









常用的选择排序方法:直接选择排序和堆排序。
一:直接选择排序
直接选择排序和直接插入排序类似,都将数据分为有序区和无序区,所不同的是直接播放排序是将无序区的第一个元素直接插入到有序区以形成一个更大的有序区,而直接选择排序是从无序区选一个最小的元素直接放到有序区的最后。
1:原理
设数组为a[0…n-1]。
(1)初始时,数组全为无序区为a[0..n-1]。令i=0
(2)在无序区a[i…n-1]中选取一个最小的元素,将其与a[i]交换。交换之后a[0…i]就形成了一个有序区。
(3)i++并重复第二步直到i==n-1。排序完成。
2:实现
void select_sort(int arr[],int n)
{
int i,j,index;
for(i=0;i<n;i++){
index = i;
for(j=i+1;j<n;j++)
if(arr[j]<arr[index])
index = j;
swap(&arr[i],&arr[index]);
}
}
void swap(int *a,int *b)
{
int temp = *a;
*a = *b;
*b = temp;
}其中需要注意的是swap函数:
也可以利用以下方法:
void swap1(int *a,int *b)
{
(*a)=(*a)^(*b);
(*b)=(*a)^(*b); //得到*b=*a1(也就是原始数据a1)
(*a)=(*a)^(*b); //得到*a=*b1(也就是原始数据a1)
}
void swap2(int *a,int *b)
{
(*a) = (*a)+(*b);
(*b) = (*a)-(*b);
(*a) = (*a)-(*b);
}
对于swap1()来说,当a==b时,也就是传入的地址是一样的时候,异或以后,*a=*b=0!会造成意想不到的结果。
对于swap2()来说,虽然看上去没什么问题,但是当调用swap(&arr[i],&arr[index]);且当i==index时,传递为同一个地址,(*a) = (*a)+(*b);执行后,*a=*b都变为原来的2倍,然后执行后两句,导致*a=*b=0。为使得程序正常工作,应该在子函数中加上if(*a != *b)判断条件。这样,当时同一个地址的时候,能够正常退出,当不是同一个地址但两个数相等的时候,也直接退出,无需交换。
详细的swap()函数的讨论,请参看:交换两种变量方法
3:分析
(1)关键字比较次数
无论文件初始状态如何,在第i趟排序中选出最小关键字的记录,需做n-i次比较,因此,总的比较次数为:
n(n-1)/2=0(n2)
(2)记录的移动次数
当初始文件为正序时,移动次数为0
文件初态为反序时,每趟排序均要执行交换操作,总的移动次数取最大值3(n-1)。
直接选择排序的平均时间复杂度为O(n2)。
(3)直接选择排序是一个就地排序
(4)稳定性分析
直接选择排序是不稳定的
【例】反例[2,2,1]
二:堆排序
参考大牛帖子:白话经典算法系列之七 堆与堆排序
1:原理
二叉堆的定义:
二叉堆是完全二叉树或者是近似完全二叉树。
二叉堆满足二个特性:
1)父结点的键值总是大于或等于(小于或等于)任何一个子节点的键值。
2)每个结点的左子树和右子树都是一个二叉堆(都是最大堆或最小堆)。
当父结点的键值总是大于或等于任何一个子节点的键值时为最大堆。当父结点的键值总是小于或等于任何一个子节点的键值时为最小堆。下图展示一个最小堆:
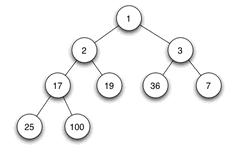
由于其它几种堆(二项式堆,斐波纳契堆等)用的较少,一般将二叉堆就简称为堆。
堆的存储:一般都用数组来表示堆。
i结点的父结点:(i – 1) / 2。它的左右子结点:2 * i + 1和2 * i + 2。如第0个结点左右子结点下标分别为1和2。

下面先给出《数据结构C++语言描述》中最小堆的建立插入删除的图解,再给出本人的实现代码,最好是先看明白图后再去看代码。
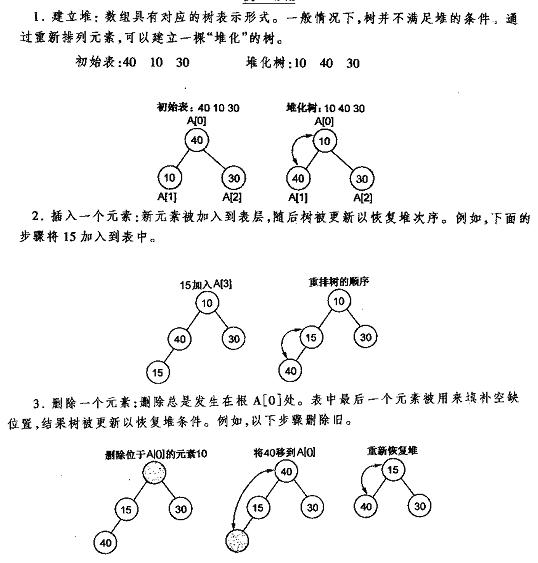
2:实现
这里呢,还是按照算法导论的讲解顺序比较好理解一点(以最大堆为例):
MaxHeapify():时间复杂度O(lgn),是维护最大堆性质的关键。
BuildMaxHeap():具有线性时间复杂度O(n),是从无序的输入数据数组中构造一个最大堆
HeapSort():时间复杂度O(nlgn),对一个数组进行原址排序。
MaxHeapInsert()--HeapExtractMax()--HeapIncreaseKey()--HeapMaximum:时间复杂度O(lgn),利用堆实现优先队列!
1):维护一个最大堆
这里假定左右子树已经是最大堆性质,然后算上父节点后(可以看成父节点改变引起的遍历),调整堆的排序:
void MaxHeapify(int arr[],int i,int n)
{
int lchild = 2*i+1;
int rchild = 2*i+2;
int largest;
if(lchild < n && arr[lchild] > arr[i])
largest = lchild;
else
largest = i;
if(rchild < n && arr[rchild] > arr[largest])
largest = rchild;
if(largest != i){
int temp = arr[i];
arr[i] = arr[largest];
arr[largest] = temp;
MaxHeapify(arr,largest,n);
}
}其时间复杂度为O(lgn),也就是树高。其中的lchild和rchild要和n比较,如果大于n,就超出了数组范围。
2)建堆
将一个无序的数组,通过调整,使整体满足二叉堆的性质。这里有个技巧,从(Length-1)/2->0遍历即可。
void BuildMaxHeap(int arr[],int n)
{
for(int i=(n-1)/2;i>=0;i--)
MaxHeapify(arr,i,n);
}这里时间复杂度为O(n),看着循环应该是O(nlgn),但这个不是渐近紧确的。《算法导论》中,有证明,确实为线性时间O(n)。
3)堆排序算法
通过堆排序算法,最后得到一个递增的有序数组。
其思想是,将第一个元素与最后一个元素交换,然后维护length-1个堆,也只有第0个元素改变,从0开始维护一次即可。
void HeapSort(int arr[],int n)
{
BuildMaxHeap(arr,n);
for(int i=n-1;i>0;i--){
int temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
MaxHeapify(arr,0,i);
}
}时间复杂度为O(nlgn)。
4)增大某一个关键字
思想是:当增大i处关键字后,会破坏i->0处的最大堆性质。两种方法:
方法一:重新调用BuildMaxHeap()函数,从(i-1)/2->0依次遍历(因为递归是向下遍历的)。
方法二:写一个向上递归的函数,依次从低端到根,一趟遍历。
现在利用方法二来实现:void HeapIncreaseKey(int arr[],int i,int key)
{
int p=(i-1)/2;
if(key<arr[i]){
printf("new key is smaller than current key!\n");
}else{
while(i>0 && arr[p]<key){
arr[i] = arr[p];
i=p;
p=(i-1)/2;
}
arr[i]=key; //将对i位置的赋值放在最后,可以将循环中的交换简化为单次赋值。
}
}
4)插入
思想是:将元素插入到数组的最后一个位置。然后又两种解决思路:
方法一:重新调用BuildMaxHeap()函数,从(n-1)/2->0依次遍历。
方法二:写一个向上递归的函数,依次从低端到根,一趟遍历。
/*此函数只写了如何调用HeapIncreaseKey()来实现插入,但没有具体实现其功能,因为涉及到数组的扩展
*main()函数中应该用malloc()生成buf[],插入子函数中,用realloc()实现数组大小动态扩展。
*/
int *MaxHeapInsert(int arr[],int n,int num)
{
arr = (int *)realloc(arr,(n+1)*sizeof(int)); //比如这样动态分配
n=n+1;
arrnew[n-1]=-1; //要对其赋值,因为在HeapIncreaseKey会判断值是否增加。
HeapIncreaseKey(arrnew,n-1,num);
return arrnew;
}5)删除
根据堆的用法(一般用于优先队列),删除时只会删除第0个元素,只考虑这一种情况即可。为了便于操作,我们借鉴由最大堆输出有序数列的方法,将第0个元素,与最后一个元素交换,然后调用MaxHeapify(arr,0,n-1);即可!
int HeapExtractMax(int arr,int n)
{
int max;
if(n==0){
printf("heap empty!\n");
exit(-1);
}
max=arr[0];
arr[0] = arr[n-1];
MaxHeapify(arr,0,n-1);
return max;
}3:分析
堆排序的时间,主要由建立初始堆和反复重建堆这两部分的时间开销构成,它们均是通过调用Heapify实现的。
堆排序的最坏时间复杂度为O(nlgn)。堆排序的平均性能较接近于最坏性能。
由于建初始堆所需的比较次数较多,所以堆排序不适宜于记录数较少的文件。
堆排序是就地排序,辅助空间为O(1),
它是不稳定的排序方法。















 2254
2254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









