






读取文件pd.read_csv()
CSV:文件以纯文本形式存储表格数据(数字和文本)
df=pd.read_csv(file_path,sep=",|:|;",engine="python",header=0,encoding='gbk')
-
file_path: 这是CSV文件的路径。您需要将file_path替换为实际的文件路径字符串,例如'C:/Users/48487/Desktop/nba.csv'。 -
sep=",|:|;": 这个参数指定了分隔符。默认情况下,read_csv期望使用逗号(,)作为字段分隔符。但有时CSV文件可能使用其他的分隔符,比如分号(;)、冒号(:)或其他特殊字符。在这里,您指定了一个正则表达式,用来匹配逗号、冒号或分号作为字段分隔符。这在处理那些使用不同分隔符的文件时非常有用。 -
engine="python": 这个参数指定了用于解析CSV文件的引擎。pandas提供了两种引擎:python和c。python引擎是纯Python实现,而c引擎是一个更快的Cython实现。在大多数情况下,使用默认的c引擎会更快。但是,如果您的CSV文件格式非常特殊或者包含大量转义字符,python引擎可能更加稳健。 -
header=0: 这个参数指定哪一行作为列名。在这里,header=0表示第一行(行索引从0开始)将被用作列名。如果您的CSV文件中没有列标题,您可以将其设置为None。 -
encoding='gbk': 这个参数指定了文件的编码格式。在这里,您使用了gbk编码,这是用于简体中文字符的编码格式之一。如果您的CSV文件使用了不同的编码,您需要相应地更改这个参数。例如,对于使用UTF-8编码的文件,您应该使用encoding='utf-8'。
综上所述,代码行配置了 read_csv 函数来读取一个可能使用不同分隔符的CSV文件,且该文件的列名位于第一行,使用 gbk 编码。如果CSV文件符合这些条件,df 将是一个包含文件数据的 DataFrame 对象。
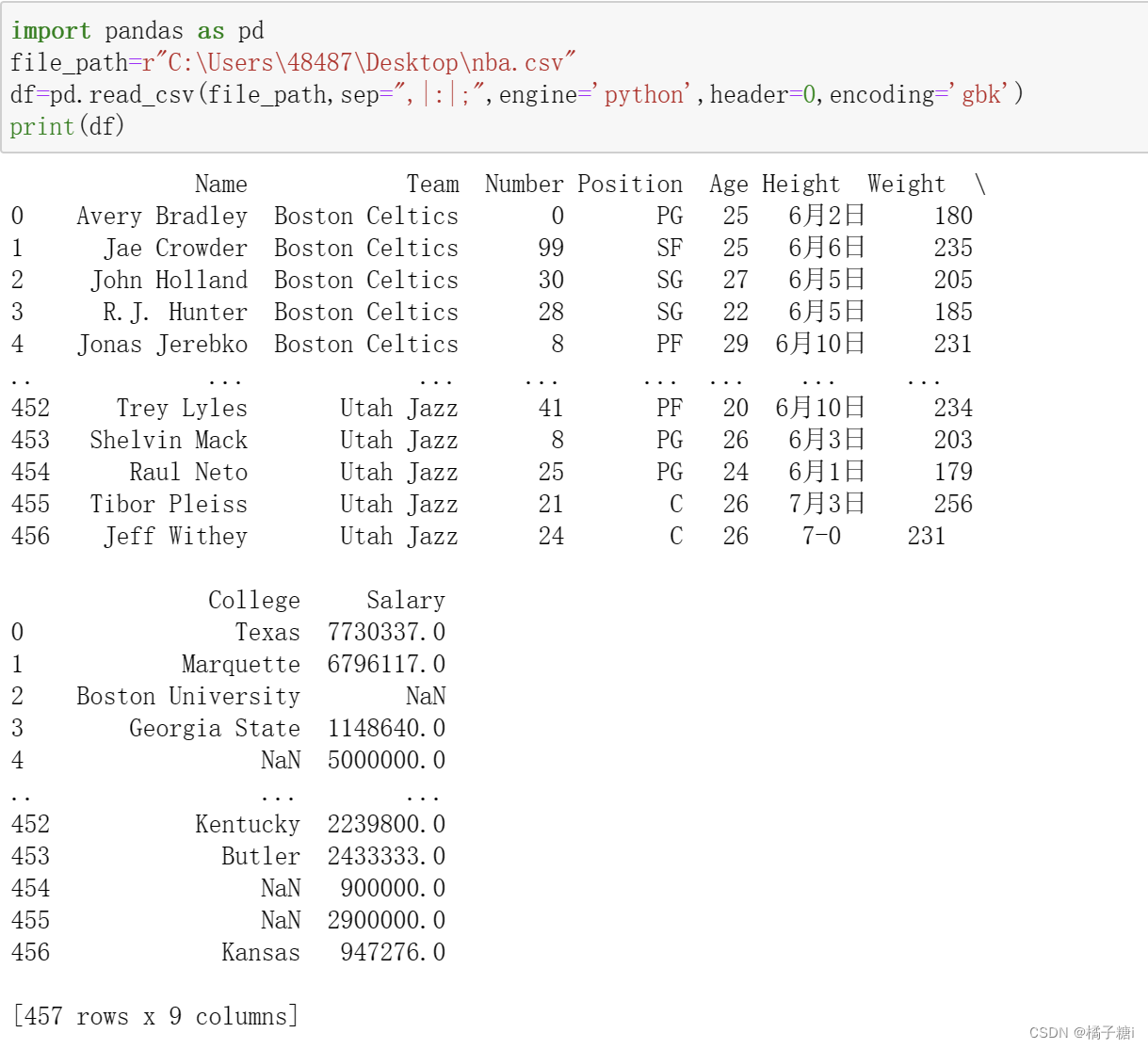
print(df.to_string())
to_string() 用于返回 DataFrame 类型的数据,如果不使用该函数,则输出结果为数据的前面 5 行和末尾 5 行,中间部分以 ... 代替。
将DataFrame存储为CSV文件:to_csv()
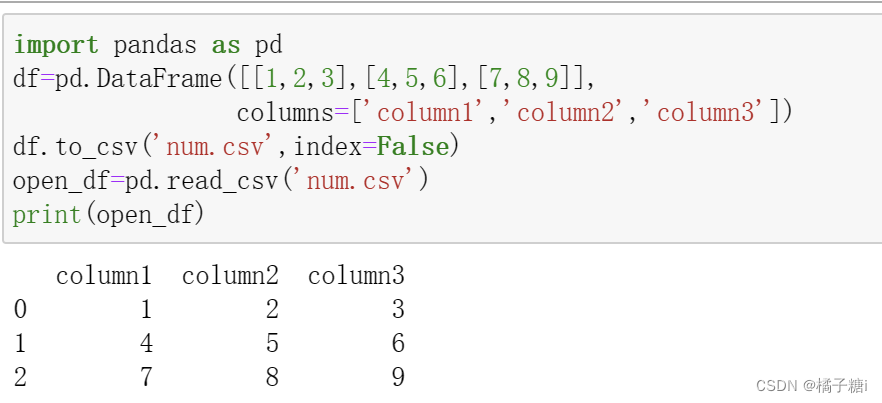
回顾了好几个知识点:1创建DataFrame 2存储为CSV文件 3打开CSV文件
df.to_csv('num.csv',index=False)如果这句话中缺少index=False
会导致索引也变成文件内一列,心都死了

读取前几行.head()
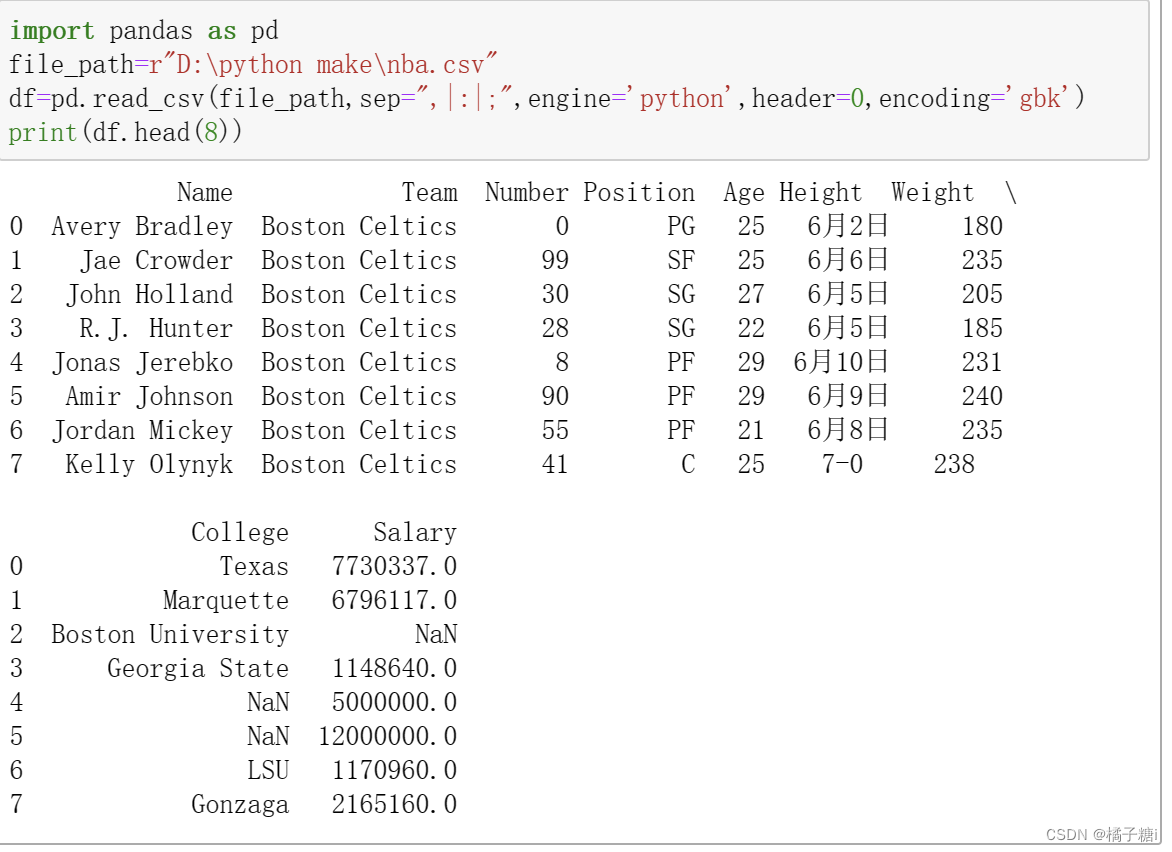
head()括号内若不填写,默认前五行
读取后几行.tail()
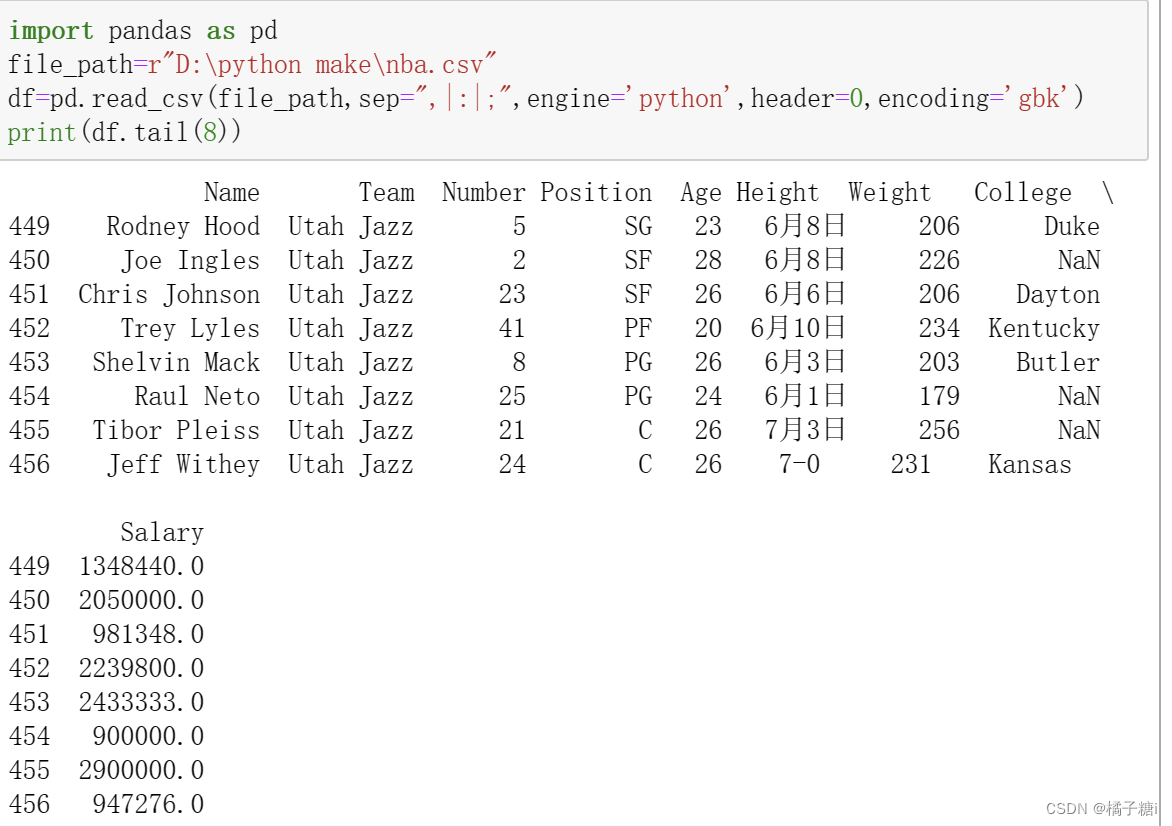
tail()括号内若不填写,默认后五行
获取表格基本信息.info()
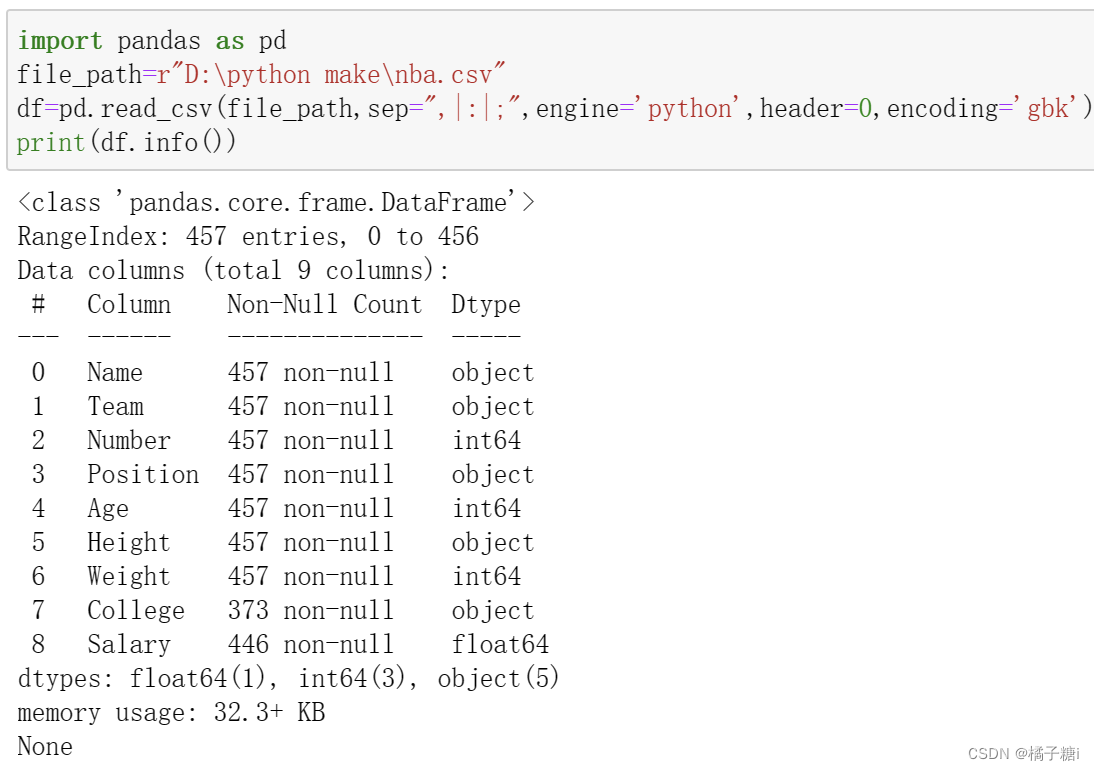
可以得出458行,第一行编号0
9列,每列数据类型,non-null,意思为非空的数据,
一个float64,3个int64,5个object
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









