







 Kafka通过多分区和消费者组实现并行消费提升效率,底层的segment存储结合二分查找优化offset定位,加上零拷贝技术降低数据传输的CPU开销,从而达到高速消息消费。
Kafka通过多分区和消费者组实现并行消费提升效率,底层的segment存储结合二分查找优化offset定位,加上零拷贝技术降低数据传输的CPU开销,从而达到高速消息消费。
1. 使用多分区机制, 构建消费者组, 多个消费者同时消费, 速度提高数倍
2. 底层使用 log 形式 即 segment 储存, 使用二分查找快速定位 offset. 一个分区被分成多个 segment , segment 文件由两部分组成,分别为 “.index” 文件和 “.log” 文件,分别表示为segment索引文件和数据文件(引入索引文件的目的就是便于利用二分查找快速定位 message 位置)
3. 零拷贝技术加持, 直接在操作系统层面读写对接, 加速访问
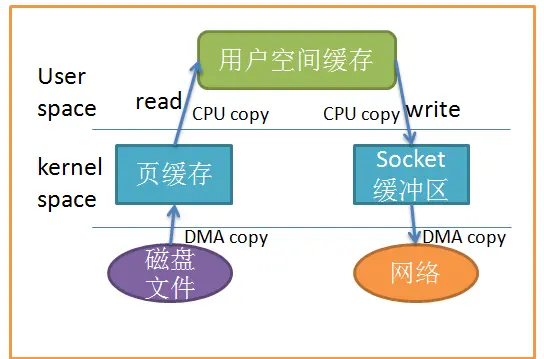
基本操作就是循环的从磁盘读入文件内容到缓
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2566
2566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









