







实验目的
掌握使用智能编程语言优化算法性能的原理,掌握智能编程语言的调优方法。
能够使用智能编程语言在DLP上加速矩阵乘法的计算。
实验代码
- mlu_gemm16.cpp:Host端调用内核算子
/*************************************************************************
* Copyright (C) [2019] by Cambricon, Inc.
*
* Permission is hereby granted, free of charge, to any person obtaining a
* copy of this software and associated documentation files (the
* "Software"), to deal in the Software without restriction, including
* without limitation the rights to use, copy, modify, merge, publish,
* distribute, sublicense, and/or sell copies of the Software, and to
* permit persons to whom the Software is furnished to do so, subject to
* the following conditions:
*
* The above copyright notice and this permission notice shall be included
* in all copies or substantial portions of the Software.
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
* OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
* MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
* IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
* CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
* TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
* SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
*************************************************************************/
#include <float.h>
#include <math.h>
#include <memory.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/time.h>
#include <vector>
#include "cnrt.h"
#include "gemm16Kernel.h"
#define PAD_UP(x, m) ((x + m - 1) / m * m)
#define MP_SELECT 16
#define MP1 ((MP_SELECT & 1))
#define MP4 ((MP_SELECT & 4))
#define MP8 ((MP_SELECT & 8))
#define MP16 ((MP_SELECT & 16))
#define MP32 ((MP_SELECT & 32))
//int Mlu_gemm(float *A, const float *B, float *C, int M, int N, int K) {
int Mlu_gemm(int8_t *A, int8_t *B, float *C, int32_t M, int32_t N, int32_t K,
int16_t pos1, int16_t pos2, float scale1, float scale2,float &return_time) {
struct timeval start;
struct timeval end;
float time_use;
int N_align = N;
// int N_align = PAD_UP(N, 16);
// int K_align = PAD_UP(K, 64);
cnrtRet_t ret;
gettimeofday(&start, NULL);
cnrtQueue_t pQueue;
CNRT_CHECK(cnrtCreateQueue(&pQueue));
cnrtDim3_t dim;
cnrtFunctionType_t func_type = CNRT_FUNC_TYPE_BLOCK; // CNRT_FUNC_TYPE_BLOCK=1
dim.x = 1;
dim.y = 1;
dim.z = 1;
if (MP1) {
dim.x = 1;
func_type = CNRT_FUNC_TYPE_BLOCK;
} else if (MP4) {
dim.x = 4;
func_type = CNRT_FUNC_TYPE_UNION1;
//printf("UNION1!\n");
} else if (MP8) {
dim.x = 8;
func_type = CNRT_FUNC_TYPE_UNION2;
} else if (MP16) {
dim.x = 16;
func_type = CNRT_FUNC_TYPE_UNION4;
//printf("16\n");
} else if (MP32) {
dim.x = 32;
func_type = CNRT_FUNC_TYPE_UNION8;
} else {
//printf("MP select is wrong! val = %d, use default setting,mp=1\n",
// MP_SELECT);
// return -1;
}
gettimeofday(&end, NULL);
time_use =
((end.tv_sec - start.tv_sec) * 1000000 + (end.tv_usec - start.tv_usec)) /
1000.0;
//printf("cnrt init time use %f ms\n", time_use);
gettimeofday(&start, NULL);
float *h_f32b = (float *)malloc(K * sizeof(float));
half *h_c = (half *)malloc(M * N_align * sizeof(half));
// float* h_a =(float*)malloc(M * K_align * sizeof(float));
//half *h_w = (half *)malloc(K_align * N_align * sizeof(half));
//memset(h_w, 0, sizeof(half) * K_align * N_align);
// int8_t *h_w = (int8_t *)malloc(K_align * N_align * sizeof(int8_t));
// memset(h_w, 0, sizeof(int8_t) * K_align * N_align);
#if 0
half *h_w_reshape = (half *)malloc(K_align * N_align * sizeof(half));
half *h_b = (half *)malloc(K_align * sizeof(half));
for (int j = 0; j < K; j++) {
h_f32b[j] = 0.0;
CNRT_CHECK(cnrtConvertFloatToHalf(&h_b[j], h_f32b[j]));
for (int i = 0; i < N; i++) {
CNRT_CHECK(cnrtConvertFloatToHalf(&h_w[i * K_align + j],
B[j * N + i])); // transpose
}
}
#endif
#if 0
for (int i =0; i < K * N; i++)
{
if (i % N == 0) //printf("\n");
//printf("%.1f ", B[i]);
}
#endif
gettimeofday(&end, NULL);
time_use =
((end.tv_sec - start.tv_sec) * 1000000 + (end.tv_usec - start.tv_usec)) /
1000.0;
//printf("convert data time use %f ms\n", time_use);
gettimeofday(&start, NULL);
#if 0
#if __BANG_ARCH__ == 100
int Tn = N_align / 256;
int Ren = N_align % 256;
for (int i = 0; i < Tn; i++) {
CNRT_CHECK(cnrtFilterReshape(h_w_reshape + i * 256 * K_align,
h_w + i * 256 * K_align, 256, K_align, 1, 1,
CNRT_FLOAT16));
}
if (Ren != 0) {
CNRT_CHECK(cnrtFilterReshape(h_w_reshape + Tn * 256 * K_align,
h_w + Tn * 256 * K_align, Ren, K_align, 1, 1,
CNRT_FLOAT16));
}
#else
int Tn = N_align / 1024;
int Ren = N_align % 1024;
for (int i = 0; i < Tn; i++) {
CNRT_CHECK(cnrtFilterReshape(h_w_reshape + i * 1024 * K_align,
h_w + i * 1024 * K_align, 1024, K_align, 1, 1,
CNRT_FLOAT16));
}
if (Ren != 0) {
CNRT_CHECK(cnrtFilterReshape(h_w_reshape + Tn * 1024 * K_align,
h_w + Tn * 1024 * K_align, Ren, K_align, 1, 1,
CNRT_FLOAT16));
}
#endif
#endif
gettimeofday(&end, NULL);
time_use =
((end.tv_sec - start.tv_sec) * 1000000 + (end.tv_usec - start.tv_usec)) /
1000.0;
//printf("reshape filter time use %f ms\n", time_use);
half *d_c = NULL;
int8_t *d_a = NULL;
int8_t *d_w = NULL;
int16_t pos = pos1 + pos2;
gettimeofday(&start, NULL);
//在mlu上为输入输出开辟空间
CNRT_CHECK(cnrtMalloc((void **)&d_c, M * N * sizeof(half)));
CNRT_CHECK(cnrtMalloc((void **)&d_a, M * K * sizeof(int8_t)));
CNRT_CHECK(cnrtMalloc((void **)&d_w, K * N * sizeof(int8_t)));
//将cpu上的输入拷贝给mlu上的输入
CNRT_CHECK(cnrtMemcpy(d_a, A, M * K * sizeof(int8_t), CNRT_MEM_TRANS_DIR_HOST2DEV));
CNRT_CHECK(cnrtMemcpy(d_w, B, K * N * sizeof(int8_t), CNRT_MEM_TRANS_DIR_HOST2DEV));
gettimeofday(&end, NULL);
time_use =
((end.tv_sec - start.tv_sec) * 1000000 + (end.tv_usec - start.tv_usec)) /
1000.0;
//printf("malloc ©in time use %f ms\n", time_use);
cnrtKernelParamsBuffer_t params;
CNRT_CHECK(cnrtGetKernelParamsBuffer(¶ms)); // Gets a parameter buffer for cnrtInvokeKernel_V2 or cnrtInvokeKernel_V3.
//向params添加参数
CNRT_CHECK(cnrtKernelParamsBufferAddParam(params, &d_c, sizeof(half *)));
CNRT_CHECK(cnrtKernelParamsBufferAddParam(params, &d_a, sizeof(int8_t *)));
CNRT_CHECK(cnrtKernelParamsBufferAddParam(params, &d_w, sizeof(int8_t *)));
CNRT_CHECK(cnrtKernelParamsBufferAddParam(params, &M, sizeof(uint32_t)));
CNRT_CHECK(cnrtKernelParamsBufferAddParam(params, &K, sizeof(uint32_t)));
CNRT_CHECK(cnrtKernelParamsBufferAddParam(params, &N_align, sizeof(uint32_t)));
CNRT_CHECK(cnrtKernelParamsBufferAddParam(params, &pos, sizeof(uint16_t)));
cnrtKernelInitParam_t init_param;
CNRT_CHECK(cnrtCreateKernelInitParam(&init_param));
CNRT_CHECK(cnrtInitKernelMemory((const void *)gemm16Kernel, init_param));
cnrtNotifier_t notifier_start; // A pointer which points to the struct describing notifier.
cnrtNotifier_t notifier_end;
CNRT_CHECK(cnrtCreateNotifier(¬ifier_start));
CNRT_CHECK(cnrtCreateNotifier(¬ifier_end));
float timeTotal = 0.0;
//printf("start invoke : \n");
gettimeofday(&start, NULL);
CNRT_CHECK(cnrtPlaceNotifier(notifier_start, pQueue)); // Places a notifier in specified queue
// 启动激活函数
CNRT_CHECK(cnrtInvokeKernel_V3((void *)&gemm16Kernel, init_param, dim, params, func_type, pQueue, nullptr)); // Invokes a kernel written in Bang with given params on MLU
CNRT_CHECK(cnrtPlaceNotifier(notifier_end, pQueue)); // Places a notifier in specified queue
CNRT_CHECK(cnrtSyncQueue(pQueue)); // Function should be blocked until all precedent tasks in the queue are completed. 同步Queue
gettimeofday(&end, NULL);
time_use =
((end.tv_sec - start.tv_sec) * 1000000 + (end.tv_usec - start.tv_usec)) /
1000.0;
// //printf("invoke time use %f ms\n", time_use);
// cnrtNotifierElapsedTime(notifier_start, notifier_end, &timeTotal);
// get the duration time between notifer_start and notifer_end.
// cnrtNotifierDuration(notifier_start, notifier_end, &timeTotal); // Gets duration time of two makers
CNRT_CHECK(cnrtNotifierDuration(notifier_start, notifier_end, &timeTotal));
return_time = timeTotal / 1000.0;
//printf("hardware total Time: %.3f ms\n", return_time);
gettimeofday(&start, NULL);
// 将输出拷回cpu
CNRT_CHECK(cnrtMemcpy(h_c, d_c, sizeof(half) * M * N_align,
CNRT_MEM_TRANS_DIR_DEV2HOST));
for (int j = 0; j < M; j++) {
for (int i = 0; i < N; i++) {
CNRT_CHECK(cnrtConvertHalfToFloat(&C[j * N + i], h_c[j * N_align + i]));
C[j * N + i] = C[j * N + i]/(scale1 * scale2);
}
}
gettimeofday(&end, NULL);
time_use =
((end.tv_sec - start.tv_sec) * 1000000 + (end.tv_usec - start.tv_usec)) /
1000.0;
//printf("copyout &convert time use %f ms\n", time_use);
// free
CNRT_CHECK(cnrtFree(d_c));
CNRT_CHECK(cnrtFree(d_a));
CNRT_CHECK(cnrtFree(d_w));
CNRT_CHECK(cnrtDestroyQueue(pQueue));
CNRT_CHECK(cnrtDestroyKernelParamsBuffer(params));
CNRT_CHECK(cnrtDestroyNotifier(¬ifier_start));
CNRT_CHECK(cnrtDestroyNotifier(¬ifier_end));
free(h_f32b);
free(h_c);
//free(h_w);
//free(h_w_reshape);
return 0;
}
- gemm_PARALL.mlu:多核并行实现矩阵乘法,Device端的关键代码
考虑到所使用的DLP有16个计算核,可以进一步采用16个计算核进行并行运算。由于每个DLP指令集所能处理的向量运算长度受限,我们对n进行分块计算,分块长度为256。每个计算核每个从GDRAM上拷贝数据的时候要根据自己的CoreID来确定目标数据的内存地址,并且只将自己负责的数据块拷入到NRAM:
#include "mlu.h"
#define ROUND 256
__mlu_entry__ void gemm16Kernel(half *outputDDR, int8_t *input1DDR, int8_t *input2DDR,
uint32_t m, uint32_t k, uint32_t n, int16_t pos) {
__nram__ int8_t input1NRAM[256*256];
__nram__ int8_t input2NRAM[256*256];
__nram__ int8_t input2NRAM_tmp[256*256];
__wram__ int8_t input2WRAM[256*256];
__nram__ half outputNRAM[256*256];
__memcpy(input1NRAM, input1DDR, m * k * sizeof(int8_t), GDRAM2NRAM);
//在这里将左矩阵一次性拷入NRAM
int all_round = n / (taskDim * ROUND);
int32_t dst_stride = (ROUND * k / 64) * sizeof(int8_t);
int32_t src_stride = k * sizeof(int8_t);
int32_t size = k * sizeof(int8_t);
int32_t total_times = ROUND / 64;
// __mlu_shared__ int8_t input2SRAM[256*1024];
//_bang_printf("taskDim=%d,clusterId=%d,coreId=%d\n",taskDim,clusterId,coreId);
for(int i = 0; i < all_round; i++)
{
__memcpy(input2NRAM_tmp, input2DDR + ROUND * k * (i*taskDim+taskId), k*ROUND*sizeof(int8_t), GDRAM2NRAM);
for (int j = 0; j < total_times; j++) {
__memcpy(input2NRAM + j * k, input2NRAM_tmp + j * 64 * k,
size, NRAM2NRAM, dst_stride, src_stride, 64);
}
// copy NRAM2WRAM
__memcpy(input2WRAM, input2NRAM, ROUND * k * sizeof(int8_t), NRAM2WRAM);
// compute
__bang_conv(outputNRAM, input1NRAM, input2WRAM, k, m, 1, 1, 1, 1, 1, ROUND, pos);
// copy NRAM2GDRAM
for (int j = 0; j < m; j++) {
__memcpy(outputDDR + (i*taskDim+taskId)*ROUND + j*n, outputNRAM + j * ROUND, ROUND*sizeof(half), NRAM2GDRAM);
}
}
}
- gemm_SRAM.mlu: SRAM的使用,加速
在上一步中,因为使用了4个Cluster的16个计算核进行并行计算,而相同Cluster上的4个核从GDRAM到NRAM/WRAM拷贝数据时,会抢占该Cluster到GDRAM的带宽,从而导致数据读取速度降低。
考虑到搭配每个Cluster有一个共享的SRAM,我们将数据先从GDRAM拷贝到SRAM,再从SRAM分发到NRAM/WRAM,从而避免了带宽抢占问题。注意,因为从GDRAM拷贝数据到SRAM和从SRAM拷贝数据到GDRAM这两个操作是在两种不同功能的核上执行(普通核和Memory核),所以这两个操作可以并行执行,为保证数据一致性,需要加上同步操作。
#include "mlu.h"
#define ROUND 256
__mlu_entry__ void gemm16Kernel(half *outputDDR, int8_t *input1DDR, int8_t *input2DDR,
uint32_t m, uint32_t k, uint32_t n, int16_t pos) {
__nram__ int8_t input1NRAM[256*256];
__nram__ int8_t input2NRAM[256*256];
__nram__ int8_t input2NRAM_tmp[256*256];
__wram__ int8_t input2WRAM[256*256];
__nram__ half outputNRAM[256*256];
__memcpy(input1NRAM, input1DDR, m * k * sizeof(int8_t), GDRAM2NRAM);
//在这里将左矩阵一次性拷入NRAM
int all_round = n / ( taskDim * ROUND); //因为现在使用16个核同时运算,所以每个核循环的次数也相应减少
int32_t dst_stride = (ROUND * k / 64) * sizeof(int8_t);
int32_t src_stride = k * sizeof(int8_t);
int32_t size = k * sizeof(int8_t);
int32_t total_times = ROUND / 64;
__mlu_shared__ int8_t input2SRAM[256*1024];
//_bang_printf("taskDim=%d,clusterId=%d,coreId=%d\n",taskDim,clusterId,coreId);
for(int i = 0; i < all_round; i++)
{
// copy GDRAM2SRAM
__memcpy(input2SRAM, input2DDR + (i*taskDim+clusterId*4)*ROUND*k, 4*ROUND*size, GDRAM2SRAM);
__sync_cluster(); //设置sync barrier,同步
// copy SRAM2NRAM
__memcpy(input2NRAM_tmp, input2SRAM + coreId*ROUND*k, ROUND*size, SRAM2NRAM);
for (int j = 0; j < total_times; j++) {
__memcpy(input2NRAM + j * k, input2NRAM_tmp + j * 64 * k,
size, NRAM2NRAM, dst_stride, src_stride, 64);
}
// copy NRAM2WRAM
__memcpy(input2WRAM, input2NRAM, ROUND * size, NRAM2WRAM);
// compute
__bang_conv(outputNRAM, input1NRAM, input2WRAM, k, m, 1, 1, 1, 1, 1, ROUND, pos);
// copy NRAM2GDRAM
for (int j = 0; j < m; j++) {
__memcpy(outputDDR + (i * taskDim + taskId) * ROUND + j * n,
outputNRAM + j * ROUND, ROUND * sizeof(half), NRAM2GDRAM);
}
__sync_cluster(); //设置sync barrier
}
}

- gemm_PIPELINE.mlu:访存与计算流水的使用
#include "mlu.h"
#define ROUND 256
__mlu_entry__ void gemm16Kernel(half *outputDDR, int8_t *input1DDR, int8_t *input2DDR,
uint32_t m, uint32_t k, uint32_t n, int16_t pos) {
__nram__ int8_t input1NRAM[256*256];
__nram__ int8_t input2NRAM[256*256];
__nram__ int8_t input2NRAM_tmp[256*256];
__wram__ int8_t input2WRAM[256*256];
__nram__ half outputNRAM[256*256];
__memcpy(input1NRAM, input1DDR, m * k * sizeof(int8_t), GDRAM2NRAM);
//在这里将左矩阵一次性拷入NRAM
int all_round = n / ( taskDim * ROUND); //因为现在使用16个核同时运算,所以每个核循环的次数也相应减少
int32_t dst_stride = (ROUND * k / 64) * sizeof(int8_t);
int32_t src_stride = k * sizeof(int8_t);
int32_t size = k * sizeof(int8_t);
int32_t total_times = ROUND / 64;
__mlu_shared__ int8_t input2SRAM1[256*1024];
__mlu_shared__ int8_t input2SRAM2[256*1024];
__mlu_shared__ int8_t *input2SRAM_read;
__mlu_shared__ int8_t *input2SRAM_write;
input2SRAM_write = input2SRAM1;
// copy GDRAM2SRAM
__memcpy(input2SRAM_write, input2DDR + ROUND*(clusterId*4)*k, ROUND*4*size, GDRAM2SRAM);
__sync_cluster(); //设置sync barrier
//_bang_printf("taskDim=%d,clusterId=%d,coreId=%d\n",taskDim,clusterId,coreId);
for(int i = 0; i < all_round-1; i++)
{
if(i % 2 == 0)
{
input2SRAM_read = input2SRAM1;
input2SRAM_write = input2SRAM2;
}else{
input2SRAM_read = input2SRAM2;
input2SRAM_write = input2SRAM1;
}
// copy GDRAM2SRAM
__memcpy(input2SRAM_write, input2DDR + ROUND*((i+1)*taskDim+clusterId*4)*k, 4*ROUND*size, GDRAM2SRAM);
// copy SRAM2NRAM
__memcpy(input2NRAM_tmp, input2SRAM_read + ROUND*coreId*k, ROUND*size, SRAM2NRAM);
for (int j = 0; j < total_times; j++) {
__memcpy(input2NRAM + j * k, input2NRAM_tmp + j * 64 * k,
size, NRAM2NRAM, dst_stride, src_stride, 64);
}
// copy NRAM2WRAM
__memcpy(input2WRAM, input2NRAM, ROUND * size, NRAM2WRAM);
// compute
__bang_conv(outputNRAM, input1NRAM, input2WRAM, k, m, 1, 1, 1, 1, 1, ROUND, pos);
// copy NRAM2GDRAM
for (int j = 0; j < m; j++) {
__memcpy(outputDDR + (i * taskDim + taskId) * ROUND + j * n,
outputNRAM + j * ROUND, ROUND * sizeof(half), NRAM2GDRAM);
}
__sync_cluster(); //设置sync barrier
}
// copy SRAM2NRAM
__memcpy(input2NRAM_tmp, input2SRAM_write + ROUND*coreId*k, ROUND*size, SRAM2NRAM);
for (int j = 0; j < total_times; j++) {
__memcpy(input2NRAM + j * k, input2NRAM_tmp + j * 64 * k,
size, NRAM2NRAM, dst_stride, src_stride, 64);
}
// copy NRAM2WRAM
__memcpy(input2WRAM, input2NRAM, ROUND * size, NRAM2WRAM);
// compute
__bang_conv(outputNRAM, input1NRAM, input2WRAM, k, m, 1, 1, 1, 1, 1, ROUND, pos);
// copy NRAM2GDRAM
for (int j = 0; j < m; j++) {
__memcpy(outputDDR + ROUND*((all_round-1) * taskDim + taskId) + j * n,
outputNRAM + j * ROUND, ROUND * sizeof(half), NRAM2GDRAM); //i = all_round-1
}
}
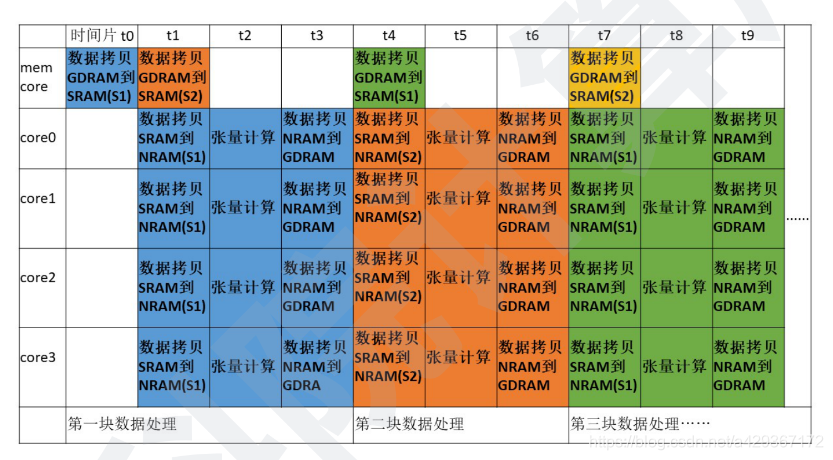
具体的数据时序如下图所示,从中可以发现耗时很长的从GDRAM到SRAM的数据拷贝被隐藏了,和之前步骤相比,每次搬运了更多的GDRAM数据到片上完成了计算。这也是计算机系统优化时常用到的数据流控制技巧,即“乒乓操作”















 222
222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









