






>- **🍨 本文为[🔗365天深度学习训练营(https://mp.weixin.qq.com/s/0dvHCaOoFnW8SCp3JpzKxg) 中的学习记录博客**
>- **🍖 原作者:[K同学啊](https://mtyjkh.blog.csdn.net/)**
今天我们就依据yolov5的yaml文件来解析common.py。
首先看看需要导入那些包和基本配置:
import ast
import contextlib
import json
import math
import platform
import warnings
import zipfile
from collections import OrderedDict, namedtuple
from copy import copy
from pathlib import Path
from urllib.parse import urlparse
import cv2
import numpy as np
import pandas as pd
import requests
import torch
import torch.nn as nn
from PIL import Image
from torch.cuda import amp从yaml文件我们可以找到经常出现的模块:Conv,C3,SPP,Concat。接下来对这些比较重要的模块进行介绍。
模块介绍
1.1 autopad
def autopad(k, p=None, d=1):
"""
用于Conv函数和Classify函数中
根据扩张系数d对卷积核的大小进行调整,再根据卷积核大小k自动计算卷积核padding数(0填充)
:params k: 卷积核的大小
:return p: 自动计算的需要pad值(默认为0填充)
:params d: 卷积核的扩张系数
"""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p这个模块可以根据输入的卷积核大小来计算pad值,主要再Conv和Classify模块中会使用到。
1.2 Conv
卷积模块,它由一个卷积层,Bn层和激活函数构成。
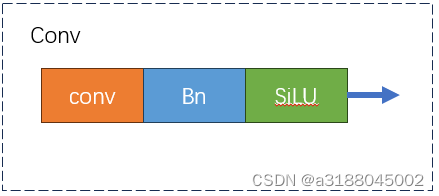
代码如下:
class Conv(nn.Module):
"""
:params c1: 输入的channel值
:params c2: 输出的channel值
:params k: 卷积的kernel_size
:params s: 卷积的stride
:params p: 卷积的padding一般是None 可以通过autopad自行计算需要pad的padding数
:params g: 卷积的groups数=1就是普通的卷积 ,>1就是深度可分离卷积
:params act: 激活函数类型True就是SiLU()/Swish,False就是不使用激活函数
类型是nn.Module就使用传进来的激活函数类型
"""
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""融合conv和Bn模块,用来加速推理,一般用在测试或推理阶段"""
return self.act(self.conv(x))1.3 Focus
这个模块是用来提高运行速度和感受野,它先将图片进行切片最后进行通道上的拼接,现在对图像做一次卷积就相当于对未切片的图像做了4次卷积,大大地节约了运算量。
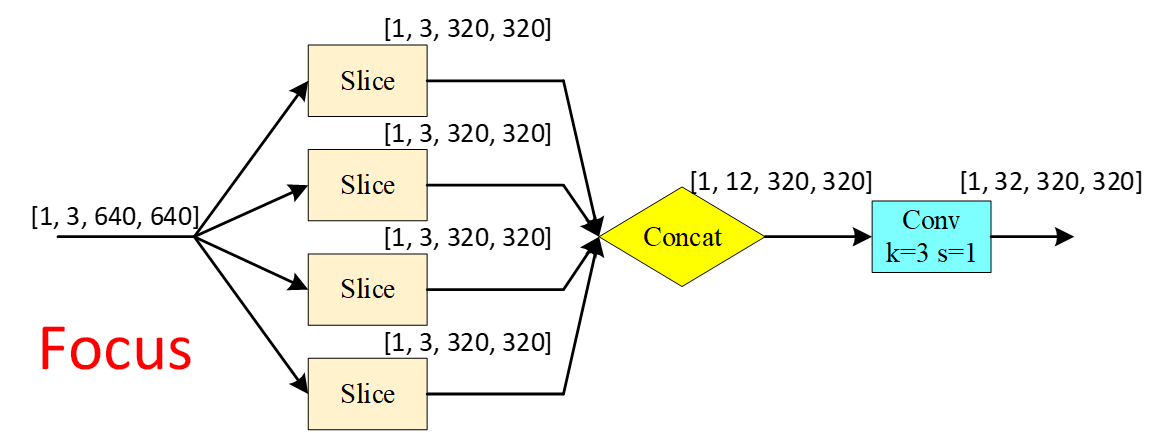
代码如下:
class Focus(nn.Module):
"""在yolo.py的parse_model函数中被调用
理论:从高分辨率图像中,周期性的抽出像素点重构到低分辨率图像中,即将图像相邻的四个位置进 行堆叠,聚焦w,h维度信息到c通道空,提高每个点感受野,并减少原始信息的丢失,该模块的设计主要是减少计算量加快速度。
Focus wh information into c-space 把宽度w和高度h的信息整合到c空间中
先做4个slice 再concat 最后再做Conv
slice后 (b,c1,w,h) -> 分成4个slice 每个slice(b,c1,w/2,h/2)
concat(dim=1)后 4个slice(b,c1,w/2,h/2)) -> (b,4c1,w/2,h/2)
conv后 (b,4c1,w/2,h/2) -> (b,c2,w/2,h/2)
:params c1: slice后的channel
:params c2: Focus最终输出的channel
:params k: 最后卷积的kernel
:params s: 最后卷积的stride
:params p: 最后卷积的padding
:params g: 最后卷积的分组情况 =1普通卷积 >1深度可分离卷积
:params act: bool激活函数类型 默认True:SiLU()/Swish False:不用激活函数
""" def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
"""Initializes Focus module to concentrate width-height info into channel space with configurable convolution
parameters.
"""
super().__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act=act)
def forward(self, x):
return self.conv(torch.cat((x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]), 1))
# return self.conv(self.contract(x))1.4 Bottleneck和C3
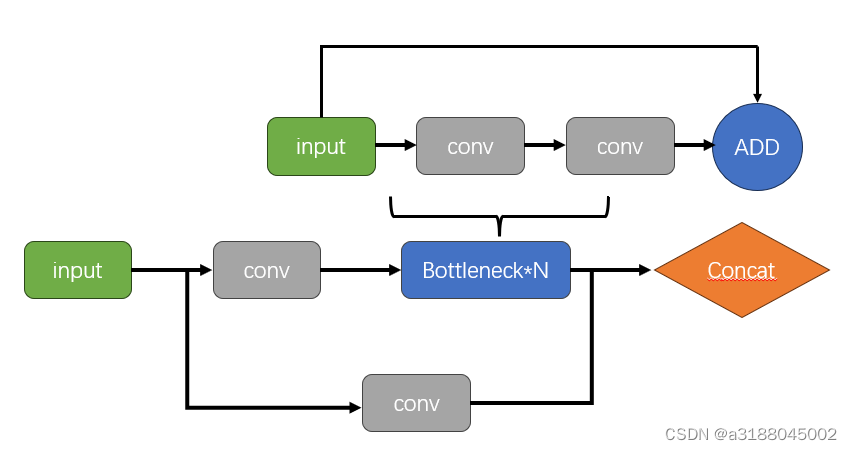
这里将C3和Bottleneck放在一起讲,这个模块的作用是提高网络的感知能力和表示能力。C3模块通过跳跃连接的方式,将不同层次的特征图进行整合,提高模型的感知能力。Bottleneck则可以加速这个过程,通过1x1 和 3x3 的卷积核,以及深度可分离卷积等,以实现更高效的计算。
class Bottleneck(nn.Module):
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5):
"""
c1和c2为输入和输出通道,shortcut为残差连接
"""
super(Bottleneck, self).__init__()
c_ = int(e*c2)
self.conv1 = nn.Conv2d(c1, c_, 1, 1)
self.conv2 = nn.Conv2d(c_, c2, 3, 1, groups=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.conv2(self.conv1(x)) if self.add else self.conv2(self.conv1(x))
class C3(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super(C3, self).__init__()
c_ = int(e * c2)
self.conv1 = nn.Conv2d(c1, c_, 1, 1)
self.conv2 = nn.Conv2d(c1, c_, 1, 1)
self.conv3 = nn.Conv2d(2*c_, c2, 1)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1) for _ in range(n)))
def forward(self, x):
return self.conv3(torch.cat((self.m(self.conv1(x)), self.conv2(x)), 1))1.5 SPP
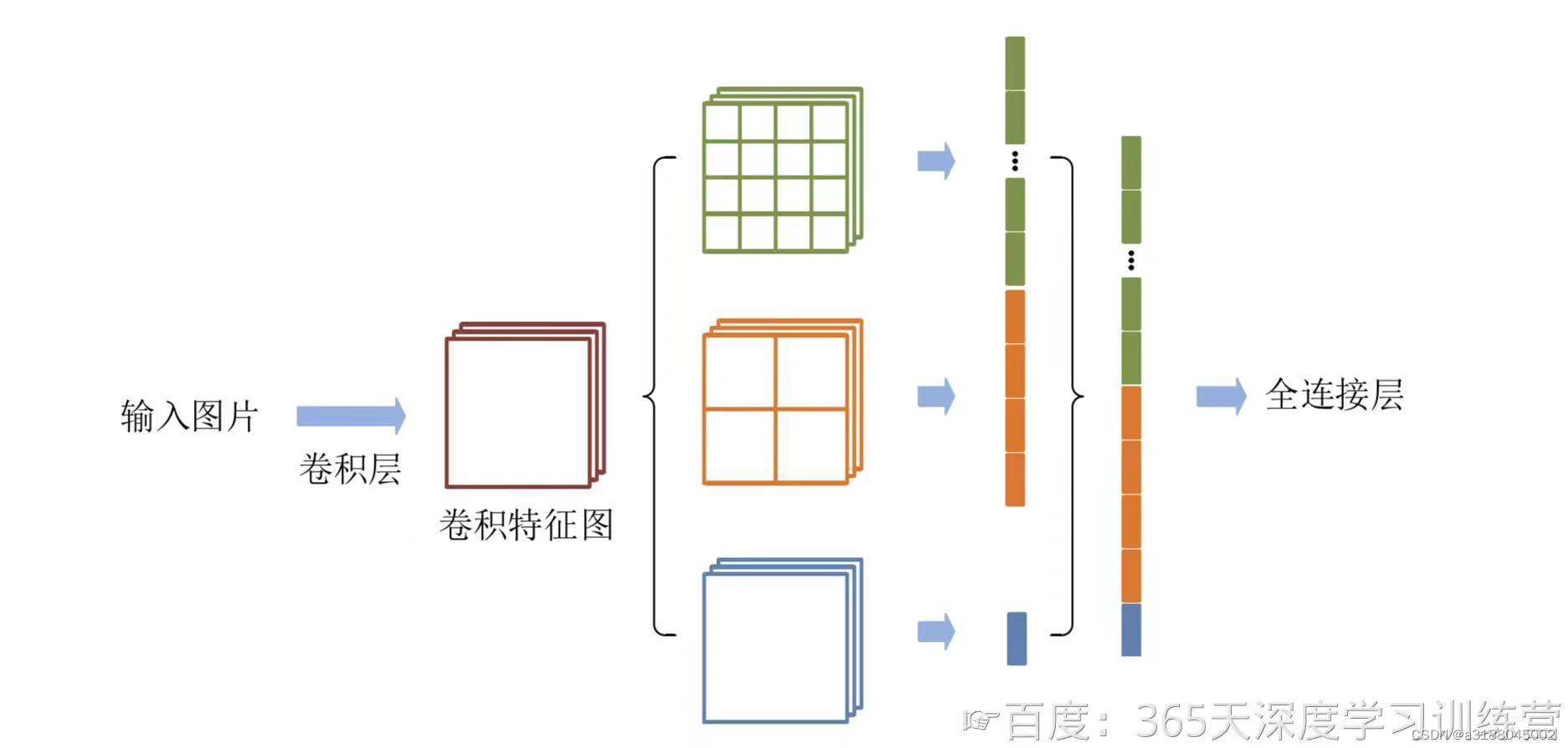
高层网络层的感受野的语义信息表征能力强,低层网络层的感受野空间细节信息表征能力强。空间金字塔池化(Spatial Pyramid Pooling,SPP)是目标检测算法中对高层特征进行多尺度池化以增加感受野的重要措施之一。经典的空间金字塔池化模块首先将输入的卷积特征分成不同的尺寸,然后每个尺寸提取固定维度的特征,最后将这些特征拼接成一个固定的维度,如图所示。输入的卷积特征图的大小为(w,h),第一层空间金字塔采用4×4的刻度对特征图进行划分,其将输入的特征图分成了16个块,每块的大小为(w/4, h/4);第二层空间金字塔采用2×2刻度对特征图进行划分,其将特征图分为4个快,每块大小为(w/2,h/2);第三层空间金字塔将整张特征图作为一块,进行特征提取操作,最终的特征向量为21=16+4+1维。 但是注意池化并不会改变图像的特征图的数量。
class SPP(nn.Module):
def __init__(self, c1, c2, k=(5, 9, 13)):
super(SPP, self).__init__()
c_ = c1//2
self.conv1 = Conv(c1, c_, 1, 1)
self.conv2 = Conv(c_*(len(k)+1), c2, 1, 1) # 输入通道为池化层的数量+1和c_的积
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x//2) for x in k]) # 对x分别进行3次池化
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))1.6 Concat
这个模块就是将张量按照某个维度进行拼接,例如[1.0, 2.0, 3.0],[4.0, 5.0, 6.0]按照维度0拼接,结果为[1., 2., 3., 4., 5., 6.]。
class Concat(nn.Module):
def __init__(self, dimension=1):
super(Concat, self).__init__()
self.d = dimension
def forward(self, x):
# x: a list of tensors
return torch.cat(x, self.d)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









