




 本文介绍了使用Python的BeautifulSoup库进行网页抓取和解析的实战练习,涉及requests、lxml、re、matplotlib.pyplot和numpy等库。在实践中,作者提醒注意CSS选择器可能因请求源码差异导致的问题,并分享了源代码和交流邮箱。
本文介绍了使用Python的BeautifulSoup库进行网页抓取和解析的实战练习,涉及requests、lxml、re、matplotlib.pyplot和numpy等库。在实践中,作者提醒注意CSS选择器可能因请求源码差异导致的问题,并分享了源代码和交流邮箱。
知识点介绍
涉及到的库如下:
requests库用于网页访问
bs4的BeautifulSoup进行网页解析
lxml第三方网页解析库,也可以使用python自带html.parser
re正则表达式用于查找提取字符
matplotlib.pyplot用于绘图
numpy用于辅助绘图处理对应数据
中途问题注意:使用CSS选择器选择获取了元素路径,但是带入BeautifulSoup的select方法中后始终获取不到数据,核对发现request获取的网页源码和浏览器获取的不一样,会导致CSS选择器选择的路径不正确,需要手工核对。
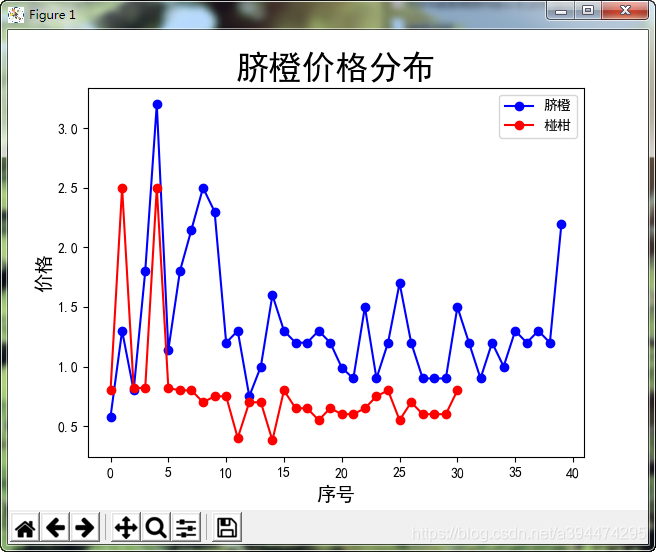
效果展示
源代码
import requests
from bs4 import BeautifulSoup
import lxml
import re
import matplotlib.pyplot as plt
import numpy as np
def GetFruitInfo(pageCnt=3):
retInfo=[]
#来源地址,某些网站不指定来源地址不允许访问
my_referer = r'https://www.lvguo.net/baojia/area/7000/'
#需要提取信息的多个页面,用for循环生成
urlList = ["https://www.lvguo.net/baojia/area/7006/"]
for i in range(2,pageCnt+1):
urlList.append("https://www.lvguo.net/baojia/area/7006/"+"t{0}".format(i))
#print(urlList)
for url in urlList:
#url="https://www.lvguo.net/baojia/area/7006/t3"
#调用requests的get方法获取网页源代码
webData = requests.get(url,headers={
'referer' : my_referer}).text
#print(webData)
#建立BeautifulSoup解析网页,这里调用的是python自带的解析器"html.parser",也可以用第三方的解析器"lxml"
soup = BeautifulSoup(webData,"html.parser")
#调用select方法并指定元素,用浏览器CSS选择器确定
list=soup.select(".bjtbl > tr")
for info in list[2:]:
#获悉信息ID
#查找第0个td标签的属性,提取出来
infoId=info.select("td" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 600
600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









