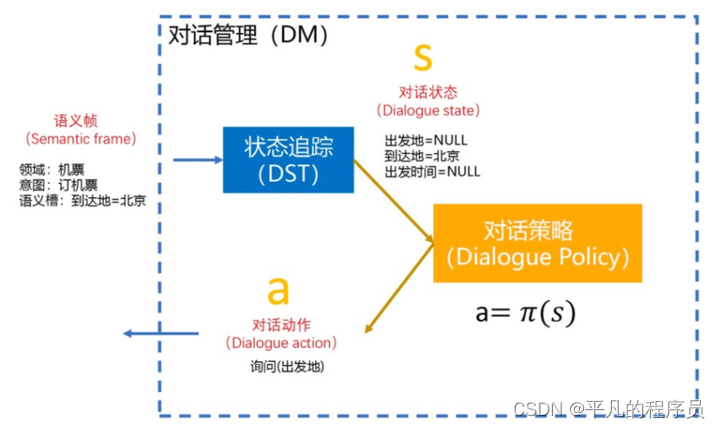
2.4 对话管理
对话管理一般包含2个子任务:
对话状态追踪(Dialog State Tracking, DST): 根据用户输入和历史对话信息识别对话状态。
对话策略学习(Dialog Policy Learning, DPL): 根据识别到的对话状态选择合适的下一步策略(action/policy)。
DST: 一般是根据用户当前的输入信息和上一轮的状态信息,更新对话流中的状态信息。在多轮场景下就是确认某些槽位值和下一步的策略,通常也有多种技术方案实现相关的功能。
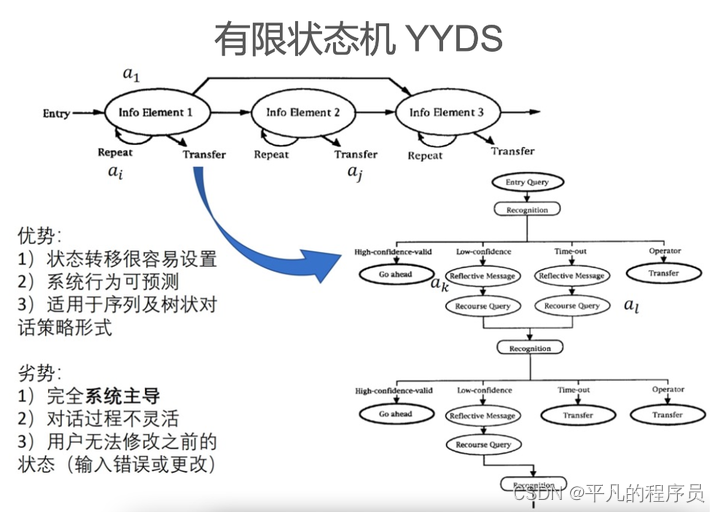
基于规则的DST:
常见的方法是利用有限状态自动机(Finite State Machine)进行对话管理。

基于统计的DST:
将每个槽位的填充任务归纳为概率图模型。
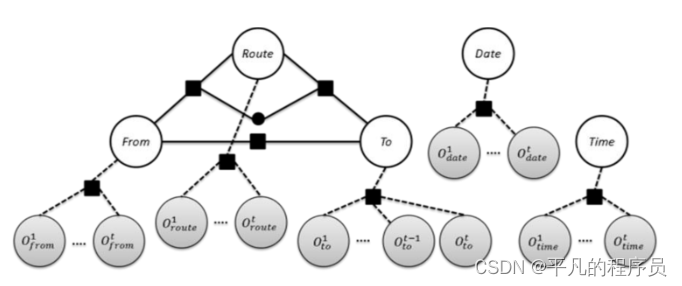
基于神经网络的DST:
将对话状态追踪任务归结为一系列的二分类任务。对话状态追踪首先需要知道ontology,它有哪些槽位值,以及每个槽位对应可能取的槽值。即模型构建了一个匹配模型(二分类模型),接受两部分的输入,第一部分是对话历史,第二部分是各个槽位和候选的取值。做槽对所有可能的槽值二分类,然后取输出值最高的。
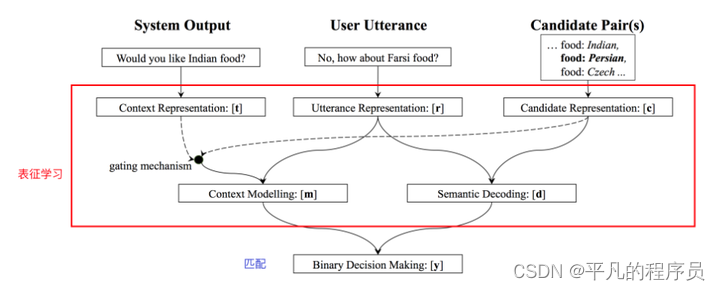
该方法借助分布式语义表示学习,无需人工构造的词典,使得语义表示更加精确,匹配效果更好。但是缺点也比较明显,需要事先定义好所有的可能的取值,不好扩展;采用句子级的k-v对形式的对话状态表示,没考虑对话历史置信度信息。论文Fully Statistical Neural Belief Tracking提出了更好的NBT。
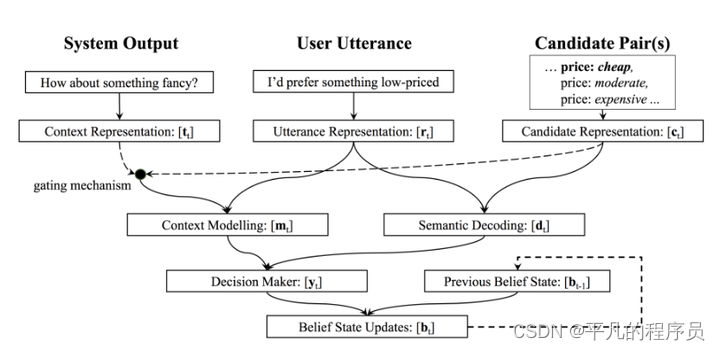
Large-Scale Multi-Domain Belief Tracking with Knoeledge Sharing 提出了不同领域的不同槽位值信息可以共享的概念。将二元组的二分类转为三元组二分类来计算领域无关的slot-value联合概率。
论文 Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems 使用了拷贝机制来从用户说的话中复制值到槽位值中。把DST看成是seq2seq任务,根据当前的对话历史和指定的slot,试图用一个Decoder来生成slot对应的value。 在生成的过程中,显示地加上拷贝机制。
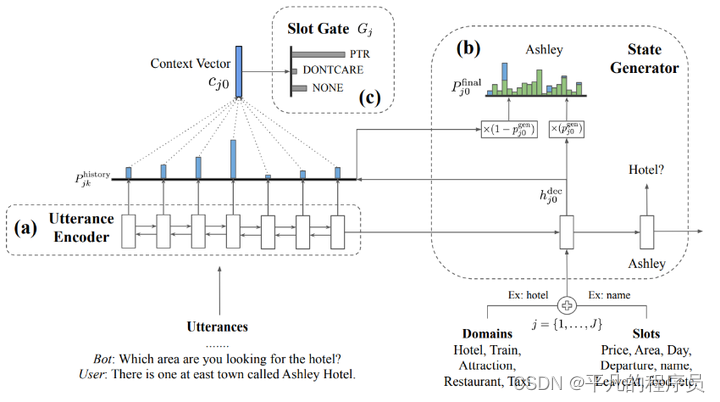
对话策略学习:
对话策略所做的事情就是根据当前的对话状态,得到一个相应的对话动作。
如: 假设现在已知到达地,但不知道出发地,那么对话策略可能生成的对话动作就是去询问出发地。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
三. 大模型建模方法
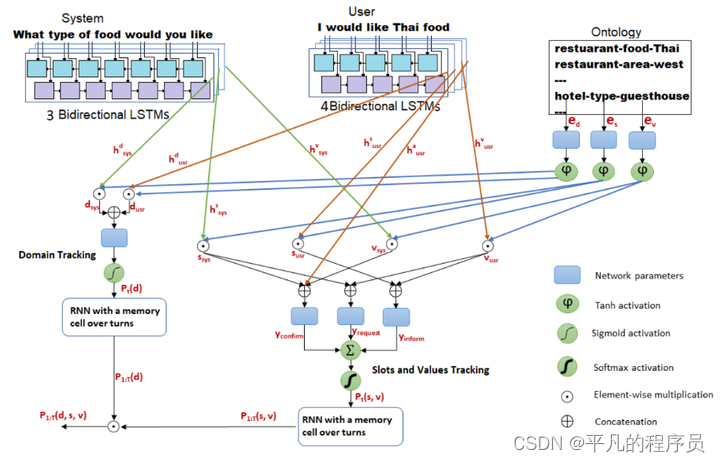
对比于传统的端到端实现的对话系统(如下图)而言,利用大模型构建任务型对话系统有以下特点。
- 避免了大量的有监督数据的标注问题。
- 多轮对话可以在闲聊和任务型对话之间无缝转换。
- 利用 Agent 来执行对话任务,原先的任务型对话系统的中间层有望得以统一。

一种做法是利用大模型去改造传统链路中的每个模块,比如用大模型去提升领域分类、意图识别、槽位抽取和对话管理等任务等。如论文: Are Large Language Models All You Need for Task-Oriented Dialogue?
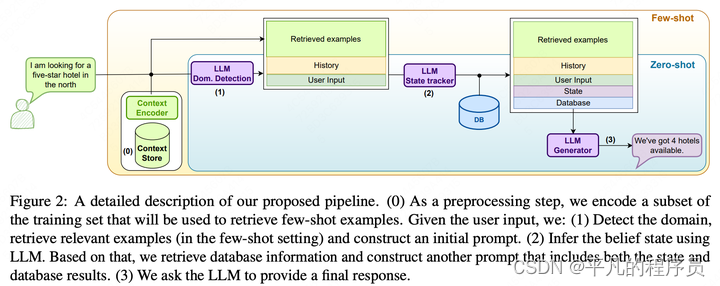
作者利用大模型的生成式模式和few-shot模式,去替换了TOD中的各个业务子模块。相关的流程如下:
- 找到一批训练数据,这些数据是用于进行few-shot的样本,并不用来微调模型。
- 进行意图/领域识别,检索一些相关的例子,然后构造原始的prompt。
- 用大模型推理出对话状态,并检索出数据库信息,构造一个含有对话状态和数据库信息的prompt。
- 利用大模型再做出最终的回复话术。
作者做了一些实验得到的结论是:
- 对话状态跟踪用大模型来解决的表现一般,需要精调prompt。
- 有监督模型仍然具有较大优势,如果能用到更大模型进行监督决策,该效果的上限会有明显提升。
- 如果给定足够的对话状态信息,大模型的生成却具有更好的效果。
四. 相关分析
4.1 对话增益
单从LLM-based Agents层面上看,大模型在这个领域的未来还是可期的,在TOD业务背景下,能带来一定的收益。对比于传统的pipeline而言,LLM-based Agents建模方法,大幅降低了TOD业务对有监督数据的依赖性。即通过NLU->DM-NLG融合规则策略虽然跑通整个对话流程,但是fallback的场景相对还是较多。
大模型的出现,能大幅提升对话系统的场景泛化能力,具备较强的迁移能力。至少在领域分类、意图识别、槽位抽取等几个核心流程上,LLM能重构整个业务流程,并取的相对较好的交互体验。
4.2 优势体现
LLM-based Agents建模方法,主要有以下几个优点:
- 便于业务的冷启动,能大幅降低有监督数据标注的人工成本和时间成本,降低业务初期落地的开发工作量。
- 降低了对话系统整体业务建模的门槛,对于简单的对话业务场景而言,在未来可能一个完全不懂对话系统的开发人员,即可实现整体业务的开发工作。
- 模型的泛化能力较好,相对基于规则模板的形式而言,维护成本会相对较低。
- 能大幅降低对数据库等资源的依赖,如音乐资源和知识图谱等等。
4.3 业务风险
- 回复内容的不确定性: LLM在融合外部知识进行辅助生成时,只存在上下文对话信息,无法知道某条语料与外部知识的对应关系,缺少知识选择的标签信息,可能会生成不匹配的回复内容。
- 推理性能的瓶颈: 对于复杂的对话系统而言,一般会存在多次的LLM推理调用,对话的实时性可能得不到保障。
4.4 应用的挑战
大模型在TOD任务上主要面临的还是对话安全性的问题。其一是大模型生成的内容相对不可控,可能会输出包含有害言论、群体歧视、政治敏感和个人隐私问题的内容等。其二是不同的用户群体,在不同的业务场景下关注的安全性可能会存在差异,不便于大模型的统一处理。
针对此问题,后续可能在以下几个方向上进行探索优化:
- 加入安全审核机制,负责对用户输入信息和大模型回复结果进行审核,保证输入输出的安全性。
- 融合多种对话技术方案,如检索式问答,用于处理用户敏感话提,返回指定的回复内容。
- 对抗攻击训练,提升大模型对结果生成的安全性。
- 数据深度清洗,提升训练集数据质量,删除不安全的样本信息。
五. 展望
大模型问世以来,生成式对话不在局限于闲聊等兜底功能。目前的大模型已经具备生成连贯流场的对话内容。但在情感化、人设角色订制化、人格等方面还存在一定的提升空间。
读者福利:倘若大家对大模型抱有兴趣,那么这套大模型学习资料肯定会对你大有助益。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

学习路上没有捷径,只有坚持。但通过学习大模型,你可以不断提升自己的技术能力,开拓视野,甚至可能发现一些自己真正热爱的事业。
最后,送给你一句话,希望能激励你在学习大模型的道路上不断前行:
If not now, when? If not me, who?
如果不是为了自己奋斗,又是为谁;如果不是现在奋斗,什么时候开始呢?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









