






数据结构Series
一维数组:只有一个轴(或维度),类似Python中的列表
缺失数据:Series 可以包含缺失数据,Pandas 使用NaN(Not a Number)来表示缺失或无值。
创建Series
pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)

第一列0 1 2是索引,第二列是数据,dtype是数据类型
使用列表、字典或数组创建一个默认索引的 Series

指定索引

指定索引得到一部分数据

设置Series名称参数

设置名称的作用:
示例 1:在图表的标题中使用名称
在使用matplotlib或Pandas自己的绘图功能时,Series或DataFrame的名称可以自动用作图表的标题。
import matplotlib.pyplot as plt # 使用name作为图表标题
data.plot(title=data.name)
plt.show()
示例 2:在数据合并操作中使用名称
在执行数据合并操作时,如果列名相同但属于不同的数据集,可以使用name属性来区分它们。
import pandas as pd
# 创建两个Series,它们有相同的列名但不同的名称
series1 = pd.Series([1, 2, 3], name='Series1')
series2 = pd.Series([4, 5, 6], name='Series2')
# 合并Series,名称可以帮助区分不同的数据来源
result = pd.concat([series1, series2], axis=1)
print(result)输出:
Series1 Series2
0 1 4
1 2 5
2 3 6示例 3:在分组操作中使用名称
在执行分组操作时,name属性可以用于指定分组的名称,这在结果中会体现出来。
import pandas as pd
# 创建一个DataFrame
df = pd.DataFrame({
'Category': ['A', 'A', 'B', 'B'],
'Value': [10, 20, 15, 30],
'SeriesName': ['TestSeries'] * 4 # 假设SeriesName是我们的name属性 })
# 按Category分组并计算Value的平均值,使用SeriesName作为分组依据
grouped = df.groupby('Category')['Value'].mean().rename('AverageValue')
print(grouped)输出:
Category
A 15.0 B 22.5
Name: AverageValue, dtype: float64基本操作
指定索引创建

获取值

索引和值的对应关系

s.items() 返回一个包含 (index, value) 对的迭代器,允许您同时获取 Series 的索引和对应的值
修改值

添加值

哇哦,修改后Series就变了,那个a就是10了
删除值del或 .drop()


基本运算
加乘

过滤(选择符合条件元素)

数学函数(例如每个元素取平方根).sqrt()

属性
print(s.sum()) # 输出 Series 的总和 print(s.mean()) # 输出 Series 的平均值 print(s.max()) # 输出 Series 的最大值 print(s.min()) # 输出 Series 的最小值 print(s.std()) # 输出 Series 的标准差 print(s.dtype) # 数据类型 print(s.shape) # 形状 print(s.size) # 元素个数 print(s.head()) # 前几个元素,默认是前 5 个 print(s.tail()) # 后几个元素,默认是后 5 个

获取描述性统计信息.describe()

获取最大值和最小值的索引.idxmax()或.idxmin()

转换数据类型.astype()

Series中的数据是有序的。- 可以将
Series视为带有索引的一维数组。- 索引可以是唯一的,但不是必须的。
- 数据可以是标量、列表、NumPy 数组等。
数据结构DataFrame
可以被看做由 Series 组成的字典(共同用一个索引)
二维结构: DataFrame 是一个二维表格,可以被看作是一个 Excel 电子表格或 SQL 表,具有行和列。可以将其视为多个 Series 对象组成的字典。
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
创建DataFrame
使用列表创建


使用ndarrays创建


使用列表创建 DataFrame 时,Pandas 需要推断列表中元素的数据类型
而NumPy 数组已经知道其元素的数据类型,Pandas 可以使用这些信息来设置 DataFrame 列的数据类型。
从Series创建DataFrame:pd.Series()

使用字典创建



没有对应的部分数据为 NaN
查看数据类型.dtypes

转换数据类型.astype()

基本操作
返回行数据
使用 loc 属性返回指定行的数据,如果没有设置索引,第一行索引为 0,第二行索引为 1,以此类推

还可以返回多行数据

发现没有!!Pandas的.loc[]方法遵循的是包含两端的行为
.loc[]方法使用的是标签索引,这意味着它会选择包含开始标签和结束标签
指定索引值

访问元素
访问列:
使用列名作为属性或通过 .loc[]、.iloc[] 访问,也可以使用标签或位置索引

访问行:
使用行的标签和 .loc[] 访问

修改列数据

添加新列

添加新行
使用 loc方法

使用append 方法

使用 concat方法

删除元素
删除列:.drop()

axis=0表示操作的是行(默认值)。axis=1表示操作的是列。
删除行:.drop()

DataFrame 的统计分析
属性和方法
# DataFrame 的属性和方法
print(df.shape) # 形状
print(df.columns) # 列名
print(df.index) # 索引
print(df.head()) # 前几行数据,默认是前 5 行
print(df.tail()) # 后几行数据,默认是后 5 行
print(df.info()) # 数据信息
print(df.describe())# 描述统计信息
print(df.mean()) # 求平均值
print(df.sum()) # 求和
描述性统计.describe()
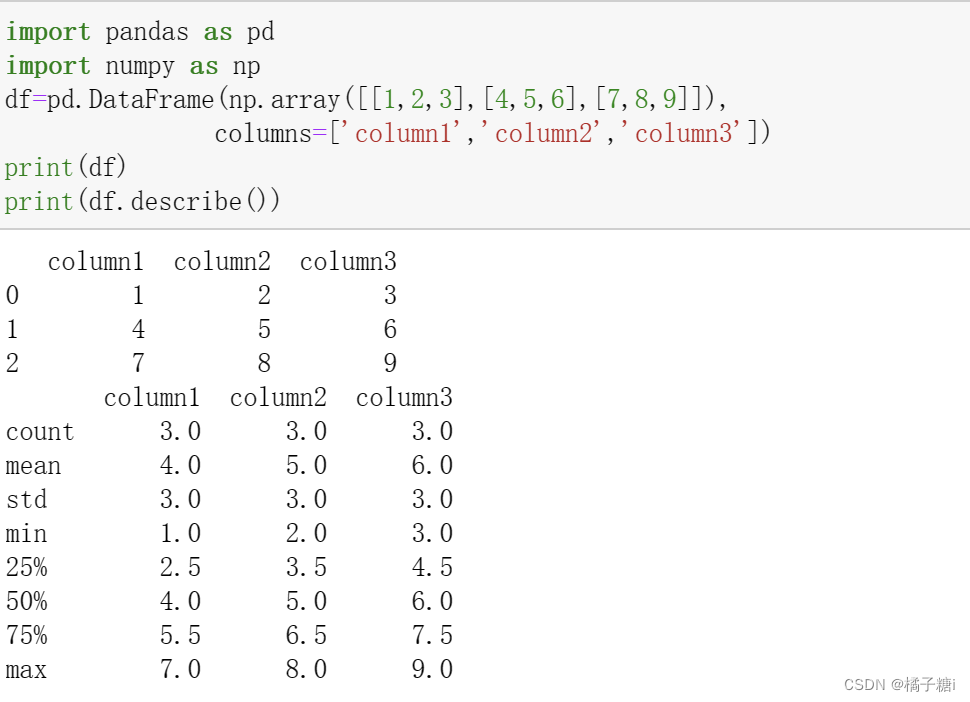
count:非空(非NaN)值的数量。mean:数值列的平均值。std:数值列的标准差,表示数据的离散程度。min:数值列的最小值。25%:数值列的第一四分位数(Q1),即在排序后位于25%位置的值。50%:数值列的中位数(Q2),也是排序后位于中间位置的值。75%:数值列的第三四分位数(Q3),即在排序后位于75%位置的值。max:数值列的最大值。
检查缺失值
如果某列的count值小于该列的总 行数,说明存在缺失值
# 计算每列的缺失值数量
print(df.isnull().sum())
检查异常值
通过查看 describe() 输出中的四分位数,可以了解数据的分布情况。如果某个数据点位于第一四分位数减去1.5倍的四分位距或第三四分位数加上1.5倍的四分位距之外,它可能被认为是异常值。
# 计算四分位距
Q1 = df.describe()["25%"]
Q3 = df.describe()["75%"]
IQR = Q3 - Q1
# 标记可能的异常值
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# 标记超出四分位距的值
outliers = (df < lower_bound) | (df > upper_bound)
print(df[outliers])计算统计数据.sum() .mean()等

DataFrame 的索引操作
索引和切片

重置索引.reset_index()

设置索引.set_index()

column1这列变成索引,day1,day2,day3是普通列但不显示
如果要显示的话,可以复制引入一个新列

布尔索引

DataFrame 的合并与分割
合并
纵向合并.cancat()

train = pd.DataFrame({
'A': [1, 2],
'B': [3, 4]
})
# 假设 test DataFrame 也有两列,分别是 B 和 C,同样有两行数据:
test = pd.DataFrame({
'B': [5, 6],
'C': [7, 8]
})
#纵向合并内连接
inner_concat = pd.concat([train, test], join='inner', axis=0)
print(inner_concat)
#纵向合并外连接
outer_concat=pd.concat([train,test],join='outer',axis=0)
print(outer_concat)
concat=pd.concat([train,test],ignore_index=True)
print(concat)
#横向合并内连接
inner_heng_concat = pd.concat([train, test], join='inner', axis=1)
print(inner_heng_concat)
#横向合并外连接
outer_heng_concat = pd.concat([train, test], join='outer', axis=1)
print(outer_heng_concat)结果自己比对下,就可以知道不同点了

横向合并.merge()

分割
长格式转宽格式.pivot()

宽格式转长格式.melt()
















 3223
3223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









