






一,FIO工具参数优化
1.FIO关键参数介绍:
平均带宽(avg bw),iops
2.psync与libaio引擎的分析
2.1 psync是使用同步方式,用多线程模拟同时批量给内核提交IO请求
2.2 libaio采用Kernel Native AIO可以达到单次批量给内核提交IO请求的目 的,相比psync的多线程,libaio的开销更小,性能更好,更加合适评估内 核块子系统的性能
3.平均带宽计算公式分析
二,优化工具
ftrace,blktrace,bpftrace
- ftrace:
- blktrace:
blktrace /dev/sda5
blkparse -i sda5 -d sda5.blktrace.bin
btt -i sda5.blktrace.bin -l sda5.d2c_latency | less
- bpftrace脚本如下:

三,内核块子系统优化分析
1.内核块子系统对IO请求的处理流程
2.从IO请求处理流程可以看到关键优化流程
X:拆分,增大bio最大限制,避免拆分
优化参数max_sectors_kb
步骤:查找参数max_sectors_kb
ll /sys/block/sda/queue/max_sectors_kb
cat /sys/block/sda/queue/max_sectors_kb
echo 1024 > /sys/block/sda/queue/max_sectors_kb
cat /sys/block/sda/queue/max_sectors_kb
效果如下图:
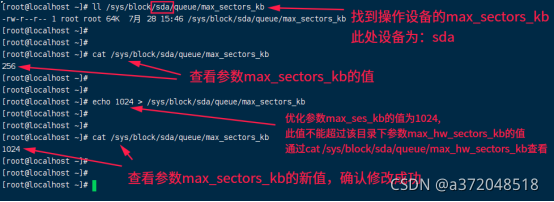
优化参数/sys/block/sda/queue/max_sectors_kb
从256增加到1024
执行命令:
fio -filename=/dev/sda5 -ioengine=libaio -time_based=1 -rw=rw -direct=1 -buffered=0 -thread -size=110g -bs=600K -numjobs=1 -iodepth=80 -iodepth_batch=80 -iodepth_batch_complete_min=80 -runtime=10 -lockmem=1G -group_reporting -name=rw
256的结果:
read: IOPS=147, BW=86.3MiB/s (90.5MB/s)(869MiB/10073msec)
bw ( KiB/s): min=42000, max=138000, per=97.95%, avg=86520.00, stdev=27311.26, samples=20
iops : min= 70, max= 230, avg=144.20, stdev=45.52, samples=20
write: IOPS=154, BW=90.6MiB/s (94.0MB/s)(912MiB/10073msec); 0 zone resets
bw ( KiB/s): min=44400, max=154800, per=98.21%, avg=91080.00, stdev=30199.92, samples=20
iops : min= 74, max= 258, avg=151.80, stdev=50.33, samples=20
1204的结果:
read: IOPS=270, BW=159MiB/s (166MB/s)(1607MiB/10122msec)
bw ( KiB/s): min=37200, max=230400, per=99.67%, avg=162000.00, stdev=44708.74, samples=20
iops : min= 62, max= 384, avg=270.00, stdev=74.51, samples=20
write: IOPS=282, BW=165MiB/s (173MB/s)(1675MiB/10122msec); 0 zone resets
bw ( KiB/s): min=58800, max=249600, per=99.87%, avg=169200.00, stdev=42340.57, samples=20
iops : min= 98, max= 416, avg=282.00, stdev=70.57, samples=20
当bio请求数据大于256KB的时候会被拆分,所以优化该值,将该值增大到1024KB
通过对执行结果分析,可以看到对于600KB的块大小,平均带宽提升了1倍
按照以上思路使用libaio与psync两种引擎,分别执行混合读写,顺序写,随机读写,平均带宽结果如下:
max_sectors_kb:256
混合读写 顺序读写 随机读写
libaio 100000 250000 50000
psync 170000®(IOPS=157,BW=92.1MiB/s) 170000 150000
max_sectors_kb:1024
混合读写 顺序读写 随机读写
libaio 170000 260000 70000
psync 210000®(IOPS=271,BW=159MiB/s) 310000 140000
1.以1024 顺序写为例进一步分析:psync(310000),libaio(260000)
以这种情况为例的原因:这种情况优化了bio的拆分,所以每个bio大小基本都相等,只需要分析bio的延时和数量即可分析出两种引擎的性能优劣,极大减少了其他方面的影响因素
libaio与psync的延迟如下:
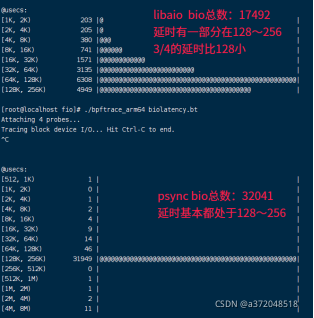
从上面的数据可以看出,虽然psync的总体带宽比libaio大,但是从上图可以很明显的看出这其实是一种假象,虽然psync总体上带宽较大,但是psync的bio总数大几乎是libaio总数的一倍,所以总得数据量较大,但是延时也较大,所以导致psync带宽总体上并不是libaio的2倍,仅仅比libaio多1/5(5万左右),所以这种假象让使用psync引擎的人误认为块子系统性能比较好,其实不然,所以psync这种引擎并不适合评估块子系统的读写性能,如下对于max_sectors_kb=1024时混合读写有类似的数据:
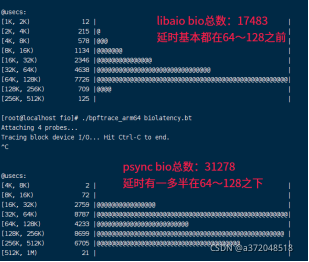
M:bio合并,合并时bio结构未变化
1.考虑在合并时将bio按照增大块大小的方式合并,比如:原始块大小为512B,按照新的1K块大小合并bio,1K块大小比512B块大小可以提升读写带宽
2.批量参数fifo_batch,此参数是从调度器请求队列单次批量提交到设备请求队列的最大请求个数,fifo_batch增大则吞吐量提高,fifo_batch减少则实时性提高
G:生成新的请求,增大请求队列最大数量,避免拥塞
通过调整nr_requests的值来动态修改队列请求最大数量
I:调度算法优化
1.根据物理磁盘介质选择合适的调度算法,例如:
磁盘介质 调度算法
SSD none
机械硬盘 mq-deadline
2.也可根据实际情况优化上述算法或实现自己的调度算法
3.将请求直接插入调度器队列,进行bio合并之后直接进行请求合并,取消 批量IO操作的时候对请求合并的逻辑,因为bio合并之后只对变化的请 求进行合并而且变化的请求合并的时候只涉及变化请求的前一个请求或是 后一个请求并无遍历,而批量IO操作的时候对每个请求都会执行合并而 且每次都有遍历查找
D:硬件驱动优化,通常由硬件厂商优化
对于SSD,虽然支持随机读写,但是存在写放大的问题,写一小部分会引起大 部分的写操作,这部分通常是厂商在固件中优化
四,blktrace对请求(块大小为512B)处理整体时间统计如下图:
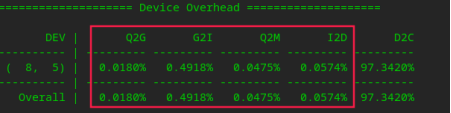
从图中可知,D2C占用了97%的时间,其他阶段总占用不到3%,D2C很大一部分时间消耗在机械磁盘的寻道上
对于512B大小的块,优化空间不大了,从blktrace的时间统计中可以看到即使把前面几个阶段的时间全部优化掉也只能影响不到3%,对整体性能优化提升不大
四,对上述三中M阶段所述的将小块合并为大块的思路分析
1.在submit_bio将所有bio请求提交到当前进程的请求队列之后,在unplug阶段 将当前进程请求队列中的所有请求批量插入到IO调度器的请求队列中,最后将请求通 过驱动全部发送给磁盘设备执行操作,考虑在此过程中加入块大小提升逻辑
结论:经过对硬件驱动对块请求的处理逻辑分析,此思路与硬件驱动中scatter/gather原理一样,所以硬件已经优化














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









