







InternVL2: Better than the Best—Expanding Performance Boundaries of Open-Source Multimodal Models with the Progressive Scaling Strategy
InternVL2:超越最好——通过渐进式扩展策略扩展开源多模态模型的性能边界
官网地址:https://internvl.github.io/blog/2024-07-02-InternVL-2.0/
官网解读:https://zhuanlan.zhihu.com/p/706547971
虽然在2025年InternVL2不是最佳的多模态模型,但是该系列的InternVL2.5任然是sota模型。故此还是需要了解InternVL2的创新。
基于对InternVL2的分析,可以得到以下经验:
1、对于将预训练好的VIT与LLM模型组装成mllm模型时,可以只训练MLP部分,实现快速的模态对齐
2、llm部分的升级可以大幅度提升mllm模型的效果,尤其是在非标准格式问答中
3、数据分布域的改变,导致在标准格式输出,如grounding任务中,模型性能的下降(这表明模型能力的提升不一定是全面的)
1、模型信息
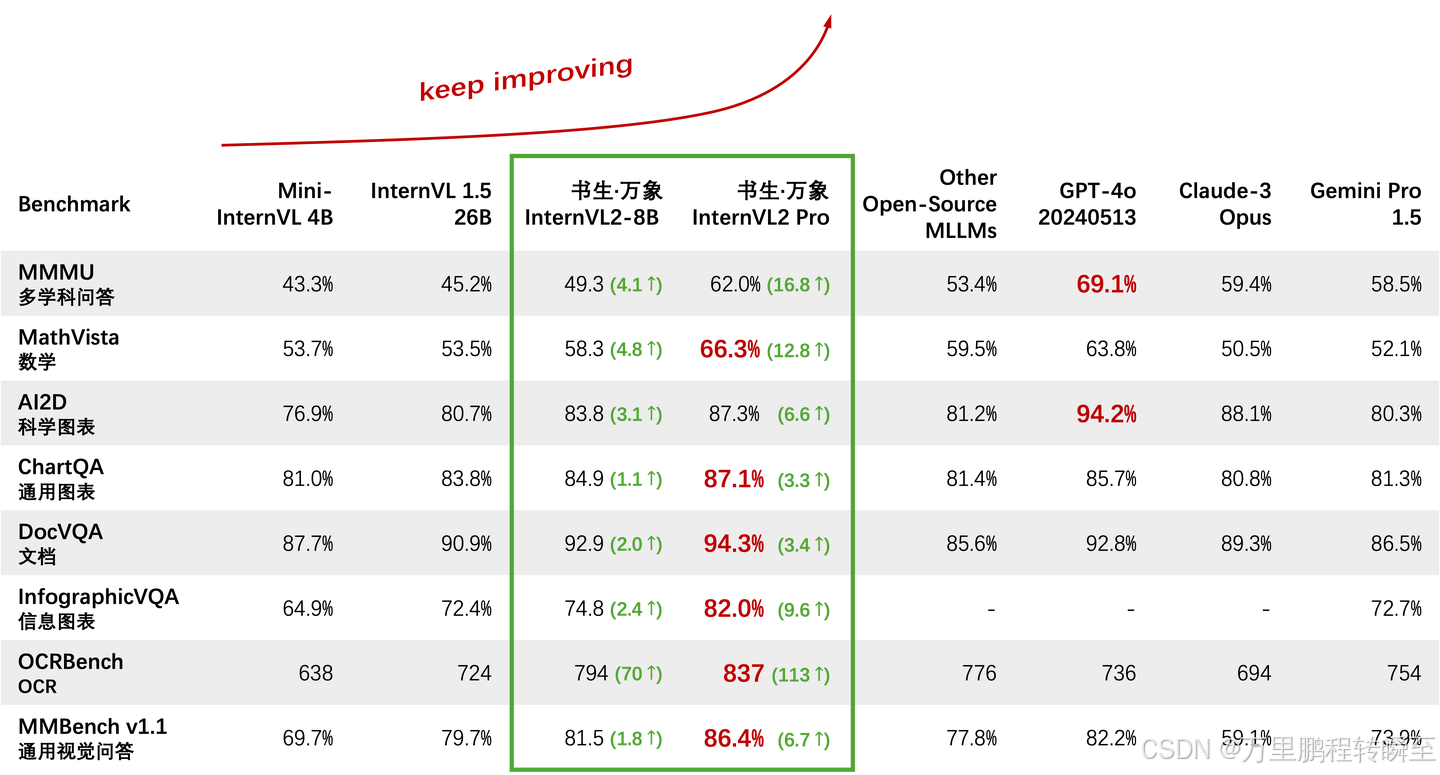
1.1 性能信息
这里可以发现InternVL2-8B模型比上一版本的26B模型还要强不少,而这里只有语言部分的区别:InternVL1.5用的是InternLM2-20B,InternVL2-8B模型用的是internlm2.5-7b模型。固定视觉部分,优化llm展现了巨大的性能提升。
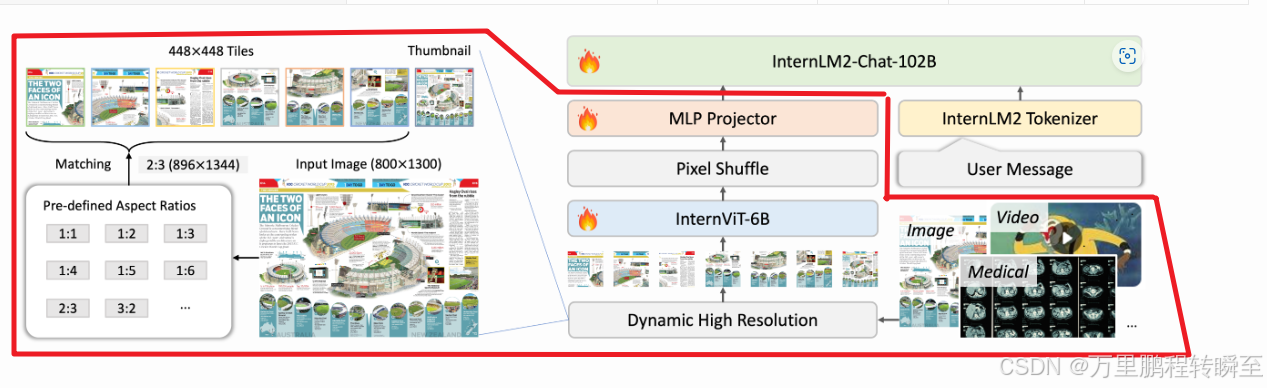
1.2 InternVL2模型结构
InternVL2由语言部分和视觉部分(VIT+MLP)组成
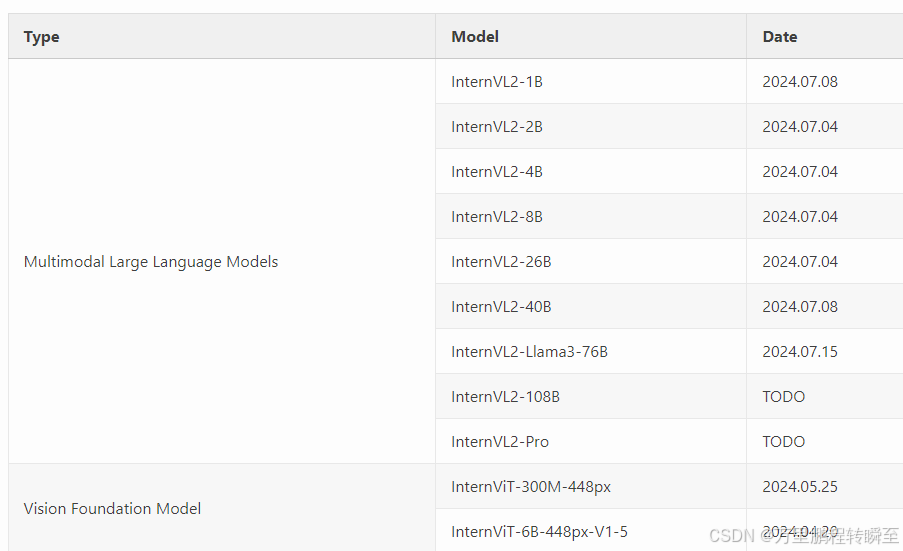
每一部分的版本详情如下所示,可以发现VIT部分还是使用了上一版(InternVL1.5模型中)的InternViT-6B-448px-V1.5模型,但补充了InternViT-300M-448px版本,以实现对8B以下mllm模型的支持。而语言部分,则进行了不同层次的扩展,如internlm2.5-7b,qwen1-0.5b、等。
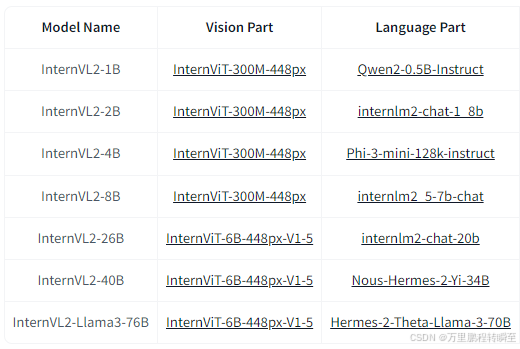
模块间的匹配关系如下
1.3 参数详情
这里主要明白VIT、MLP、LLM之间的参数量匹配关系。VIT模型只有两个参数规模,这表明视觉部分不是制约mllm性能的关键。MLP的参数增长规模与LLM的增长是相适应的,MLP主要实现将VIT输出的encoding投影到LLM所能理解的token中。

2、算法改进
2.1 构建原则
InternVL2 系列基于以下设计构建:
- 1、使用较大的语言模型进行渐进式:我们引入了渐进式对齐 训练策略,从而产生第一个原生对齐的 Vision Foundation 模型 使用大型语言模型。通过采用渐进式训练策略,其中模型 从小到大,当数据从粗细到细时,我们完成了 以相对较低的成本训练大型模型。这种方法已经证明 在有限的资源下实现出色的性能。
- 2、多模态输入:通过一组参数,我们的模型支持多种模态 的输入,包括文本、图像、视频和医疗数据。
- 3、多任务输出:由我们最近的工作 VisionLLMv2 提供支持, 我们的模型支持各种输出格式,例如图像、边界框和蒙版, 展示广泛的多功能性。通过将 MLLM 与多个下游任务连接起来 解码器,InternVL2 可以推广到数百个视觉语言任务,同时实现 性能可与专业模型相媲美。
2.2 训练步骤
InternVL-2的训练步骤如下所示,在模态对齐中仅实现了对MLP部分的微调。
第一阶段,仅训练MLP,快速实现现有预训练模型的模态对齐;
第二阶段,训练所有参数,实现性能的提升

而原来InternVL-1的训练步骤则为3步,可以发现最模态对齐中有较多的步骤
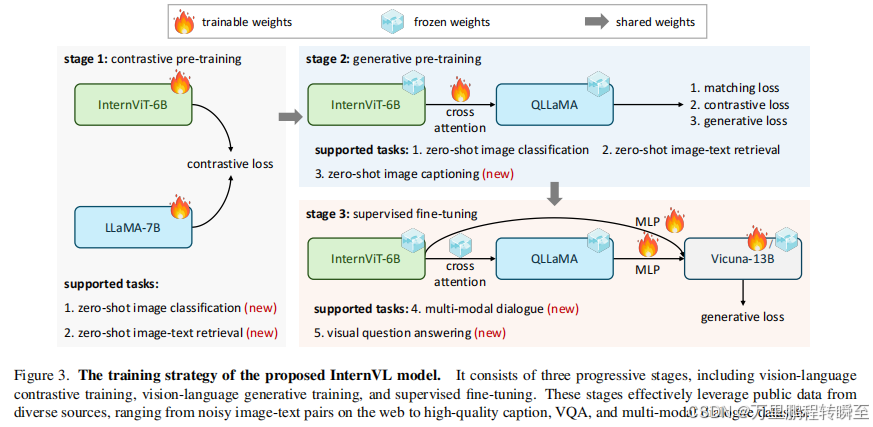
3、性能指标
数据来源自 https://huggingface.co/OpenGVLab/InternVL2-40B#quick-start
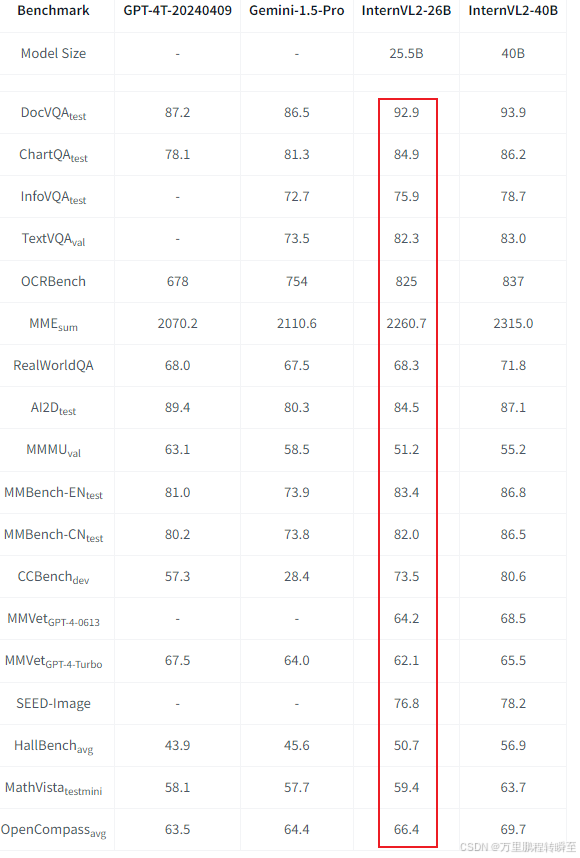
3.1 Image Benchmarks
可以发现与同时期模型相比,InternVL是超越了Gemini1.5 pro,但预计与gpt4o存在差异
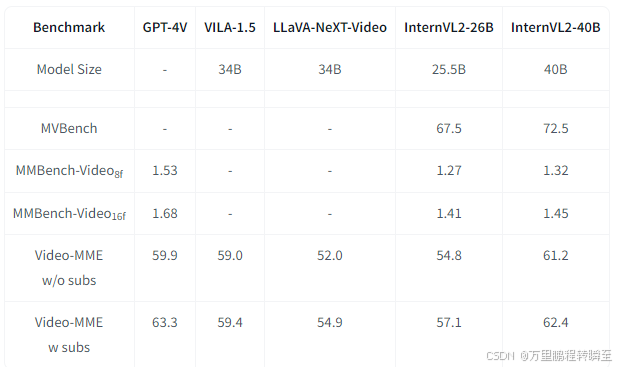
3.2 Video Benchmarks
在视觉指标中,没有与Gemini1.5 pro对比,可以发现还是差了不少。40b模型不如qwen2-vl 7b模型。这表明该模型在时序建模方式上存在不足。
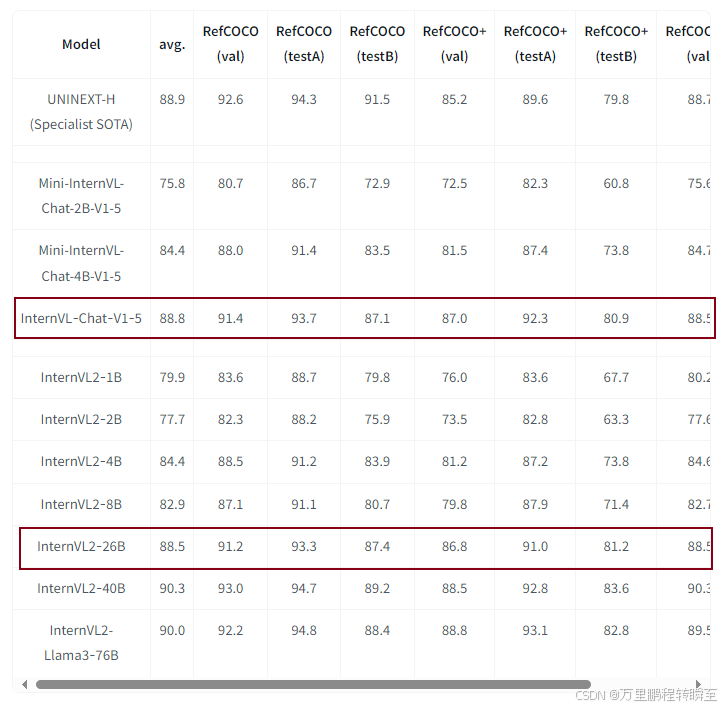
3.3 Grounding Benchmarks
在Grounding 任务中,可以发现InternVL2‑26B模型效果还不如InternVL‑Chat‑V1‑5,这表明训练数据的分布变化会严重影响效果,llm性能增益不如数据增益有效。该现象表明,在专业任务中,广而泛的大模型不如专业数据训练出的小模型。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











