







一、初步认识数据库系统
内容:
工作环境
数据库功能(用户)
数据库功能(系统)
数据库标准结构
工作环境
DB:相互之间有关联关系的若干表的集合
DBMS:管理数据库的软件
DBAP:数据库应用程序
DBA:数据库管理员
计算机基本系统
数据库功能(用户)
数据库定义:定义表名称,标题等
DBMS给用户提供数据定义语言DDL
用户用DDL描述其所需格式
DBMS依据DDL创建数据库与表
数据库操纵:对表进行增删改查,对数据查询、检索、统计
DBMS给用户提供数据定义语言DML
用户用DML描述其所需格式
DBMS依据DML执行
数据库控制:控制数据库的使用权限
DBMS给用户提供数据定义语言DCL
用户用DCL描述其所需格式
DBMS依据DCL执行
数据库功能(系统)
语言编译器:将数据库语言转为可执行命令
查询优化(执行引擎)与查询实现(基本命令的不同执行算法):提高检索效率的方法
数据存取与索引:数据在磁盘磁带上高效存取的方法
通信控制:网络环境下的操作与输出
事务管理:提高可靠性,避免并发操作错误
故障恢复:恢复至故障发生前的正确状态
安全性控制:合法性检验
完整性控制:数据与操作的正确性检查
数据字典管理:管理用户已定义信息
数据库标准结构
三级模式:
外模式,外视图:某一用户能看到的结构描述
概念模式,概念视图:全局角度的结构描述,含相应的关联约束
内模式,内视图:存储在介质上的结构描述,含存储路径、存储方式、索引方式等
两层映像:
E-C Mapping 外-概念映像,外视图->概念视图,便于用户观察使用
C-I Mapping 概念-内映像,概念视图->内视图,便于系统存储与处理
两个独立性:
逻辑数据独立性:概念模式变化时可不改变外模式,仅改变E-C映像,从而不改变外应用程序
物理数据独立性:内模式变化时,可不改变概念模式,仅改变C-I映像,从而不改变外模式
二、数据库系统的结构抽象与演变
内容:数据模型,历代数据库特性
数据模型
定义:规定模式统一描述方式的模型,包括数据结构,操作,约束
数据、模式、数据模型关系:
数据自身结构可抽象为模式
模式自身结构可抽象为数据模型
三种经典的数据模型:
关系模型:表
层次模型:树,由多个实体性构成,各实体由“系型”连接,各系型由指针确定
网状模型:图,与树相似,但其实体型的父/子节点个数不确定
历代数据库特性
文件系统:
以记录为单位
优点:用户不用考虑文件存储的物理细节,解脱了对物理设备存取复杂性处理的负担
缺点:数据与程序紧密结合,若更改数据结构,则必须修改应用程序。其文件之间、文件记录之间 均无联系,共享性差,冗余度大,不一致性高
网状与层次数据模型数据库:
数据之间关联关系由指针系统维系,结构复杂
数据检索依赖指针指示路径
不支持记录集合操作
关系数据库:
按行按列组织数据库(关系第一范式)
数据项不可再分
关系运算:关系代数,元组演算,域演算
关系数据库设计理论
对象-关系数据库:
支持不满足第一范式的数据项(多值/复合项)
以对象来封装需分解的数据项
行对象与列对象:聚集对象与结构对象
XML数据库:
半结构化数据库
数据与数据的语义合并存储与管理
面向数据交换提出
开放互联多种多样数据库:
ODBC,JDBC等
三、关系模型-基本概念
内容:
区分概念:域、笛卡尔积、关系、关系模式、关键字、外码、主码、主/非主属性
三个完整性:主体完整性、参照完整性、用户自定义完整性
关系模型三要素:基本结构、基本操作、完整性约束
关系模型:
描述数据库各数据基本结构形式 Table/Relation
描述表之间的各种操作 关系运算
描述关系运算中的约束条件 完整性约束
运算
关系代数:基于集合的运算,其操作对象与结果均为集合,一次一集合,而非关系型数据则多为一次一记录操作。
基于关系代数的数据库语言:ISB2
元组演算:基于逻辑的运算
基于元组演算的数据库语言:QUEL
域演算:基于示例的运算
基于域演算的数据库语言:QBE
定义表:
定义列的取值范围为“域”,其中元素个数为“基数”
定义元组与所有可能的行:每个域出一个元素,构成元组
D1xD2x...xDn={(d1,d2,...dn) | di ∈ Di,i=1,2,3,4...}
积中每个元素(d1,d2,...dn)称为n-元组,每个值di称为“分量”
积的基数=各域基数乘积
关系:一组笛卡尔积中有意义的组合。其每列列名为“属性名”,列值为“属性值”
关系R(A1:D1,A2:D2,...An:Dn),其中Ai ∈ Di 且“:Di”可省略。n称为“度数/目数”,元组数/行数为“基数”
关系特性
同一列必须来自同一个域
不同列须有不同属性名
关系靠内容(名字,值)来区分,不靠位置区分。例:(A1,A2,A3)与(A1,A3,A2)为同一关系
理论上,关系内不能有相同元组,但实际中,表不一定完全遵守此规定
满足第一范式:关系不可再分
码的分类:
候选码(不唯一):在一个属性组中,其值可唯一标识一个元组,且从该组中去掉任一属性,它便不再具有此性质。可以用一个属性组作为候选码,例:(课程名,教师)
主码(唯一):数据库管理系统以主码为主要线索管理元组,一般从候选码中选择其一作为主码
主属性/非主属性:包含任一候选码的属性为主属性,否则为非主属性
全码:一种特殊情况,所有属性共同组成一个候选码,此时关系中只有主属性,没有非主属性
外码:某一属性不是关系R的候选码,但是关系S的候选码,称该属性为关系S的外码。两关系常靠外码连接
完整性
四、关系模型-关系代数
内容:
基本操作:并、差、积、选择、投影、更名
扩展操作:交、ɵ-连接、自然连接
复杂扩展:除、外连接
操作类型:
集合操作:交、并、差、积
纯关系操作:投影、选择、连接、除
并相容性:若关系R与S具有并相容性,则当且仅当:
R与S属性数目相同
中第i个属性的域相同
基本操作
并、差、积、选择、投影、更名
广义笛卡尔积:R x S:R与S所有可能的组合,且R x S的元祖数目=R元祖数目 x S元祖数目, R x S度数=R度数+S度数
选择(有关元组):ɕcon(R)={ t |t∈R ∧ con(t)=’真’}
运算优先级:括号-比较符-非-交-并(由高到低)
投影(有关属性):从原关系R中选出部分属性构成新关系S
更名:ρsc1(sc) ->将表sc更名为sc1,可用于表与自身的连接
扩展操作
交、ɵ-连接、等值连接、自然连接
交:R∩S = { t |t∈R ∧t∈S},也可通过差实现:R∩S = R-(R-S)=S-(S-R)
ɵ-连接:在乘积运算基础上,选择所有符合条件的元组,其中A、B具有可比性

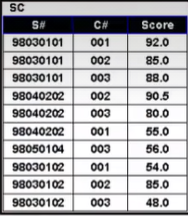
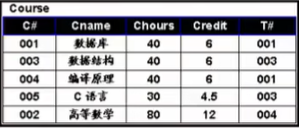
例如:查询98030101号与98040202号学生所学的所有课程号

按规则先将sc与其自身按C#值相连接
根据条件选择对应学生序号的元组
投影所选元组的课程号C#

等值连接:一种特殊的ɵ-连接操作,选择RxS中在属性A、B上值相等的元组
优点:可大幅降低中间元组保存量,提升速度

自然连接:一种特殊的等值连接,在关系R与S中选择相同属性组B上值相等的元组(可以比较多组属性),连接时去掉重复的属性

过程:
两表作积
选择对应属性值相同的元组
去掉重复列
也可以使用积操作来表示连接操作,例如:


例题1:
选择学过001与002两门课程的学生
结果应为
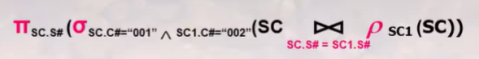
若此处使用自然连接而非等值连接,会出错。原因是:自然连接会删除重复列,导致连接后新表中仅含一列课程号C#
该问题也可以使用交运算来实现:πsc.s#(ɕsc.c#=”001”) ∧ πsc.s#(ɕsc.c#=”002”)
选择未学过001课程的学生
结果用差实现:

不应直接将条件设为c#<>"002",否则会选出未学过001课程的学生,和学过001且学过其他课程的学生
也不应直接用S减去选择后的新表,两表不一定满足并相容性
运算思路总结:
若为单个表,则不考虑连接
若有复数张表,优先考虑自然连接,再考虑等值/非等值连接,最后考虑积运算
连接完成后,继续使用“选投联”操作
复杂扩展操作
除、外连接
除:用于解决“查询全部的...或所有的...”
若R{A1,A2,....An}, S{B1,B2,...Bm}
R÷S前提条件为:{B1,B2,...Bm}为{A1,A2,....An}真子集,m<n
R÷S属性结果为:{C1,C2,...Ck}={A1,A2,....An} - {B1,B2,...Bm},k=n-m
R÷S元组结果为:R÷S中各元组与S中每个元组组合,其结果一定是R中的一个元组

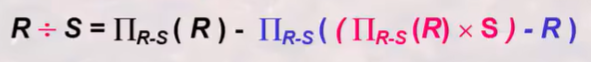
例题(假设sc表中包含了学生姓名Nname):

查询选修了学号98030201学生所学全部课程的学生姓名:
πc#(ɕs#="98030201"(SC)):该学生选择的所有课程
πs#,c#(SC) ÷ πc#(ɕs#="98030201"(SC)):符合题目的所有学生序号
πNname(SC ⋈ (πs#,c#(SC)÷πc#(ɕs#="98030201"(SC))):连接SC表,投影对应学生姓名
外连接:当R与S连接时,若R(或S)在S(或R)中未找到匹配的元组,则将R(或S)中的该元组与S(或R)中假设存在的全为空值的元组形成连接,并存入结果中。
作用:保证左/右表中所有元组运算时不丢失
分类:左外连接,右外连接,全外连接
注意事项
关系运算使用∩ ∪,选择条件使用∧ ∨
注意题目中R与S的关系是连接,还是积
五、关系模型-关系演算
内容:
关系元组演算、关系域演算的递归定义
与、或、非、存在量词、全称量词
用关系演算公式表达查询
QBE语言表达查询
查询时,关系元组演算、关系域演算与关系代数的差异
关系元组演算
以元组变量作为谓词变量的基本对象
基本形式:{ t | P(t) }
三种原子公式:
S∈R
S[A] ɵ C
S[A] ɵ U[B]
优先级:括弧、ɵ、ョ、∀、¬、∧、∨
ョ(t∈R)(P(t))
t前有ョ、∀,称t为约束变量,否则为自由变量
步骤:
写出所需的最终结果所在的表
写出第二张表中元组选择的条件
后接表间所需的联系或元组选择条件
若有两张以上的表,则先考虑将其中两张表按条件连接,最后与第一张表作交运算
元组演算公式例子:
例1:
检索年龄不是最小的所有学生姓名:
{ t | t ∈student ∧ョ(u ∈student ) (age[t] > age[u])}
π student * (ɕ student.age > s1.age(student x ρ s1(student)))
例2:

|

|

|

|
检索学过所有课程的学生
{ t | t ∈student ∧∀(u ∈course )(ョ(w∈sc) (t[s#]=w[s#] ∧ u[c#]=w[c#]) }
检索所有学生的所有课程都及格的系dept
{ t | t ∈dept ∧ ∀(u ∈student∧t[s#]=u[s#])(∀(w∈sc ∧ t[s#]=u[s#]) (w[score]>=60) }
元组演算与关系代数的转换
其中积、选择、投影的转换方式:

其中ョ、∀也存在相互转化的可能
转换例题:



存在多张表时,理清先后顺序,逐层嵌套筛选,在最里层写入各表间的联系属性和判断条件
即:以元组为单位循环,先找元组,再找元组分量,最后谓词判断
关系域演算
原子公式:
<x1,x2,...xn>∈R
x ɵ c:x为域变量,c为常量
x ɵ y:x,y均为域变量
例:
检索不是03系的所有学生
{<a,b,c,d,e,f>|<a,b,c,d,e,f>∈S ∧ e<>'03'}
检索不是(小于20岁男生)的学生姓名
{<b>|ョa,b,c,d,e(<a,b,c,d,e,f>∈S ∧ ¬( c='男' ∧ d<20) )}
域演算语言QBE
高度非过程化查询语言,适合终端用户
特点:操作独特,基于屏幕表格的查询语言,只需将条件填入表格即可
QBE操作框架:
关系名区:待查询关系名 | 属性名区:关系名所对应的各个属性 |
操作命令区:写明查询操作的命令 | 查询条件区:直接写入查询条件 |
操作命令:
Print/P. 输出
Delete/D. 删除
Insert/I. 插入
Update/U. 更新
例:输出年龄小于20或大于17的男同学名字
Student | S# | Sname | Ssex | Sage | D# | Sclass |
Z | P.X | Male | <17 | |||
P.Y | Male | >20 |
若要输出年龄小于20且大于17的男同学名字,则应全写为P.X
连接两表时,使用相同的示例元素表示
例:输出(年龄小于20或大于17)且学过003课程的不及格男同学名字和成绩(连接上表)
SC | S# | C# | score |
Z | 003 | <60 | |
Z | 003 | P.00 |
输出大于张三年龄的同学名字:
Student | S# | Sname | Ssex | Sage | D# | Sclass |
张三 | X | |||||
P.李四 | >X |
关系演算的安全性
安全:不产生无线关系和无穷验证的运算
关系代数是安全的,但关系演算不一定
对关系演算的约束:对演算范围施加一定约束,即任何公式都在一个有限集合内操作
安全约束有限集合DOM(ψ):集合中元素要么是明显出现的符号,要么是出现在集合中的,某关系R中的元组分量。其目的是约束计算范围,不一定是最小集合
安全演算表达式{t|ψ(t)}:
t的每个分量均为DOM(ψ)成员
ョ(u)(w(u))中,所有使w(u)为真的元素都在DOM中
∀(u)(w(u))中,所有使w(u)为假的元素都在DOM中
三种关系运算区别
关系代数:以集合为对象,集合到集合的变换
元组演算:以元组为对象,取出关系中的元组进行运算,一个元组变量可能需要一个循环,多个元组变量需要多个循环
域演算:以域变量为对象,取出关系中的每个域变量进行验证
三种运算时等价的,可互相转换。
非过程性:域演算>元组演算>关系代数
三种运算是衡量一个数据库的基础,若某数据库可等价实现三种运算,则该数据库是完备的
六、SQL语言概述
重点:
SQL-DDL基础语句CREATE DATABASE,CREATE TABLE
SQL-DML基础语句INSERT,DELETE,UPDATE,SELECT
SQL-SELECT语句
引导词
DDL语句引导词:Create,Alter,Drop,用于模式的定义与删除
DML语句引导词:Insert,Delete,Update,Select,用于各种方式的检索与更新,各种复杂条件检索,各种聚焦操作
DCL语句引导词:Grant,Revoke,用于安全性控制,授权与取消授权
建立数据库
创建数据库
Create databese
创建表
Create table 表名 (列名 数据类型[Primary key | Unique][Not Null] [列名 数据类型[Not Null]]......)
其中:
[]中内容可省略
Primary key:主键约束,每张表唯一
Unique:唯一性约束(候选键),要求属性值取值唯一
Not Null:空值约束,该列不能为空
数据类型:char(n),varchar(n),int/integer,numeric(p,q)固定精度数字,real/float(n)浮点精度,date,time等
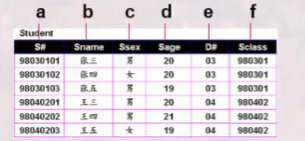
例:创建学生信息表
Create table Student (S# char(8) not null, Sname varchar(10), Ssex char(2), Sage integer, D# char(6), Sclass char(6));向表中追加元组
Insert into 表名 [ (列名 [,列名]....]
Values (值 [,值]....)列名可省略,此时值的排列与表中属性一一对应
例:插入元组到学生信息表
Insert into Student (S#, Sname, Ssex, Sage, D#, Sclass))
Values('93010202','张三',‘女’,20,‘03’,‘980301’)单表查询
Select 列名
From 表名
[where 检索条件]
//where 条件通过and,or not连接例:
Select S#, Sname, Ssex, Sage, D#, Sclass
From Student
where Sage<=18;
//或者
Select * from Student where Sage<=18;结果中不保留重复元组:DISTINCT
Select DISTINCT S#
From Student
where Sage<=18;结果排序:order by
order by 列名 [asc或省略 | dasc] <--升序/降序例:输出18岁以下学生学号,按年龄从高到低排列
Select S#
From Student
where Sage<=18
order by Sage DASC;模糊查询:like
列名 [not]like "字符串"
匹配规则:
%:匹配任意个字符
-:匹配单个字符
\:转义字符,用于去除特殊字符的特殊含义,eg: \%-->查询“%”
例:1.查询所有姓张学生的姓名
Select Sname
From Student
where Sname like‘张%’;2.查询所有姓张XX的学生姓名
Select Sname
From Student
where Sname like‘张____’;(4个'_')3.查询所有不姓张的学生姓名
Select Sname
From Student
where Sname Not like‘张%’;多表联合查询:
Select 列名1,列名2....
From 表名1,表名2...(此处不是连接操作,而是笛卡尔积)
where 条件;例:按001号课程成绩降序排列学生学号
Select S#
From Student,Score
Where Student.S#=Score.S# and Score.C#='001'
Order By Sscore DASC;重名处理as
Select 列名1 as 新列名1,列名2 as 新列名2.... //as可省略
From 表名1 as 新表名1,表名2 as 新表名2...
where 条件;
//as可省略SQL更新操作
新增,更新,删除
新增Insert
单一元组新增
Insert into 表名 (列1,列2,....)
value (值1,值2,...);批元组新增:将检索到的符合条件的元组插入表中
Insert into 表名 (列1,列2,....)
Select 列名1,列名2....
From 表名1,表名2...
where 条件;例:将学生的平均成绩插入新表中
Insert into St(S#,Sname,Avg(Score))
Select S#,Sname,Avg(score)
From Student,SC
Where Student.S#=SC.S#
Group by Student.S#删除Delete
Delete from 表名;//删除所有元组,不删除表本身
Delete from 表名 where 条件;例:删除大于18岁的学生
Delete from Student where Sage in
( //子查询
Select Sage
From Student
Where Sage>18
);更新Update
Update from 表名
set 列名=表达式 | (子查询);例:将001成绩高于平均分的学生奖学金上调10%
Update from Student
Set scholarship = scholarship*1.1
where C#='001' and Score >some
( //子查询
Select Avg(Score)
From Student
Where C#='001'
);修正与撤销数据库
修正数据库定义,修正数据库中表的定义
Alter Table 表名
Add 新增列名1 数据类型1,新增列名2 数据类型2...
| Drop 约束条件(列名)
| Modify 列名 新数据类型;
Drop Table 表名;//撤销表及其中元组
Drop Datebase 数据库名;//撤销数据库
Use 数据库名;//指定当前数据库
Close 数据库名;/关闭当前数据库SQL-Sever数据库
系统数据库:
Master:最重要的数据库,存储元数据
Model:模板数据库,作为新数据库的基础
Msdb:代理服务数据库,提供一个存储空间
Tempdb:临时数据库,断开连接时自动删除
数据库构成:
文件类型:
主数据库文件.mdf: 唯一,存储数据库启动文件和部分或全部数据
辅助数据库文件.ndf:用于存放.mdf定义的数据库的其他数据
日志文件.ldf:数据库中至少有一个,事务日志文件
页面:数据库存储的最小单位,8k
空间 :8个连续页面,是分配数据库表的一个单位
创建/删除数据库:可使用查询分析器或交互式数据库查询引擎
创建表:同一个用户不能创建多个同名表,但一个表可被多个用户拥有,但使用时需添加拥有者名
七、SQ语言-复杂查询与视图
内容:
子查询运用
结果计算与聚焦函数
分组查询与分组过滤
关系代数操作的实现
视图及其应用
重点:
SELECT: IN | NOT IN,ɵ some,ɵ all,Exists | NOT Exists
SELECT: 聚集函数,GROUP BY,HAVING
视图及其应用
子查询运用
定义:出现在where中的select语句被称为子查询,子查询会返回一个集合,可通过这一集合来比较确定另一集合。其语句区可分为外循环与内循环
非相关子查询: 内层查询独立进行,不涉及外层循环相关信息
相关子查询:内层需要依靠外层某些参量作为条件来进行查询。外层的参量需用外层表名/表别名限定
变量作用域原则:子查询只能由外向内传递参数
子查询:
集合成员资格:某一元素是否是某集合成员
集合之间比较:某一集合是否包含另一集合
集合基数测试:集合是否为空,是否有重复元组
(NOT)IN子查询:
IN与=some等价,但NOT IN与<> some不等价,NOT IN等价于<> all
判断某表达式的值是否在子查询结果中
Select 列名
From 表名
where 列名k in/not in (条件)//条件中筛选的列名应与列名k一致例:查询张三,李四同学信息
Select *
From Student
where Sname in ("张三","李四");//条件固定时,可直接写入查询选择了001或002课程的同学信息
Select *
From Student
where C#=‘001’
or S# in (Select S# From SC Where C#='002');(NOT)IN相关子查询
例:
Select *
From Student
where C#=‘001’
and S# in (Select S# From SC Where S#=Student.S# and C#='002');ɵ some,ɵ all子查询
表达式 ɵ some(子查询):子查询中某个值满足ɵ关系,为真
表达式 ɵ all(子查询):子查询中全部值满足ɵ关系,为真
注:ɵ any已废弃,因为其意思存在歧义-->任一/全部
例:查询学过001课程的最低成绩学生学号
Select S#
From SC
where C#=‘001’//内外层均要写明限制条件,不能只写在内层。内层仅用于筛选符合的值
and Score <= all (Select Score From SC where C#='001');查询张三的最低成绩的课程号
Select C#
From Student S,SC
where Sname="张三" and S.S#=SC.S#
and score <= all (Select score From SC Where S#=Student.S# );Exists | NOT Exists子查询
子查询结果中是否存在元组
(NOT) Exist (子查询)
其中 Exist语句可替代,Not Exist语句不易替代
检索达成全部条件的个体信息:多层not exist
检索达成至少一个条件的个体信息:一层not exist 或 一层not exist+一层exist
例:查询所有选择了张三老师课程的学生姓名
Select DISTENT Sname
From Student S
Where exist ( Select *
From Coures C,Teacher T
Where S.S#=T.S# and C.C#=T.C# and C.S#=S.S#
and T.Tname=“张三”);查询所有选择了张三老师所有课程的学生姓名
Select DISTENT Sname
From Student S
//where意思:该学生/不存在/一门张三老师的课程/未学过
Where NOT exist ( Select *
From Teacher T
Where T.Tname=“张三”and not exist
(Select * From Course C
Where S.S#=T.S# and C.C#=T.C# and C.S#=S.S# )结果计算与聚集计算
结果计算
Select 列名1,列名2,...列2 ɵ 列1,列2 ɵ 数字n
from 表1,表2...
where 条件例:计算两教师工资差值
Select T1.Tname as t1, T2.Tame as t2, t1-t2 as T
From Teacher T1,Teacher T2
Where T1.salary>=T2.salary;聚集计算
COUNT,SUM,AVG,MAX,MIN
不允许写在Where子句中
例:求所有教师的工资总和
Select SUM(T.salary)From Teacher T;分组查询与分组过滤
分组查询定义:将检索到的元组按某一条件进行分类,将符合条件的元组划分到某一集合/组中,同时处理多个组和集合的聚集计算
Select 列名1,列名2,...
from 表1,表2...
where 条件
Group by 分组条件 [Having 条件] //保留符合Having条件的分组having条件筛选分组,where条件筛选元组
例:按学号分为不同组,并求出各组平均成绩
Select C#,AVG(score)
From SC
Group by s#查询不及格课程大于2的学生学号
Select S#
From SC
Where score<60
Group by S# Having Count(*)>2;查询不及格课程数大于2的学生学号和平均成绩
Select S#,Avg(score)
From SC
Where S# in (
Select S#
From SC
Where score<60
Group by S# Having Count(*)>2;
)
Group by S# 关系代数操作的实现
并:UNION 交:INTERSECT 非:EXCEPT
ALL:保留重复元组
若子查询1重复m次,子查询2重复n次,则;
并:子查询1 Union (ALL) 子查询2 重复次数m+n
交:子查询1 Intersect(ALL)子查询2 重复次数min(m, n)
非:子查询1 Except (ALL) 子查询2 重复次数max(0, m-n)
例:检索学过001或002课程的学生学号
select S# From SC Where C#='001'
Union
select S# From SC Where C#='002'
//或者
select S# From SC Where C#='002' orC#='001'空值
属性值 is (not) null
例:年龄为空学生学号
select S# From SC Where Sage is null;//不能写=null空值处理:
空值仅能被 is (not) null查找到
空值参与计算时,表达式值为null
空值参与比较时,视为false
空值参与聚集计算时,除count(*)外均忽略null
内、外连接:
连接类型:内inner join、左外leter outer join、右外right outer join、全外full outer join
连接条件:自然连接natural、ɵ连接on 连接条件、using 属性1,属性2,..
From 表1 连接类型 表2 on 连接条件SQL扩展:
基础SQL中,Select-From-Where仅能出现在Where语句中
新标准中,Select-From-Where可以出现在任何聚集计算能出现的语句中,例如From之后
视图及其应用
SQL数据库结构:
基本表是实际存储在存储文件中的表,其数据也需要存储
视图在SQL中仅存储其导出所需要的公式,视图的数据不存储
视图的更改最终要反映在基本表的更改上
定义视图:
视图需要先定义,再使用
视图的属性名可不填写,默认为子查询的属性名
格式:create view 视图名 (属性1,属性2,...)as (子查询)
使用视图:
视图定义好后,可以像table一样使用
更新视图:
因为视图不保存数据,因此对于视图的更新最终要反映到基本表中,但有些视图是不可逆
可以更新视图的情况:
视图是从单个表中使用选择、投影操作导出,且包含主键。
不能更新视图的情况:
视图中Select目标列中包含聚集函数
视图中Select子句中使用了unique,distinct
视图中包括group by语句
视图中包括经算术表达式计算出的列
视图中由单个表的列构成,但不包含主键
更新视图时,对于缺失属性值,用null表示
例:更新学生信息视图
create view CStud(S#,Sname,Sclass)
as ( select S#,Sname,Sclass
from Student
where D#='03'
)
更新格式:Insert into CStud
Values ("98030101",“张三”,null,null,”980301”);
撤销视图:
格式:Drop view 视图名
八、SQL语言与数据库完整性安全性
内容:
数据库完整性概念与分类
列约束与表约束-静态约束
触发器-动态约束
数据库安全性概念与分类
安全性实现
数据库完整性概念与分类
数据库完整性定义:数据库在任何情况下的正确性、有效性、一致性
广义完整性:语义完整性、并发控制、安全控制、数据库故障恢复等
狭义完整性:专指语义完整性
关系模型的完整性要求:实体、参照、用户自定义完整性
为什么会出现数据库完整性问题:不当的数据库操作
数据库完整性管理作用:
防止、避免数据库中不合理数据的出现
DBMS应尽可能防止DB中出现的语义不合理现象
DBMS如何保证完整性?
DBMS允许用户自定义一些完整性(DDL)
更新DB时1,DBMS自动依据完整性约束条件进行检查,以确保新操作符合语义完整性
完整性约束规则的一般形式
Integrity Constraint ::=(O,P,A,R)
O:数据集合-约束的对象,如元组、列
P:谓词条件-什么样的约束
A:触发条件-什么时候审查
R:响应动作-不满足时怎么处理
即:在A时,检查数据O是否符合条件P,不符合则执行R
按约束对象分类:
域完整性约束条件:针对列。对于某一列所要更新的某属性值是否可以接受进行判断,孤立进行。例:Sage>17
关系/表完整性约束条件:针对元组。对于某一表中部分元组更新是否可接受,或表A某部分元组与表B某部分元组的联系是否可接受进行判断。例:90>Cscore/Csubject>60
按约束条件分类:
结构约束:针对模型。如:函数依赖性约束、主键外键约束,仅关注某属性值是否存在、数值是否相等,是否允许空值等
内容约束:来自用户的约束。如:用户自定义完整性,仅关注某属性值范围等
按约束状态分类:
静态约束:DB在任何时候均需满足的约束,如0<age<100等
动态约束:DB从A状态变为B状态需满足的约束,如:工资只能升不能降等
SQL语言支持的约束
Integrity Constraint ::=(O,P,A,R),其中O为列/表,P须自定义,A默认更新时检查,R默认为拒绝
静态约束:
列完整性-域约束
表完整性-关系约束
动态约束:
触发器
列约束与表约束-静态约束
格式:Create Table 表名1(列名1 数据类型 列约束,表约束1,表约束2.....,列名2 ....)
列约束:针对单列
Create Table 表名1(列名1 数据类型 Not null |
constrain 约束名//可省略
{ Unique//唯一
| Primary Key//主键
| check (自定义列约束条件,如:age<18)
| Reference 表名2 (列名2)//外键,若列名相同,可省略
[on delete {cascade | set null } ]
//on delete cascade:若表2中删除该属性值,则在表1中删除该元组
}
)
约束:S#非空,唯一,Ssex约束名csssex,其值为"男"或"女",D#为外键,且随表Dept变化
表约束:针对多列
位置:可放在列约束之后-->列名1 数据类型 列约束,表约束,
constrain 约束名//可省略
{ Unique (列1,列2,....)//唯一
| Primary Key(列1,列2,....)//主键
| check (自定义列约束条件,如:age<18)
| Foregin Key (列1,列2,....)//外键
Reference 表名2(列1,列2,....)
[on delete cascade ]
//on delete cascade:若表2中删除该属性值,则在表1中删除该元组
}
S#,C#为外键,当Student或course表中S#值被删除后,表SC中对应元组也会删除
check()中可加入任何where()中的语句,如:check ( C# in (Select C# from SC where C#='001'))
约束调整:
create table 定义的约束可以通过Alter table语句调整ADD,DROP,MOTIFY
Alter table 表名(ADD (列名 数据类型 列约束,表约束,.....)
| Drop column 列名
| Motify (列名 数据类型 列约束,表约束,.....)
| ADD constraint 约束名 //追加约束
| Drop constraint 约束名 //撤销约束
| Drop Primary Key //撤销主键
)实现约束方式:断言assertion
断言是一个谓词表达式,表示DB总希望满足的一个约束。表/列约束是特殊的断言
复杂断言使用过多会增加数据库负担,谨慎使用
复杂断言格式:create assertion 断言名 check (条件)
触发器-动态约束
触发器tigger是一个过程完整性约束,是一段程序,该程序可在特定时间被触发执行
create tigger 触发器名 before | after insert/delete/update [of 列名]
on 表名 [referencing corr_name_def1,corr_name_def2,...]
[ for each row | for each statement] //每一个元组/整个表操作
[ when (条件1)] //若满足,则执行下列程序
单个程序 | begin atomic 程序1;程序2;....;end意义:当某事件发生时(before/after),对该事件产生的结果(每一元组、全部元组),检查条件1若满足则执行后续程序。程序或条件引用的变量可用corr_name_def限定
before:验证还未写入前的数据
after:验证写入后的值
corr_name_def定义:{old 变量名1 | new 变量名2 | old table 表1 | new table 表2}


数据库安全性概念与分类
数据库安全性:DBMS应保证的数据库特性:免受非法、非授权用户的使用、泄露、修改与破坏
DBMS安全机制
自主安全机制:存取控制。通过权限在用户之间传递,使用户自主管理数据库安全性
强制安全机制:通过对用户与数据的强制分类,使不同等级用户可以访问不同等级数据
推断控制机制:防止通过历史信息、公开信息推断出私密信息
数据加密存储机制:通过加解密保证数据安全性
DBA责任:划分数据安全级别,用户安全级别
自主安全机制:
一般通过授权机制实现
访问规则:AccessRule ::=(S,O,T,P)//用户,访问对象,访问权利,谓词
AccessRule通常存在数据字典或系统目录中
用户多时,可按用户组建立访问规则
访问对象可大可小:属性、元组、关系、数据库
权利:创建、增删改查等
两种控制示例
按名控制安全性:存储矩阵

视图
通过视图限制用户对某些数据的存取,在定义好视图后,该视图也可以作为一个新的数据对象
如:create view empv1 as select s# from Employee where P#=:userid <--条件P
安全性实现
SQL中用户级别:超级用户DBA-->账户级别(程序员用户)-->关系级别(普通用户)
级别1:读select
级别2:更新modify,可使用insert,delete,update等
级别3:创建create,可使用create,alter,drop等
授权命令:
授权视图权利不等于基本表的访问权利
授权的权利必须是授权者已拥有的权利
grant all privilieges | priviliege1,priviliege2,....//priviliege即级别1,2,3中的权利
on [table] 表名|视图名
to public | user-id1,user-id2,....
with grant option //允许二次授权收回授权命令:
revoke all privilieges | priviliege1,priviliege2,....//priviliege即级别1,2,3中的权利
on 表名|视图名
from public | user-id1,user-id2,....授权传播范围:
水平传播数量:授权者的再授权者数量
垂直传播数量:授权者A-->用户B-->用户C.....指授权的传播深度
不同DBMS的授权范围不同,SQL中未设置
强制安全性
分类:绝密,机密,可信,无分类
访问规则:
低级别用户不能读高级别数据
高级别用户不能改低级别数据,会引起数据级别的上升
强制安全性的实现:
DBMS通过扩展关系模式实现强制安全性
原模式:R(A1:D1,A2:D2,....An:Dn)
扩展后:R(A1:D1:C1,A2:D2:C2,....An:Dn:Cn)//Ci为安全级别
九、嵌入式数据库语言-基本技巧
内容:
嵌入式sql语言概述
变量声明与数据库连接
数据集与游标
可滚动游标与数据库增删改
状态捕获与错误处理机制
嵌入式sql语言概述
嵌入式语言特点:
新增引导词,以便于SQL语句预编译为编译器语言。如:C语言编译器引导词exec sql select...
into子句,将select结果赋给由“:”引导的程序变量。如:select Sname into : vSname from...
变量声明与使用
嵌入式SQL中可出现宿主语言使用的变量,但须提前声明
//声明
exec sql begin declare section:
char vSname[10],specName[10]=“张三”;//宿主语言中,字符串长度+1
int vSage;
exec sql end declare section;
//此处可给变量赋值
select Sname,Sage into : vSname ,:vSage from Student where Sname=:specName;连接/断开数据库,SQL提交/撤销:
//连接数据库
exec sql connect to 数据库名 as 连接名 user 用户名;
exec sql connect to default;
//断开数据库
exec sql disconnect to 连接名;
exec sql disconnect to current;
//SQL提交
exec sql commit work;
//SQL撤销
exec sql rollback work;事务:
一条或多条数据库语句的执行。是DBMS提供的控制数据库操作的方式,保证数据库系统能提供一致性的状态转换
事务格式:
begin transaction//可省略
exec sql ...
exec sql ...
exec sql commit | rollback work
end transaction//可省略事务特性:
原子性:事务不可中断
一致性:DBMS保证事务的操作状态正确
隔离性:保证多个并发事务互不影响
持久性:保证已提交事务影响是永久的
数据集与游标
读取单行结果:
into子句,将select结果赋给由“:”引导的程序变量。
格式:select 属性1 into : 变量1 from...
读取多行结果:
游标Cursor:指向某检索记录集的指针,每读一行就处理一行
使用步骤:定义-打开-处理数据-关闭,游标可多次打开和关闭
格式:
exec sql dlare 游标名 cursor
for select 属性1,属性2... from 表1,表2... where 条件;
order by 属性i
for read only | update of 属性1,属性2,... //定义
exec sql open 游标名;
exec sql fetch 游标名 into :变量名1,:变量名2,.....;//逐行处理
... ...
exec sql close 游标名;可滚动游标与数据库增删改
可滚动游标:
可重复访问每条记录的游标,由ODBC支持使用
格式:
exec sql fetch 移动位置 游标名into :变量名1,:变量名2,.....;
移动位置包括:
next:下一条
prior:上一条
first:首行
last:末行
absolut 数字n:指定检索第n条
relative 数字n:上/下移动n条
数据库删除:查找删除与定位删除
exec sql delete from 表名 where 删除条件 | current of 游标名;
数据库更新:查找更新与定位更新
exec sql update 表名 set 列名=表达式 where 更新条件 | current of 游标名;
数据库插入:只有一种
exec sql insert into 表名 (列名....) value ('值',....) select 属性 from.....;
状态捕获与错误处理机制
状态嵌入式sql的执行状态,尤其是出错状态
状态捕获及处理:
设置sql通信区:程序开始时设置,SQLCA:通信区
exec sql include sqlca;
设置状态捕获语句:可多次,在任何位置设置,但有作用域
exec sql sqlerror goto report_error;
设置状态处理语句:应对sql操作的某种状态
report_error: exec sql rollback;
状态捕获语句:
设置一个陷阱,对后续所有exec sql引起的数据库改变加以判断,若满足条件,则执行处理
范围:其后续编写的所有exec sql,直到下一条whenever语句为止,与编写顺序有关,与执行顺序无关
格式:exec sql whenever 条件 处理;
条件:
sqlerror:语句出错
not found: 执行某exec sql语句后,对应结果未出现
sqlwarning:警告
处理:
contune:忽略,继续执行
goto 标记: 转至标记语句,执行后序处理
stop:终止程序,撤销操作,断开数据库连接
do 函数| call 函数:调用函数处理,返回后继续执行后序语句
注意问题:容易重复执行错误语句,引发无限循环
解决方式:在错误处理方案中加入语句:exec sql whenever sqlerror contune,跳过出错语句,执行下一句
记录状态信息方法:
sqlcode:=0-执行成功,<0错误,>0警告
sqlca.sqlcode
sqlstate
显式状态:需要明确错误类型
隐式状态:只需知道出现了错误,不管错误类型
显式状态处理:
须先中止上一条whenever的作用域,且让语句在出错后执行下一条,也就是错误处理程序
exec sql whenever goto error_deal;
exec sql ....
... ...
exec sql whenever sqlerror contune;
exec sql create table cs(S# char(10),......)....
if(strcmp(sqlstate,"82100")==0)//处理82100错误程序十、嵌入式数据库语言-动态SQL
内容:
SQL语言的动态改造
动态SQL语言执行方式
数据字典与SQLDA
ODBC/JDBC简介
SQL语言的动态改造

程序构造:
写出基本语句sqitext、字符串前后加单引号strcat、条件之间添加and等连接符、数值型变量须转为字符型dtoa
#include <stdio.h>
#include "prompt.h"
//将用户输入数据存入以下变量中
char Vcname[];
char Vcity[];
double range_from,range_to;
int Cname_chose,City_chose,Discnt_close;
Cname_chose=0, City_chose=0, Discnt_close=0;//判断用户是否输入了cname、city与rang范围
int sql_sign=0;
char continue_sign[];//用于判断是否结束语句
exec sql include sqlca;
exec sql begin declare section;
char user_name[20],user_pwd[20];
char sqitext[]="delete from customers where";//字符串初值,where条件可在后续strcat语句中补充
exec sql end declare section; // strcat:追加拷贝,将此句中值与上一句连接在一起
int main()
{
exec sql whenever sqlerror goto report_error;//错误捕获语句
strcpy(user_name,"poneilsql");
strcpy(user_pwd,"XXXX");
exec sql connect :user_name identified by :user_pwd;//数据库连接
while(1){
memset(Vcname,'\0',20);
memset(Vcity,'\0',20); //初始化
if(GetCname(Vcname)) //获取Cname值
Cname_chose=1;
if(GetCity(Vcity()) //获取City值
City_chose=1;
if(GetDiscntRange(&range_from,&range_to))//获取Discnt区间值
Discnt_chose=1;
if(Cname_chose) //若输入了Cname,则构造sqltext
{
sql_sign=1;
strcat(sqltext,"Cname=\' "); //补充之前字符串中的条件:Cname='Vcname',其中的\为转义字符
strcat(sqltext,Vcname);
strcat(sqltext," \' ");
}
if(City_chose)//若输入了City,则构造sqltext
{
sql_sign=1;
if(Cname_chose) //判断在此之前是否已经有了一个条件,有则加上“and”
strcat(sqltext,"and City= \' ");
else
strcat(sqltext, "City= \' ");
strcat(sqltext,Vcity);
strcat(sqltext," \' ");
}
if(Discnt_chose)//若输入了Discnt,则构造sqltext
{
sql_sign=1;
if(Cname_chose=0 and City_chose =0)//判断在此之前是否已经有了一个条件
strcat(sqltext, "discnt > \' ");
else
strcat(sqltext, "and (discnt > \' ");
strcat(sqltext,dtoa(range_from));//dtoa: int转char
strcat(sqltext," and (discnt< ");
strcat(sqltext,dtoa(range_to));
strcat(sqltext,")");
}
if(sql_sign)
{
exec sql execute immediate :sqltext;//开始执行sqltext
exec sql commit work;//提交改动
}
scanf("continue(y/n)%1s",continue_sign)//让用户确认是否结束
if(continue_sign="n"){
exec sql commit release;//提交并断开连接
return 0;
}
}//while结束
report_error:
print_dberror(); //输出错误,撤销
exec sql rollback release;
return 1;
}//main 结束界面要素及其变量:
复选框:框名.checked//=true,选中;=false,未选中
文本框:框名.text//键盘输入的内容,待显示内容
例:
if(id,checked=true and len(trim(name.text))>0) then
if(firstflag=1) then
str_temp=str temp + " and (sname like'" + trin(name.text)+" ') ";
else
str_temp=str temp + " (sname like'" + trin(name.text)+" ') ";
firstflag=1;
... ...动态SQL语言执行方式
两种方式:
立即执行语句:运行时编译并执行
exec sql execute immediate :host_variable;Prepare-Execute-Using语句:Prepare语句先编译,编译后允许动态参数,Execute执行,用using语句将参数传入编译好的SQL语句中
exec sql prepare sql_temp from :host_variable;
... ...
exec sql execute sql_temp using :cond_variable;数据字典与SQLDA
数据字典:
系统中一些表和视图的集合,存储了数据库中各类对象的定义信息,这些信息又称“元数据”--关于数据的数据
数据字典又称系统目录、系统视图、目录表
DBA可以通过特殊的SQL命令访问公开的部分数据字典
构成:关系相关信息、用户账户信息、统计与描述性数据、物理文件组织信息、索引相关信息
结构:也是存储在磁盘上的信息,但可以专为内存的快速访问设计特定的数据结构
SQLDA:
SQL描述区:一个内存数据结构,可装载关系模式的定义信息,如列的数目,每列的名字类型等
ODBC/JDBC简介
ODBC:
是一个不同语言与不同数据库之间通讯的标准,是一组API支持应用程序与数据库服务器的交互
应用程序通过ODBC与API,实现:
与数据库的连接
向数据库服务器发送SQL指令
逐条提取数据库检索元组并赋值给应用程序中的变量
应用程序如何通过ODBC连接至数据库:
确认DBMS Driver被安装至ODBC环境中后,应用程序调用ODBC API时,ODBC API先调用DBMS Driver库函数,库函数与数据库服务器通信,执行请求并返回结果
int ODBCexample()
{
//分配数据库连接环境
retcode error;//返回状态?
Henv env;//环境变量
HDBC conn;//连接句柄
SQLAllocEnv(&env);
SQLAllocConnect(env,&conn);
//打开一个数据库
SQLConnect(conn,"aura.bell-labs.com",SQL_NTS,"avi",SQL_NTS,"avipasswd",SQL_NTS);
//与数据库通讯
... ...
//断开连接,释放环境
SQLDisConnect(conn);
SQLFreeConnect(conn);
SQLFreeEnv(env);
}应用程序如何与数据库通讯:
SQLExecDirect():向数据库发送SQL命令
SQLFetch():获取产生的结果元组
SQLBindCol():绑定程序变量与结果中的属性,其参数为:
stmt:查询结果中的属性位置
SQL到C的类型编号,变量地址
对于可变长度类型数据,应给出:最大长度、获取单个元组后的实际长度的地址(长度为负时,表示空值)
//分配一个与指定数据库连接的新句柄
char branchname[80];
float balance;
int lenout1,lenout2;
HSTMT stmt;
SQLAllocStmt(conn,&stmt);
//执行查询,stmt句柄指向结果集合
char *sqlquery="select branch_name,sum(balance)
from account
group by branch_name";
error=SQLExecDirect(stmt,sqlquery,SQL_NTS);
//绑定高级语言变量与stmt句柄中的属性
if(error==SQL_SUCCESS){
SALBindCol(stmt,1,SQL_C_CHAR, branchname,80,&lenout1);
SALBindCol(stmt,2,SQL_C_FLOAT,&balance, 0,&lenout2);
//提取一条记录,结果数据存入高级语言变量中
while(SQLFetch(stmt)>=SQL_SUCCESS){
printf("%s %g\n",branchname,balance);
}
}
//释放句柄
SQLFreeStmt(stmt,SQL_DROP);ODBC其他功能:
动态SQL语句预编译-动态参数传递
获取元数据特性:数据库中所有关系的特性及各结果列名字与数据类型
默认:每条SQL语句均被作为独立的事务提交处理
应用程序可以关闭一个连接的自动提交特性:
SQLSetConnectOption(conn,SQL_AUTOCOMMIT,0);
此时,事务需显式给出提交与撤销目录
SQLTransact(conn,SQL_COMMIT);
SQLTransact(conn,SQL_ROLLBACK);
JDBC
java版ODBC
常用API:
java.sql.DriverManager:处理驱动调入,为数据库连接提供支持
java.sql.Driver:通过驱动进行数据库访问
java.sql.Connection:特定数据库连接
Try(...) Catch(...):异常捕获与处理
java.sql.Statement:执行SQL语句
java.sql.PreparedStatement:执行预编译SQL语句
java.sql.CallableStatement:执行数据库内嵌过程调用
java.sql.ResultSet:返回结果
JDBC访问数据库过程:
打开一个连接,创建Statement对象,设置查询语句,对Statement对象执行查询语句,发送查询给数据库并返回结果给应用程序;错误捕获与处理


嵌入式,ODBC,JDBC的比较
嵌入式:建立连接,声明游标,打开游标,获取一条记录(循环),关闭游标,断开连接
ODBC:建立连接,分配语句句柄,用句柄执行SQL,将高级语言变量与句柄属性对应,获取一条记录(循环),释放语句句柄,断开连接
JDBC:建立连接,创建语句对象,用语句对象执行SQL并返回结果对象,(从结果对象中获取一条记录,将对象属性值传给高级变量)(循环),释放语句对象,断开连接
十一、数据建模-思想与方法
内容:
E-R模型-建模基本思想
E-R模型-Chen表达方法
E-R模型-Crow's foot方法
数据库设计的抽象
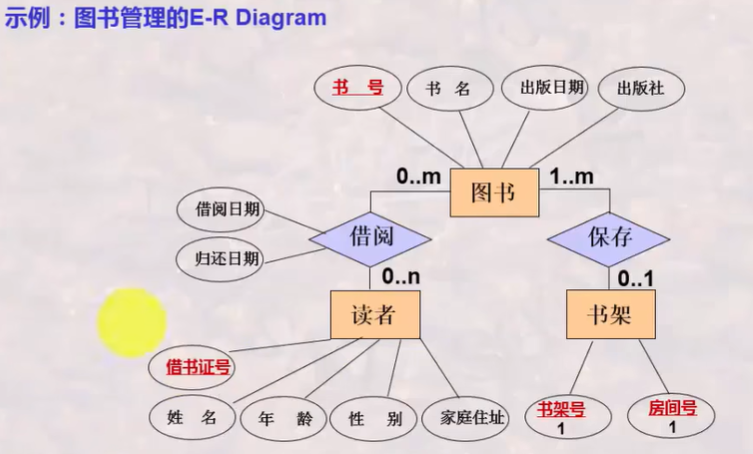
E-R模型-建模基本思想
E-R模型基本概念
实体:单个存在且可相互区分的事务
实体概念分为实体与实例。
实例指单个个体。而实体指某一类具有相似特性的实例,如:读者
属性:实体所具有的某方面特性
分类1:单一属性与复合属性,如家庭住址--省份+详细住址。
分类2:单值属性与多值属性,如张三有多个电话号码
在关系模型中,后者均需转化为前者(第一范式)
分类3:可空值属性,非空值属性
分类4:导出属性,可由其他属性计算得出,如年龄差值
联系:某个实体的实例与其他实例的联系,如某位读者借阅了某本图书
实体是相对稳定的,但联系是多样的
角色:实体在联系中的作用
度/目:参与联系的实体数目,分为一元联系,二元联系,多元联系
如:一元联系:同一实体中的联系,如零件A与零件B
二元联系-读者与图书
三元联系-供货商,零件,工程项目
联系的基数:实体实例之间联系的数量,分为一对一(1:1)、一对多(1:m)、多对多(m:n)
联系常用最小/最大基数来标记
(最小...最大基数):如书架参与图书存放联系基数为(0..m),图书参与图书存放联系基数为(1..1)
完全参与联系:最小基数为1
部分参与联系:最小基数为0
关键字:实体中能用其值唯一每一个实例的属性或属性组合,如序号
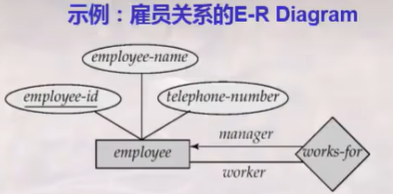
E-R模型-Chen表达方法
chen方法基本图元
实体:矩形框
属性:椭圆
多值属性:双线椭圆
导出属性:虚线椭圆
联系名称:菱形框
关键字:下划线
复合关键字:下划线下标记相同数字
多组关键字:下划线下标记不同数字
连接线:
实体-属性:直线
实体-联系:直线
联系-属性:直线
角色:直线上标记文字
1:1联系:箭头直线
1:m联系:箭头-无箭头直线
m:n联系: 无箭头直线
也可不加箭头,在直线末端标记数量
部分参与联系:单直线
完全参与联系:双直线
也可不加箭头,在直线末端标记 最小...最大基数
注意:
每个实体都需给出关键字
联系可能也需要属性
联系与实体的连线代表实体的关键字要作为联系的属性
表示一元联系:
E-R图建模步骤:
理解需求,寻找实体。找出所有需求涉及到的,可独立管理的事务,作为实体。
用属性刻画各实体,至少给出重要属性,但不要涉及其他实体。如:仓库实体中不要出现零件,零件实体中也不要出现仓库
确定各实体关键字
分析实体间联系(重点),标出各联系属性。若某实体不与包括其自身在内的任何实体存在联系,则该E-R图不合适
标出联系基数,不同基数可能导致不同设计方案
检查是否完全覆盖了需求
E-R模型-Crow's foot方法
Crow's foot方法基本格式
实体:矩形框,实体名写在横线上方
属性:写在矩形框横线下方
关键字:属性名下加下划线
联系:菱形框或联系名表示
联系基数:若为一元联系,则使用虚线

数据库设计的抽象
三个世界与多层抽象:
现实世界-->(描述、抽象为)信息世界-->(描述、抽象为)计算机世界
现实(客观存在)-->抽象/概述(概念/观念)-->计算机中(计算机实现)
型与“型的型”:
“型与值”的进一步抽象,将无限延伸或无法枚举的情况抽象为可有限描述的概念
越抽象,语义信息越少,概括性越高,越反映共性信息
检验抽象正确性方法:既能将现实抽象(抽象化),也能依据抽象的信息与抽象规则还原出被抽象事物(具体化)
数据模型:
现实的抽象与描述需遵循统一的数据模型:统一的概念与统一的表达方法
数据模型是一组相互关联且被严格定义的概念集合,即一组概念+其关联性
十二、数据建模-工程方法与案例分析
内容:
IDEF1x两种实体的区分
IDEF1x标定联系与非标定联系
IDEF1x的非确定联系
IDEF1x的分类联系
IDEF1x两种实体的区分
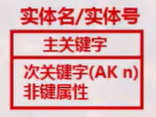
实体分类
独立标识符实体/独立实体/强实体
从属标识符实体/从属实体/弱实体
独立实体:主关键字不包含外来属性的实体。其实例可被唯一标识,且不取决于其他实体的联系
格式:直角矩形框,实体名/实体号写在矩形框上方,主码写在第一栏,无外键
从属实体:主关键字包含了外来属性的实体。其实例的标识取决于它与其他实体的联系,如:合同条目需要合同来标识
从属实体需要从其他实体中继承属性作为关键字的一部分
格式:圆角矩形框,矩形框,实体名/实体号写在矩形框上方,主码写在第一栏,FK代表外键
独立实体 | 从属实体 | 属性类型 |
|

| FK:外键,继承属性 (别名/作用名,继承属性名,FK) AK i:候选码,数字代表候选码种类 |
属性规则:
最小关键字规则:主/次关键字属性(组)去掉任一属性后,均无法再唯一标识实例
完全依赖函数规则:主/次关键字属性(组)必须全部确定,非键属性才能唯一确定
非传递依赖规则:非键属性值仅取决于键值属性,不由其他非键属性决定
外来关键字:一个联系只能用一个外键;外键只能来自于其他实体的主属性(组)
联系:
可标定连接联系
非标定连接联系
分类联系
非确定联系
IDEF1x标定联系与非标定联系
通过属性继承来实现两实体联系
标定联系:子实体实例取决于其与父实体的联系。父实体关键字是子实体关键字的一部分。
非标定联系:子实体实例可以被唯一标识,不取决于其与父实体的联系。父实体关键字不是子实体关键字的一部分。
标定联系 | 非标定联系 | 子实体一侧有圆圈,联系名写在直线旁 |

|

| 标定联系:FK写在键值属性中,实线连接 如:零件(零件序号n)-零件工序(零件序号n+工序序号m) 非标定联系:即FK写在非键属性中,虚线连接 如:顾客(顾客号)-合同(合同号,顾客号) |
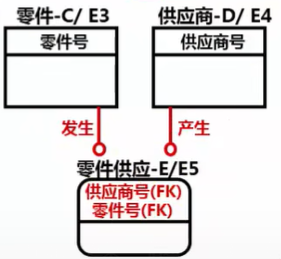
IDEF1x的非确定联系
实体间多对多联系。须通过引入相交/相关实体,将其分为多个一对多联系来表达
如:零件+供应商<--零件供应
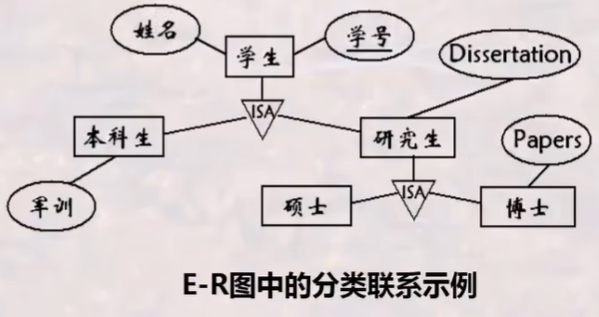
IDEF1x的分类联系
一个实体实例由一个一般实体+多个分类实体组成
分类联系不等于分类,分类联系的各类别需要有自己的独有属性
一般实体:若干个具体实体的类
分类实体:主键与一般实体相同,除具有一般实体特征外,也具有其他的独有特征(必须)
如:零件(一般实体)分为:自制件与外购件(分类实体),这两者不仅具有零件的属性,也有其自身独有的属性
具体化与泛化:
具体化(强调差异):实例集中,某些子集具有区别于其他子集的特性,依据这些特性对该实例集进行的分组/分类
泛化(强调相似):若干实体依据共有的特证,合成一个更高层的实体
ISA三角:用于标识高层实体与低层实体间的“父类-子类”联系,且分类属性中不需要再写关键字属性
完全分类联系 | 非完全分类联系 | |

|
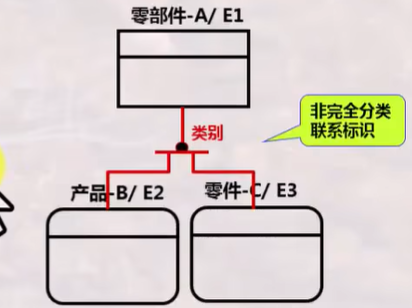
| 完全分类:子类集合之和=父类集合 非完全分类:子类集合之和<父类集合 |
十三、数据库设计过程
内容:
数据库设计过程与方法
E-R图/IDEF1x向关系模式的转换
不正确数据库引发的问题及解决方法
需求分析
以企业数据库为例
步骤:
了解部门-岗位划分
对每一岗位收集“源”,形成源表
理解各个“源”的构成、处理规则及其属性的处理规则
提交需求分析报告,包括:
企业部门-岗位划分
形成各种报表的基础数据表
各种数据表间的处理关系(what-how)
围绕业务表的处理关系(who-when--where)
可能但尚未实施的需求
最终:形成“源”清单、“属性”清单及详细描述。尤其是业务规则与属性处理规则
“源”清单
总序号 | 源表名称 | |
001 | 处理及存档要求 | |
源表属性名表 | ||
总序号 | 源表名称 | |
... | ... |
“属性”清单
局部序号 | 属性名称 | 全局序号 | 属性统一名称 | 对应源序号 | ||
英文 | 中文 | 英文 | 中文 | |||
属性定义表
统一序号 | 属性含义 | 属性建库要求(类型/长度/取值含义) |
如:工资只升不降,分类标准及规则等 |
概念数据库设计
识别实体与联系
用E-R/IDEF1x图表达业务规则
定义实体、联系、实体属性组成
提交数据库设计报告,包括
各实体的发现、划分、定义
各实体属性的发现、分析、定义
各实体联系的发现、分析、定义
外部视图与概念视图的定义
两种思路:
先局部后全局,先全局后局部
局部E-R模式设计:
确定局部结构范围,实体定义,联系定义,属性分配
全局E-R模式设计:
确定公共实体类型,合并各个局部E-R模式,检查消除冲突
消除冲突:
属性冲突:
属性类型,取值范围不同,如:不同地区编号方式不同
属性取值单位冲突,如:磅-千克
结构冲突:
同一对象在不同应用中抽象不同,如职工在应用A中为实体,应用B中为属性
同一对象在不同E-R图中属性组成不同
实体间联系在不同E-R图中类型不同
命名冲突:
同名异义
异名同义
全局E-R模式优化:
合并实体类型,消除冗余属性,消除冗余联系
绘制不同层级的E-R/IDEF1x图
实体图:以实体为建模单位,仅包含实体与联系
键值图(常用):以实体为建模单位,并标注键值
完整图:以实体为建模单位,标注所有属性
实体定义表:
统一序号 | 实体含义 | 实体建库需求 |
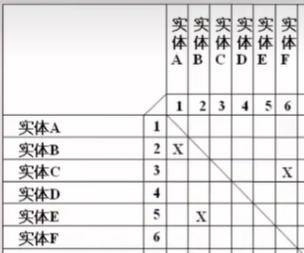
实体-联系矩阵:
实体-属性矩阵:

逻辑数据库设计
E-R/IDEF1x图向关系模型转换
检查逻辑数据库设计的正确性
定义全局模式与外模式
逻辑数据库设计报告,包括:
E-R/IDEF1x转换为逻辑模式
遵循关系范式的设计原则
注意折中,提醒开发者和使用者可能存在的问题
给出外模式、概念模式定义
E-R图 ->关系模式转换规则
实体->关系
联系->关系的属性
关键字->关系关键字
复合属性+分量->只保留属性或各个分量
如:出生日期-年、月、日->保留出生日期或年、月、日属性
多值属性->多值属性+所在实体关键字,组成新关系,即新增一张表
如:学生(学号,姓名,所选课程)->学生(学号,姓名)+选课(学号,所选课程)
联系转换
一对一:
双方均部分参与(0....n),将联系作为一个新关系,其属性为双方关键字
其中一方A全部参与(1...1),将另一方B关键字作为关系A的属性
一对多:
将单方(1..1)的关键字作为多方(1...n)关系的属性
多对多:
将联系定义为新关系,属性为双方关键字
弱实体转换:弱实体关键字=弱实体自身的区分属性(主键)+所依赖实体的关键字
如:产品关键字=产品序号+公司序号
泛化与具体化实体(高、低层实体)转换:
泛化、具体化实体分别转变为不同关系
具体化实体的关系中,一定包含泛化实体的全部关键字,可以不包含其他属性
若两者是完全分类关系,则可以不创建泛化实体。如:学生仅有本科生,研究生两种分类,则可以不创建“学生”关系
多元联系转换:
可以创建一个新关系,其关键字为该联系中所有实体的关键字
可以创建一个新关系,其关键字为一个新增的“区分属性”,其他实体关键字作为非键属性
如:供应商-零件-工程项目,三者为“供应”联系
法1:供应(供应商,零件,工程项目,数量)
法2:供应(条目号,供应商,零件,工程项目,数量)
区别:法1中三个关键字属性均不能为空,法2中这三个属性可以为空
IDEF1x图 ->关系模式转换规则
只需将实体转为关系,不用考虑联系
图中分类联系与E-R中泛化、具体化规则相同
图中复合属性、多值属性与E-R中规则相同
不正确数据库引发的问题及解决方法
可能的问题
非受控冗余:非主属性之间存在依赖,改一方,另一方必须要手动修改
如:学生(学号,姓名,班主任,班主任职称)中,当某班主任职称变化时,所有含该班主任的元组是否能同步更新?
受控冗余:作为外键,联系另一实体,获得相应的属性
插入异常:插入的数据违反了数据库对象的规定,而导致插入不正确的异常结果
如:在约束为非空的列插入空值;
在有三列的表中插入四个值的行
删除异常:指的是当需要删除的时候,数据不能被删除而导致的删除错误
如:当表中有外键限制,删除可能会出现错误;
删除某一数据可能会导致与此数据关联的多个数据遭到删除
修改/更新异常:指的是当更新数据的时候,数据不能被更新而导致的错误
如:更新一个自增列
解决方法:
数据库设计满足规范:由DBMS或数据库本身解决
数据库设计不满足规范:由使用者自己解决
规范数据设计理论:数据依赖理论、关系范式理论、模式分解理论
物理数据库设计
利用DBMS创建数据库/表
确定物理存储方式与存储空间
创建索引、视图等
提交物理数据库报告,包括
DBMS选型
确定数据库存储结构,文件类型。如:定长/不定长文件;堆文件、散列文件,B-Tree文件等
用Tiggers,设计完整性约束
确定数据库高效访问方式
评估设置磁盘空间
设置用户视图与访问控制规则
设计备份与恢复措施
十四、函数依赖及其数理定理
内容:
函数依赖
完全函数依赖与传递函数依赖
函数依赖的定理公理
函数依赖集的最小覆盖
函数依赖
X->Y:
概念
设 R 为任一给定关系,如果对于 R 中属性 X 的每一个值,R 中的属性 Y 只有唯一值与之对应。X 称为决定因素,Y为依赖因素。即:属性值X相同时,Y一定相同
例:学生的学号,姓名在一般情况下都能决定年龄,班级。但在出现重名情况时,学号唯一,姓名不唯一,故在此情况下,年龄,班级仅依赖于学号,不依赖于姓名
函数依赖特性
X->Y, Y¢X:非平凡函数依赖,即X不可以推导出自己的属性值
X->Y,则X相等时,Y相等,X为决定因素
X->Y,Y->X, 记作:X<->Y
X->Y,若基于关系模式R成立,则对该模式中任一关系均成立
若关系S的所有元组中X值均不同,则X->Y恒成立
完全函数依赖与传递函数依赖
完全函数依赖;对于任一X真子集X',均不存在X'->Y,记为X ->(f) Y
例:成绩只能由{学号,课程号}共同决定,而不能仅由学号或课程号决定
部分函数依赖:对于某个X真子集X',存在X'->Y,记为X ->(P) Y
部分依赖存在非受控冗余
传递函数依赖:关系模式中,出现非主属性决定非主属性的情况
如:在关系R(学号,宿舍,费用)中,主键为学号,通过{学号}可以得到{宿舍},通过{宿舍}可以得到{费用},而反之都不成立,则存在传递依赖{学号}->{费用}
候选键:K为关系R(U)上属性(组),若K ->(f) U,则K为候选键
超键:K为候选键,K属于S,则S为超键
超键,候选键关系:在关系中能唯一标识元组的属性集称为关系模式的超键,不含有多余属性的超键称为候选键
逻辑蕴涵:若能从函数依赖集F中推导出X->Y,即为F逻辑蕴涵X->Y, X->Y逻辑蕴涵于F,记作F |= X->Y
闭包:被F逻辑蕴涵的所有函数依赖集合,记作F+
若F = F+,则F是一个全函数依赖族(函数依赖完备集)
例:R=ABC , F{A->B,B->C},则F+由如下形式的X->Y组成:
X为A,Y任意,如:ABC->BC,AB->BC,A->C...
X含B不含A,Y不含A、B,如:BC->C, B->C...
X->Y为C->C, C->Ø
函数依赖的定理公理
引理1 Armstrong公理:
在关系模式R(U,F)中,U为属性集,F为函数依赖,则:
A1自反律:若Y⊆X⊆U,则X->Y∈F
A2增广律:X->Y∈F,Z⊆U,则(XZ->YZ) ⊆U。XZ=>X的属性加上Z的属性
A3传递率:X->Y∈F,Y->Z,则X->Z ∈F
引理2 Armstrong推论/定理:
合并律:X->Y,X->Z,则X->YZ
伪传递率:X->Y,WY->Z, 则XW->Z
分解律:X->Y, Z⊆Y, 则X->Z
引理3 : A1,A2,A3...An为属性,当且仅当X->Ai , i=1,2,...n时,X->A1A2,....An
属性闭包:对于R(U,F), X⊆U, U={A1,A2,A3...An}
令X+F={ Ai | 可用Armstrong公理导出 X-> Ai }
可以理解为X+表示所有X可以决定的属性
X⊆X+F
引理4:当且仅当Y⊆X+F时,X->Y恒成立
公理有效性:通过公理推出的结论是有效的
公理完备性:被F逻辑蕴涵的所有函数依赖均能由公理A1A2A3在F上推出
计算属性闭包
设要求的闭包属性集是Y,把Y初始化为X.
检查函数依赖集F中的每个函数依赖A->B,如果属性集A中的所有属性都在Y中,而B中有属性不在Y中,则将其加入到Y中。
重复第二步,直到没有属性可以添加到Y中为止。最后得出的Y就是X+。
函数依赖集的最小覆盖
覆盖:对R(U)上的两个函数依赖集F,G,若F+ = G+,则称F G等价,或F覆盖G,G覆盖F
引理 5:F+ =G+ <=> F⊆G+ ∧ G ⊆ F+
验证F,G等价?
即验证对任一X->Y ⊆ F,+是否存在X->Y ⊆ G+,由引理4转化为检验是否Y⊆ X+
引理 6:每个函数依赖集F均可由其右端至多有一个属性的函数依赖集G覆盖
最小覆盖:
F中每个函数依赖的右部都是单个属性
对任何X->A ∈F,都有F-{X->A}不等价于F
对任何X->A ∈F,Z⊆F,都有{ F-{X->A} }∪ { Z->A }不等价于F
即:
F中的每个“->”右侧都是单个字符;
去掉F中的任意依赖,F都不再等价于自身
去掉F中的任意依赖,且补上该依赖中含有的一部分属性依赖后,F仍不等价于自身
十五、关系模式设计之规范形式
内容:
关系第一、二范式
关系第三范式、Boyce-Code范式
多值依赖及其公理定理
关系第四范式
关系第一、二范式
第一范式:若R(U)中各分量均为不可分数据项,则R(U)符合第一范式,记作R(U)∈1NF
即:属性不可拆分
不符合第一范式处理:
将复合属性处理为简单属性
将多值属性与关键字组成新关系
引入面向对象的数据模型
第二范式:R(U)∈1NF且U中没他非主属性均完全依赖于候选键,则R(U)符合第二范式,记作R(U)∈2NF
即:非键属性必须由所有候选键共同决定
消除了非主属性的部分依赖,消除了非受控冗余
不符合第二范式处理:将该关系拆分为多个新关系
关系第三范式、Boyce-Code范式
第三范式:R(U,F)∈3NF且不存在非主属性对于码的传递函数依赖,则R(U,F)符合第三范式,记作R(U,F)∈3NF
消除了非主属性对于码的传递函数依赖,所有的非键属性都必须和每个候选键有直接相关。
即:非键属性只能由若干个候选键决定,不能由非键决定
不符合第三范式处理:将该关系拆分为多个新关系
BCNF:R(U,F),X→Y ∈F时,X中一定含有键
即:每个函数依赖的决定属性中都含有键
消除了主属性对候选码的部分和传递函数依赖
BCNF分解:
左侧不含候选键的依赖各自单独组成一个关系
左侧含候选键的依赖一起组成一个关系
多值依赖及其公理定理
多值依赖:设R(U)是属性集U上的一个关系模式。X、Y、Z是U的子集,并且Z=U-X-Y。关系模式R(U)中多值依赖X->->Y成立,当且仅当对R(U)中任一关系r,给定的一对(X,Z)的值,有一组Y的值,这组值仅仅决定于X的值而与Z值无关。
即:X值唯一时,有一组Y值(y1,y2,....)与之对应
多值依赖性质(Armstrong公理及引理):
多值依赖具有对称性。即若X->->Y,则X->->Z,其中Z=U-X-Y
多值依赖具有增广性。即若X->->Y,V⊆W,则WX-->VY
多值依赖具有传递性。即若X->->Y,Y->->Z,则X->->Z-Y
函数依赖可以看做多值依赖的特殊情况。即若X->Y,则X->->Y
多值依赖合并律:若X->->Y,Z⊆Y,W->Z,W ∩ Y=Ø,则X->Z
多值依赖伪传递率:若X->->Y且WY->->Z,则X->->Z-WY
多值依赖分解律:若X->->Y,X->->Z,则X->->Y∩Z
混合伪传递率:若X->->Y,X->->Z,则X->->Y-Z,X->->Z-Y
若X->->Y,X->->Z,则X->->YZ
多值依赖与函数依赖区别:
多值依赖的有效性与属性集的范围有关。若X->->Y在U上成立,则在W(XY⊆W⊆U)上一定成立;反之则不然,即X->->Y在W(W⊂U)上成立,在U上并不一定成立,这是因为多值依赖的定义中不仅涉及属性组X和Y,而且涉及U中其余属性Z。
若函数依赖X->Y在R(U)上成立,则对于任何Y'⊂Y均有X->Y'成立,而多值依赖X->->Y若在R(U)上成立,却不能断言对于任何Y'⊂Y有X->->Y'成立。
关系第四范式
第四范式(4NF):满足BCNF,且关系中不含有多值依赖。
4NF一定是BCNF
弱BCNF仅含有函数依赖,则BCNF一定是4NF
弱第四范式(W4NF):满足3NF,且关系中不含有多值依赖。
十六、关系模式存在的问题
内容:
模式分解存在的问题
无损连接分解及其检验算法
保持依赖分解及其检验算法
无损连接或保持依赖的分解算法
连接依赖与第五范式
模式分解存在的问题
模式分解:将R(U)用它的一组子集{R1(U1)...Rn(Un)}来代替,其中Ui,Uj可能存在若干相同属性,但Ui不属于Uj
将这组子集对ρ的投影记为:m ρ(r)=π R1(r)⋈π R2(r)⋈....π Rn(r),其中r为原关系
分解的无损连接性:R与ρ在数据内容是否等价?
分解的保持依赖性:R与ρ在函数依赖是否等价?
无损连接分解不一定为保持依赖分解
保持依赖分解不一定为无损连接分解
模式分解特性:
1.1 r⊆m ρ(r),即:用r模式分解后的各子投影关系Ri 自然连接后得出的关系m ρ(r),其元组数可能多于原关系r
1.2 π Ri [ m ρ(r) ]=π Ri ( r ),即:用r模式分解后的各子投影关系Ri 自然连接后得出的关系m ρ(r),对子集组中的单个子集Ri所含的全部属性 投影,结果也为Ri
1.3 m ρ( m ρ(r) )= m ρ(r),即:用已经投影过的m子集再次模式分解后投影, m ρ(r)不会再变化(只有在第一次时会变)
无损连接分解及其检验算法
无损连接分解:关系模式R(U,F)中,分解后的关系Ri通过自然连接可以恢复成原来的关系,即通过自然连接得到的关系与原来的关系相比,既不多出信息、又不丢失信息。一般子关系中只有一个关键字的,都是有损的
无损连接检验(2种):
若关系模式R(U,F)中,被分解为p={R1, R2}是R的一个分解,若R1∩R2 → R1 - R2或者R1∩R2 → R2 - R1,则为无损连接
或者用表格
1.建立一张 n(U中属性的个数) 列 k(ρ中关系模式的个数) 行的表,若 “属性” 属于 “模式” 中的属性,则填 aj,否则填 bij
A1 | A2 | … | An | |
R1<U1 , F1> | ||||
R2<U2 , F2> | ||||
… | ||||
Rk<Uk , Fk> |
2. 对于 F 中的每一个X->Y 做如下操作:找到 X所对应的列中具有相同值的那些行k1,k2...。考察这些行k1,k2...中 Y列的元素,若Y列的元素中有ai,就全部改为ai,否则全改为bij。ai(bij)都取这些行中i值最小的那个ai(bij)。
如果在某次更改后,有一行成为:a1,a2,…,an,则算法终止。且分解ρ具有无损连接性,否则不具有无损连接性。
无损连接性质:
可传递:对R进行一次无损连接分解得到R1,R2,...Rn,再对R1进行无损连接分解得到r1,r2,...rm。则r1,r2,...rm,R2,...Rn也是对于R的无损连接分解
可扩展:对R进行一次无损连接分解得到R1,R2,...Rn,再对R进行分解得到S1,S2,...Sm,则:R1,R2,...Rn,S1,S2,...Sm也是对于R的无损连接分解
如何无损分解例题:U= {A,B,C,D,E } ,F={A→B,DE→B,CB→E,E→A,B→D},ρ={ R1(ABC),R2(ED),R3(ACE)}
构造一个初始的 i 行 j 列 的二维表,若 “属性” 属于 “模式” 中的属性,则填 aj,否则填 bij。
A | B | C | D | E | |
R1(ABC) | a1 | a2 | a3 | b14 | b15 |
R2(ED) | b21 | b22 | b23 | a4 | a5 |
R3(ACE) | a1 | b32 | a3 | b34 | a5 |
根据 A→B ,对上表进行处理,由于属性列 A上第1、3行相同均为a1,所以将属性列 B 上的 a2、b32 改为同一个符号 a2(这里有有 a2 于是就改为 a2)。
A | B | C | D | E | |
R1(ABC) | a1 | a2 | a3 | b14 | b15 |
R2(ED) | b21 | b22 | b23 | a4 | a5 |
R3(ACE) | a1 | a2 | a3 | b34 | a5 |
根据 DE→B ,对上表进行处理,由于属性列 DE 上没有相同的列所以这里不做处理。
根据 CB→E ,对上表进行处理,由于属性列 CB上第1、3行相同均为 a2 a3,所以将属性列 E 上的 a5、b15 改为同一个符号 a5(这里有有 a5 于是就改为 a5)。
A | B | C | D | E | |
R1(ABC) | a1 | a2 | a3 | b14 | a5 |
R2(ED) | b21 | b22 | b23 | a4 | a5 |
R3(ACE) | a1 | a2 | a3 | b34 | a5 |
根据 E→A ,对上表进行处理,由于属性列 E 上第1、2、3行相同均为 a5,所以将属性列 A 上的 a1、b21 、a1改为同一个符号 a1(这里有有 a1 于是就改为 a1)。
A | B | C | D | E | |
R1(ABC) | a1 | a2 | a3 | b14 | a5 |
R2(ED) | a1 | b22 | b23 | a4 | a5 |
R3(ACE) | a1 | a2 | a3 | b34 | a5 |
根据 B→D ,对上表进行处理,由于属性列 B 上第1、3行相同均为 a2,所以将属性列 D 上的 b14 、b34 改为同一个符号 b14 (取行号最小值)。
A | B | C | D | E | |
R1(ABC) | a1 | a2 | a3 | b14 | a5 |
R2(ED) | a1 | b22 | b23 | a4 | a5 |
R3(ACE) | a1 | a2 | a3 | b14 | a5 |
再根据 A→B (F中的依赖关系可以重复使用),对上表进行处理,由于属性列 A上第1、2、3行相同均为a1,所以将属性列 B 上的 a2、b22、a2 改为同一个符号 a2。
A | B | C | D | E | |
R1(ABC) | a1 | a2 | a3 | b14 | a5 |
R2(ED) | a1 | a2 | b23 | a4 | a5 |
R3(ACE) | a1 | a2 | a3 | b14 | a5 |
根据 B→D ,对上表进行处理,由于属性列 B 上第1、2、3行相同均为 a2,所以将属性列 D 上的 b14 、a4、b14 改为同一个符号 a4。
A | B | C | D | E | |
R1(ABC) | a1 | a2 | a3 | a4 | a5 |
R2(ED) | a1 | a2 | b23 | a4 | a5 |
R3(ACE) | a1 | a2 | a3 | a4 | a5 |
最终,第1、3行成为a1a2a3a4a5。所以 ρ={ R1(ABC),R2(ED),R3(ACE)} 分解具有无损连接性。
保持依赖分解及其检验算法
保持依赖分解:将R分解为R1,R2,...Rn,对于F中任何一个X->Y,均有X∈Ri,Y∈Ri
即:F中所有的函数依赖,均可以在{ F1,F2 ...Fn }这组函数依赖子集中找到
保持依赖分解检验:依次判断R1,R2....Rn中的函数依赖F1,F2 ...Fn,若F1∪F2 ∪...∪Fn=F,则是保持依赖分解
将关系模式分解为3NF,BCNF
无损连接或保持依赖的分解算法
无损连接分解为BCNF:(不一定保持依赖)
R(U,F),其中F为最小覆盖依赖。将R无损连接分解为R1,R2,...Rn
若Ri不符合BCNF,则Ri上必有X->A,且X不为超键且A不属于X,可以将Ri分解为r1,r2,r1由X,A构成,r2由Ri中除了A之外的所有属性构成
重复步骤2,将所有不符合BCNF的关系全部分解
无损连接分解为4NF:
R(U,F),将R无损连接分解为R1,R2,...Rn
若Ri不符合4NF,则Ri上必有X->->Y,且X不为超键且Y-X不为空,可以将Ri分解为r1,r2,r1由X,Y构成,r2由Y-X构成
重复步骤2,将所有不符合4NF的关系全部分解
保持依赖分解为3NF:
R(U,F),其中F为最小覆盖依赖。将R无损连接分解为R1,R2,...Rn
将R中未出现在F中的属性去掉,并按照依赖单独组成模式
在剩余属性中,对于各X->Ai依赖中的决定属性X,组成X,A1,A2,A3...模式
既保持依赖有无损连接分解:
将保持依赖分解为3NF所得的分解Rj∪{ 全部候选键 },结果即为既保持依赖有无损连接的分解,但该分解不一定是最小符合该分解的关系模式集合,因此可以逐次去掉该分解集合中的一个分解模式,直至它变为最小符合该分解的关系模式集合
连接依赖与第五范式
连接依赖:R(U,F),将R分解为R1,R2,...Rn,对R模式的任一关系r均满足:
r (n目)=π R1(r)⋈π R2(r)⋈....π Rn(r),称为r的n目连接依赖,记为n-JD
多值依赖是特殊的连接依赖,记为2-JD
第五范式:如果关系模式R中的每一个连接依赖均由R的候选码所隐含,则称此关系模式符合第五范式。
5NF也称为投影连接范式(PJNF)
十七、数据库物理存储
内容:
计算机存储体系
磁盘结构与特性
DBMS数据存储与查询思想
数据库表和记录与磁盘块的映射
数据库文件组织方法
计算机存储体系
不同性价比的存储器组织在一起,满足大容量高速度低价格要求
CPU与内存直接交换信息,按存储单元(字)进行访问
外存按存储块进行访问,其信息需要先装入内存,再被CPU访问
操作系统对文件的组织:
FAT文件分配表-目录(文件夹)-磁盘块/簇
磁盘读写时间:寻道时间+旋转时间+传输时间
物理存储算法关键:降低IO次数、排队时间、寻道/旋转延迟时间
降低寻道/旋转延迟时间方法:同一磁道连续块存储,同一柱面不同磁道并行块存储,多个磁盘并行块存储
比特级拆分:一个字节被拆为8bit存储于不同磁盘
块级拆分:一个文件被拆为不同块存储于不同磁盘
扇区/块读写校验:对一个扇区/块作读写校验
磁盘间读写校验:对多个磁盘共同构成的读写信息作校验
RAID技术:
思想:
并行处理:并行读取多个磁盘
可靠性:奇偶校验与纠错
各等级RAID技术:
块级拆分但无冗余
镜像处理:每一个磁盘有一个镜像磁盘C
位交叉纠错处理:4个磁盘存储4位+3个校验盘P存储3校验位
位交叉校验:4个磁盘存储4位+1个校验盘P存储1校验位,位拆分存储(借助扇区读写磁盘判断出错磁盘,再依据校验盘纠错)
块交叉校验:块拆分存储,其他相同
块交叉分布式校验:块拆分存储,互为校验盘
DBMS数据存储与查询思想
数据存储映射关系:
查询操作算法-文件/索引管理:数据逻辑结构-内存:缓冲区管理-磁盘-磁盘管理:读写块(I/O)
数据存储于查询实现示意图

数据库表和记录与磁盘块的映射

数据库记录在磁盘上的存储:
定长记录/变长记录(靠分隔符区分开始与结束)
两种方式都可按长度区分记录,但变长记录也可按指针(标志)区分记录
是否跨块存储?都可以
跨块存储时可以靠指针连接,虽然该方式可以节省一定空间,但会影响并行读写
数据库表所占磁盘的分配方法:
联续分配(后续扩展困难)
链接分配(影响访问速度)
按簇分配:簇指连续的若干磁盘块,簇之间靠指针连接,簇也称片段、盘区
索引分配
数据库文件组织方法
数据组织需考虑更新、检索需求
更新涉及磁盘空间扩展与回收问题
检索涉及扫描数据库,大批量处理数据问题
不同需求要求不同的数据组织存取方法
文件组织:将数据组织成记录、块和访问结构的方式。包括记录和存储在磁盘上的方式,以及记录和块相互联系的方式
存取方法:对文件存取所采用的具体算法
无序记录文件:
特点:无序,存储在任何位置,更新效率高,检索效率低,有内部碎片问题
操作方法:新记录插入文件尾部,删除时直接删除文件,
也可以在要删除的文件前加入删除标志,新增记录可以利用删除记录获得的的空间,
因为反复更新插入会造成空间浪费,因此需要定期重组数据库
重组数据库:通过移除删除记录使得记录连续存放,释放因删除而难以利用的空间
有序记录文件:按某属性(组)值进行插入
特点:记录有序,更新效率低,检索效率可能提高(看检索的要求)
排序字段(排序码):用于排序的属性(组),多为主码
操作方法:为将来可能插入的元组预留空间,但可能造成浪费
或使用溢出文件(一个临时的无序文件)保存新增记录,也需要定期重组数据库
重组数据库:将溢出文件按顺序插入主文件中
散列文件:取某属性(组)值,按散列函数算出其存放位置:桶号/块号/簇,类似桶排序
特点:检索更新效率均有提高
散列字段(散列码):参与散列函数计算的属性(组),多为主码
桶满时处理方法:链接处理法-将溢出记录存储在溢出桶中
聚簇文件:将具有相同/相似属性(组)的记录存储在连续磁盘簇块中
多表聚簇:将多个相关联的table存储在一个文件中->提高多表查询速度
特点:大幅提高检索速度
十八、数据库索引
内容:
索引定义与意义
索引的简单分类
B+树索引
散列索引
索引定义与意义
定义:在表的基础上,无需检查所有记录而快速定位所需记录的辅助存储结构,由一系列索引项组成。
索引项=索引字段+行指针
主文件:存储各种表的文件,有堆、排列、散列、聚簇等多种文件组织形式
索引文件:存储索引项的文件,其存在不改变文件的物理结构,但可以提高文件的访问速度。
分两种:排序索引文件(字段值)、散列索引文件(桶排序)
索引一般特点:
一张表可以建立多种索引文件,索引字段的值可以是任一属性(组)的值
索引文件小于主文件,可以全部装入内存
有索引时,须同步更新主文件和索引文件
索引文件的性能指标:
访问时间、插入时间、删除时间、空间负载、支持存取的有效性(如:支持检索的是属性的唯一值,还是该属性的一定范围的值)
索引相关概念:
字段、排序字段、索引字段(index field)
码/主码/表键:唯一性和最小性
排序码:对主文件进行排序的属性(组),不唯一
索引码(index key):是索引字段,不唯一
搜索码:在主文件中查找记录的属性(集),不唯一
SQL中的索引:
表及其主键被定义后,系统会自动创建主索引
索引可以被用户创建、撤销
系统会自动维护索引文件
删除表后,该表的所有索引也会撤销
创建/撤销索引语句:
creat [unique] index 索引名
on 表名(列1 [asc|desc], ...)
dorp index 索引名索引的简单分类
稠密索引:主文件的每一个记录,都有一个索引项与之对应
候选键稠密索引:有唯一性,与记录一一对应
非候选键稠密索引:
索引文件的索引字段 不重复,则主文件记录 需按索引字段值顺序存储
索引文件的索引字段 可重复,则主文件记录 不需按索引字段值顺序存储
引入指针桶处理重复的索引字段值,索引文件的索引字段 可重复,且主文件记录 不需按索引字段值顺序存储
稀疏索引(非稠密索引):主文件中只有部分记录,有一个索引项与之对应
要求:稀疏索引的主文件必须按索引字段的值顺序排列
稀疏索引使用:
定位值为K的记录:先在索引表中找到小于K的最大索引字段值对应的索引项,从该项所对应的记录开始顺序查找
优缺点:稀疏索引空间占用少,维护压力轻,但检索速度慢
平衡优缺点方法:主索引
主索引:每一磁盘块有一个索引项,索引项数=块数,存储块的第一条记录称为锚记录或块锚
是稀疏索引
索引字段值为各物理块的锚记录索引字段值,指针指向存储块
是按索引字段值排序的有序文件,索引字段多为主码
辅助索引:定义在主文件上的若干非排序字段上的辅助存储结构
索引字段多为非排序字段的不同值,指针指向记录本身或存储块
当索引字段值不唯一时,使用类链表结构来记录包含该字段值的所有记录的位置
聚簇索引:在索引中临近的记录在主文件中也临近存储,索引字段最好是聚簇字段
非聚簇索引:在索引中临近的记录在主文件中不一定临近存储
可以理解为:将表按索引字段值分组存储
聚簇字段:主文件中的某排序字段不为主码,即为聚簇字段。
聚簇索引通常为每个不同的索引字段值设一个索引项,指针指向该值所在的第一个存储块
主索引/聚簇索引可指示新记录插入位置,辅助索引仅能用于查询
主索引与辅助索引的区别 | ||
主索引 | 辅助索引 | |
主文件 | 仅有一个主索引,一个聚簇索引 | 有多个辅助索引,多个非聚簇索引 |
索引类型 | 稀疏索引 | 稠密索引 |
重组主文件数据 | 可以 | 不可以 |
索引字段 | 主码/排序码 | 其他属性(组) |
备注 | 主索引为聚簇索引时,索引项数通常与主存储块数相同,不与索引字段不同值数量相同 | |
正排索引:
文档1的ID→单词1的信息;单词2的信息;单词3的信息…
文档2的ID→单词3的信息;单词2的信息;单词4的信息…
倒排索引:
单词1→文档1的ID;文档2的ID;文档3的ID…
单词2→文档1的ID;文档4的ID;文档7的ID…
其他类型索引:
多级索引:如B/B+树索引
多属性索引
散列索引
网格索引:用多属性字段交叉联合定位与检索
B+树索引
以树形组织结构来组织索引项的多级索引
节点/存储块:
P1 | K1 | P2 | ... ... | P n-1 | K n-1 | Pn |
Ki:索引字段值
Pj:指针,指向索引块,或数据块,或数据库中记录的指针
如何判断使用哪个指针?
若新索引字段值为x,若K i-1 <x < K i+1,则使用Pi指针
索引项大小=索引数据字段值大小+指针大小
一个存储块中索引项数量:块大小-指针大小/(索引项大小),即块中存放N个索引项+一个指向下一存储块的指针
指针指向:
非叶节点指针:指向下一层索引块
叶节点指针:指向数据块/数据记录
最后一个叶节点指针:指向下一个叶节点
B+树结构:
B+ 树非叶子节点上是不存储数据的,仅存储键值,而 B 树节点中不仅存储键值,也会存储数据
B+ 树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的
B+树特点:
通过分裂与合并自动保持与主文件大小相适应的树层次
各索引块的指针利用率都在50%~100%之间,根节点至少有两个指针
B+树存储约定:
索引字段值可重复出现在叶/非叶节点
指向主文件的指针仅出现在叶节点
叶节点可覆盖所有键值的索引
索引字段值在叶节点中顺序排列
插入删除可能导致节点的分裂与合并,进而调整节点中的索引项















 5478
5478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









